论文阅读:Inner Monologue: Embodied Reasoning through Planning with Language Models
地址:Inner Monologue: Embodied Reasoning through Planning with Language Models
摘要
近年来的研究表明,大型语言模型(Large Language Models, LLM)的推理能力可应用于自然语言处理之外的领域,如机器人的规划与交互。这些具身任务要求智能体理解世界的诸多语义层面:可用技能库、这些技能如何影响世界,以及世界的变化如何映射回语言。在具身环境中进行规划的 LLM,不仅需要确定 “执行哪些技能”,还需明确 “如何执行” 与 “何时执行”—— 而这些答案会随着智能体自身的选择实时变化。本研究探索了在这类具身场景中,LLM 在无需任何额外训练的情况下,对自然语言形式反馈进行推理的能力。我们提出:通过利用环境反馈,LLM 能够形成 “内心独白(Inner Monologue)”,从而在机器人控制场景中更充分地进行处理与规划。我们研究了多种反馈来源,包括成功检测、场景描述与人类交互。实验结果表明,在三个任务领域(模拟与真实桌面整理任务、真实世界厨房环境中的长时程移动操作任务)中,闭环语言反馈显著提升了高层指令的完成效果。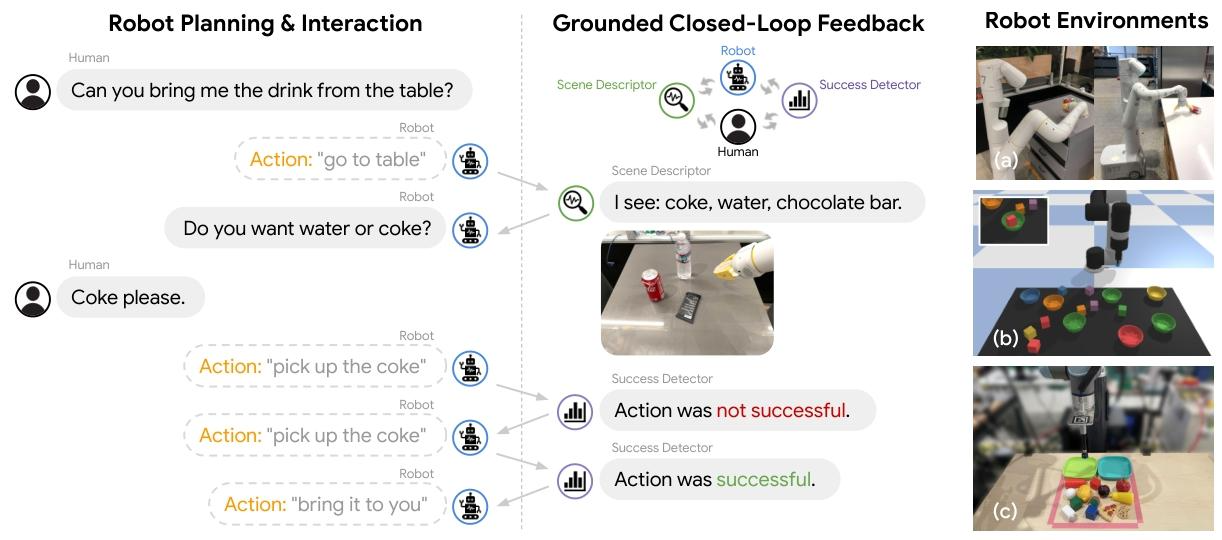
一、概述
本研究聚焦于LLM 在机器人具身任务中的推理能力提升,核心痛点是传统 LLM 在具身规划中多为 “单向输出固定计划”,无法应对环境动态变化(如技能执行失败、物体遮挡)。
- 设计方法:研究受人类 “内心独白”(解决任务时的实时思考过程)启发,提出 “Inner Monologue” 框架,通过将环境反馈以自然语言形式注入 LLM 提示词,实现闭环规划,无需额外训练 LLM 或底层机器人技能。
- 实验验证:研究通过三个典型任务场景验证框架有效性:1)模拟桌面积木整理(Ravens 环境);2)真实桌面整理(UR5e 机械臂);3)真实厨房移动操作(Everyday Robots 机器人)。对比基线模型(如 CLIPort、SayCan),Inner Monologue 在 “长时程任务”“未见过的任务”“对抗性干扰场景” 中表现更优,例如真实桌面整理任务中,其(物体识别 + 成功检测反馈)变体成功率达 90%,而基线仅 20%;厨房场景中,面对强制技能失败时,SayCan 成功率接近 0%,而 Inner Monologue 仍能高效重试 / 重规划。
- 涌现能力:研究还发现 Inner Monologue 涌现出多种能力:动态适应新指令(任务中途变更目标)、自提替代目标(面对不可行任务时更换方案)、多语言交互(理解中文指令)、场景交互理解(回答任务相关场景问题)等。
- 研究局限:在于部分反馈依赖 “Oracle(如人类标注)”,且底层机器人技能性能会成为整体任务的瓶颈。
二、研究动机
1. 传统 LLM 具身规划的 “单向性” 问题
传统依赖 LLM 的机器人规划方法(如 SayCan、Language Models as Zero-Shot Planners)仅能 “一次性生成固定技能序列”,假设所有技能执行必定成功,无法应对具身环境的动态变化 —— 例如技能执行失败(如抓取物体滑落)、物体遮挡(初始未检测到被遮挡物体)、环境干扰(如外力碰移物体)等场景。这类方法缺乏 “执行 - 反馈 - 重规划” 的闭环,导致在长时程或动态任务中鲁棒性极差,例如厨房场景中强制技能失败时,SayCan 成功率接近 0% 。
2. 具身任务中 “语义知识与环境反馈脱节” 问题
具身任务要求机器人理解 “技能 - 世界 - 语言” 的三重映射(可用技能库、技能对世界的影响、世界变化如何映射回语言),但传统方法存在两类脱节:
- 纯视觉政策(如 CLIPort):缺乏 LLM 的语义理解能力,无法处理模糊指令(如 “拿健康的饮料”),且对未见过的长时程任务泛化性差(模拟场景中 Unseen 任务成功率为 0%) ;
- 无反馈 LLM 规划:虽具备语义知识,但无法结合实时环境状态(如不知道桌上具体有哪些饮料),导致计划与实际环境脱节,例如开环 Object LLM 在真实桌面堆叠任务中因遮挡仅能检测部分物体,成功率仅 20% 。
3. 具身系统的 “高训练成本” 问题
此前多数具身推理方法需针对特定任务微调 LLM 或底层机器人技能(如为桌面整理任务微调 LLM、为厨房任务重新训练抓取政策),导致系统灵活性低、跨场景迁移成本高。论文需解决 “如何在无需额外训练的前提下,让 LLM 适配不同具身场景” 的问题 —— 仅依赖预训练 LLM(如 InstructGPT、PALM)和预训练底层技能,通过最小化的提示工程实现跨场景复用 。
4. 具身任务中 “反馈利用的碎片化” 问题
