【iOS】关键字复习
目录
weak的实现原理
SideTable
weak流程
weak是如何引入的
weak的本质
strong\copy原理+深浅拷贝
copy\strong原理
容器内部的深浅拷贝
完全拷贝(真正的深拷贝)
自定义类的深浅拷贝
retain\release实现原理
关键字
线程安全
内存管理
修饰变量
weak的实现原理
-
Runtime维护了一个weak表,用于存储指向某个对象的所有weak指针。weak表其实是一个hash(哈希)表,Key是所指对象的地址,Value是weak指针的地址(这个地址所指向的的值是被引用对象的地址)数组。
-
runtime对注册的类, 会进行布局,对于weak对象会放入一个hash表中。 用weak指向的对象内存地址作为key,当此对象的引用计数为0的时候会dealloc,假如weak指向的对象内存地址是a,那么就会以a为键, 在这个weak表中搜索,找到所有以a为键的weak对象,从而设置为nil
在初始化时,objc_initWeak函数会调用objc_initWeak函数,初始化一个新的weak指针指向对象的地址;在添加引用时,objc_initWeak函数会调用objc_storeWeak()函数,objc_storeWeak()的作用是更新指针指向,创建对应的弱引用表;释放时,调用clearDeallocating函数,首先根据对象地址获取所有weak指针地址的数组,然后遍历这个数组把其中的数据设为nil,最后把这个entry从weak表中删除,最后清理对象的记录
声明一个弱引用对象时,会先调用objc_initWeak,这个函数会检查对象是否为空,为空就会把弱引用的值置为nil,不为空就会调用objc_storeWeak(),在这个方法里会先判断该引用是否有旧值以及是否指向了新值,如果有旧值就要把旧值清除掉,如果指向了新值,就要把新值添加到对象的弱引用表中。添加弱引用时,先找到对应的散列表,获取weak_table,然后将table和变量以及弱引用地址作为参数调用weak_register_no_lock这个函数,在函数中调用weak_entry_for_referent根据变量地址找到对应的weak_entry,找到后通过append_referrer方法进行弱引用的存储;当要先清除旧值时,需要先获取对象对应的实体weak_entry,再调用remove_referrer方法,从实体中移除对应的弱引用。当对象引用计数为0时调用dealloc方法,最终会调用clearDeallocating方法对弱引用进行处理,对于有弱引用的对象,会调用clearDeallocating_slow()方法,最终在weak_clear_no_lock方法中清除弱引用,在这个过程中首先会获取对象对应的实体,然后开启循环把entry数组中的弱引用全部设为nil,最后把entry从弱引用表中移除
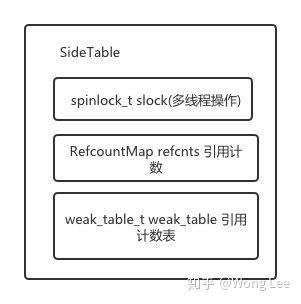
SideTable
在runtime中,有4个非常重要的数据结构:sidetables、sidetable、weak_table_t和weak_entry_t
sidetables,顾名思义是一个存放sidetable的哈希结构,它是一块放在静态区的内存,通过对象的地址经过运算后可以找到对象对应的sidetable的地址(也可以看作是哈希算法),在模拟机中,最多存在64张sidetable,在真机中最多存在8张sidetable

sidetable中包含(不严格地说,sidetable可以类比成一个桶,里面的元素是哈希表(引用计数表或弱引用表)):
-
保证原子属性的自旋锁
spinlock_t -
记录引用计数值的
RefcountMap -
用于存储对象弱引用的哈希表
weak_table_t
