【机器学习深度学习】模态与多模态的概念
目录
前言
一、什么是模态?
二、多模态:信息的融合与协作
多模态的类型
三、多模态的三种典型形式
核心模态:3V框架
四、模态研究的核心领域:“3V”
五、为什么多模态很重要?
六、现实世界中的多模态应用
智能医疗诊断
内容审核与安全
教育技术
智能零售
总结

前言
在人工智能的语境中,模态(Modality) 是一个核心概念。它指的是 表达或感知事物的方式,也就是信息的来源或形式。理解“模态”与“多模态”,就像理解人类如何通过不同的感官去感知世界,是理解大模型能力的重要前提。本文将围绕模态的概念、多模态的分类,以及其在人工智能中的研究方向进行解读。
我们生活在一个信息丰富的世界里。清晨醒来,你看到阳光透过窗帘(视觉),听到鸟儿的鸣叫(听觉),闻到咖啡的香气(嗅觉),感受床铺的柔软(触觉)——这一切都是你通过不同方式感知世界的结果。每一种感知方式,在人工智能领域都有一个对应的概念:模态。
那么,AI是如何像人类一样,通过多种"感官"来理解和处理信息的呢?本文将带您深入浅出地了解模态与多模态的核心概念,以及它们如何推动人工智能技术的发展。
一、什么是模态?
模态可以理解为信息的载体和表现形式。例如:
视觉模态:人通过眼睛获取图像和视频。
听觉模态:人通过耳朵获取语音和声音。
触觉模态:人通过皮肤感受压力与温度。
文本模态:书写语言所承载的知识与语义。
传感器模态:雷达、红外、加速度计等设备获取的信号。
更细粒度地说:
-
同一媒介下可以有不同模态,比如中文与英文是不同的文本模态。
-
同一类数据在不同条件下采集,也可以看作不同模态,例如在白天和夜晚拍摄的图像。
因此,模态的本质在于:同一事物可通过不同的感知或表达形式被捕捉和理解。
模态是表达或感知事物的一种方式,简单说,就是信息的“来源”或“形式”。它类似人类感官:视觉(看)、听觉(听)、触觉(摸),每种感官是一个模态。在AI中,模态更广:
- 媒介:文本(文章)、语音(音频)、图像(照片)、视频。
- 传感器:雷达(电磁波)、红外(热信号)、加速度计(运动)。
模态比“多媒体”更细腻。例如,同一媒介(文本)下,中文和英文可算两种模态;同一图像数据,室内和户外采集也算不同模态。这种细粒度让AI更灵活地处理复杂信息。
一句话总结:模态是信息的一个“视角”,像人类感官一样捕捉世界。
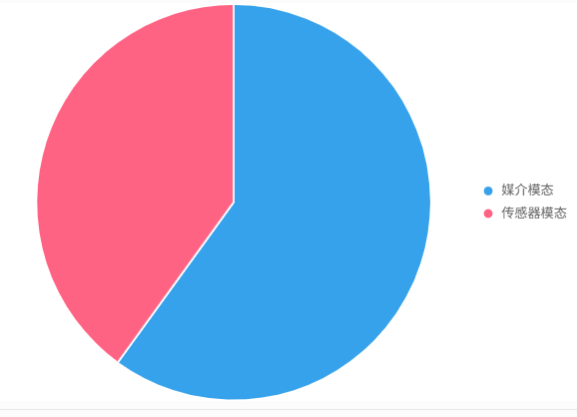
解释:图表显示模态主要分为媒介模态(如文本、图像)和传感器模态(如雷达、红外),前者在AI应用中占比更高,因其贴近人类交互。
二、多模态:信息的融合与协作
多模态(Multimodal),顾名思义,就是来自多个模态的信息被结合起来,以便更全面地理解和表达事物。
多模态的类型
▲同质性模态
不同来源的同类数据。
