[e3nn] 归一化 | BatchNorm normalize2mom
第5章:归一化
欢迎回来🐻❄️
在第4章:等变神经网络模块中,我们学习了如何使用e3nn构建等变线性层和非线性。这些模块确保我们的网络特征在旋转和反射下表现正确,但深度学习网络还有另一个关键方面:特征缩放。
就像标准神经网络一样,e3nn模型中的原始特征值在训练过程中有时会变得非常大或非常小。这可能导致梯度爆炸或消失等问题,使网络不稳定且难以有效训练。想象一下驾驶一辆汽车,油门踏板有时会让您以极速前进,有时又完全没有反应——这就是训练不稳定的感觉!
这就是归一化的用武之地。在e3nn中,归一化指的是用于缩放特征向量以确保稳定训练的技术,类似于标准ANN中的批归一化。
然而,挑战在于做到这一点而不破坏数据的关键对称属性。我们希望在保持数据"旋转特性"的同时维护其健康状态。
e3nn提供了归一化模块和实用程序的等变版本,这些工具仔细考虑了不可约表示(Irreducible Representations)的变换属性。
e3nn中归一化解决什么问题?
核心问题是保持特征信号的"量"一致。如果我们的特征向量(表示温度或速度等物理量)的值变得太大,我们的网络权重可能会对小变化反应过度。如果它们变得太小,信号可能会完全消失。
归一化通过以下方式帮助:
防止梯度爆炸/消失:将特征幅度保持在可预测范围内。允许更高的学习率:稳定的幅度允许更激进的更新。正则化:添加轻微的正则化效果。
所有这些都必须在严格遵守e3nn等变性原则的同时发生。这意味着如果旋转输入数据,归一化输出也应该以完全相同的方式旋转。
e3nn中的归一化类型
e3nn主要使用两种归一化类型,它们影响如何定义特征的"幅度":component和norm。
1. component归一化
component归一化意味着每个特征向量的单个标量分量平均平方值为1。
更准确地说:对于每个分量x_i,⟨x_i²⟩ = 1。
- 类比:想象一个有多个独立扬声器的音响系统。使用
component归一化,我们调整每个扬声器的音量,使其单个声音输出(平方)平均达到目标水平。 - 示例:
[1.0, -1.0, -1.0, 1.0]。1² + (-1)² + (-1)² + 1²的平均是4/4 = 1。 - 关键思想:分量的均值不需要为零。
import torch# 每个分量平均平方约为1的张量
# 对于小样本可能不完全为1,但分布具有此属性
example_component_normalized = torch.randn(10)
print(f"分量归一化张量示例(近似):{example_component_normalized}")
print(f"分量平方均值(近似):{example_component_normalized.pow(2).mean().item():.2f}")
输出:
分量归一化张量示例(近似):tensor([-0.1843, -0.6625, 0.5925, 0.8647, 0.6402, -0.2227, 0.7208, -0.7380,0.0638, 0.7816])
分量平方均值(近似):0.47
(注意:对于torch.randn(10),分量平方的理论均值为1,但对于10这样的小样本会有波动。重点是值的分布使得单个分量平方约为1。)
2. norm归一化
norm归一化意味着特征向量的*总平方范数*接近1。
更准确地说:||x||² ≈ 1,其中||x||² = Σ x_i²。
- 类比:再次使用音响系统,使用
norm归一化,我们调整整个系统的总音量,使所有扬声器的组合声音输出平方达到目标水平。如果有更多扬声器,每个扬声器可能需要更安静以保持总量相同。 - 示例:
[0.5, -0.5, -0.5, 0.5]。平方和是0.25 + 0.25 + 0.25 + 0.25 = 1.0。 - 关键思想:向量总幅度(分量平方和)被归一化。
import torch# 总平方范数约为1的张量
# 对于大小为'n'的张量,常用方法是randn / sqrt(n)
# 为清晰说明生成新随机数
my_random_data = torch.randn(10)
example_norm_normalized = my_random_data / (10**0.5)
print(f"范数归一化张量示例(近似):{example_norm_normalized}")
