通过官方文档详解Ultralytics YOLO 开源工程-熟练使用 YOLO11实现分割、分类、旋转框检测和姿势估计(附测试代码)
目录
前言:
1.了解ultralytics工程与yolo模型
1.1 yolo11可以为我们做些什
1.2 yolo11模型的高性能
1.3 对于yolo11一些常见的问题
1.3.1 YOLO11 如何以更少的参数实现更高的精度?
1.3.2 YOLO11 可以部署在边缘设备上吗?
2. 深入了解yolo11的使用
2.1 yolo环境配置
2.2 yolo创建模型实例化
2.3 yolo的predict()方法
2.3.1 基本语法
2.3.2 核心参数
2.4 yolo的Results对象
2.4.1 Results对象方法实例
2.5 yolo的实例分割
2.5.1Results对象中的,masks属性
2.5.2 Masks 的工作原理
2.5.3 实例分割示例
2.6 yolo的姿态估计
2.6.1 Results对象的Keypoint属性
2.6.2 Keypoints 的数据集与标注规范
2.6.3 姿态检测示例
结语
前言:
Ultralytics 是一个专注于计算机视觉领域的开源项目,以其高效的 YOLO (You Only Look Once) 系列目标检测算法实现而闻。该项目不仅提供了预训练模型,还包含了一套完整的工具链,支持从数据标注、模型训练到推理部署的全流程工作。YOLO 系列算法从 v3 发展到最新的 v11,在模型结构、训练策略、推理速度和精度上进行了持续优化。
在本文中我们就是通过yolo11系列去展开yolo功能详解
1.了解ultralytics工程与yolo模型
这里给出ultralytics的官方文档链接Ultralytics YOLO11 - Ultralytics YOLO 文档 这里面有对该工程的详细介绍,你想要的内容基本都会提及。
下面对于ultralytics工程和最新的yolo11模型我也做出简要的总结
1.1 yolo11可以为我们做些什
YOLO11 模型用途广泛,支持各种计算机视觉任务,包括:
- 目标检测: 识别和定位图像中的目标。
- 实例分割: 检测目标并描绘其边界。
- 图片分类: 将图像分类为预定义的类别。
- 姿势估计: 检测和跟踪人体上的关键点。
- 旋转框检测 (OBB): 检测具有旋转的对象,以获得更高的精度。
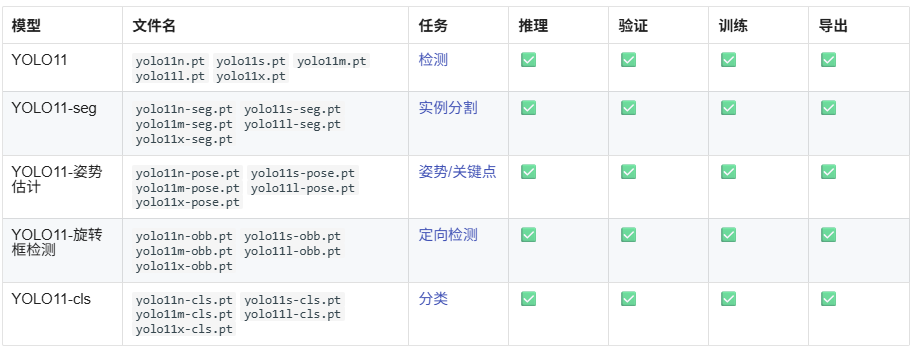
具体功能我们将在后面用到
1.2 yolo11模型的高性能
每一次yolo模型的更新在性能上都称得上是一次质的飞跃,到现在最新的yolo11可以说是十分成熟的视觉模型。
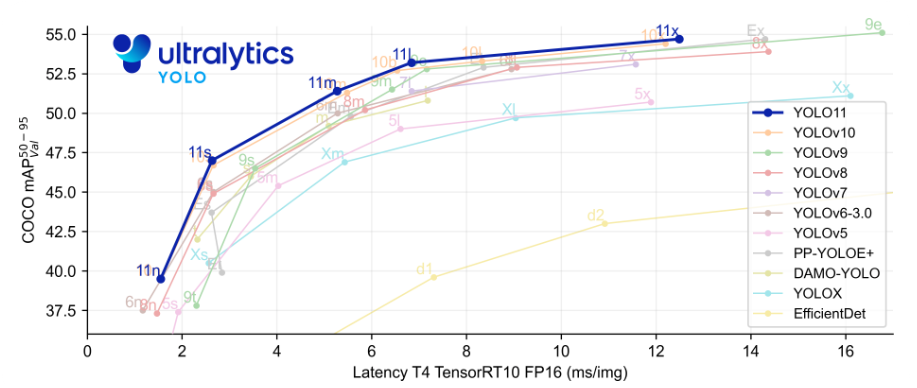
下面是官方对最新yolo11的描述
- 增强的特征提取: YOLO11 采用了改进的骨干网络和颈部架构,增强了特征提取能力,从而实现更精确的目标检测。
- 优化的效率和速度: 改进的架构设计和优化的训练流程提供了更快的处理速度,同时保持了准确性和性能之间的平衡。
- 以更少的参数实现更高的精度: YOLO11m 在 COCO 数据集上实现了更高的平均精度均值 (mAP),与 YOLOv8m 相比,参数减少了 22%,从而在不影响准确性的前提下提高了计算效率。
- 跨环境的适应性: YOLO11 可以部署在各种环境中,包括边缘设备、云平台和支持 NVIDIA GPU 的系统。
- 广泛支持的任务范围: YOLO11 支持各种计算机视觉任务,例如目标检测、实例分割、图像分类、姿势估计和旋转框检测 (OBB)。