例子:两台相机从不同角度拍摄的同一场景。
▲异质性模态
不同媒介的数据结合。
例子:一张图像 + 与其对应的文字描述。
▲跨结构模态
数据结构与表现形式完全不同。
例子:用公式、函数图、解释性文本共同描述一个数学概念;用知识图谱和词向量共同表达语义。
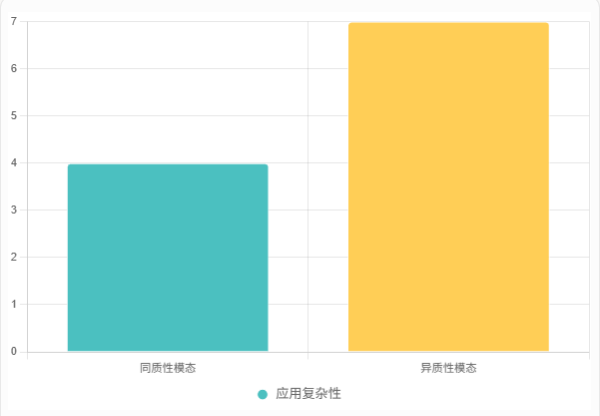
对比同质性和异质性模态的特点:
解释:异质性模态(如图像+文本)因数据形式差异,融合复杂性更高,但潜力更大。
#
三、多模态的三种典型形式
1.同一对象的多媒体描述
-
互联网中,一个商品可能同时有视频介绍、图片展示、语音解说和文字说明。
2.不同传感器对同一对象的采集
-
医学影像学:CT、B 超、核磁共振对同一病灶的不同视角呈现。
-
物联网:雷达、红外等传感器检测同一目标的不同特征。
3.不同符号系统对同一语义的表达
-
数学领域:用公式、图像和文字三种方式解释同一个概念。
-
NLP 语义建模:用词向量、知识图谱和文本描述表达相同语义。
以下图表展示三种形式在行业的应用比例:
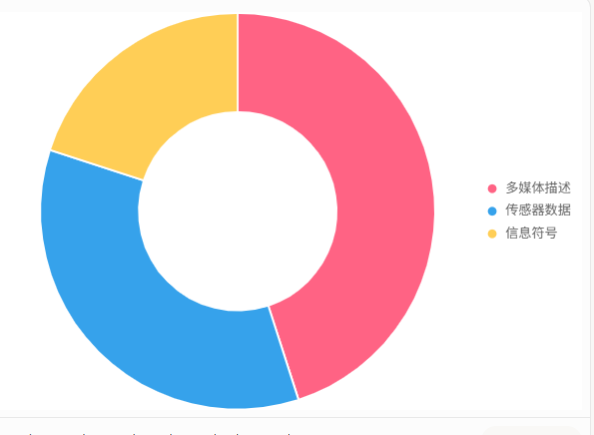
解释:多媒体描述(如社交媒体分析)应用最广,传感器数据(如医疗、驾驶)次之,信息符号(教育)因复杂性较高占比稍低。
核心模态:3V框架
四、模态研究的核心领域:“3V”
人工智能中常见的三大模态,也被称为 3V:
-
Verbal(文本)
-
Vocal(语音)
-
Visual(视觉)
这三类模态覆盖了人类大部分日常信息来源,也是多模态研究的重点。
五、为什么多模态很重要?
人类对世界的理解从来不是单一模态的。比如,我们观看一部电影时,会同时处理视觉(画面)、听觉(对白、音乐)和语义(剧情逻辑)。AI 如果仅依赖单一模态,很难达到人类水平的理解和表达。
多模态的价值在于:
信息互补:不同模态提供的视角能增强理解的准确性。
增强泛化能力:避免模型过度依赖单一模态而产生偏差。
更自然的人机交互:支持“看图提问”、“语音对话”、“图文混合生成”。
六、现实世界中的多模态应用
智能医疗诊断
结合医学影像(CT、MRI)、患者病历文本和实验室数据,提供更全面的诊断建议。
内容审核与安全
同时分析图像的视觉内容、文本的描述和音频的语音内容,精准识别违规内容。
教育技术
在线学习平台同时分析学生的文本回答、语音表达和面部表情,评估理解程度和投入度。
智能零售
顾客可以通过多种方式与系统交互:语音查询、手势选择商品、面部识别支付,创造无缝购物体验。
总结
简而言之:
模态 是信息的来源与表达形式。
多模态 是不同模态的协同,帮助 AI 更全面地理解与生成信息。
如果说 单一模态 AI 是“单感官智能”,那么 多模态 AI 就是“多感官智能”,更接近人类的认知方式,也因此成为当前大模型发展的重要方向。