【大语言模型 16】Transformer三种架构深度对比:选择最适合你的模型架构
【大语言模型 16】Transformer三种架构深度对比:选择最适合你的模型架构
关键词:Transformer架构,Encoder-Only,Decoder-Only,Encoder-Decoder,BERT,GPT,T5,模型选择,计算复杂度,架构设计
摘要:本文深入解析Transformer的三种主流架构:Encoder-Only、Decoder-Only和Encoder-Decoder。从技术原理、计算复杂度、适用场景等多个维度进行全面对比,帮助开发者理解每种架构的优势特点,并提供实用的架构选择指南。无论你是刚接触大语言模型还是正在优化现有系统,本文都将为你的架构决策提供科学依据。
文章目录
- 【大语言模型 16】Transformer三种架构深度对比:选择最适合你的模型架构
- 引言:为什么架构选择如此重要?
- 一、Encoder-Only架构:理解之王
- 1.1 核心设计理念
- 1.2 技术实现细节
- 1.3 适用场景分析
- 1.4 性能特点
- 二、Decoder-Only架构:生成之星
- 2.1 设计哲学转变
- 2.2 技术实现解析
- 2.3 现代大模型的主流选择
- 2.4 应用场景广谱
- 三、Encoder-Decoder架构:转换专家
- 3.1 双塔设计理念
- 3.2 技术实现要点
- 3.3 独特优势分析
- 3.4 应用领域
- 四、计算复杂度深度分析
- 4.1 理论复杂度对比
- 4.2 实际性能测试
- 4.3 优化策略
- 五、架构选择实战指南
- 5.1 决策矩阵
- 5.2 具体场景分析
- 5.3 架构演进趋势
- 5.4 实际部署考虑
- 六、未来发展展望
- 6.1 技术演进方向
- 6.2 应用场景扩展
- 6.3 选择策略进化
- 总结与实践建议
- 核心要点回顾
- 实践决策框架
- 最终建议
- 参考资料
引言:为什么架构选择如此重要?
想象一下,你正在设计一个房子。是选择开放式的大平层、传统的多层结构,还是带阁楼的复式设计?每种设计都有其独特的优势和适用场景。Transformer架构的选择也是如此——不同的架构设计决定了模型的能力边界、计算效率和应用方向。
在大语言模型的发展历程中,我们见证了三种主要架构的崛起:
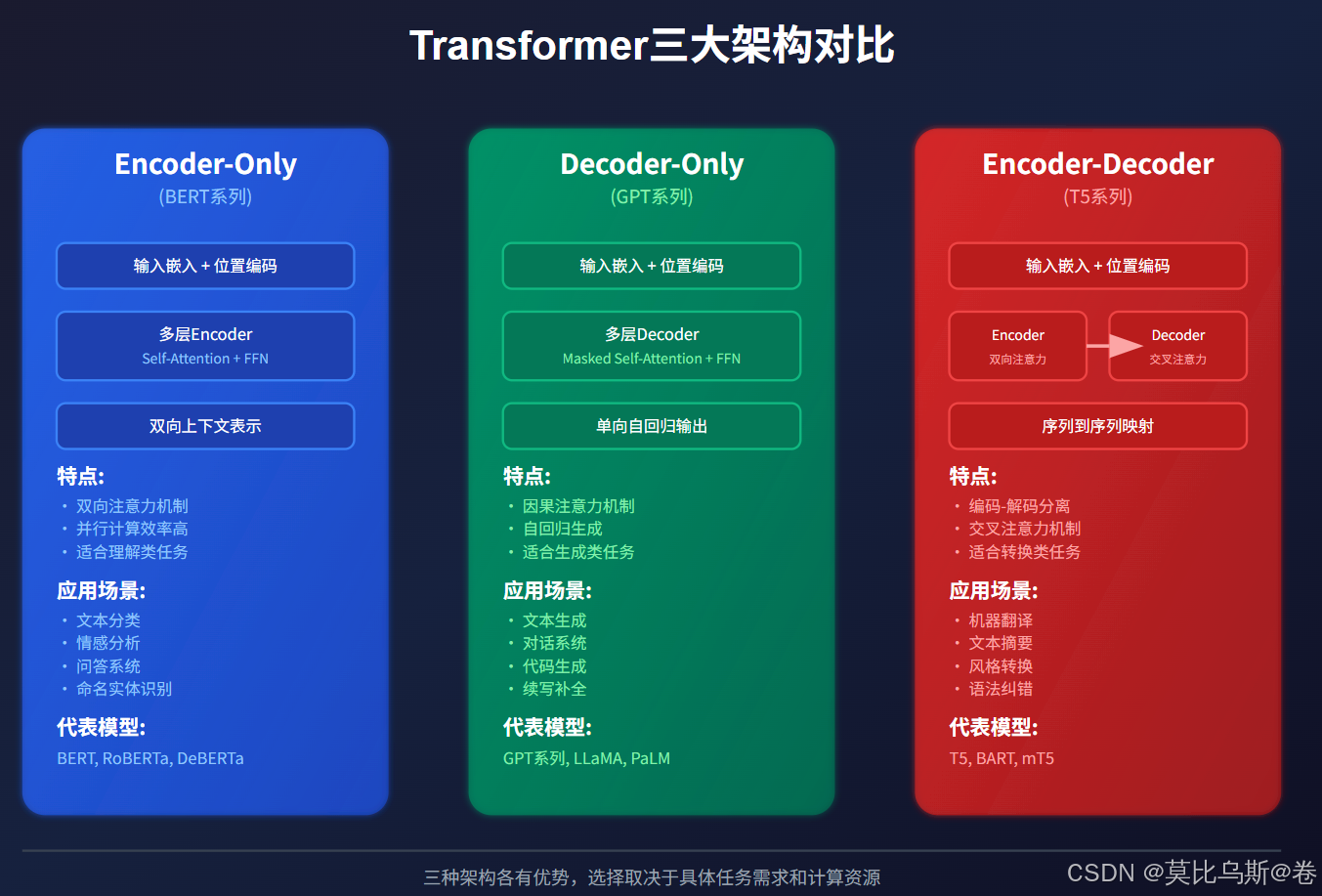
- Encoder-Only:以BERT为代表,专注于理解和表示学习
- Decoder-Only:以GPT为代表,在生成任务中大放异彩
- Encoder-Decoder:以T5为代表,擅长序列到序列的转换任务
但问题来了:面对具体的业务需求,我们该如何选择?每种架构背后的设计哲学是什么?它们的性能特点有何差异?
今天,我们将从技术原理出发,用通俗易懂的方式深入剖析这三种架构,帮你做出明智的选择。
一、Encoder-Only架构:理解之王
1.1 核心设计理念
Encoder-Only架构的设计哲学很简单:专注于理解。就像一个专业的文学评论家,它能够从多个角度同时审视文本,捕捉其中的细微含义。
核心特点:
- 双向注意力机制:能够同时关注前文和后文的信息
- 并行计算友好:所有位置可以同时计算,训练效率高
- 表示学习专家:擅长生成高质量的文本表示
1.2 技术实现细节
让我们用一个具体的例子来理解Encoder-Only的工作原理:
# 简化的Encoder-Only注意力机制
import torch
import torch.nn as nnclass EncoderOnlyAttention(nn.Module):def __init__(self, d_model, num_heads):super().__init__()self.d_model = d_modelself.num_heads = num_headsself.d_k = d_model // num_headsself.w_q = nn.Linear(d_model, d_model)self.w_k = nn.Linear(d_model, d_model)self.w_v = nn.Linear(d_model, d_model)self.w_o = nn.Linear(d_model, d_model)def forward(self, x, mask=None):batch_size, seq_len, d_model = x.shape# 计算Q, K, VQ = self.w_q(x).view(batch_size, seq_len, self.num_heads, self.d_k)K = self.w_k(x).view(batch_size, seq_len, self.num_heads, self.d_k)V = self.w_v(x).view(batch_size, seq_len, self.num_heads, self.d_k)# 