强化学习实战:从零搭建自主移动机器人避障仿真(1)— 导论篇
在机器人研究与应用领域,一个共识正变得越发清晰:仿真,是通往现实自主不可或缺的“训练场”与“试验田”。无论是学生完成课程设计、研究员验证前沿算法,还是企业进行产品原型迭代,仿真技术都以其零风险、低成本、高效率的独特优势,扮演着至关重要的角色。
那么,为何选择“避障”作为仿真学习的切入点?
与重传感器耦合、强依赖物理标定的SLAM(同步定位与建图)不同,避障算法的核心更侧重于逻辑与决策的优雅。它剥离了部分硬件的不确定性,让我们能更纯粹地聚焦于“智能”本身——如何让机器人在复杂环境中做出合理、安全的实时决策。正是这种特性,使避障成为探索人工智能算法,特别是强化学习(Reinforcement Learning) 的完美沙盒。
而强化学习,作为一种让智能体通过“试错”与“奖励”来自主学习最优策略的范式,为解决传统规则式避障算法在动态、未知环境中的局限性提供了全新的思路。它不再依赖于人类工程师穷举所有规则,而是让机器自己学会“敏捷”与“丝滑”的避障策略。
在本专栏中,我们将依托 Gazebo/PyBullet 这类高保真动力学仿真引擎,构建一个无限逼近现实的训练环境。您将亲眼见证,一个智能体如何从零开始,通过数百万次的仿真碰撞与探索,最终进化出堪比老司机的娴熟避障能力。
一、强化学习概念:与环境交互的试错学习
强化学习(Reinforcement Learning, RL)是机器学习的一个重要分支,其核心思想非常直观:一个智能体(Agent)通过与环境(Environment)进行持续交互,根据其行动(Action)所获得的奖励(Reward)或惩罚来学习最优策略(Policy),以达成长期目标。
可以将其类比为训练宠物:
智能体 (Agent) -> 宠物狗
环境 (Environment) -> 家和后院
行动 (Action) -> 狗做出的动作(坐、趴、叫)
奖励 (Reward) -> 主人给的零食和抚摸
策略 (Policy) -> 狗心里学会的“怎么做才能得到零食”的规则
智能体通过和环境交互,基于行动所对应的奖惩机制学到策略,就是强化学习的本质。就比如说金毛发现在主人“叫其名字时坐下”能得到零食时,便会趋向于此策略。强化学习与传统机器学习的关键区别在于:
监督学习(如分类):拥有标准答案( labeled data),学习的是“是什么”。
强化学习:没有标准答案,只有评价性的反馈(奖励信号),学习的是“怎么做”。
其核心框架遵循一个闭环:状态(State) -> 行动(Action) -> 奖励(Reward) -> 下一状态(New State)。智能体的终极目标,不是获取眼前的即时奖励,而是通过学习一套策略,来实现长期累积奖励的最大化。