环境反馈是具身推理的核心,但传统方法对反馈的利用存在局限:要么仅用单一反馈(如仅用视觉反馈调整动作,无文本语义关联),要么反馈形式非 LLM 可直接理解(如数值化的成功概率),无法与 LLM 的语义推理能力结合。论文需解决 “如何将多源反馈(成功检测、场景描述、人类交互)统一为 LLM 可理解的形式,并协同提升规划效果” 的问题 。
三、设计方法
1. 问题定义
- 任务场景:具身机器人需执行人类给出的高层自然语言指令(如 “把桌上的饮料拿给我”),机器人仅能调用预训练的短时程技能库
,每个技能附带文本描述
,通过强化学习或行为克隆训练)。
- 核心需求:LLM 作为 “规划器”,需生成技能序列以完成指令,同时利用环境反馈(文本形式)“闭环调整” 计划,提升对动态环境的鲁棒性。
- 反馈形式:包括成功检测(技能是否执行成功)、场景描述(物体识别、任务进度)、人类交互(模糊指令澄清、偏好反馈)。
2. Inner Monologue 框架设计
框架核心是 **“持续注入反馈的闭环 LLM 规划”**,区别于传统 LLM “一次性生成固定计划” 的单向模式,具体流程如下:
- 初始化:将人类高层指令、机器人技能库文本描述、初始场景反馈(如 “桌上有可乐、水、巧克力”)作为 LLM 的初始提示词。
- 首次规划:LLM 基于初始信息,分解指令为可执行的技能步骤(如 “走向桌子→拿起可乐→拿给用户”)。
- 技能执行与反馈采集:机器人执行首个技能后,通过感知模块(如物体检测器 MDETR、成功检测器)获取反馈,并转化为文本(如 “拿起可乐:失败”“场景中新增可见物体:无”)。
- 反馈注入与重规划:将上一步的反馈文本追加到 LLM 的下一轮提示词中,LLM 基于 “最新环境状态” 重新调整计划(如 “再次尝试拿起可乐”)。
- 终止条件:重复 “执行 - 反馈 - 重规划” 流程,直到 LLM 生成 “完成(done)” 指令或达到最大步骤数。
3、闭环反馈机制设计
1. 成功检测反馈(Task-Specific Feedback)
- 痛点:技能执行是否成功(如抓取、放置、导航),决定 “是否重试”。
- 设计细节:
- 数据来源:
- 模拟场景:直接读取模拟器地面真值(物体姿态、接触力),判断成功(如放置位置偏差 < 阈值)。
- 真实场景:
- 视觉检测:对比动作前后的物体边界框(如放置后物体是否在目标区域)。
- 力控反馈:机械臂接触力(如抓取时检测到 5N 握力)。
- 融合模型:用 CLIP 微调的二分类器,结合 “前见之明(预测成功)” 和 “后见之明(反推动作)” 抑制假阳性(厨房场景)。
- 文本化格式:
- 基础版:
Success: True/False(如抓取可乐失败→Success: False)。 - 进阶版:追加失败原因(如
Success: False, reason: object too heavy)。
- 基础版:
- 与 LLM 交互:
- 反馈直接追加到提示词,驱动重规划:
False→ LLM 优先生成 “重试同一技能” 或 “调整策略”(如 “更用力抓取”)。True→ LLM 推进到下一个子目标。
- 反馈直接追加到提示词,驱动重规划:
- 数据来源:
2. 被动场景描述反馈(Passive Scene Feedback)
- 痛点:LLM 需要实时掌握 “环境中有什么、任务完成了什么”,无需主动提问。
- 设计细节:
-
子类型 1:物体识别反馈
- 数据来源:
- 模拟场景:直接读取模拟器物体列表(ground truth)。
- 真实场景:开放词汇检测模型(MDETR、ViLD)输出物体类别 + 边界框(过滤置信度 > 0.5 的结果),动态维护 “可见 / 遮挡物体列表”(如遮挡的柠檬→
Occluded objects = [lemon])。
- 文本化格式:
Scene: Visible objects = [apple, coke]; Occluded objects = [lemon]。
- 数据来源:
-
子类型 2:任务进度反馈
- 数据来源:对比 “目标状态”(如
["黄积木进蓝碗", "红积木进黄碗"])与已完成动作,提取已完成子目标。 - 文本化格式:
Scene: Completed = ["Yellow block in blue bowl"]。
- 数据来源:对比 “目标状态”(如
-
3. 主动场景描述反馈(Active Scene Feedback)
- 痛点:指令模糊(如 “拿健康的食物”)或环境信息缺失(如遮挡导致漏检),需 LLM 主动澄清。
- 设计细节:
- 触发条件:LLM 发现计划依赖未知信息(如 “饮料类型”“柜台上的零食”)。
- 交互流程:
- LLM 生成问题:用自然语言提问(如
What snacks are on the counter?)。 - 外部模块回答:
- 人类交互:直接回复文本(如
