Redis 持久化策略
目录
1. 什么是持久化
2.RDB 策略 (定期备份)
2.1 手动触发
2.1.1 save
2.1.2 bgsave
2.2 自动触发
2.3 dump.rdb 文件
2.4 RDB 策略的优缺点
3.AOF 策略
1. 开启 aof
2. aof 的工作流程
3. aof 缓冲区的 同步文件策略
4. aof 的重写机制
4.1 手动触发
4.2 自动触发
4.3 aof 重写机制的执行流程
5. 混合持久化
1. 什么是持久化
我们知道 redis 是一个内存数据库, 把数据存储到内存中的, 然而内存中的数据时不持久的, 想要能够做到持久, 就需要让 redis 把数据存储到硬盘上
为了保证速度快, 数据肯定还是得在内存中. 但是为了持久, 数据还得想办法存储在硬盘上
Redis 决定, 内存中也存数据. 硬盘上也存数据这样的两份数据, 理论上是完全相同的. 实际上可能存在一个小的概率有差异~~ 取决于咱们具体怎么进行持久化
当要插入一个新的数据的时候, 就需要把这个数据, 同时写入内存和硬盘(具体怎么写是不同的策略)~
当要查询某个数据的时候, 直接从内存中读取
硬盘的数据只是在 redis 重启的时, 用来恢复内存中的数据的
代价就是消耗了更多的空间, 同一份数据, 存储了两遍(但是毕竟硬盘比较便宜~~, 这样的开销并不会带来太多的成本~~)
2.RDB 策略 (定期备份)
RDB 策略就是定期的将 redis 内存中所有的数据都写入硬盘中, 生成一个 "快照", 后面 redis 重启就会根据这个快照将内存中的数据恢复成原来的样子
2.1 手动触发
2.1.1 save
执行 save 命令的时候, redis 就会全力以赴的进行 "快照生成" 操作, 此时就会阻塞 redis 的其他客户端的命令~ 导致类似 keys * 的后果 (一般不建议使用 save)
2.1.2 bgsave
bg -> bacegroung, 不会影响 redis 服务端处理其他客户端的请求和命令 (这里看上去 redis 是使用了多线程的方式来实现的, 但是 redis 是一个单线程模型, 所以这里 redis 使用的是多进程来完成并发编程的)
bgsave 的工作流程 :
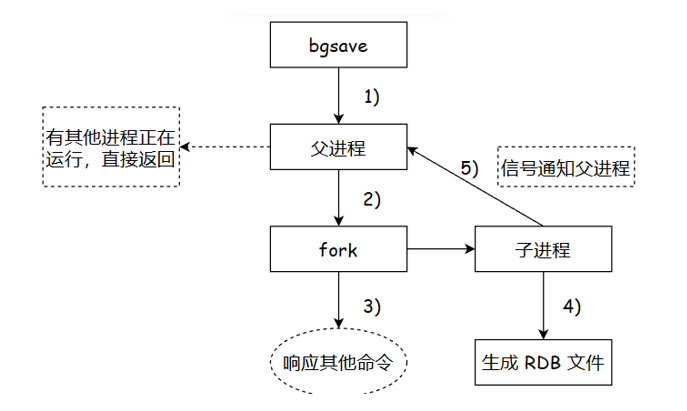
1. 当我们执行 bgsave 命令后, 父进程会查看是否已经存在其他正在执行这个指令的子进程, 若有, 直接把当前的 bgsave 返回
2. 如果没有, 就会通过 fork 这样的系统调用来创建出一个子进程
fork 是 linux 系统提供的一个创建子进程的 api (系统调用), 如果是其他系统, 比如 windows, 创建子进程就不是 fork(CreateProcess)
fork 创建子进程, 简单粗暴, 就是直接把当前的进程 (父进程) 复制一份, 作为子进程, 复制完成了, 就是两个独立的进程, 就各自执行各自的了
如果当前, redis 服务器中存储的数据特别多, 内存消耗特别大, 此时进行复制操作, 是否会有很大的性能开销?