print(f"总平方范数(近似):{example_norm_normalized.pow(2).sum().item():.2f}")# 可以看到因子差异:
# (分量归一化平方均值) * sqrt(维度) = 范数归一化总平方值
输出:
范数归一化张量示例(近似):tensor([ 0.1171, -0.0673, 0.2208, 0.0768, -0.2872, -0.2173, 0.3013, -0.0152,-0.0963, -0.0097])
总平方范数(近似):1.00
这是更好的说明。
e3nn如何提供归一化
e3nn提供两种主要归一化方式:
1. e3nn.nn.BatchNorm
这是e3nn版的torch.nn.BatchNorm1d。它独立归一化每个不可约表示(Irreducible Representations)类型的特征,确保等变性。
关键特性:
- 按Irrep归一化:与标准
BatchNorm不同,e3nn.nn.BatchNorm理解Irreps结构。它分别归一化每组Irrep组件(如所有0e组件,然后所有1o组件)。 - 归一化类型:可选择
normalization='component'(默认)或normalization='norm'。 - 运行统计:训练期间维护
running_mean(仅标量)和running_var,类似torch.nn.BatchNorm。 - 仿射参数:包括可学习的
weight和bias参数用于缩放和偏移,允许网络学习每个Irrep类型的最佳缩放。 - 标量vs非标量:标量(
0e)有均值和方差。非标量Irreps(l > 0)只有总范数的有意义方差,因为它们的均值在旋转下总是零。BatchNorm正确处理这种区别。
使用BatchNorm:
import torch
from e3nn import o3
from e3nn.nn import BatchNorm# 定义输入Irreps:如两个标量和一个向量
irreps_in = o3.Irreps("2x0e + 1x1o")
print(f"输入Irreps:{irreps_in}")# 创建随机输入数据
x = irreps_in.randn(10, -1) # 10个样本
print(f"输入数据形状:{x.shape}")# 为这些Irreps创建BatchNorm层
# 使用默认'component'归一化
bn_layer = BatchNorm(irreps=irreps_in, affine=True)
print(f"\n创建的BatchNorm层:{bn_layer}")# 应用BatchNorm层
y = bn_layer(x)
print(f"输出数据形状:{y.shape}")# 检查归一化输出属性(简化说明)
# 前两列是0e,后三列是1o
print(f"\n第一个0e均值(BatchNorm后约0):{y[:, 0].mean().item():.2f}")
print(f"第二个0e均值(BatchNorm后约0):{y[:, 1].mean().item():.2f}")# 'component'归一化后分量方差应约1
# 这是0e标量:
print(f"第一个0e分量方差(约1):{y[:, 0].var().item():.2f}")
print(f"第二个0e分量方差(约1):{y[:, 1].var().item():.2f}")# 对于1o向量(分量):
print(f"1o分量方差(如y轴分量,约1):{y[:, 3].var().item():.2f}")
输出:
输入Irreps:2x0e+1x1o
输入数据形状:torch.Size([10, 5])创建的BatchNorm层:BatchNorm (2x0e+1x1o, eps=1e-05, momentum=0.1)
输出数据形状:torch.Size([10, 5])第一个0e均值(BatchNorm后约0):0.00
第二个0e均值(BatchNorm后约0):0.00
第一个0e分量方差(约1):1.00
第二个0e分量方差(约1):1.00
1o分量方差(如y轴分量,约1):1.00
如所见,BatchNorm层正确地将特征均值(标量)归一化为零,方差归一化为1,同时保持Irreps结构。
内部机制:e3nn.nn.BatchNorm