1.3 对于yolo11一些常见的问题
1.3.1 YOLO11 如何以更少的参数实现更高的精度?
通过模型设计和优化技术的进步,YOLO11 以更少的参数实现了更高的准确率。 改进的架构允许高效的特征提取和处理,从而在使用比 YOLOv8m 少 22% 的参数的同时,在 COCO 等数据集上实现更高的平均精度 (mAP)。 这使得 YOLO11 在计算上高效,同时又不影响准确性,使其适合部署在资源受限的设备上。
1.3.2 YOLO11 可以部署在边缘设备上吗?
是的,YOLO11 旨在适应各种环境,包括边缘设备。其优化的架构和高效的处理能力使其适合部署在边缘设备、云平台和支持 NVIDIA GPU 的系统上。这种灵活性确保了 YOLO11 可用于各种应用,从移动设备上的实时检测到云环境中的复杂分割任务。有关部署选项的更多详细信息,请参阅导出文档。
这里我要提到的是其实我们一些常用的视觉模块k230,Jetson Nano,Coral TPU(谷歌),瑞芯微RKNN芯片:如RK3566、RK3588等边缘设备都可以部署YOLO模型!后续会更新在这些设备上部署yolo。
2. 深入了解yolo11的使用
要了解yolo11的使用我们主要掌握predict()方法和Results对象
2.1 yolo环境配置
Ultralytics 开源工程主要使用 Python 语言开发,该工程基于 PyTorch 深度学习框架,而 PyTorch 的主要接口和生态系统以 Python 为核心;
我想表达的意思是使用yolo模型需要一个比较严格的python环境,这个复杂的过程在我另一篇博客中有详细的过程,下面是博客链接(超详细)yolo11机器视觉模型环境配置(附带摄像头识别测试)_yolo11环境配置-CSDN博客
2.2 yolo创建模型实例化
在官方的文档中有下面一句话
PyTorch pretrained *.pt 模型以及配置 *.yaml 文件可以传递给 YOLO() 类在 Python 中创建模型实例:
于是通过下面的代码我们可以创建模型实例化,以及查看是否实例化成功,以及查看关于该模型的一些信息。
from ultralytics import YOLO #导入必要的库
model = YOLO('yolo11n.pt') # 模型路径# 检查模型信息
print(f"模型类别数: {model.model.nc}")
print(f"模型类别名称: {model.names}")# 获取模型输入尺寸
print(f"模型输入尺寸: {model.model.args.get('imgsz', 640)}")我的pycharm控制台输出下面信息

可以看到我们这个模型可以识别80种物品,随后打印出可以识别物品的类别以及编号。
2.3 yolo的predict()方法
2.3.1 基本语法
results = model.predict(source, **kwargs)- 返回值 :若输入为单张图像 / 单帧视频,返回一个Results对象;若输入为批量图像 / 视频流,返回Results对象的列表(或生成器,取决于stream参数)。
2.3.2 核心参数
| 参数名 | 类型 | 作用 | 默认值 | 实用场景 |
|---|---|---|---|---|
source | 多种类型 | 输入源(推理对象) | 必需参数 | 支持:图像路径("img.jpg")、视频路径("video.mp4")、摄像头 ID(0表示默认摄像头)、RTSP 流("rtsp://...")、numpy 数组(cv2读取的图像)、PIL 图像等。 |
