[开源项目] Tiny-RAG :一套功能完善、高度可配的本地知识库问答解决方案
在过去的一段时间里,我一直在探索大型语言模型(LLM)的落地应用。LLM的强大毋庸置疑,但它们普遍存在的“知识截止日期”和“一本正经地胡说八道”(幻觉)问题,使其在处理专业、私有或实时知识时常常力不从心。
检索增强生成(Retrieval-Augmented Generation, RAG)是解决这个问题的最佳方案之一。然而,在动手实践的过程中,我发现市面上大多数的RAG教程或项目都过于简化,离一个真正“好用”的系统还有很长的距离。
所以,我决定自己动手,从头打造一套功能完善、高度可定制的RAG系统。今天,我非常高兴地宣布,这个项目已经开源,并上传到了GitHub!
➡️ 项目地址:Tiny_RAG
不只是另一个RAG Demo,它有什么特别之处?
如果你也像我一样,看过无数个“上传文档->提问->回答”的RAG演示,你可能会问:这个项目有什么不同?
不同之处在于,我将重点放在了解决那些让简单Demo“不好用”的关键问题上。
1. 告别单一的向量检索:引入混合与集成检索
纯向量检索依赖“语义”相似,但在处理专业术语、代码、产品型号这类“关键词”敏感的查询时,常常表现不佳。为了解决这个问题,我实现了一套更智能的检索策略:
- 混合检索 (Hybrid Search): 它将传统关键词检索(类似BM25)的精准匹配能力和向量检索的语义理解能力结合起来,你可以通过一个权重参数动态调节两者的贡献。这意味着,无论你的问题是偏向语义理解还是关键词匹配,系统都能找到最相关的结果。
- 集成检索 (Ensemble Retrieval): 更进一步,你可以定义多个检索器,系统会将它们的结果加权融合,取长补短,最大化召回的准确性和多样性。
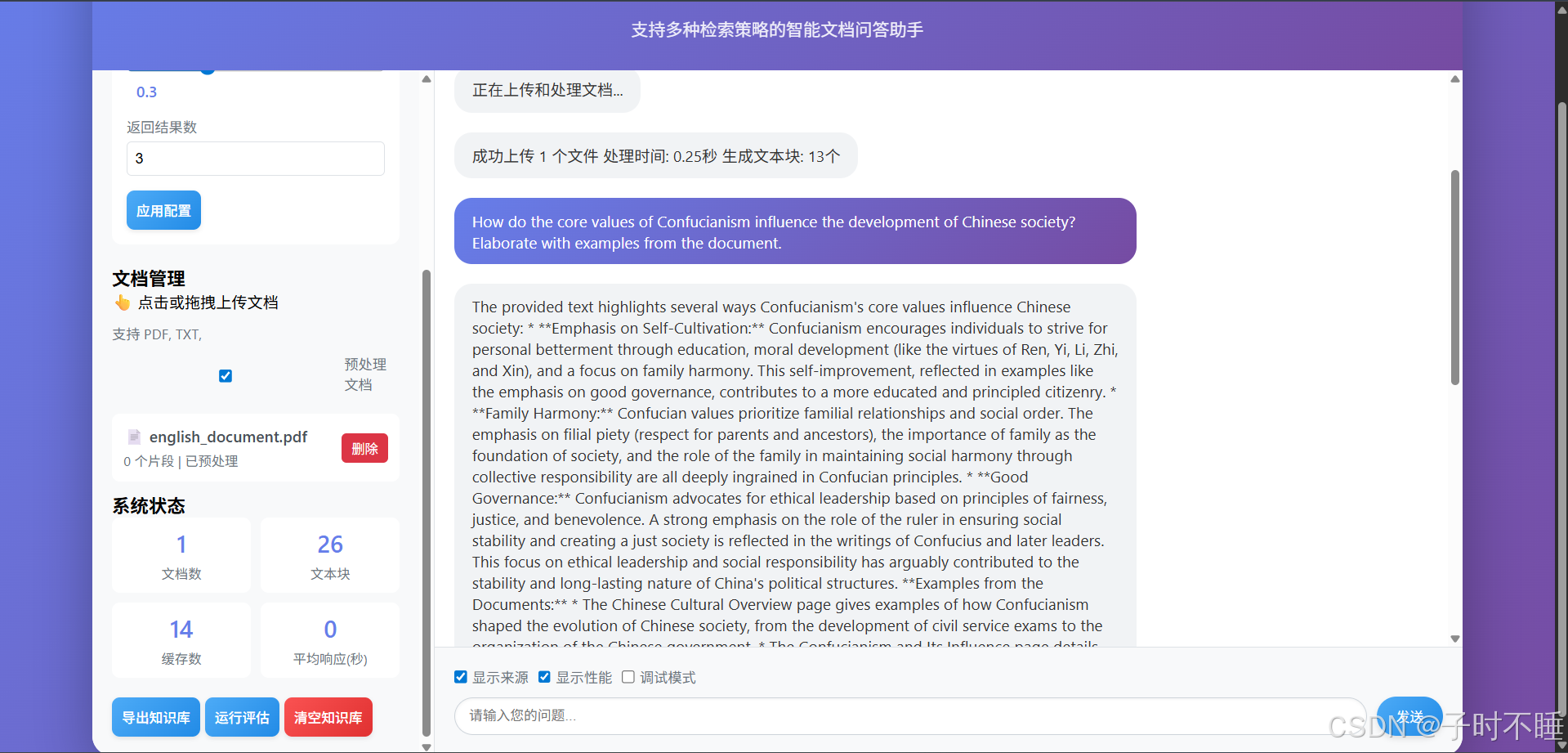
2. 答案可信可溯源:让每一句话都有据可查
