算法第五十五天:图论part05(第十一章)
并查集理论基础
并查集主要有两个功能:
- 将两个元素添加到一个集合中。
- 判断两个元素在不在同一个集合
class UnionFind:def __init__(self, n):"""初始化并查集"""self.n = nself.father = list(range(n)) # 每个节点自己是根self.rank = [1] * n # 每棵树初始高度为1def find(self, u):"""查找根节点,同时做路径压缩"""if self.father[u] != u:self.father[u] = self.find(self.father[u]) # 路径压缩return self.father[u]def is_same(self, u, v):"""判断 u 和 v 是否在同一个集合"""return self.find(u) == self.find(v)def join(self, u, v):"""按秩合并 u 和 v 所在集合"""u_root = self.find(u)v_root = self.find(v)if u_root == v_root:return # 已经在同一个集合# 按秩合并:小树挂到大树下面if self.rank[u_root] < self.rank[v_root]:self.father[u_root] = v_rootelif self.rank[u_root] > self.rank[v_root]:self.father[v_root] = u_rootelse:self.father[u_root] = v_rootself.rank[v_root] += 1
1.寻找存在的路径
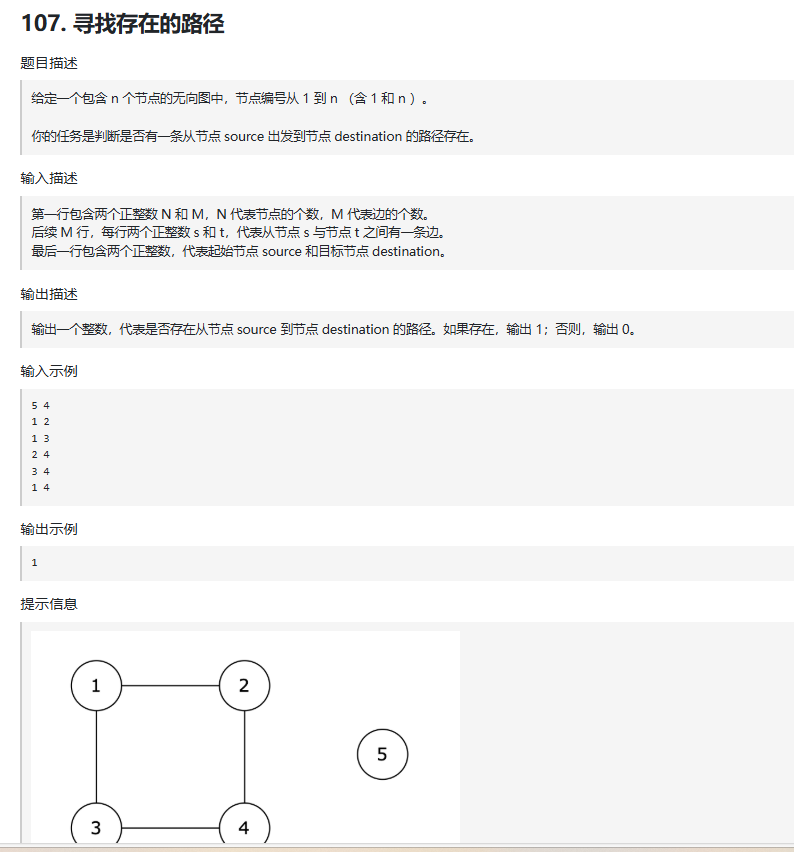
主函数逻辑
main函数是程序的执行入口,它负责处理输入、调用并查集的方法,并输出结果。它的步骤是:
读取输入:一次性读取所有输入数据,包括元素的总数
n、操作的次数m,以及所有的合并和查询数据。初始化并查集:创建一个
UnionFind(n)的实例,准备好处理n个元素。执行合并操作:通过一个循环,读取
m对元素,并对每一对元素调用uf.union()方法,将它们所在的集合合并。执行查询:读取最后需要查询的一对元素
source和destination。输出结果:调用
uf.is_same()方法来判断source和destination是否属于同一个集合,然后根据结果输出1或0。
class UnionFind:
#每个人的根都指向自己
def __init__(self, size):
self.parent = list(range(size+1))
def find(self, u):
if self.parent[u] != u:
self.parent[u] = self.find(self.parent[u]) # 路径压缩
return self.parent[u]
def union(self, u, v):
root_u = self.find(u)
root_v = self.find(v)
if root_u != root_v:
self.parent[root_v] = root_u
#检查两个元素 u 和 v 是否属于同一个集合(也就是它们是否“连通”)
def is_same(self, u, v):
return self.find(u) == self.find(v)
def main():
#sys.stdin.read 这个方法有点不一样。它是从标准输入流中一次性读取所有的输入
import sys
input = sys.stdin.read
data = input().split()
index = 0
n = int(data[index])
index += 1
m = int(data[index])
uf = UnionFind(n)
index += 1
for _ in range(m):
s = int(data[index])
index += 1
t = int(data[index])
index += 1
uf.union(s, t)
source = int(data[index])
index += 1
destination = int(data[index])
if uf.is_same(source, destination):
print(1)
else:
print(-1)
if __name__ == "__main__":
main()
今天就到这里了有点难!