conf | float | 置信度阈值 | 0.25 | 过滤低置信度目标(如conf=0.5表示只保留置信度≥50% 的结果)。值越高,结果越严格(误检少,但可能漏检)。 |
iou | float | 非极大值抑制(NMS)的 IOU 阈值 | 0.45 | 解决目标框重叠问题(如多个框检测同一目标)。值越高,允许的重叠度越大(可能保留重复框);值越低,会过滤更多重叠框。 |
classes | list[int] | 指定检测的类别 | None(检测所有类别) | 只检测特定目标,如classes=[0](只检测 “人”,0 是 COCO 数据集的 “人” 类别 ID)、classes=[2, 3](只检测 “汽车” 和 “摩托车”)。 |
imgsz | int/tuple | 输入图像尺寸 | 640 | 模型推理时将输入缩放到该尺寸(如640表示 640×640,(800, 600)表示宽 800× 高 600)。尺寸越大,精度可能越高,但速度越慢。 |
device | str/int | 推理设备 | 自动选择(优先 GPU) | 指定用 CPU("cpu")或 GPU(0表示第 1 块 GPU,"0,1"表示多 GPU)。测试时用 CPU 方便,批量处理用 GPU 加速。 |
stream | bool | 是否启用流模式 | False | 处理视频 / 摄像头时建议设为True,通过生成器逐帧返回结果,大幅节省内存(尤其长视频)。 |
save | bool | 是否自动保存结果 | False | 设为True时,自动将标注后的图像 / 视频保存到runs/detect/exp*目录(可通过project和name参数自定义路径)。 |
show | bool | 是否实时显示结果 | False | 处理摄像头 / 视频时设为True,会弹出窗口实时显示带检测框的画面(需要 GUI 支持)。 |
下面我在origin目录下放了一张包含人和狗的图片(但是我让他只识别人),然后识别后放在result/personanddog目录下,
代码如下
from ultralytics import YOLO
import os#如果文件夹不存在将创建文件夹
os.makedirs("result",exist_ok=True)#实例化模型
model = YOLO("yolo11n.pt")#执行预测
results = model.predict(source="origin/personandgod.jpg", #要识别的图片路径 conf = 0.5, #置信度设置(低于该置信度将不会被框选)classes = [0], #只需要识别人project = "result", #要保存的文件地址name = "personandgod_s", #保存在该名下save=True #确保文件被保存)
如上图他只把任务框选出来了,那大家根据参数设置我们该如何做到只识别狗呢?尝试一下这个小实验。
下面做一个摄像头实时识别实验,还是让他只识别人。其实不用yolo自带的视频实时显示我问也可以使用python cv2库中的方法实现视频显示,大家可以试试看。
from ultralytics import YOLO
import cv2model = YOLO("yolo11n.pt")results = model.predict(source=0, # 本地摄像头show=True, # 实时显示stream=True, # 流模式省内存classes = [0], #只识别人物conf=0.4, # 适中的置信度阈值imgsz=640 #尺寸大小
)