RefcountMap结构是一个hash map,其key是obj的DisguisedPtr<objc_object>,而value,则是obj对象的引用计数,同时,这个map还有个加强版功能,当引用计数为0时,会自动将对象数据清除。
weak_table本质是一个以obj地址为key,弱引用obj的指针的地址作为value的hash结构。记录了所有弱引用对象的集合,在weak_table_t中存在一个哈希数组weak_entries(元素类型为weak_entry_t)用来存储弱引用对象的相关信息weak_entry_t,还保存了数组中的元素个数,以及数组长度-1作为掩码(数组长度而不是个数),还有最大哈希偏移值
weak_entries实质上是一个动态数组,数组中存储weak_entry_t类型的元素,每个weak_entry_t对应了一个OC对象的所有弱引用信息,weak_entry_t的结构相当于一个只有键没有值或者键值相等的hash表(元素数量大于4的情况下),存储的元素是weak_referrer_t,实质上就是弱引用该对象的指针的地址,通过操作指针的指针,可以使weak引用的指针在对象析构后指向nil
struct weak_entry_t {DisguisedPtr<objc_object> referent; // 被弱引用的对象// 引用该对象的对象列表,联合。 引用个数小于4,用inline_referrers数组。 用个数大于4,用动态数组weak_referrer_t *referrersunion {struct {weak_referrer_t *referrers; // 弱引用该对象的对象指针地址的hash数组uintptr_t out_of_line_ness : 2; // 是否使用动态hash数组标记位uintptr_t num_refs : PTR_MINUS_2; // hash数组中的元素个数uintptr_t mask; // hash数组长度-1,会参与hash计算。(注意,这里是hash数组的长度,而不是元素个数。比如,数组长度可能是64,而元素个数仅存了2个)素个数)。uintptr_t max_hash_displacement; // 可能会发生的hash冲突的最大次数,用于判断是否出现了逻辑错误(hash表中的冲突次数绝不会超过改值)};struct {// out_of_line_ness field is low bits of inline_referrers[1]weak_referrer_t inline_referrers[WEAK_INLINE_COUNT];};};
bool out_of_line() {return (out_of_line_ness == REFERRERS_OUT_OF_LINE);}
weak_entry_t& operator=(const weak_entry_t& other) {memcpy(this, &other, sizeof(other));return *this;}
weak_entry_t(objc_object *newReferent, objc_object **newReferrer): referent(newReferent) // 构造方法,里面初始化了静态数组{inline_referrers[0] = newReferrer;for (int i = 1; i < WEAK_INLINE_COUNT; i++) {inline_referrers[i] = nil;}}
};weak_entry_t的属性中有被弱引用的对象的指针,然后是一个联合体,有两种形式,当数目小于WEAK_INLINE_COUNT(值为4)时,使用定长数组,当超过时,会把定长数组中的元素转移到动态哈希表,之后都用动态哈希表
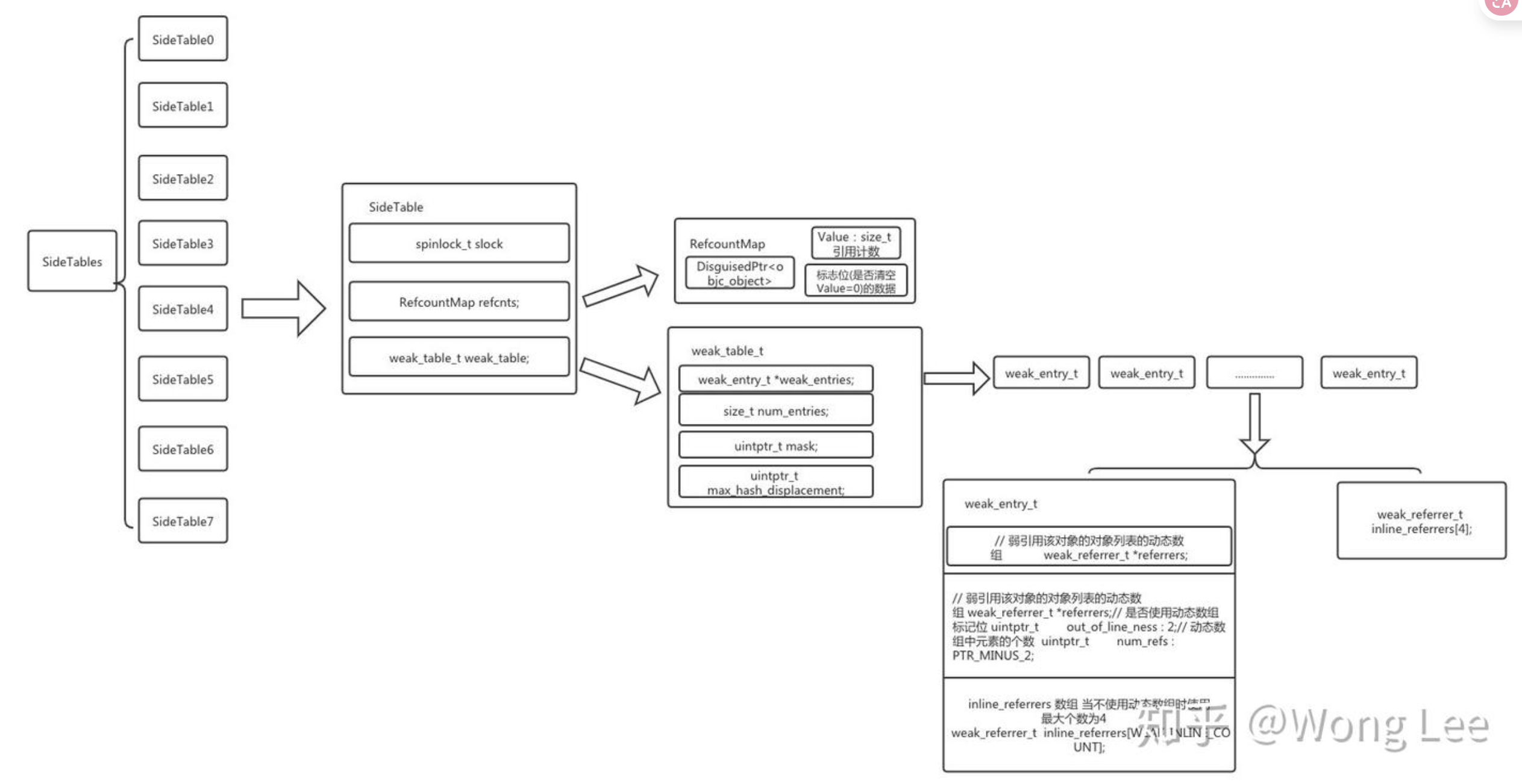