为了解决LLM的幻觉问题,RAG的核心是“基于事实回答”。我的系统在这一点上做了强化。
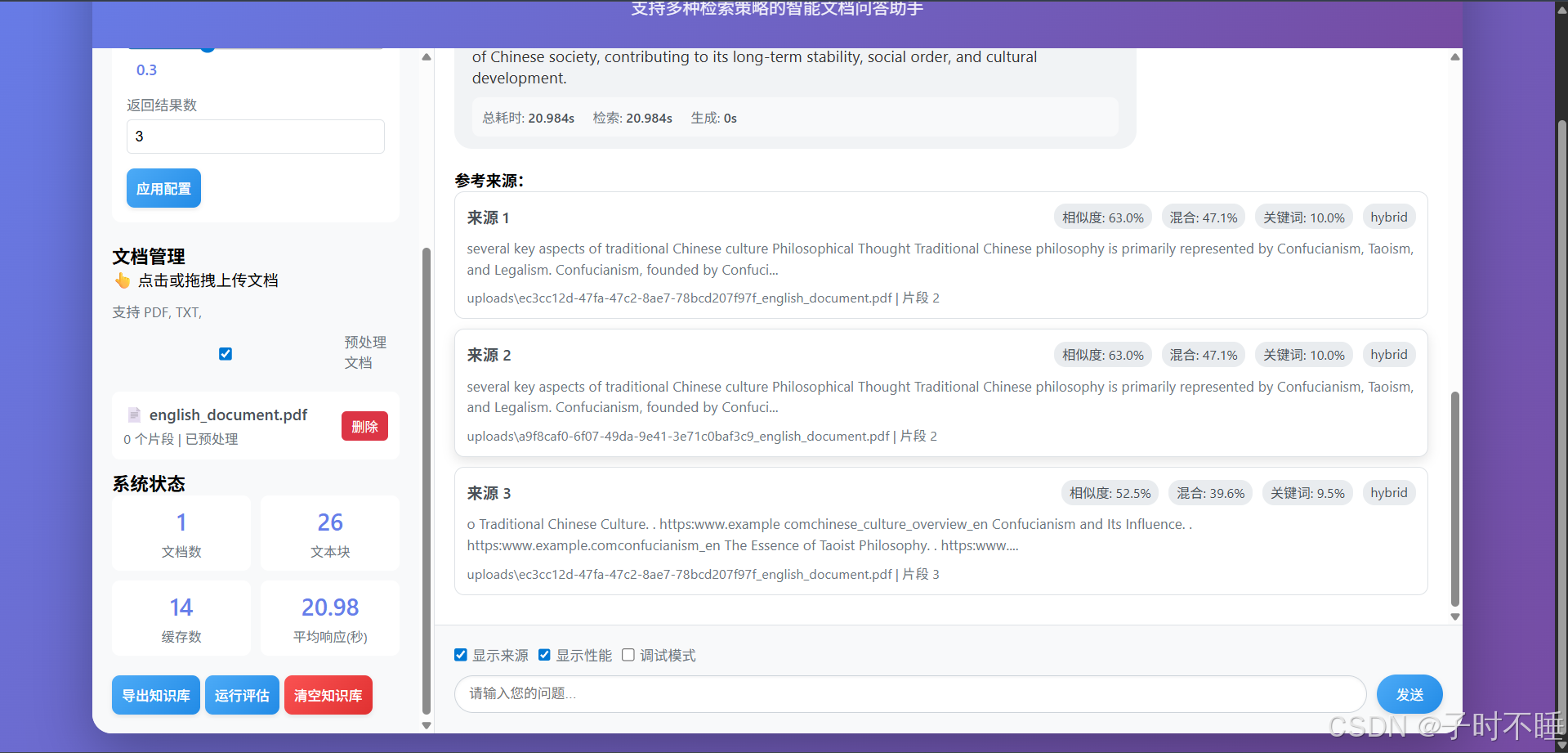
每一个由LLM生成的答案,都会附带详细的引用来源。你可以清晰地看到:
- 答案依据了哪些原文片段。
- 每个片段与你的问题的相关度分数。
- 它们是由哪种检索策略(向量/混合)找到的。
这种透明度建立起了用户对系统回答的信任。
3. 为开发者和学习者设计:高度模块化与可配置
我深知每个人的需求都不同。因此,我将整个系统设计得高度模块化和可配置。无论是Embedding模型、LLM模型,还是文本分块的chunk_size,甚至是检索器的参数,你都可以通过config.yaml文件或Web UI轻松修改,而无需改动核心代码。
你可以轻易地将任何模块(如检索器、LLM处理器)替换成你自己的实现,把它当作一个学习和实验RAG技术的绝佳平台。
快速开始
让它在你的本地运行起来非常简单,只需要三步:
# 1. 克隆仓库
git clone [你的GitHub仓库链接]
cd [你的项目目录]# 2. 安装依赖
pip install -r requirements.txt# 3. 启动!
python run.py
然后打开浏览器,访问 http://127.0.0.1:5000,你的专属知识大脑就准备就绪了。
未来的路与你的贡献
这个项目只是一个开始。我还有很多想实现的想法,比如:
- 引入更先进的Re-ranking模型过滤检索噪音。
- 集成知识图谱,实现更高阶的推理问答。
- 建立一套更完善的自动化评估体系。
这是一个社区驱动的开源项目,我非常欢迎任何形式的贡献!无论是一个Star⭐️来鼓励我,一个Issue来报告问题或提出建议,还是一个Pull Request来直接贡献代码,都将是对这个项目巨大的帮助。
➡️ 再次附上项目链接:Tiny_RAG和RAG_Mini
感谢你的阅读,期待在GitHub上与你相遇!