不会很大, 因为在 fork 进行内存拷贝的时候, 不是简单无脑的直接把所有的数据都拷贝一遍, 而是 "写时拷贝" 的机制来完成的
如果子进程里的这个内存数据, 和父进程的内存数据完全一样了, 此时就不会触发真正的拷贝动作.(而是爷俩其实用一份内存数据)
但是, 其实这俩进程的内存空间, 应该是各自独立的, 一旦某一方针对这个内存数据做了修改就会立即触发真正的物理内存上的数据拷贝
在进行 bgsave 这个场景中, 绝大部分的内存数据, 是不需要改变的(整体来说这个过程执行的还挺快的这个短时间内, 父进程中不会有大批的内存数据的变化), 因此, 子进程的 "写时拷贝" 并不会触发很多次, 也就保证了整体的 "拷贝时间" 是是可控的, 高效的
3. 子进程负责进行写文件, 生成快照(.rdb 文件), 父进程继续接收客户端的请求, 继续正常的提供服务
由于 .rdb 文件只有一份, 那么在 子进程生成快照时, 就会将快照数据保存到一个临时文件中, 当快照生成完毕后, 就会删除之前的 .rdb 文件, 然后将这个临时文件改为 dump.rdb
4. 子进程完成整体的持久化过程之后, 就会通知父进程, 干完了, 父进程就会更新一些统计信息, 子进程就可以结束销毁了
2.2 自动触发
1. 在 redis 配置文件中, 设置一些, 让 redis 每隔 多长时间/每产生多少次修改就会触发, 从而备份数据
redis 生成的 rdb 文件, 是存放在 redis 的工作目录中的, 也是在 redis 配置文件中进行设置的

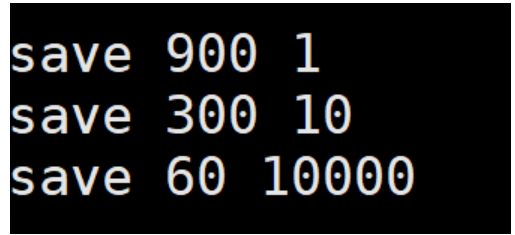
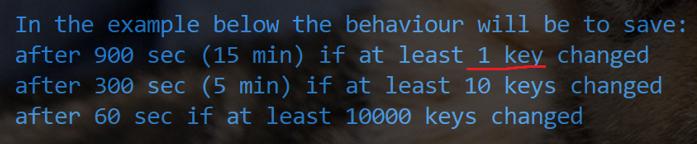
2. 因为生成一次 rdb 快照, 这个成本是一个比较高的成本, 不能让这个操作执行的太频繁, 不然当数据较大的时候, 容易造成 redis 卡死
3. 通过 shutdown 关闭 redis 也会自动触发快照(正常退出), 但是通过 kill, 主机掉电...., 不正常关闭就不会触发快照, 这个时候的部分数据就会没有被写入 .rdb文件中
4.redis 进行主从复制的时候, 主节点也会自动生成 rdb 快照, 然后把 rdb 快照文件内容传输给从节点
2.3 dump.rdb 文件
dump.rdb 文件始终只有一份
dump.rdb 文件是经过压缩后的二进制文件
dump.rdb 文件可能会损坏, 这个时候可以使用 redis 中的工具进行修复
检查工具 : ![]()
2.4 RDB 策略的优缺点
RDB 是一个紧凑压缩的二进制文件, 代表 redis 在某个时间点上的数据快照, 非常适用于备份全量复制等场景
redis 加载 RDB 恢复数据远远快于 AOF 的方式