重塑为 (batch_size, num_heads, seq_len, d_k)Q = Q.transpose(1, 2)K = K.transpose(1, 2)V = V.transpose(1, 2)# 计算注意力分数 (关键:无因果掩码,可以看到所有位置)scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)if mask is not None:scores.masked_fill_(mask == 0, -1e9)# 双向注意力:每个位置都能关注到所有其他位置attention_weights = torch.softmax(scores, dim=-1)# 应用注意力权重context = torch.matmul(attention_weights, V)# 合并多头输出context = context.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)return self.w_o(context)
1.3 适用场景分析
Encoder-Only架构在以下场景中表现优异:
1. 文本分类任务
# 文本分类示例
class TextClassifier(nn.Module):def __init__(self, encoder, num_classes):super().__init__()self.encoder = encoder # BERT等Encoder-Only模型self.classifier = nn.Linear(encoder.config.hidden_size, num_classes)def forward(self, input_ids, attention_mask):# 获取[CLS]标记的表示outputs = self.encoder(input_ids, attention_mask)pooled_output = outputs.pooler_output # [CLS]位置的表示# 分类预测logits = self.classifier(pooled_output)return logits
2. 问答系统
- 能够理解问题和上下文的复杂关系
- 通过双向注意力捕捉关键信息
- 在阅读理解任务中表现出色
3. 语义相似度计算
- 生成高质量的句子表示
- 支持语义检索和匹配
- 广泛应用于搜索引擎和推荐系统
1.4 性能特点
优势:
- 训练效率高:并行计算,训练速度快
- 理解能力强:双向上下文,语义理解深入
- 迁移性好:预训练模型可用于多种下游任务
劣势:
- 生成能力弱:不适合文本生成任务
- 固定长度限制:输入序列长度受限
- 推理模式单一:主要用于判别式任务
二、Decoder-Only架构:生成之星
2.1 设计哲学转变
如果说Encoder-Only是文学评论家,那么Decoder-Only就是创作家。它的设计核心是因果性和自回归生成。
核心特点:
- 因果注意力机制:只能看到当前位置之前的信息
- 自回归生成:一个词一个词地生成文本
- 通用性强:既能理解又能生成
2.2 技术实现解析
让我们看看Decoder-Only架构的关键实现:
class DecoderOnlyAttention(nn.Module):def __init__(self, d_model, num_heads):super().__init__()self.d_model = d_modelself.num_heads = num_headsself.d_k = d_model // num_headsself.w_q = nn.Linear(d_model, d_model)self.w_k = nn.Linear(d_model, d_model)self.w_v = nn.Linear(d_model, d_model)self.w_o = nn.Linear(d_model, d_model)def create_causal_mask(self, seq_len):"""创建因果掩码:下三角矩阵"""mask = torch.tril(torch.ones(seq_len, seq_len))return mask.unsqueeze(0).unsqueeze(0) # (1, 1, seq_len, seq_len)def forward(self, x):batch_size, seq_len, d_model = x.shape# 计算Q, K, VQ = self.w_q(x).view(batch_size, seq_len, self.num_heads, self.d_k)K = self.w_k(x).view(batch_size, seq_len, self.num_heads, self.d_k)V = self.w_v(x).view(batch_size, seq_len, self.num_heads, self.d_k)Q = Q.transpose(1, 2)K = K.transpose(1, 2)V = V.transpose(1, 2)# 计算注意力分数scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)# 应用因果掩码(关键差异)causal_mask = self.create_causal_mask(seq_len)scores.masked_fill_(causal_mask == 0, -1e9)attention_weights = torch.softmax(scores, dim=-1)context = torch.matmul(attention_weights, V)context = context.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)return self.w_o(context)# 自回归生成示例
class AutoregressiveGenerator:def __init__(self, model, tokenizer):self.model = modelself.tokenizer = tokenizerdef generate(self, prompt, max_length=100, temperature=0.8):"""自回归文本生成"""input_ids = self.tokenizer.encode(prompt, return_tensors='pt')for _ in range(max_length):# 模型预测下一个tokenwith torch.no_grad():outputs = self.model(input_ids)logits = outputs.logits[:, -1, :] # 最后一个位置的logits# 应用温度参数logits = logits / temperatureprobs = torch.softmax(logits, dim=-1)# 采样下一个tokennext_token = torch.multinomial(probs, num_samples=1)# 添加到序列中input_ids = torch.cat([input_ids, next_token], dim=1)# 检查是否生成结束符if next_token.item() == self.tokenizer.eos_token_id:breakreturn self.tokenizer.decode(input_ids[0], skip_special_tokens=True)
2.3 现代大模型的主流选择
Decoder-Only架构在大模型时代的成功并非偶然:
1. 统一的任务处理范式
# 统一的提示格式处理不同任务
def unified_prompt_format(task_type, input_text, instruction=""):if task_type == "classification":return f"分类以下文本:{input_text}\n类别:"elif task_type == "summarization":return f"请总结以下文本:{input_text}\n摘要:"elif task_type == "qa":return f"问题:{input_text}\n答案:"elif task_type == "translation":return f"将以下文本翻译成英文:{input_text}\n翻译:"else:return f"{instruction}\n{input_text}\n"
2. 扩展性优势
- 参数规模可扩展:从GPT-1的117M到GPT-4的数万亿参数
- 计算可并行:训练时支持大规模并行计算
- 能力涌现:随着规模增大,涌现出新的能力
2.4 应用场景广谱
Decoder-Only架构适用于:
生成类任务:
- 创意写作、代码生成、对话系统
- 内容续写、故事创作
理解类任务:
- 通过Few-shot learning处理分类、抽取等任务
- 指令跟随和复杂推理
多模态任务:
- 结合视觉、语音等多种模态信息
- 统一的多模态理解和生成
三、Encoder-Decoder架构:转换专家
3.1 双塔设计理念
Encoder-Decoder架构采用了"理解-转换-生成"的三段式设计思路,就像一个专业的翻译官:先深度理解源语言,然后在脑海中进行转换,最后用目标语言表达出来。
核心组件:
- Encoder:负责理解和编码输入序列
- Decoder:负责生成和解码输出序列
- Cross-Attention:连接两者的桥梁
3.2 技术实现要点