for r in results: # 逐帧处理if cv2.waitKey(1) & 0xFF == ord('q'): #按q退出break效果如下图
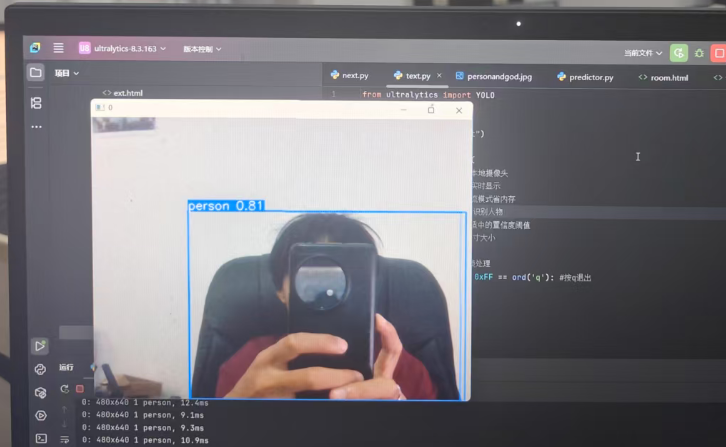
可以看到即使有遮挡物识别效果依旧精准!
2.4 yolo的Results对象
predict() 方法返回一个 Results 对象或 Results 对象列表,包含丰富的检测信息。可以说Results是 YOLO 推理结果的 “容器”,封装了从输入到输出的所有信息(原始图像、检测框、类别等)。对于目标检测任务
1. 基础属性(通用信息):
| 属性名 | 类型 | 含义 |
|---|---|---|
orig_img | numpy.ndarray | 原始输入图像(BGR 格式,可直接用cv2处理)。 |
orig_shape | tuple | 原始图像的尺寸,格式为(height, width)(如(480, 640)表示高 480 像素,宽 640 像素)。 |
path | str | 输入图像 / 视频帧的路径(或摄像头 ID)。 |
boxes | Boxes对象 | 检测到的目标边界框信息(核心属性,下文详细说明)。 |
2. 核心属性:boxes(边界框信息)
boxes是Results中最常用的属性,类型为Boxes对象,封装了所有检测到的目标的边界框、类别、置信度等信息。其常用子属性如下:
| 子属性 | 类型 | 含义 | 示例 |
|---|---|---|---|
xyxy | torch.Tensor | 目标框坐标(绝对坐标),格式为(x1, y1, x2, y2),其中(x1,y1)是左上角,(x2,y2)是右下角。 | 若box.xyxy = tensor([[100, 200, 300, 400]]),表示目标框左上角在 (100,200),右下角在 (300,400)。 |
xywh | torch.Tensor | 目标框坐标(绝对坐标),格式为(x_center, y_center, width, height)(中心坐标 + 宽高)。 | tensor([[200, 300, 200, 200]])表示中心在 (200,300),宽 200,高 200。 |
xyxyn/xywhn | torch.Tensor | 归一化坐标(相对图像尺寸,范围 0~1),用途同上(方便跨尺寸统一处理)。 | 若图像宽 640,xyxyn中0.5表示 320 像素位置。 |
conf | torch.Tensor | 每个目标的置信度(0~1)。 | tensor([0.85])表示置信度 85%。 |
cls | torch.Tensor | 每个目标的类别 ID(对应model.names中的索引)。 | tensor([0.])表示类别 ID 为 0(通常是 “人”)。 |
id | torch.Tensor | 目标跟踪 ID(仅在track()方法中存在,用于多帧关联同一目标)。 | tensor([5.])表示该目标的跟踪 ID 为 5。 |
len(boxes) | int | 检测到的目标数量。 | len(result.boxes) = 3表示检测到 3 个目标。 |
3. Results对象的常用方法
| 方法 | 作用 | 示例 |
|---|---|---|
plot() | 生成带检测框的图像(可视化结果),返回numpy.ndarray(BGR 格式)。 | annotated_img = result.plot(line_width=2, conf=True)(自定义线宽,显示置信度)。 |