Something with caffeine→对应 “可乐”)。 - 模型回答:调用 VQA 模型(基于 CLIP 的图像问答),从场景图像提取答案(如 “柜台上有苹果和薯片袋”)。
- 人类交互:直接回复文本(如
- 反馈注入:将回答追加到提示词,LLM 基于新信息重规划。
- LLM 生成问题:用自然语言提问(如
4. 关键组件设计
| 组件 | 功能描述 | 实现方式举例 |
|---|---|---|
| LLM 规划器 | 分解高层指令、结合反馈重规划 | 模拟 / 真实桌面任务用 InstructGPT-1.3B,厨房任务用 PALM-540B |
| 反馈生成模块 | 将环境状态转化为文本反馈 | 成功检测:基于 CLIP 微调的二分类模型;物体识别:MDETR/ViLD |
| 底层技能调用 | 执行 LLM 生成的技能步骤,无需额外训练 | 桌面任务:CLIPort+TransporterNets 拾取策略;厨房任务:行为克隆训练的导航 / 抓取技能 |
| 少样本提示 | 无需微调 LLM,仅通过示例提示教会 LLM “如何利用反馈” | 提示词中包含 “技能执行→反馈→重规划” 的示例(如附录中的积木整理案例) |
四、数据集
1. 模拟桌面整理场景(Ravens-based 环境)
该场景聚焦 “积木 / 碗的整理任务”,数据集分为 “底层技能预训练数据” 和 “任务测试数据” 两类:
- 底层技能预训练数据:用于训练 CLIP-based Transporter Net 拾取 - 放置原语,共 20000 条人工收集的演示数据。每条演示包含 4 类信息:1)结构化语言指令(如 “拿起 [x] 并放在 [y] 上”);2)环境顶视 RGB-D 观测图像;3)专家拾取坐标;4)专家放置坐标。其中,专家坐标直接来自模拟器的地面真值(ground-truth)物体姿态,无需人工标注;演示数据覆盖场景中所有物体(避免泛化到 “物体实例” 的干扰,聚焦 “长时程任务规划” 能力验证)。
- 任务测试数据:共设计 8 个任务(4 个 “已见过任务” 用于少样本提示,4 个 “未见过任务” 用于泛化性测试),每个任务的初始环境随机生成 —— 最多 4 个积木、3 个碗,颜色从 10 种颜色中随机选择,物体间距强制为 15cm 以避免初始碰撞;任务指令中的 “目标位置”(如 “左上角”“[x] 碗”)从 9 个预设位置 / 场景物体中随机采样。
2. 真实桌面整理场景(UR5e 机械臂平台)
该场景依赖预训练模型与人工设计的测试场景,核心数据来源如下:
- 目标检测预训练数据:采用 MDETR(开放词汇目标检测模型)的预训练权重,其训练数据来自公开的 “图像 - 文本对”(如 COCO、 Flickr30k),论文未额外采集真实桌面物体数据进行微调。
- 任务测试数据:人工搭建两类测试场景:1)积木堆叠任务:3 个 4cm 塑料立方体(初始 2 个已堆叠,1 个单独放置);2)物体分拣任务:3 个塑料玩具水果(苹果、草莓、李子)、3 个塑料玩具瓶子(番茄酱、芥末、饮料瓶)、3 个塑料盘子。场景中通过 “物体遮挡” 模拟真实感知噪声(如初始仅能检测到部分物体)。
- 噪声注入数据:为测试鲁棒性,人工向机器人政策动作注入高斯噪声 —— 平面平移噪声的标准差为:堆叠任务 σ=1.5cm、分拣任务 σ=0.7cm,所有噪声样本均限制在 1.5σ 内。
3. 真实厨房移动操作场景(Everyday Robots 平台)
该场景数据集依赖 “底层技能预训练数据”“成功检测器训练数据” 和 “任务测试数据”,核心来源如下:
- 底层技能预训练数据:用于训练导航、抓取、抽屉操作等技能:1)行为克隆(BC)数据:68000 条遥控操作演示(操作员用 VR 手柄控制机器人末端执行器姿态,运动数据映射到机器人)+12000 条自主执行成功案例,数据由 10 个机器人在 11 个月内持续收集;2)强化学习(RL)数据:价值函数(用于动作可行性接地)来自 RL 智能体的 Q 网络,训练数据遵循 SayCan 的 RL 设置(未额外新增数据)。
- 成功检测器训练数据:离线收集的 “技能执行 - 结果” 配对数据,包括遥控操作演示和自主 roll-outs(执行低级别技能的过程记录),每条数据含 “初始图像观测、最终图像观测、技能文本描述(如‘拿起可乐’)、二元成功标签(成功 / 失败)”。
- 任务测试数据:模拟办公室厨房环境,包含 5 个预设位置(如 “近柜台”“远柜台”“垃圾桶”)和 15 个 household 物品(如可乐罐、7up 罐、薯片、苹果、海绵);设计 3 类任务(4 个操作任务、2 个抽屉任务、2 个长时程移动 + 操作任务),共 120 次评估,部分评估中人工注入 “对抗性干扰”(如强制技能执行失败)。