在机器人避障任务中,这套框架完美落地:
状态:机器人传感器读取的数据(如激光雷达点云、图像)。
行动:机器人的运动指令(如前进、后退、左转、右转)。
奖励:设计奖励函数是算法的灵魂。例如,成功前进给予正奖励,发生碰撞则给予巨大的负奖励(惩罚)。
目标:学会一种避障策略,使得从起点到终点所获得的累积奖励最高,即安全、高效地抵达目标。
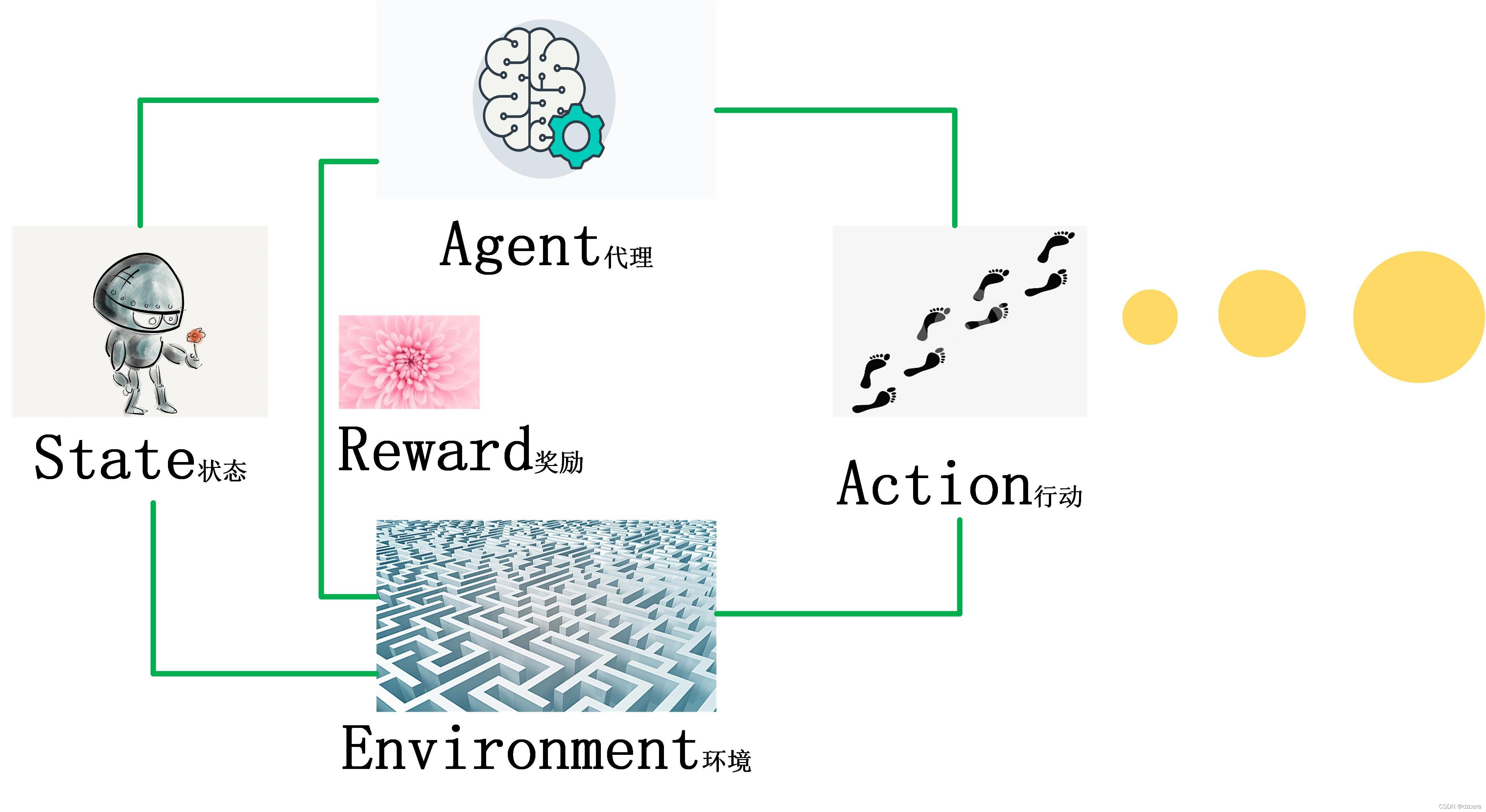
强化学习机制
二、避障算法对比:从“本能反应”到“全局规划”再到“智能学习”
移动机器人的避障算法主要经历了从“反应式”到“认知式”的演进,我们可以将其分为三大类:
1. 反应式算法(如VFF、Bug算法)
核心思想:“感知-行动”的直接映射。不构建全局地图,像条件反射一样,根据即时传感器信息(如激光雷达)实时产生运动指令。
优点:计算开销极小,速度快,实时性极高。
缺点:缺乏全局观,容易陷入局部陷阱(如死循环),行为短视,在复杂环境中可靠性差。
比喻:像一只盲目的飞蛾,绕着灯飞,虽然不会撞上,但永远在打转,到不了真正的目的地。
2. 基于规划的算法(如A、D、RRT)
核心思想:“先地图,后路径”。首先利用SLAM等技术构建全局或局部地图,然后在已知地图上进行最优路径搜索与规划。
优点:能够做出全局最优的决策,路径平滑合理。
缺点:严重依赖地图的准确性和实时性,无法应对未知的、动态变化的障碍物(突然出现的人或车)。
比喻:像一个严格按照导航软件开车的人。只要地图没错,就能到达终点,但一旦路上突然出现施工路障,导航就会失灵。
3. 基于学习的算法(特别是强化学习)
核心思想:“经验学习”。让机器人在仿真或真实环境中通过数百万次的“试错”来自主学习避障策略,最终获得一种逼近本能的驾驶能力。
优点:能应对动态未知环境,适应性极强。无需精确地图,仅凭传感器输入就能做出智能决策。
缺点:需要大量数据和时间进行训练,设计奖励函数需要技巧(“奖励工程”)。
比喻:像一个经验丰富的老司机。他不需要精确的地图,仅凭眼睛观察路况,就能根据多年驾驶经验(训练结果)下意识地做出流畅、安全的避障操作。
总结而言:与传统方法相比,强化学习避障牺牲了前期的计算效率,换来了最终决策的智能性和对未知环境的强大泛化能力,为解决动态复杂环境中的避障问题提供了全新的范式。
| 维度 | 反应式算法 | 基于规划的算法 | 基于学习(强化学习)的算法 |
| 核心思想 | “感知-行动”反射弧 (无地图) | “先建图,后规划” (依赖地图) | “经验学习” (试错优化) |
| 优点 | 速度快、计算量小、实时性极高 | 路径全局最优、逻辑清晰 | 适应动态未知环境、泛化能力强 |