save(save_dir) | 保存带检测框的图像到指定目录。 | result.save("output_dir")(保存到output_dir文件夹)。 |
save_crop(save_dir) | 裁剪每个检测到的目标并保存到指定目录。 | result.save_crop("cropped_objects")(每个目标单独存为一张图)。 |
tojson() | 将结果转换为 JSON 字符串(方便存储和传输)。 | json_str = result.tojson()。 |
Results对象方法实在太多,其子属性的子方法也是很多,下面代码展示常用方法的使用
2.4.1 Results对象方法实例
下面的代码是对工程目录origin目录下test.jpg图片的识别,图片中有两个人物,具体作用看注释
from ultralytics import YOLOmodel = YOLO("yolo11n.pt")
results = model.predict("origin/test.jpg", conf=0.5) # 单张图像推理# 取第一个结果(单张图像只有一个Results对象)
result = results[0]# 1. 基础信息
print(f"原始图像尺寸: {result.orig_shape}") # 输出 (高度, 宽度)
print(f"图像路径: {result.path}")
print(f"检测到的目标数量: {len(result.boxes)}")# 2. 遍历所有检测到的目标
for i, box in enumerate(result.boxes):# 边界框坐标(转换为列表方便处理)x1, y1, x2, y2 = box.xyxy[0].tolist() # 绝对坐标# 类别与置信度cls_id = int(box.cls[0]) # 类别IDcls_name = model.names[cls_id] # 类别名称(如"person")conf = float(box.conf[0]) # 置信度# 输出信息print(f"目标{i + 1}:")print(f" 类别: {cls_name} (ID: {cls_id})")print(f" 置信度: {conf:.2f}")print(f" 边界框: 左上角({x1:.1f}, {y1:.1f}), 右下角({x2:.1f}, {y2:.1f})")# 3. 实例化并保存结果
annotated_img = result.plot(line_width=3, # 边界框线宽font_size=10, # 字体大小conf=True, # 显示置信度labels=True # 显示类别名称
)
result.save("result/test.jpg") # "路径"
# 或手动用cv2保存
import cv2cv2.imwrite("result/custom_result.jpg", annotated_img)下面是打印信息
检测到的目标数量: 2
目标1:
类别: person (ID: 0)
置信度: 0.63
边界框: 左上角(4.3, 212.8), 右下角(1178.8, 1276.9)
目标2:
类别: person (ID: 0)
置信度: 0.56
边界框: 左上角(768.6, 42.2), 右下角(1705.0, 1276.1)
可以看到结果也是符合我们预期,也是在result文件夹中保存了两张识别后的图片,下面是识别结果(花是我后期加的)。

最后提一句
遍历顺序和规则,按检测置信度降序排列(默认行为)!