在向weak_table_t中查找某个元素时是通过方法weak_entry_for_referent来实现的,它会在weak_entries数组中使用哈希算法获取到弱引用传入的这个对象的weak_entry_t
关于weak_table_t扩容,当存储量达到3/4时需要扩容,是先创建一个局部变量存放当前哈希表中保存的所有弱引用实体,再新建一个容量是旧哈希表大小2倍的哈希表并重置相关属性,再遍历之前保存的旧的数据,将数据按顺序依次重新插入新建的哈希表中,再释放旧数据
关于weak_entries_t扩容,当存储数量达到4时,需要将定长数组扩容为动态哈希表,在动态哈希表中存储量达到3/4时需要扩容,步骤与weak_table_t相同
要向weak_table_t中插入某个对象时,要先取出哈希表中所有弱引用对象的数据,遍历取出的所有数据找到第一个空位置,将要插入的实体插入到这个位置,同时更新当前weak_table中弱引用实体个数,最后重置weak_table中最大哈希冲突次数的值
weak流程
当一个weak变量被初始化并指向一个对象时,runtime会调用objc_initWeak函数,接着调用objc_storeWeak()函数完成实际的存储操作,如果对象无效就会把变量设置为nil
当weak变量被赋值给一个对象时,会添加引用,再次调用objc_storeWeak()函数来更新指针指向并维护弱引用表
当对象引用计数为0时,会调用clearDeallocting函数进行弱引用表中的清除,这里与之前weak原理中的相同
因此对象被释放后,所有指向它的weak变量都会被设为nil,从而避免了悬空指针的问题
weak是如何引入的
当两个对象相互持有对方的强引用时,会导致他们都无法释放,使用weak引用可以打破这种循环,使得对象可以被正确地释放
weak的本质
-
不增加引用计数: weak 引用不会增加被指向对象的引用计数,因此不会阻止对象被释放。
-
自动置nil: 当所指向的对象被释放后,weak 引用会自动被设置为 nil。这可以避免使用一个已释放对象的指针,从而防止野指针错误。
-
用于解决循环引用: weak 引用常用于解决对象之间循环引用的问题。当两个对象相互持有对方的强引用时,会导致它们都无法被释放。使用 weak 引用可以打破这种循环,使得对象可以被正确地释放。
-
底层实现: weak 引用在底层是通过一个哈希表实现的。当一个对象被声明为 weak 时,对象的地址会被用作哈希表的键,而一个指向该 weak 变量的指针会被存放在一个集合中。当对象被释放时,runtime 会通过这个哈希表找到所有指向该对象的 weak 引用,并将它们设置为 nil。
strong\copy原理+深浅拷贝
深拷贝得到的副本,副本与源数据互不影响,而浅拷贝得到的副本与源数据之间会互相影响
在记忆copy与mutableCopy时,可以记住一个结论,我们使用copy方法,目的是为了得到一个互不影响的副本,因此如果对象不可变,那就可以直接浅拷贝
深浅拷贝:
浅拷贝:对内存地址的复制,让目标对象指针和原对象指向同一片内存空间会增加引用计数 深拷贝:对对象内容的复制,开辟新的内存空间

自定义对象需要具有拷贝功能时,我们要实现NSCopying协议和NSMutableCopying协议
copy\strong原理
-
copy:用该修饰符进行修饰的属性,在调用该属性的set方法时,会进行一次copy操作,新开辟一块内存区域,所以原对象指针指向的内存区域值被修改不会造成影响.因为做了一次深拷贝.
-
strong:用该修饰符进行修饰的属性,引用计数+1,但仅仅拷贝了指针,实际跟原指针指向同一块内存区域,所以原指针指向的内存区域值被修改之后,新的对象值也会被修改.这里仅仅是浅拷贝
在底层为属性添加修饰符后,调用set方法最后会调用reallySetProperty,在这个方法中会根据修饰符判断是否需要copy或者mutableCopy,如果需要就会调用copyWithZone/mutableCopyWithZone方法,对属性进行一次拷贝,只是调用copy方法,是深拷贝还是浅拷贝取决于属性类型