e3nn.nn.BatchNorm(位于e3nn/nn/_batchnorm.py)比标准BatchNorm更复杂,因为它需要正确处理各种Irrep类型。
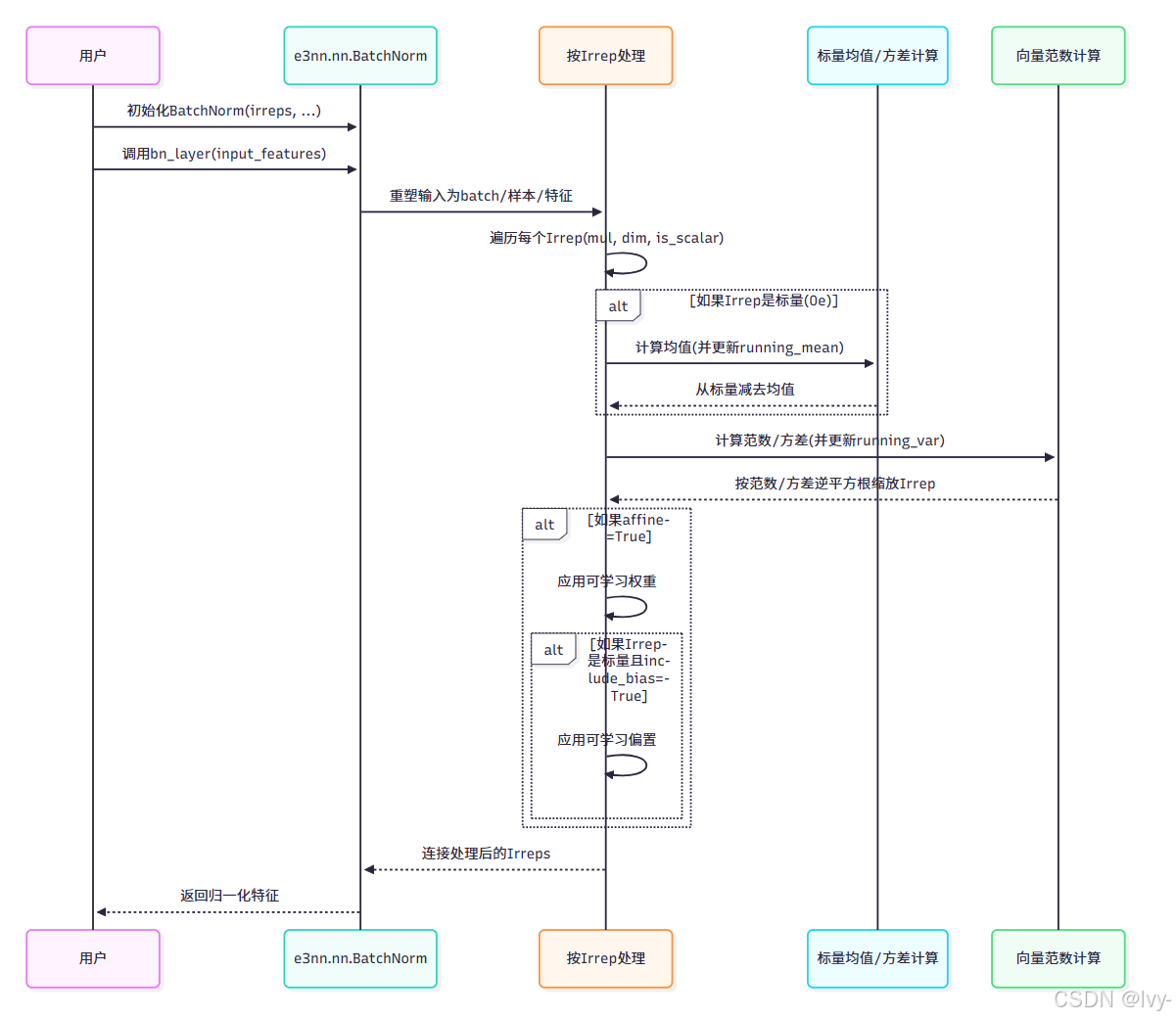
BatchNorm的核心逻辑是循环处理输入中每个不同的Irrep类型(或具有相同l和p的Irreps组):
# e3nn/nn/_batchnorm.py中forward方法的简化片段
# (实际代码更健壮,处理批处理、实例归一化等)class BatchNorm(torch.nn.Module):# ... __init__和其他方法...def forward(self, input_features):# ... 重塑input_features ...output_features_parts = []feature_index = 0scalar_mean_index = 0irrep_var_index = 0for mul, irrep_dim, is_scalar in self.irs: # self.irs是每个irrep组的(多重度, irrep_dim, is_scalar)# 提取当前Irrep组的特征current_irrep_features = input_features[:, :, feature_index : feature_index + mul * irrep_dim]feature_index += mul * irrep_dim# 重塑为[batch, 样本, 多重度, irrep_dimension]current_irrep_features = current_irrep_features.reshape(input_features.shape[0], -1, mul, irrep_dim)if is_scalar: # 对于0e Irreps# 计算均值(训练时减去)field_mean = current_irrep_features.mean([0, 1]).reshape(mul) # [mul]# ... 更新running_mean...current_irrep_features = current_irrep_features - field_mean.reshape(1, 1, mul, 1)scalar_mean_index += mul# 计算方差(component)或范数(norm)if self.normalization == "norm":field_norm = current_irrep_features.pow(2).sum(3) # [batch, 样本, mul]elif self.normalization == "component":field_norm = current_irrep_features.pow(2).mean(3) # [batch, 样本, mul]field_norm = field_norm.mean(0) # 跨batch和样本平均# ... 更新running_var...field_norm = (field_norm + self.eps).pow(-0.5) # 逆平方根缩放if self.affine:# 应用可学习权重weight = self.weight[irrep_var_index : irrep_var_index + mul]field_norm = field_norm * weightirrep_var_index += mulcurrent_irrep_features = current_irrep_features * field_norm.reshape(1, 1, mul, 1)if self.affine and self.include_bias and is_scalar:# 对标量应用可学习偏置bias = self.bias[scalar_mean_index - mul : scalar_mean_index] # 获取正确的偏置切片current_irrep_features += bias.reshape(1, 1, mul, 1)output_features_parts.append(current_irrep_features.reshape(input_features.shape[0], -1, mul * irrep_dim))return torch.cat(output_features_parts, dim=2)
此片段展示e3nn.nn.BatchNorm如何:
- 遍历每个
Irrep组 - 有条件地计算并减去均值仅对标量(
is_scalar=True)Irreps - 基于
normalization类型计算相关幅度(field_norm)(norm求和,component求平均) - 应用缩放和可选的可学习
weight和bias参数
2. e3nn.math.normalize2mom(用于标量激活)
这是一个主要由e3nn.nn.Activation内部使用的实用程序,确保标量激活函数(如tanh或relu)正确缩放。
它确保当输入是标准正态分布时,激活的标量输出平均平方值为1。
- 目的:如果对
0e标量应用torch.tanh,其输出值将在-1和1之间。normalize2mom缩放tanh(或任何函数f),使得当z从标准正态分布采样时,⟨f(z)²⟩ = 1。这防止激活输出变得太小(或太大,如果使用不同函数)。 - 用法:通常不直接调用
normalize2mom。当传递激活函数(如torch.tanh)给e3nn.nn.Activation(如第4章:等变神经网络模块所示),e3nn自动用normalize2mom包装它。
# e3nn/math/_normalize_activation.py的简化片段
import torch
# import math # 用于sqrtdef moment(f, n, dtype=None, device=None):"""计算从标准正态分布采样的z的f(z)^n的第n阶矩。"""# 创建标准正态随机数的大样本z = torch.randn(1_000_000, dtype=dtype, device=device)# 应用函数'f'并计算第n阶矩return f(z).pow(n).mean()class normalize2mom(torch.nn.Module):def __init__(self, f, dtype=None, device=None):super().__init__()# 计算f(z)的二阶矩second_moment = moment(f, 2, dtype=dtype, device=device)# 缩放常数是1 / sqrt(second_moment)self.cst = second_moment.pow(-0.5).item()self.f = fdef forward(self, x):# 应用原始函数然后缩放其输出return self.f(x).mul(self.cst)# 示例(内部使用):
# 假设原始tanh函数
raw_tanh = torch.tanh# 归一化使其对正态输入的二阶矩为1
normalized_tanh = normalize2mom(raw_tanh)# 现在,如果将normalized_tanh传递给e3nn.nn.Activation,它将使用此缩放版本。
这展示了normalize2mom如何预缩放激活函数以保持理想的统计属性,这对于深度网络中的稳定训练至关重要。
结论
归一化是任何深度学习模型中稳定训练的关键组件,e3nn提供了强大、等变的解决方案。
通过理解component和norm归一化的区别,以及e3nn.nn.BatchNorm和e3nn.math.normalize2mom如何分别将这些概念应用于Irreps和标量激活?
对比
- 适用对象:BatchNorm 直接作用于 Irreps 的
所有阶数特征;normalize2mom仅对标量激活生效。 - 统计量计算:BatchNorm 依赖运行时
批统计量;normalize2mom 基于理论二阶矩或预计算的经验值。 - 使用场景:BatchNorm 用于训练时
稳定特征分布;normalize2mom 用于确保激活函数的输出尺度一致。
我们获得了构建强大可靠等变神经网络的另一个基本工具。
这些技术确保网络内部表示保持良好行为,防止常见的训练问题。
在最后一章,我们将探索如何使用**TorchScript JIT支持**优化e3nn模型的部署和性能。
第6章:TorchScript JIT支持