class EncoderDecoderAttention(nn.Module):def __init__(self, d_model, num_heads):super().__init__()self.d_model = d_modelself.num_heads = num_headsself.d_k = d_model // num_heads# Self-attention层self.self_attention = MultiHeadAttention(d_model, num_heads)# Cross-attention层 (Decoder特有)self.cross_attention = MultiHeadAttention(d_model, num_heads)self.feed_forward = FeedForward(d_model)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)def forward(self, decoder_input, encoder_output, self_attn_mask=None, cross_attn_mask=None):# 1. Decoder自注意力 (带因果掩码)self_attn_out = self.self_attention(decoder_input, decoder_input, decoder_input, self_attn_mask)x = self.norm1(decoder_input + self_attn_out)# 2. 交叉注意力 (关键:Query来自Decoder,Key/Value来自Encoder)cross_attn_out = self.cross_attention(x, encoder_output, encoder_output, cross_attn_mask)x = self.norm2(x + cross_attn_out)# 3. 前馈网络ff_out = self.feed_forward(x)x = self.norm3(x + ff_out)return x# 序列到序列生成示例
class Seq2SeqGenerator:def __init__(self, encoder_decoder_model, tokenizer):self.model = encoder_decoder_modelself.tokenizer = tokenizerdef translate(self, source_text, target_lang="en", max_length=128):"""机器翻译示例"""# 编码输入source_ids = self.tokenizer.encode(source_text, return_tensors='pt', padding=True)# Encoder处理源序列encoder_outputs = self.model.encoder(source_ids)# Decoder自回归生成目标序列decoder_input = torch.tensor([[self.tokenizer.bos_token_id]])for _ in range(max_length):decoder_outputs = self.model.decoder(decoder_input, encoder_hidden_states=encoder_outputs.last_hidden_state)# 预测下一个tokennext_token_logits = decoder_outputs.logits[:, -1, :]next_token = torch.argmax(next_token_logits, dim=-1, keepdim=True)# 添加到序列decoder_input = torch.cat([decoder_input, next_token], dim=1)# 检查结束条件if next_token.item() == self.tokenizer.eos_token_id:breakreturn self.tokenizer.decode(decoder_input[0], skip_special_tokens=True)
3.3 独特优势分析
1. 长度灵活性
- 输入和输出序列长度可以不同
- 适合压缩(摘要)和扩展(详细描述)任务
2. 表示分离
- Encoder专注于理解,Decoder专注于生成
- 各自优化,分工明确
3. 控制性强
- 可以通过Encoder输出控制生成过程
- 支持条件生成和风格控制
3.4 应用领域
机器翻译:
# T5风格的翻译任务
def translation_prompt(source_text, source_lang, target_lang):return f"translate {source_lang} to {target_lang}: {source_text}"# 示例