| 缺点 | 易局部最优(死循环)、无全局观 | 依赖地图精度、怕动态障碍 | 训练成本高、需要设计奖励函数 |
| 适用场景 | 简单、静态结构化环境 | 已知、静态或缓慢变化环境 | 复杂、动态、未知环境 |
避障算法对比
三、仿真平台介绍:Gazebo vs. PyBullet — 工程与研究的双刃剑
在机器人仿真领域,Gazebo和PyBullet是两款最主流的高保真动力学引擎,它们设计哲学不同,各有千秋,共同构成了我们专栏的“数字试验场”。
1. Gazebo: 机器人领域的“工业标准”
核心定位:与ROS(机器人操作系统)深度绑定的全能型选手。它不仅仅是一个物理引擎,更是一个完整的机器人仿真环境,提供传感器模拟、逼真渲染、甚至插件系统。
优点:
生态成熟:拥有大量预制的经典机器人模型(如TurtleBot、PR2)和传感器模型,开箱即用。
ROS原生支持:与ROS消息、服务、TF变换无缝集成,是学习和实践ROS的首选仿真工具。
高精度传感器模拟:其摄像头、激光雷达(Lidar)等传感器模拟非常接近真实数据,便于算法迁移。
缺点:重量级。安装复杂(尤其对新手),对硬件要求较高,启动和运行相对较慢。
适用场景:侧重于机器人整体系统集成、传感器融合和ROS开发。如果你想走机器人工程师路线,Gazebo是必须掌握的技能。
2. PyBullet: 强化学习研究的“利器”
核心定位:一个专注于物理模拟和AI研究的轻量级库。它本身不是一个独立的软件,而是一个Python库,通过API提供物理仿真服务。
优点:
轻量高效:安装极其简单(
pip install pybullet),启动速度快,计算开销小,更适合需要大量“试错”的强化学习训练。Pythonic API:所有操作通过Python代码控制,与深度学习框架(如PyTorch, TensorFlow)无缝衔接,开发调试流程非常顺畅。
专注于物理:剥离了复杂的图形界面(支持无头模式),将全部算力集中于物理计算本身,效率极高。
缺点:传感器模拟和渲染效果相对Gazebo稍弱,与ROS的集成需要额外配置。
适用场景:侧重于算法验证、快速原型开发和大规模的强化学习训练。如果你是算法研究员或希望快速实现想法,PyBullet是更优选择。
专栏的选择:为何两者兼用?
本专栏将同时介绍基于Gazebo和PyBullet的实现路径。这不仅让你同时掌握工业界和学术界的两大主流工具,更能让你深刻理解:Gazebo如何为ROS算法提供系统级验证,而PyBullet又如何为AI算法提供高效训练环境。通过对比学习,你将获得更全面、更深刻的仿真能力,并能根据项目需求灵活选择最合适的平台。
Gazebo

PyBullet