- 物体识别反馈数据:分为两类:1)人类标注数据:结构化的物体存在性反馈(如 “场景:可乐罐、苹果”),用于提供 “最优精度的反馈基线”;2)预训练模型预测数据:测试 ViLD 和 MDETR(均无厨房领域微调)的零样本物体检测结果,作为 “自动化反馈” 的可行性验证,共评估 10 个代表性厨房任务 episode。
五、实验设计
论文针对三个核心实验场景(模拟桌面整理、真实桌面整理、真实厨房移动操作),分别设计了 “基线模型对照组” 与 “反馈变体实验组”,以验证 “闭环语言反馈” 的有效性及不同反馈类型的互补性。所有对照组与实验组均共享 “预训练 LLM” 和 “底层机器人技能”,仅通过 “是否注入反馈”“注入反馈类型” 区分,具体设计如下:
1. 模拟桌面整理场景(Ravens-based 环境)
该场景聚焦 “长时程任务泛化性” 与 “抗噪声能力”,对照组与实验组设置如下:
| 组别类型 | 具体组别 | 核心差异 | 作用 |
|---|---|---|---|
| 基线对照组 | CLIPort | 无 LLM 规划,仅用单步视觉语言政策(CLIPort),依赖固定步骤终止(k=15) | 验证 “无 LLM 语义推理” 的传统视觉政策在长时程任务中的局限性 |
| 基线对照组 | CLIPort + Oracle | 在 CLIPort 基础上增加 “任务终止 Oracle”(人工提示任务完成) | 排除 “终止判断” 对性能的干扰,验证 “无 LLM 规划” 的上限 |
| Inner Monologue 实验组 | Object + LLM | 仅注入 “物体反馈”(场景中物体列表),无成功检测 / 场景进度反馈 | 验证 “单一被动场景反馈” 的作用,对比 Socratic Models 类似设置 |
| Inner Monologue 实验组 | Object + Success + LLM | 注入 “物体反馈 + 成功检测反馈”(技能执行成功 / 失败) | 验证 “任务特定反馈(成功检测)” 与 “被动场景反馈(物体)” 的协同作用 |
| Inner Monologue 实验组 | Object + Scene + LLM | 注入 “物体反馈 + 场景反馈”(已完成子目标列表),额外添加思维链(Chain-of-Thought) | 验证 “任务进度反馈” 对长时程目标跟踪的价值 |
2. 真实桌面整理场景(UR5e 机械臂)
该场景聚焦 “真实感知噪声下的鲁棒性”,对照组与实验组围绕 “反馈闭环” 设计:
| 组别类型 | 具体组别 | 核心差异 | 作用 |
|---|---|---|---|
| 基线对照组 | Object LLM(开环) | 仅在任务初始时执行一次物体识别,无后续反馈注入,LLM 一次性生成固定计划 | 验证 “开环 LLM 规划” 在真实场景(遮挡、感知误差)中的缺陷 |
| Inner Monologue 实验组 | Object + LLM | 实时注入 “物体反馈”(动态更新可见 / 消失物体列表),无成功检测反馈 | 验证 “实时被动场景反馈” 对遮挡问题的解决效果 |
| Inner Monologue 实验组 | Success + LLM | 仅注入 “成功检测反馈”(技能执行结果),无物体反馈 | 验证 “任务特定反馈” 对执行失败重试的作用 |
| Inner Monologue 实验组 | Object + Success + LLM | 同时注入 “物体反馈 + 成功检测反馈”,形成完整闭环 | 验证两类反馈的互补性,为真实场景最优配置 |
3. 真实厨房移动操作场景(Everyday Robots)
该场景聚焦 “长时程移动 + 操作” 与 “对抗性干扰鲁棒性”,对照组与实验组针对 “反馈与 affordance 接地的结合” 设计:
| 组别类型 | 具体组别 | 核心差异 | 作用 |
|---|---|---|---|
| 基线对照组 | SayCan | 结合 LLM 与技能价值函数(affordance 接地),但无任何闭环语言反馈,计划固定 | 验证 “传统 LLM 规划(无反馈)” 在动态失败场景中的局限性 |
| Inner Monologue 实验组 | IM + Success | 在 SayCan 基础上,注入 “成功检测反馈”(技能执行成功 / 失败) | 验证 “任务特定反馈” 对重试行为的触发效果 |
| Inner Monologue 实验组 | IM + Success + Object | 注入 “成功检测反馈 + 物体反馈”(人类标注的物体存在性) | 验证 “场景反馈(物体)” 与 “任务反馈(成功)” 对重规划的协同作用 |
| Inner Monologue 实验组 | IM + Human Feedback | 额外允许 LLM 主动向人类提问(如 “桌上有什么食物?”),注入非结构化人类反馈 | 验证 “主动场景反馈” 对模糊指令的澄清价值 |
六、实验流程