RDB 方式数据没办法做到实时持久化 / 秒级持久化, 因为 bgsave 每次运行都要执行 fork 创建子进程, 属于重量级操作, 频繁执行成本过高
RDB 文件使用特定二进制格式保存, redis 版本演进过程中有多个 RDB 版本,兼容性可能有风险, 老版本的 redis 的 rdb 文件,放到新版本的 redis 中不一定能识别
不能实时的持久化保存数据, 当子进程生成 .rdb 文件时, 此时父进程会继续收到新的请求, 导致数据与之前的不一致, 但是此时的 .rdb 文件不会将新的数据也写进去, 那么此时 .rdb 文件中的数据就不是最新数据
3.AOF 策略
类似于 mysql 的 binlog, 就会把用户的每个操作, 都记录到文件中, 当 redis 重新启动的时候, 就会读取这个 aof 文件中的内容, 用来恢复数据. aof 默认一般是关闭状态. 当开启 aof 的时候, rdb 就不生效了, 启动的时候就不再读取 rdb 文内容了
1. 开启 aof

2. aof 的工作流程
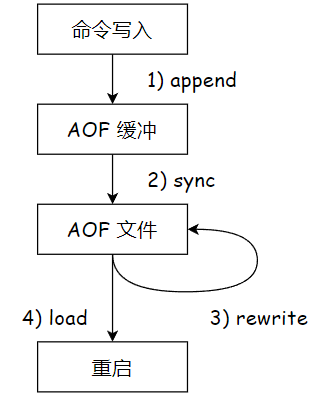
1. aof 机制并非是直接让工作线程把数据写入硬盘, 而是先写入一个内存中的缓冲区, 积累一波之后, 在统一写入硬盘
大大降低了, 写入硬盘的次数
2. 硬盘上读写数据, 顺序读写的数独是比较快的(还是比内存要慢很多), 随机访问则速度是比较慢的, aof 是每次把新的操作写入到原有的文件末尾, 属于顺序写入
3. aof 缓冲区的 同步文件策略
- always : 只要执行了一条指令, 就将这条指令写入硬盘
- everysec : redis 默认策略, 以 1s 为刷新区间, 每隔 1s 就会将新指令写入硬盘
- no : 操作系统自行刷新缓冲区

4. aof 的重写机制
aof 文件持续增长, 体积越来越大, 会影响到, redis 下次的启动的启动时间(redis 启动的时候要读取 aof 文件的内容)

因此, redis 就存在一个机制, 能够针对 aof 文件进行整理操作. 这个整理就是能够剔除其中的冗余操作, 并且合并一些操作, 达到给 aof 文件瘦身这样的效果.
4.1 手动触发
调用 bgrewriteaof 命令
4.2 自动触发
根据 auto-aof-rewrite-min-size 和 auto-aof-rewrite-percentage 参数确定自动触发时机
- auto-aof-rewrite-min-size:表示触发重写时 AOF 的最小文件大小, 默认为64MB
- auto-aof-rewrite-percentage:代表当前 AOF 占用大小相比较上次重写时增加的比例
4.3 aof 重写机制的执行流程
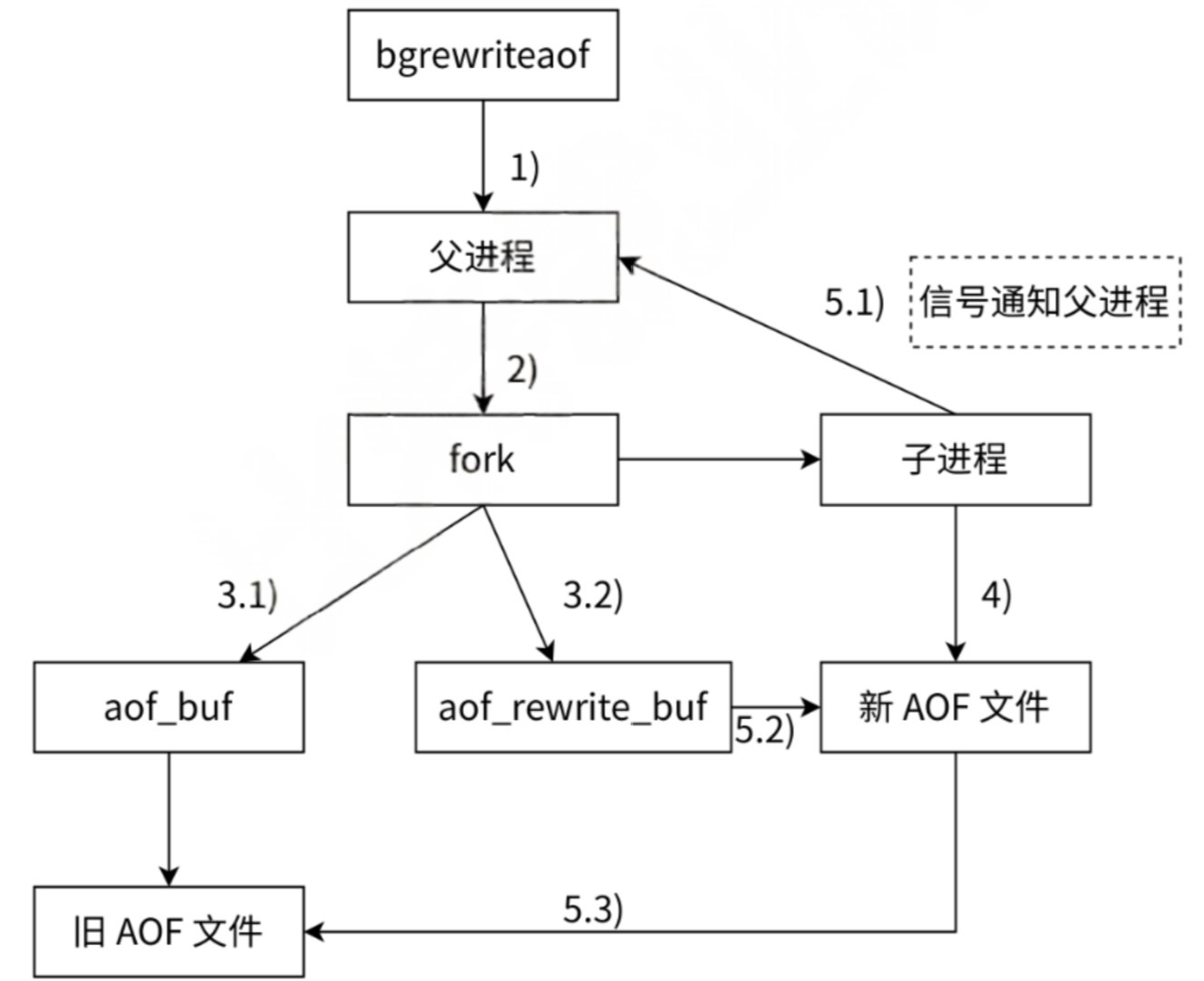