⚠️注意:对于不可变类型,copy修饰符和strong修饰符其实都是进行浅拷贝,但是copy意在强调数据隔离,对于可变类型,copy进行深拷贝但是返回的是不可变对象,这时如果对属性进行修改会报错,为什么源码中会出现mutableCopy,这是因为在KVC或一些框架中可能会通过元数据标记属性应该mutableCopy,但是在实际开发中,如果要实现mutableCopy的效果,就需要在setter中明确调用mutableCopy来实现这类需求
一般情况下,推荐不可变对象使用copy,防止对象被修改,可变对象使用strong,如果用copy就会返回不可变对象,但是如果确保数据不会被修改,建议使用strong而不是copy,这样可以避免copy使用过多,重复判断造成的性能消耗
容器内部的深浅拷贝
对于容器,copy和mutableCopy都是针对集合对象本身的,集合中的对象都默认执行浅拷贝,如果想要深拷贝容器的同时也copy容器内的元素,可以调用方法[initWithArray:aArray copItems:YES];
这样每个元素都会收到copyWithZone:消息
注意⚠️:这个方法也不是所有情况下都深拷贝集合对象本身的,如果原对象是不可变的空数组的话,对原对象本身执行的就是浅拷贝
完全拷贝(真正的深拷贝)
上面说到对对象发送copy消息,也就意味着拷贝行为还是根据对象类型决定的,并不一定是深拷贝,要实现完全拷贝就要先归档后解档(前提是嵌套的子模型要遵守NSCoding协议)
以NSArray<NSArray *>为例
NSArray *trueDeepCopyArray = [NSKeyedUnarchiver unarchiveObjectWithData: [NSKeyedArchiver archivedDataWithRootObject: oldArray]];这段代码把原数组通过archivedDataWithRootObject方法得到一个包含这个数组对象和她关联数据的NSData对象,通过将这个对象传递给unarchiveObjectWithData:方法,可以得到一个解档后的对象,即trueDeepCopyArray,这就是归档解档,数组以及数组内所有元素必须遵守NSCoding协议,否则就会报错
关于远对象和副本对象的可变性,在使用initWithArray: copyItems: YES时,生成的副本集合中的(第一个级别)对象是不可变的,更深层次的对象仍保持之前的可变性;在使用归档解档时,原对象和副本对象所有级别的可变性一致
自定义类的深浅拷贝
要实现自定义类的深浅拷贝,我们让自定义类遵守NSCopying或者NSMutableCopying协议,实现copyWithZone/mutableCopyWithZone方法,如果是浅拷贝,就在方法内返回self(此时对象可变性不可能发生改变),如果是深拷贝,就创建新对象,把属性依次赋值给新对象的属性,最后返回这个新的对象,如果属性也需要深拷贝,就在赋值时调用属性的copy方法
有一种Runtime+KVC的方式给新对象进行赋值也可以实现新拷贝(面试别说)
CustomModel *m1 = [CustomModel new];
m1.name = @"Shaw";
m1.age = 27;
CustomModel *m2 = [m1 copy];
m2.name = @"CTT";
m2.age = 28;NSLog(@"%@&%@", m1.name, m2.name);
// 打印结果:Shaw&CTT@interface CustomModel : NSObject <NSCopying>
@property (nonatomic, strong) NSString *name;