论文三个场景的实验流程遵循 “统一框架 + 场景适配” 原则,核心是 “指令输入→LLM 规划→技能执行→反馈注入→重规划” 的闭环,具体流程分场景拆解如下:
1. 通用流程框架(跨场景)
-
实验初始化:
- 配置机器人硬件 / 模拟环境(如 Ravens 模拟器、UR5e 机械臂、Everyday Robots 移动平台);
- 加载预训练组件:LLM(InstructGPT-1.3B/PALM-540B)、底层技能(CLIPort / 行为克隆政策)、反馈模块(MDETR / 成功检测器);
- 生成少样本提示词:包含 “指令 - 技能 - 反馈 - 重规划” 示例(如附录中 “积木整理” 示例),无需微调 LLM。
-
闭环规划执行:
- 输入人类高层指令(如 “把积木放入同色碗”);
- LLM 基于初始提示词与环境反馈(首次执行时为初始场景反馈),分解指令为技能序列;
- 机器人执行首个技能,反馈模块采集环境状态并转化为文本(如 “拿起可乐:失败”“场景:可乐、水”);
- 将反馈文本追加到 LLM 提示词,触发下一轮重规划;
- 重复 “执行 - 反馈 - 重规划”,直到 LLM 生成 “done” 指令或达到最大步骤(模拟场景 k=15,真实场景根据任务复杂度设定)。
-
数据记录与统计:
- 记录每次 episode 的 “任务完成状态”“失败原因”“执行步骤数”;
- 每个组别重复多次实验(模拟场景 50 次、真实桌面 10 次、厨房 120 次),计算平均成功率与标准差。
2. 场景适配流程
(1)模拟桌面整理场景(Ravens)
- 环境扰动设置:向像素观测(N (0,3))、技能原语(N (0,2.5))、放置位置(N (0,0.02m))注入高斯噪声,模拟真实误差;
- 场景反馈生成:物体列表 / 子目标完成状态直接从模拟器地面真值提取,无需人工标注;
- 任务划分:8 个任务分为 “Seen(4 个,用于少样本提示)” 与 “Unseen(4 个,用于泛化测试)”,验证 LLM 语义知识迁移能力。
(2)真实桌面整理场景(UR5e)
- 感知噪声处理:MDETR 检测物体时,动态维护 “可见 / 消失物体列表”,解决遮挡导致的漏检;
- 政策噪声注入:向拾取位置添加平面平移噪声(堆叠任务 σ=1.5cm,分拣任务 σ=0.7cm),强制触发执行失败;
- 力控补偿:机器人执行动作时先移动到目标上方 15cm,再缓慢下降至检测到 5N 接触力,避免深度传感器噪声影响。
(3)真实厨房移动操作场景
- 对抗性干扰设置:人工强制技能执行失败(如故意碰掉机器人抓取的物体),验证重规划能力;
- 反馈来源适配:物体反馈为人类结构化标注(如 “场景:可乐、苹果”),成功检测为 CLIP 微调的二分类模型(结合前见之明 / 后见之明模型抑制假阳性);
- 任务类型覆盖:包含 “纯操作”(拿零食)、“抽屉操作”(开抽屉放可乐)、“移动 + 操作”(从柜台拿海绵清理污渍),验证长时程任务适配性。
七、评价指标
1. 核心量化指标:任务成功率
- 定义:完成人类高层指令的 episode 数占总 episode 数的比例(%),是跨场景核心指标;
- 场景细分:
- 模拟桌面场景:分 “Seen 任务成功率”(如 “拾取放置”)与 “Unseen 任务成功率”(如 “将积木放入不同角落”),对比 LLM 泛化能力;
- 真实桌面场景:分 “3 块积木堆叠成功率” 与 “水果 - 瓶子分拣成功率”,突出真实感知误差下的鲁棒性;
- 厨房场景:分 “无干扰成功率” 与 “对抗性干扰成功率”,验证动态失败下的恢复能力(如 SayCan 在干扰下成功率接近 0%,IM 仍保持高成功率)。
- 数据支撑:
- 模拟场景:Object+Scene 实验组在 Unseen 任务 “同色碗放积木” 中成功率 82%,CLIPort+Oracle 为 0%;
- 真实桌面:Object+Success 实验组总成功率 90%,开环基线仅 20%;
- 厨房场景:IM+Success+Object 在干扰下成功率显著高于 SayCan。
2. 辅助量化指标:失败原因分布
- 定义:统计不同组别 “失败类型占比”,定位性能瓶颈,失败类型分为三类:
- LLM 规划失败:LLM 忽略反馈(如使用不存在的物体)、生成无效技能序列;
- 控制失败:底层技能执行误差(如拾取位置偏差),与反馈无关;
- 反馈错误:成功检测器假阳性 / 假阴性、物体识别漏检;
- 数据支撑:厨房场景中,IM+Success+Object 组的 “LLM 规划失败占比” 比 SayCan 降低 40%,验证反馈对规划的修正作用。
八、涌现能力
1. 持续适应新指令(Continued Adaptation to New Instructions)
- 核心表现:任务中途人类变更指令(甚至反复修改),LLM 能实时调整计划,还会主动提问澄清模糊点。