1. 通过 fork创建子进程
2. 父进程负责接收请求, 子进程负责对 aof 文件进行重写
子进程只需要将内存中的数据获取出来, 以 aof 的格式写入到一个新的 aof 文件中
此处子进程写数据的过程, 非常类似于 RDB 生成一个镜像快照
只不过 RDB 这里是按照二进制的方式来生成的
AOF 重写, 则是按照 AOF 这里要求的文本格式来生成的.
子进程写新 aof 文件的同时, 父进程仍然在不停的接收客户端的新的请求. 父进程还是会写把这些请求产生的 AOF 数据先写入到缓冲区, 再刷新到原有的 AOF 文件里
在创建子进程的一瞬间, 子进程就继承了当前父进程的内存状态, 因此, 子进程里的内存数据是父进程 fork 之前的状态 fork 之后, 新来的请求, 对内存造成的修改, 是子进程不知道的. 此时, 父进程这里又准备了一个 aof_rewrite_buf 缓冲区, 专门放 fork 之后收到的数据
子进程这边, 把 aof 数据写完之后, 会通过信号通知一下父进程, 父进程再把 aof_rewrite_buf 缓冲区中的内容也写入到新AOF 文件里, 就可以用新的 AOF 文件代替旧的 AOF 文件了
如果, 在执行 bgrewriteaof 的时候, 当前 redis 已经正在进行 aof重写了, 会咋样呢?
此时, 不会再次执行 aof 重写. 直接返回了
如果, 在执行 bgrewriteaof 的时候, 发现当前 redis 在生成 rdb 文件的快照, 会咋样呢?
此时, aof 重写操作就会等待, 等待 rdb 快照生成完毕之后, 再进行执行 aof 重写
rdb 对于 fork 之后的新数据, 就直接置之不理了. aof 则对于 fork 之后的新数据, 采取了aof_rewrite_buf 缓冲区的方式来处理
父进程 fork 完毕之后, 就已经让子进程写新的 aof 文件了. 并且随着时间的推移, 子进程很快就写完了新的文件, 要让新的 aof 文件代替旧的. 父进程此时还在继续写这个即将消亡的旧的 aof 文件是否还有意义??[不能不写!]
因为考虑到极端情况, 假设在重写过程中, 重写了一半了, 服务器挂了, 子进程内存的数据就会丢失, 新的 aof 文件内容还不完整所以如果父进程不坚持写旧 aof 文件, 重启就没办法保证数据的完整性了
5. 混合持久化
由于AOF 文件中的数据是以文本形式存储的, 那么在启动 Redis 时读取 AOF 文件中的内容所消耗的时间就会变多, 于是可以采取使用 RDB 文件存储方式, 即使用二进制存储数据, 那么就会加快文件的读取速度
在 Redis 的配置文件中, 若将 aof_use_rdb_preamble 设置为 yes, 就表示以二进制形式存储数据. Redis 默认 aof_use_rdb_preamble 为 yes