prompt = translation_prompt("Hello world", "English", "Chinese")
# 输出: "translate English to Chinese: Hello world"
文本摘要:
- 长文档压缩为简洁摘要
- 保持关键信息不丢失
- 支持抽取式和生成式摘要
数据格式转换:
- 结构化数据转换
- 代码语言转换
- 文档格式转换
四、计算复杂度深度分析
4.1 理论复杂度对比
我们来详细分析三种架构的计算开销:
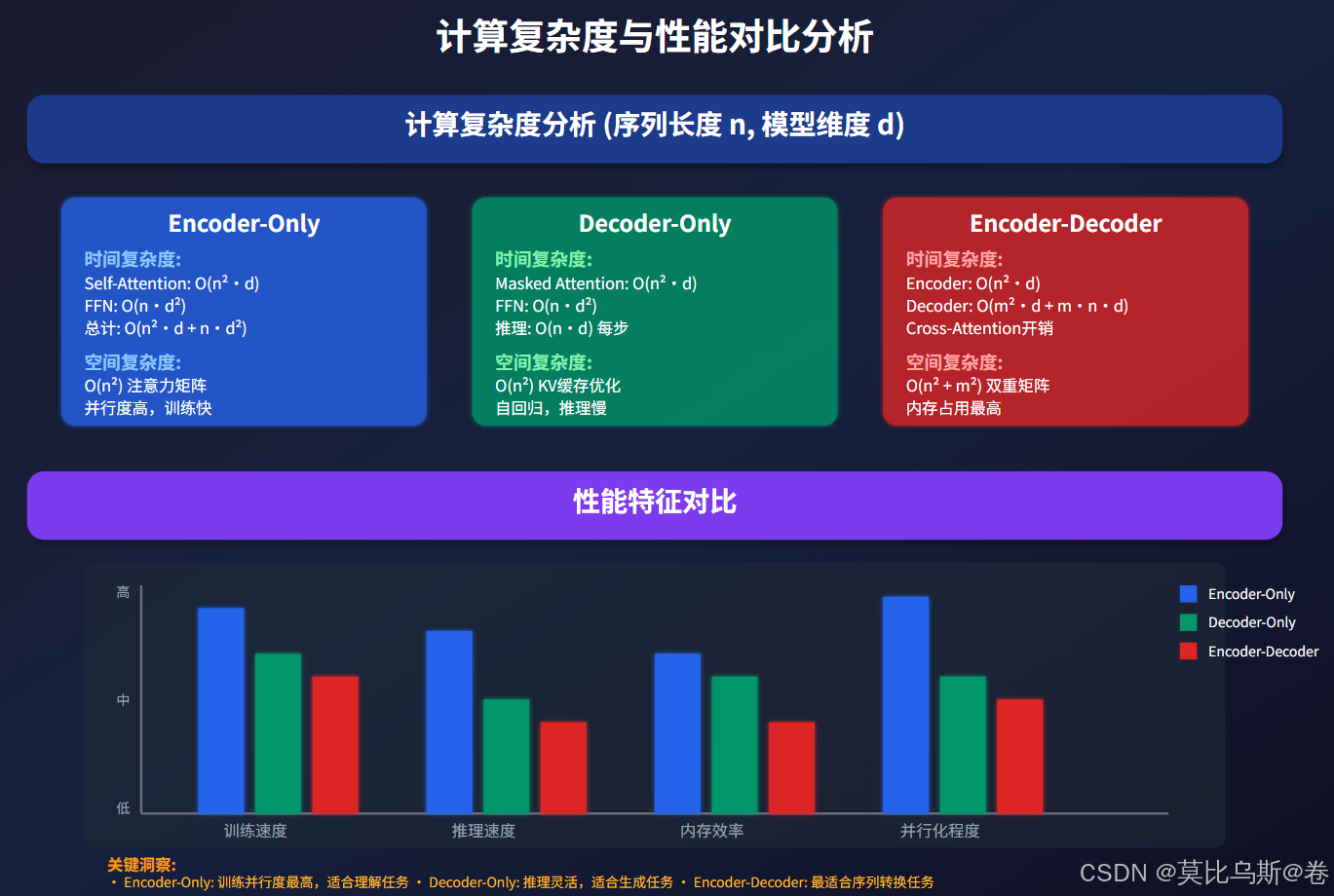
时间复杂度分析:
-
Encoder-Only
- Self-Attention: O(n²·d + n·d²)
- 优势:完全并行,训练快速
- 劣势:推理时需要处理完整序列
-
Decoder-Only
- 训练时: O(n²·d + n·d²)
- 推理时: O(n·d) 每步,但需要n步
- KV缓存优化可显著减少重复计算
-
Encoder-Decoder
- Encoder: O(n²·d)
- Decoder: O(m²·d + m·n·d)
- Cross-attention增加额外开销
空间复杂度分析:
def calculate_memory_usage(seq_len, model_dim, num_heads, batch_size):"""计算不同架构的内存使用"""# 注意力矩阵大小attention_matrix = batch_size * num_heads * seq_len * seq_len# Encoder-Onlyencoder_memory = attention_matrix * 4 # Q,K,V + attention weights# Decoder-Only decoder_memory = attention_matrix * 4kv_cache = batch_size * seq_len * model_dim * 2 # K和V缓存# Encoder-Decoderenc_dec_memory = attention_matrix * 6 # self + cross attentionreturn {"encoder_only": encoder_memory,"decoder_only": decoder_memory + kv_cache,"encoder_decoder": enc_dec_memory}# 示例计算
memory_stats = calculate_memory_usage(seq_len=512, model_dim=768, num_heads=12, batch_size=8
)
print(memory_stats)
4.2 实际性能测试
让我们看看实际场景中的性能表现:
import time
import torchdef benchmark_architectures():"""基准测试三种架构"""seq_len = 512batch_size = 16d_model = 768# 模拟数据input_data = torch.randn(batch_size, seq_len, d_model)# Encoder-Only (BERT风格)encoder_model = EncoderOnlyModel(d_model, num_layers=12)start_time = time.time()for _ in range(100):with torch.no_grad():_ = encoder_model(input_data)encoder_time = time.time() - start_time# Decoder-Only (GPT风格) decoder_model = DecoderOnlyModel(d_model, num_layers=12)start_time = time.time()for _ in range(100):with torch.no_grad():_ = decoder_model(input_data)decoder_time = time.time() - start_time# Encoder-Decoder (T5风格)enc_dec_model = EncoderDecoderModel(d_model, num_layers=6)start_time = time.time()for _ in range(100):with torch.no_grad():encoder_out = enc_dec_model.encoder(input_data)_ = enc_dec_model.decoder(input_data, encoder_out)enc_dec_time = time.time() - start_timereturn {"encoder_only": encoder_time,"decoder_only": decoder_time, "encoder_decoder": enc_dec_time}