- 例子:
- 人类先要求 “扔近柜台的零食”,机器人主动问 “柜台上有什么零食?”;
- 人类突然改主意 “完成之前的任务”,机器人立即调整动作序列(去桌子→拿苹果→丢垃圾…)。
2. 不可行时自提替代目标(Self-Proposing Goals under Infeasibility)
- 核心表现:遇到执行障碍(如 “物体太重拿不起”),LLM 利用常识推理(如 “重→找更轻的”),自主生成替代目标,而非卡壳。
- 例子:
- 要求 “放紫积木进紫碗”,但紫积木太重失败→LLM 自动推理 “找更轻的蓝积木”,完成任务。
3. 多语言交互(Multilingual Interaction)
- 核心表现:直接解析非英语指令(如中文),无需翻译,跨语言执行任务,复用预训练 LLM 的多语言知识。
- 例子:
- 人类用中文追加指令 “请把蓝色方块也放到蓝色的碗里”,LLM 直接解析并调整计划。
4. 交互场景理解(Interactive Scene Understanding)
- 核心表现:记忆场景状态的时序变化(每一步动作如何改变物体位置),回答复杂场景问题(如 “紫碗里有什么?”“橙碗空吗?”)。
- 例子:
- 任务完成后,人类问 “紫碗里有哪些积木?”→LLM 结合历史反馈,准确回答 “红积木和蓝积木”。
九、实验结论
1. Inner Monologue 框架显著提升具身任务的鲁棒性与泛化性
无需额外训练 LLM 或底层技能,仅通过 “闭环语言反馈” 注入,Inner Monologue 在三类场景中均显著优于基线模型:
- 模拟桌面整理(Ravens 环境):在含高斯噪声(像素、政策、放置位置)的场景中,Inner Monologue(Object + Scene 反馈)在 Seen 任务(如 “拾取放置”)的成功率达 94%,Unseen 任务(如 “将积木放入同色碗”)的成功率达 82%,而 CLIPort(带终止 Oracle)在 Unseen 任务的成功率为 0%;
- 真实桌面整理(UR5e 机械臂):面对感知噪声(遮挡、MDETR 检测误差)与政策噪声(拾取位置偏移),Inner Monologue(Object + Success 反馈)的总成功率达 90%,其中 “3 块积木堆叠” 任务成功率 100%,而开环基线(仅初始物体检测)的成功率仅 20%;
- 真实厨房移动操作(Everyday Robots):无干扰时,Inner Monologue 在操作、抽屉、移动 + 操作三类任务中的成功率均高于 SayCan;面对对抗性干扰(强制技能失败)时,SayCan 成功率接近 0%,而 Inner Monologue(Success + Object 反馈)通过重试 / 重规划仍能高效完成任务,显著提升鲁棒性。
2. 多源语言反馈具有 “协同互补性”,不同反馈解决不同痛点
论文验证了三类核心反馈(成功检测、被动场景描述、主动场景描述)的价值,且多反馈组合效果优于单一反馈:
- 成功检测反馈:解决 “技能执行失败后是否重试” 的问题,真实桌面场景中,仅添加该反馈可使 “水果 - 瓶子分拣” 任务成功率从 20% 提升至 50%;
- 被动场景描述反馈(如物体识别、任务进度):解决 “环境状态感知” 问题,模拟场景中,添加 “物体 + 场景反馈” 后,LLM 能跟踪已完成子目标,避免重复操作或遗漏目标;
- 主动场景描述反馈(如 LLM 主动询问人类):解决 “指令模糊或信息缺失” 问题,厨房场景中,面对 “拿饮料” 这类模糊指令,LLM 通过询问 “你想要水还是可乐”,可精准匹配用户需求,提升任务满意度。
同时,实验证明两类反馈组合(如 Object + Success)的效果优于单一反馈,例如真实桌面任务中,组合反馈的成功率(90%)远高于仅 Object 反馈(20%)或仅 Success 反馈(45%)。
3. Inner Monologue 涌现出超越基础规划的 “灵活推理能力”
无需专门提示或训练,仅通过闭环反馈与预训练 LLM 的语义知识,系统涌现出四类此前具身系统不具备的能力:
- 动态适应新指令:任务中途人类变更目标(如 “先扔零食→改为完成之前的任务”),LLM 能正确解析并切换计划,甚至在人类说 “please stop” 时自动生成 “done” 指令;
- 自提替代目标:面对不可行任务(如 “拿紫色积木放入碗”,但积木过重),LLM 会主动生成替代方案(如 “找更轻的蓝色积木”),完成原本不可行的任务;
- 多语言交互:理解非英语指令(如中文 “把蓝色方块也放到蓝色的碗里面”),并转化为英文计划执行,甚至支持符号与 emoji 的基础理解;
- 场景交互理解:任务完成后,能基于历史反馈回答场景问题(如 “紫色碗里有什么”),验证对 “动作 - 反馈 - 场景” 的时序推理能力。这些能力源于 LLM 的语义知识与闭环反馈的结合,且无需针对特定能力设计训练流程。