@property (nonatomic, assign) int age;
@end@implementation CustomModel- (id)copyWithZone:(NSZone *)zone {CustomModel *copy = [[[self class] alloc] init];unsigned int propertyCount = 0;objc_property_t *propertyList = class_copyPropertyList([self class], &propertyCount);for (int i = 0; i < propertyCount; i++ ) {objc_property_t thisProperty = propertyList[i];const char* propertyCName = property_getName(thisProperty);NSString *propertyName = [NSString stringWithCString:propertyCName encoding:NSUTF8StringEncoding];id value = [self valueForKey:propertyName];[copy setValue:value forKey:propertyName];}return copy;
}
// 注意此处需要实现这个函数,因为在通过Runtime获取属性列表时,会获取到一个名字为hash的属性名,这个是系统帮你生成的一个属性
- (void)setValue:(id)value forUndefinedKey:(NSString *)key {}retain\release实现原理
retain步骤:首先判断对象是否为小对象,如果是小对象不用内存管理直接返回;然后判断isa指针有没有优化,如果没有优化,就从散列表(散列表解锁,散列表结构体中存在自旋锁)中获取引用计数加一,接着判断对象是否正在释放,如果正在释放就dealloc流程,不在释放就访问isa位域extra_rc并加一,如果满了就拿一半存到散列表里去
release步骤:如果小对象就不用内存管理直接返回,如果没优化isa就从散列表取引用计数并减一,接着判断引用计数是否为0,如果为0就执行dealloc流程,如果isa优化过就从isa位域中取引用计数,如果为零,再在散列表里找,找到了就减一,没找到或者减一后为零的话都进行dealloc流程
关键字
-
内存管理有关的关键字:
weak,assgin,strong,retain,copy; -
线程安全的关键字:
monatomic,atomic -
访问权限的关键字:
readonly,readwrite。 -
修饰变量的关键字:
const,static,extern。
线程安全
nonatomic:非原子操作,不加锁,线程执行快,但是多个线程访问同一个属性可能产生crash
atomic:原子操作,加锁,保证setter和getter存取方法的线程安全(仅仅对setter和getter方法加锁)。因为线程加锁,别的线程访问当前属性的时候会先执行完属性当前的操作。
注意⚠️:atomic只针对属性的 getter/setter 方法进行加锁,所以安全只是针对getter/setter方法来说,并不是整个线程安全,因为一个属性并不只有 setter/getter 方法,例:(如果一个线程正在getter 或者 setter时,有另外一个线程同时对该属性进行release操作,如果release先完成,会造成crash)
内存管理
关键字weak 同样经常用于修饰OC对象类型的数据,修饰的对象在释放后,指针地址会自动被置为nil,这是一种弱引用。