4.3 优化策略
通用优化技术:
-
Flash Attention
# Flash Attention减少内存使用 def flash_attention(Q, K, V, block_size=64):"""分块计算注意力,减少内存占用"""seq_len = Q.shape[1]output = torch.zeros_like(Q)for i in range(0, seq_len, block_size):end_i = min(i + block_size, seq_len)Q_block = Q[:, i:end_i]for j in range(0, seq_len, block_size):end_j = min(j + block_size, seq_len)K_block = K[:, j:end_j]V_block = V[:, j:end_j]# 计算局部注意力scores = torch.matmul(Q_block, K_block.transpose(-2, -1))attn_weights = torch.softmax(scores, dim=-1)output[:, i:end_i] += torch.matmul(attn_weights, V_block)return output -
梯度检查点
def checkpoint_wrapper(func):"""梯度检查点包装器"""def wrapper(*args, **kwargs):return torch.utils.checkpoint.checkpoint(func, *args, **kwargs)return wrapper
五、架构选择实战指南
5.1 决策矩阵
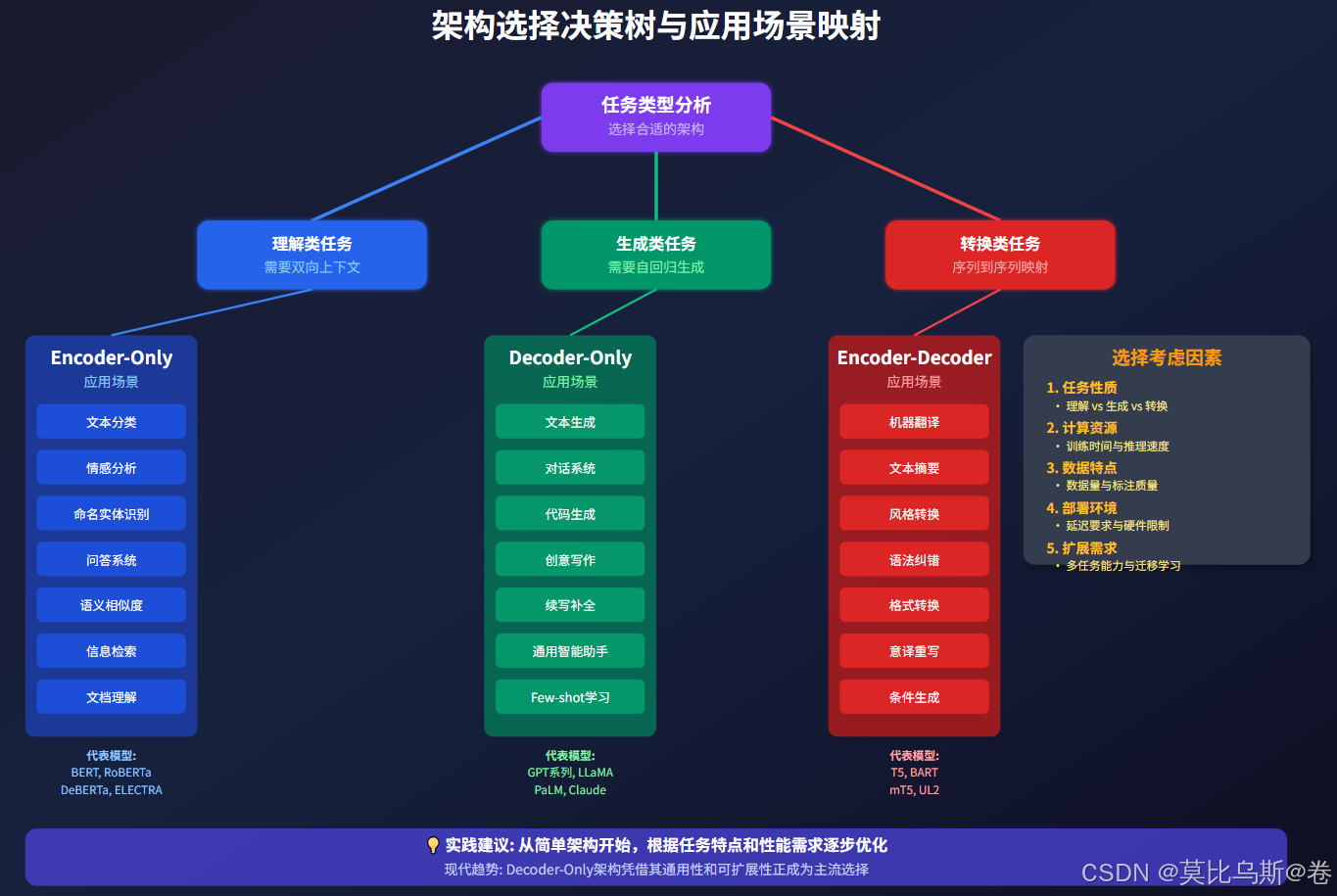
选择架构时,我们需要考虑多个维度:
class ArchitectureSelector:def __init__(self):self.decision_matrix = {'task_type': {'understanding': 'encoder_only','generation': 'decoder_only', 'transformation': 'encoder_decoder'},'compute_resource': {'limited': 'encoder_only','medium': 'decoder_only','abundant': 'encoder_decoder'},'latency_requirement': {'real_time': 'encoder_only','interactive': 'decoder_only','batch': 'encoder_decoder'},'data_availability': {'large_unlabeled': 'decoder_only','labeled_pairs': 'encoder_decoder','task_specific': 'encoder_only'}}def recommend_architecture(self, requirements):"""基于需求推荐架构"""scores = {'encoder_only': 0, 'decoder_only': 0, 'encoder_decoder': 0}for criterion, preference in requirements.items():if criterion in self.decision_matrix:recommended = self.decision_matrix[criterion].get(preference)if recommended:scores[recommended] += 1return max(scores, key=scores.get)# 使用示例
selector = ArchitectureSelector()
requirements = {'task_type': 'generation','compute_resource': 'medium', 'latency_requirement': 'interactive','data_availability': 'large_unlabeled'
}recommended = selector.recommend_architecture(requirements)
print(f"推荐架构: {recommended}")
5.2 具体场景分析
场景1:智能客服系统