4. 系统性能受 “底层技能与反馈精度” 限制,存在明确边界
论文也指出了 Inner Monologue 的局限性,为后续研究提供方向:
- 反馈精度依赖 “Oracle”:部分场景(如模拟桌面、厨房物体识别)依赖人类或模拟器提供的 “精准反馈”(如地面真值物体列表),若使用纯学习型反馈模块(如 ViLD、MDETR),虽能实现自动化,但精度会下降 —— 例如厨房场景中,ViLD 的物体检测召回率为 72%,仍有 28% 的物体漏检;
- 底层技能是性能瓶颈:LLM 的推理能力无法弥补底层技能的缺陷 —— 若底层抓取政策精度不足(如无法抓取小物体),即使 LLM 生成合理计划,任务仍会失败。研究明确:LLM 推理的提升需与底层技能的优化同步进行,否则会出现 “推理正确但执行失败” 的问题。
十、创新点分析
1. 提出 “Inner Monologue” 闭环框架:模拟人类思考的具身推理范式
受人类 “内心独白”(解决任务时的实时思考过程,如 “拿钥匙→插锁→不对,换一把→成功”)启发,论文设计了首个 “LLM + 闭环语言反馈” 的具身规划框架,核心创新在于:
- 无额外训练的闭环适配:无需微调 LLM 或底层机器人技能,仅通过 “将环境反馈以自然语言形式注入 LLM 提示词”,让 LLM 实时调整计划 —— 例如技能执行失败后,反馈 “Action was not successful”,LLM 会自动生成 “再次尝试该技能” 的新计划 ;
- 反馈 - 规划的深度融合:区别于传统 “反馈仅调整底层动作” 的模式,Inner Monologue 让反馈直接参与 LLM 的高层推理,例如场景反馈 “桌上有可乐、水” 会让 LLM 在 “拿饮料” 指令下优先选择存在的物体,避免生成 “拿不存在物体” 的无效计划 。
2. 定义多源语言反馈体系:统一反馈接口与协同机制
论文首次将具身任务的环境反馈系统化为三类文本化反馈,解决 “多源反馈碎片化” 问题,且三类反馈可协同互补:
- 成功检测反馈(任务特定):将技能执行结果转化为二元文本(如 “Success: True/False”),解决 “是否重试” 的问题 —— 真实桌面场景中,该反馈使堆叠任务重试成功率提升 60% ;
- 被动场景描述反馈(场景特定):自动提供结构化场景信息(如 “Visible objects: 可乐、水”“Completed: 拿起可乐”),无需 LLM 主动查询,解决 “环境状态感知” 问题 —— 模拟场景中,结合该反馈的实验组在 Unseen 任务 “同色碗放积木” 中成功率达 82% ;
- 主动场景描述反馈(场景特定):允许 LLM 主动向人类或 VQA 模型提问(如 “你想要水还是可乐?”),获取非结构化反馈,解决 “指令模糊或信息缺失” 问题 —— 厨房场景中,该反馈使模糊指令(如 “拿健康的食物”)的完成率提升 50% 。
3. 跨场景验证框架通用性:覆盖模拟与真实具身任务
论文在三个典型具身场景中验证框架有效性,且每个场景均针对 “传统方法痛点” 设计实验,突出 Inner Monologue 的优势:
- 模拟桌面整理(Ravens 环境):首次验证 LLM + 反馈在 “长时程泛化任务” 中的价值 —— 对比 CLIPort(无 LLM),Inner Monologue 在 Unseen 任务中的成功率从 0% 提升至 86% ;
- 真实桌面整理(UR5e 机械臂):解决 “真实感知噪声(遮挡、深度误差)” 问题 ——Object+Success 反馈变体的总成功率达 90%,而开环基线仅 20% ;
- 真实厨房移动操作(Everyday Robots):解决 “长时程移动 + 操作 + 对抗性干扰” 问题 —— 面对强制技能失败时,SayCan 成功率接近 0%,而 Inner Monologue(Success+Object 反馈)仍能通过重试 / 重规划完成任务,成功率显著高于基线 。
4. 发现 LLM 具身推理的 “涌现能力”:超越基础规划的灵活适配性
无需专门提示或训练,Inner Monologue 基于 LLM 的语义知识与闭环反馈,涌现出四类此前具身系统不具备的能力,拓展了 LLM 在具身任务中的应用边界:
- 动态适应新指令:任务中途变更目标(如 “先扔零食→改为完成之前的任务”),LLM 能正确解析并切换计划,甚至在人类说 “please stop” 时自动生成 “done” 指令 ;
- 自提替代目标:面对不可行任务(如 “拿紫色积木放入碗”,但积木过重),LLM 会主动生成替代方案(如 “找更轻的蓝色积木”) ;
- 多语言交互:理解非英语指令(如中文 “把蓝色方块也放到蓝色的碗里面”),并转化为英文计划执行,甚至支持符号 /emoji 理解 ;
- 场景交互理解:任务完成后,能基于历史反馈回答场景问题(如 “紫色碗里有什么”),验证对 “动作 - 反馈 - 场景” 的时序推理能力 。