注意⚠️:在ARC环境下,为避免循环引用,往往会把delegate属性用weak修饰;在MRC下使用assign修饰。当一个对象不再有strong类型的指针指向它的时候,它就会被释放,即使还有weak型指针指向它,那么这些weak型指针也将被清除。
关键字assign 经常用于非指针变量,用于基础数据类型 (例如NSInteger)和C数据类型(int, float, double, char, 等),另外还有id类型。用于对基本数据类型进行复制操作,不更改引用计数。也可以用来修饰对象,但是,被assign修饰的对象在释放后,指针的地址还是存在的,也就是说指针并没有被置为nil,成为野指针。
注意⚠️:之所以可以修饰基本数据类型,因为基本数据类型一般分配在栈上,栈的内存会由系统自动处理,不会造成野指针 以及:在MRC下常见的id delegate往往是用assign方式的属性而不是retain方式的属性,为了防止delegation两端产生不必要的循环引用。例如:对象A通过retain获取了对象B的所有权,这个对象B的delegate又是A, 如果这个delegate是retain方式的,两个都是强引用,互相持有,那基本上就没有机会释放这两个对象了。
关键字strong
用于修饰一些OC对象类型的数据如:(NSNumber,NSString,NSArray、NSDate、NSDictionary、模型类等),它被一个强指针引用着,是一个强引用。在ARC的环境下等同于retain,它是我们通常所说的指针拷贝(浅拷贝),内存地址保持不变,只是生成了一个新的指针,新指针和引用对象的指针指向同一个内存地址,没有生成新的对象,只是多了一个指向该对象的指针。
关键字copy
修饰OC对象数据类型,在给属性赋值时会调用copy方法,在MRC时代,block需要用copy来修饰,因为copy需要从栈区copy到堆区,现在的ARC时代,系统会自动进行这个操作,所以使用copy还是strong都可以
关键字retain
关键字retain常用于MRC模式下,当使用 retain 声明一个属性时,意味着该对象被引用计数加1,除非手动释放,否则对象不会被销毁。重新赋值时,会自动释放旧值,当对象销毁时,必须在dealloc中显式地去调用release,在ARC模式下,retain与strong是一样的,常使用strong
修饰变量
关键字const
常量修饰符,表示不可变,可以用来修饰右边的基本变量和指针变量(注意const的位置)
常量(const)和宏定义(define)的区别: 使用宏和常量所占用的内存差别不大,宏定义的是常量,常量都放在常量区,只会生成一份内存 缺点:
宏是预编译(编译之前处理),const是编译阶段。使用宏定义过多的话,宏定义替换后的代码量会膨胀,随着工程越来越大,编译速度会越来越慢 宏不做检查,不会报编译错误,只是替换,const会编译检查,会报编译错误。 优点:
宏能定义一些函数、方法,const不能。
关键字static
定义所修饰的对象只能在当前文件访问,不能通过extern来引用
static修饰全局变量:只能在本文件中访问,修改全局变量的作用域,生命周期不会改。避免重复定义全局变量(单例模式) static修饰局部变量:有时希望函数中的局部变量的值在函数调用结束后不消失而继续保留原值,即其占用的存储单元不释放,在下一次再调用的时候该变量已经有值。这时就应该指定该局部变量为静态变量,用关键字 static 进行声明。延长局部变量的生命周期(没有改变变量的作用域,只在当前作用域有用),程序结束才会销毁。
局部变量只会生成一份内存,只会初始化一次。把它分配在静态存储区,该变量在整个程序执行期间不释放,其所分配的空间始终存在
关键字extern
用来获取全局变量(包括全局静态变量)的值,不能用于定义变量(查找优先级: 先在当前文件查找有没有全局变量,没有找到,才会去其他文件查找。)
static与const联合使用用来声明一个静态的全局只读常量
extern与const联合使用用来定义一份全局常量