# 需求分析
customer_service_requirements = {'primary_task': '对话生成','response_time': '<2秒','context_length': '中等(512 tokens)','customization_need': '高','budget': '中等'
}# 推荐:Decoder-Only
# 理由:生成能力强,响应速度快,支持个性化微调
场景2:文档分析系统
# 需求分析
document_analysis_requirements = {'primary_task': '文档理解+信息抽取','accuracy_priority': '极高','document_length': '长(>1000 tokens)', 'real_time_need': '低','structured_output': '需要'
}# 推荐:Encoder-Only + 微调
# 理由:理解能力强,准确率高,适合结构化输出
场景3:多语言翻译平台
# 需求分析
translation_requirements = {'primary_task': '序列转换', 'language_pairs': '50+','quality_standard': '商业级','input_output_alignment': '严格','domain_adaptation': '需要'
}# 推荐:Encoder-Decoder
# 理由:专为序列转换设计,对齐能力强,领域适应性好
5.3 架构演进趋势
当前趋势观察:
-
Decoder-Only的统治地位
- GPT系列证明了统一架构的威力
- 大规模预训练 + 指令微调成为主流
- 多模态扩展更加自然
-
混合架构探索
class HybridArchitecture(nn.Module):def __init__(self, config):super().__init__()# 结合不同架构优势self.encoder_layers = EncoderLayers(config.encoder_config)self.decoder_layers = DecoderLayers(config.decoder_config)self.mode_switcher = ModeController()def forward(self, input_ids, task_type):if task_type in ['classification', 'extraction']:return self.encoder_layers(input_ids)elif task_type in ['generation', 'dialogue']:return self.decoder_layers(input_ids)else:# 混合模式encoded = self.encoder_layers(input_ids)return self.decoder_layers(encoded) -
效率优化方向
- 稀疏注意力模式
- 检索增强生成(RAG)
- 专家混合(MoE)架构
5.4 实际部署考虑
生产环境检查清单:
def production_readiness_check(architecture_choice, requirements):"""生产就绪性检查"""checklist = {'model_size': '是否适合硬件资源?','inference_speed': '是否满足延迟要求?', 'memory_usage': '内存占用是否可控?','scalability': '是否支持水平扩展?','maintenance': '是否容易维护和更新?'}# 架构特定检查if architecture_choice == 'decoder_only':checklist.update({'kv_cache_optimization': 'KV缓存是否优化?','batch_processing': '批处理是否高效?'})elif architecture_choice == 'encoder_decoder':checklist.update({'cross_attention_efficiency': '交叉注意力是否优化?','beam_search_config': 'Beam搜索参数是否调优?'})return checklist
六、未来发展展望
6.1 技术演进方向
1. 架构融合趋势
随着技术发展,我们看到各种架构优势的融合:
- 统一多任务处理:一个模型处理多种任务类型
- 动态架构切换:根据输入自适应选择最优处理方式
- 模块化设计:可插拔的组件化架构
2. 效率优化突破