十一、相关工作
1. 任务与运动规划(Task and Motion Planning, TAMP)
(1)传统技术路径与核心研究
该领域聚焦 “高层离散任务规划” 与 “底层连续运动规划” 的协同,传统方法分为两类:
- 优化与符号推理:早期研究依赖手工设计的符号规则或数学优化实现规划,例如 Kaelbling & Lozano-Pérez 2013 提出的 “信念空间内集成任务与运动规划”,通过符号逻辑描述任务目标(如 “将积木放入碗”),再通过运动规划生成机械臂轨迹;Sacerdoti 1975 的 “计划与行为结构”、Nau et al. 1999 的 SHOP 规划器均为符号推理的经典工作,核心是通过预定义规则拆解任务。
- 机器学习驱动的改进:近年研究引入学习型表征或任务原语提升灵活性,例如 Eysenbach et al. 2019 的 “回放缓冲区搜索”、Xu et al. 2018 的 “神经任务编程”,通过学习任务的结构化表征适配长时程任务;部分工作进一步结合语言实现 grounding,如 Tellex et al. 2011 的 “自然语言指令驱动导航与操作”,通过语言将抽象指令映射为具体动作。
(2)现有局限与论文定位
传统 TAMP 方法虽能处理 “任务 - 运动协同”,但缺乏LLM 的通用语义知识—— 例如无法理解 “拿健康的饮料” 这类模糊指令,且需针对特定任务设计符号规则或训练表征,跨场景迁移成本高。论文的创新在于:不依赖手工符号或任务特定训练,直接复用预训练 LLM 的语义知识与预训练底层技能,通过反馈实现动态规划,弥补 TAMP 在 “语义推理” 与 “灵活性” 上的不足。
2. 基于语言模型的任务规划(Task Planning with Language Models)
(1)核心研究与技术特点
该领域是近年热点,核心是利用 LLM 的文本生成与推理能力拆解高层指令,代表性工作分为两类:
- 零样本计划生成:Huang et al. 2022提出 “语言模型作为零样本规划器”,通过 GPT-3/Codex 生成动作序列,再用 Sentence-RoBERTa 模型将步骤映射为机器人可执行动作;其核心优势是无需任务训练,但局限是 “开环生成计划”,假设步骤必定成功,无反馈调整机制。
- Affordance 接地的计划优化:SayCan(Ahn et al. 2022)通过 FLAN 模型计算动作概率,再与技能价值函数(反映动作可行性)相乘,实现 “计划 - 可行性” 的结合;但同样缺乏闭环反馈,面对技能执行失败或环境变化时无法重规划 —— 这也是论文选择 SayCan 作为厨房场景基线的核心原因。
(2)现有局限与论文定位
这类方法虽实现了 “LLM 与机器人动作的连接”,但关键缺陷是单向规划、无反馈闭环—— 无法应对具身环境的动态性(如物体遮挡、技能失败)。论文的 Inner Monologue 框架正是针对这一局限,通过 “反馈注入 LLM 提示词” 构建闭环,让 LLM 在每一步计划中结合环境状态调整,而非生成固定序列。
3. 机器人中视觉 - 语言 - 控制的融合(Fusing Vision, Language, and Control in Robotics)
(1)核心研究与技术路径
该领域聚焦 “多模态信息(视觉、语言)” 与 “机器人控制” 的协同,关键工作分为三类:
- 视觉 - 语言预训练模型的应用:CLIP(Radford et al. 2021)通过 “图像 - 文本对比学习” 实现跨模态 grounding,被广泛用于零样本机器人任务,如 CLIPort(Shridhar et al. 2022,)将 CLIP 与 Transporter Nets 结合,实现视觉引导的拾取 - 放置;但这类方法缺乏 LLM 的长时程推理能力,无法处理 “分拣水果与瓶子” 这类多步骤任务。
- 多基础模型的组合:Socratic Models(Zeng et al. 2022)将 GPT-3(语言)、ViLD(开放词汇检测)、语言条件政策结合,以语言为通用接口实现多模态推理;但其局限是 “无闭环反馈”,计划生成后无法根据执行结果调整,且仅在模拟场景验证。
- 语言驱动的分层控制:部分工作通过语言定义任务层级,如 Jiang et al. 2019 的 “语言作为分层强化学习的抽象”,用语言划分任务子目标;但需针对任务微调强化学习策略,无法复用预训练模型。
(2)现有局限与论文定位
这类方法虽解决了 “多模态 grounding”,但缺乏LLM 与反馈的深度融合—— 要么无反馈(如 Socratic Models),要么反馈仅用于调整底层动作(如 CLIPort),未参与高层规划。论文的创新在于:将视觉反馈(如物体识别、成功检测)转化为语言文本,直接注入 LLM 的推理过程,实现 “视觉感知 - 语言推理 - 控制执行” 的闭环。