# 未来架构优化方向示例
class NextGenTransformer(nn.Module):def __init__(self, config):super().__init__()# 1. 稀疏注意力self.sparse_attention = SparseAttention(config)# 2. 动态深度self.adaptive_depth = AdaptiveDepth(config)# 3. 专家混合self.moe_layers = MoELayers(config)# 4. 检索增强self.retrieval_module = RetrievalAugmentation(config)def forward(self, inputs, task_context):# 根据任务动态调整架构depth = self.adaptive_depth(inputs, task_context)# 稀疏注意力处理attention_out = self.sparse_attention(inputs)# 专家混合处理expert_out = self.moe_layers(attention_out)# 检索增强(如需要)if task_context.requires_retrieval:expert_out = self.retrieval_module(expert_out)return expert_out
6.2 应用场景扩展
多模态统一架构:
- 文本、图像、语音的统一处理
- 跨模态理解和生成
- 具身智能应用
边缘计算适配:
- 轻量化架构设计
- 移动端友好的模型
- 云边协同架构
6.3 选择策略进化
未来的架构选择将更加智能化:
class IntelligentArchitectureSelector:def __init__(self):self.performance_predictor = PerformancePredictor()self.cost_optimizer = CostOptimizer()self.auto_tuner = AutoTuner()def select_optimal_architecture(self, task_spec, constraints):"""智能选择最优架构"""# 1. 性能预测performance_scores = self.performance_predictor.predict(task_spec, ['encoder_only', 'decoder_only', 'encoder_decoder'])# 2. 成本优化cost_analysis = self.cost_optimizer.analyze(constraints)# 3. 自动调优optimal_config = self.auto_tuner.optimize(performance_scores, cost_analysis)return optimal_config
总结与实践建议
经过深入分析,我们可以得出以下核心结论:
核心要点回顾
- Encoder-Only:理解任务的首选,训练高效,适合批量处理
- Decoder-Only:生成任务的王者,通用性强,是当前大模型主流
- Encoder-Decoder:转换任务专家,结构清晰,控制性好
实践决策框架
选择架构时,建议按以下优先级考虑:
-
任务性质 (权重40%)
- 理解类 → Encoder-Only
- 生成类 → Decoder-Only
- 转换类 → Encoder-Decoder
-
资源约束 (权重30%)
- 计算资源、延迟要求、成本预算
-
数据特点 (权重20%)
- 数据量、标注质量、领域特性
-
技术生态 (权重10%)
- 团队技术栈、维护成本、社区支持
最终建议
对于新项目:
- 优先考虑Decoder-Only架构,特别是需要多任务处理的场景
- 如果是特定的理解或转换任务,再考虑专门的架构
对于现有系统:
- 评估当前架构是否满足需求
- 考虑渐进式迁移而非一次性重构
- 重视性能监控和持续优化
记住,没有完美的架构,只有最适合的选择。随着技术发展和需求变化,保持开放的心态,持续评估和优化你的架构选择。
参考资料
- Vaswani, A., et al. “Attention is All You Need.” NIPS 2017.
- Devlin, J., et al. “BERT: Pre-training of Deep Bidirectional Transformers.” NAACL 2019.
- Radford, A., et al. “Language Models are Unsupervised Multitask Learners.” OpenAI 2019.
- Raffel, C., et al. “T5: Text-to-Text Transfer Transformer.” JMLR 2020.
- Brown, T., et al. “Language Models are Few-Shot Learners.” NeurIPS 2020.