不过也可以更改排序,这里不在多说
2.5 yolo的实例分割
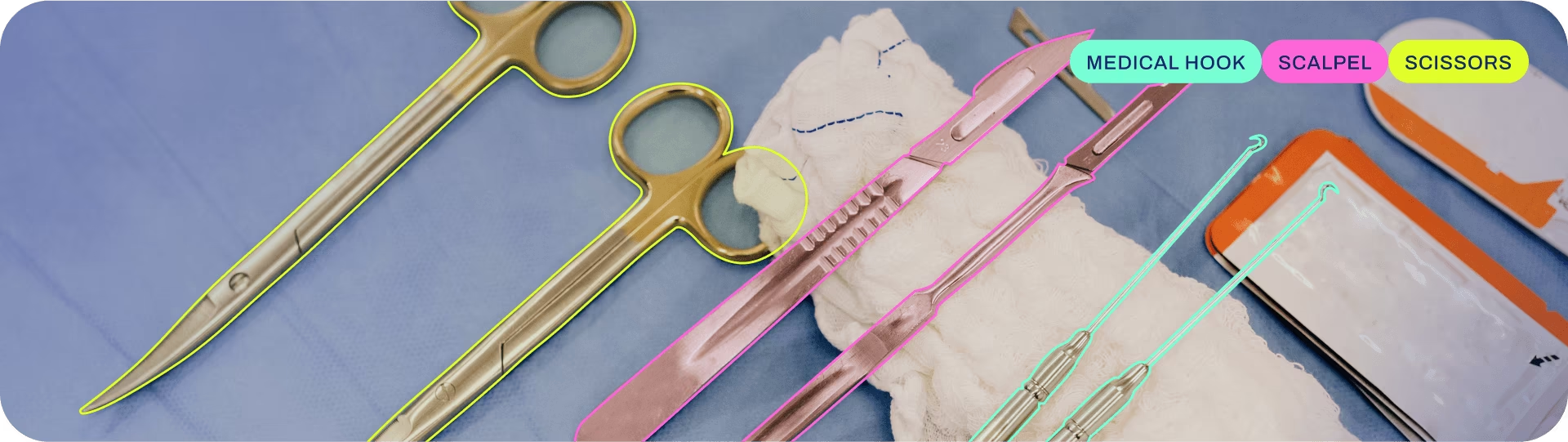
实例分割结合了目标检测(在哪里,是什么)和语义分割(每个像素属于什么)。它不仅需要识别出图像中的每个物体并确定其边界框,还要精确地勾勒出每个物体的像素级轮廓。这意味着同一类别的不同实例会被区分开来。
实例分割模型的输出是一组掩码或轮廓,它们勾勒出图像中每个对象,以及每个对象的类别标签和置信度分数。 当您不仅需要知道对象在图像中的位置,还需要知道它们的精确形状时,实例分割非常有用。
2.5.1Results对象中的,masks属性
在YOLO-seg等模型中(后缀带seg),执行实例分割预测后,会返回一个Results对象,其中包含的masks属性就是关键。它包含了模型分割出的所有实例的掩码信息。
Masks对象通常包含以下重要属性:
| 属性名 | 数据类型 | 描述 |
|---|---|---|
data | torch.Tensor | 最核心的属性,存储了所有实例的掩码张量,形状通常为 (n, H, W),其中 n 是实例数量,H和W是掩码的高度和宽度。 |
xy | List[ndarray] | 一个列表,每个元素是一个ndarray,表示一个实例掩码的轮廓坐标点(相对于图像原图)。 |
xyn | List[ndarray] | 类似xy,但坐标是经过归一化(Normalized)的,值在0到1之间。 |
-
data(Tensor):
这是最核心的掩码数据。它是一个三维张量,形状通常为(n, H, W),其中:n是检测到的实例数量。H和W是掩码的高度和宽度(通常是原图经过模型处理后的输出尺寸,如160x160,而非原图尺寸)。这个张量中的每个值通常在0到1之间,表示该像素属于该实例的概率。通过设置一个阈值(如0.5),可以将其转换为二值掩码。 -
xy(List[ndarray]):
这是一个列表,列表中的每个元素是一个NumPy数组(ndarray),表示一个实例掩码的轮廓坐标点。这些坐标是相对于原始图像尺寸的绝对坐标,格式通常是[[x1, y1], [x2, y2], ..., [xn, yn]]。这非常有用,例如可以直接用cv2.polylines在原图上绘制轮廓。 -
xyn(List[ndarray]):
与xy类似,但坐标是归一化(Normalized) 的,值在0到1之间。适合某些需要相对坐标的计算场景。
2.5.2 Masks 的工作原理
YOLO的实例分割模型(如YOLACT/YOLOv5/8-seg)其核心思想是将复杂的实例分割任务分解为两个并行的子任务:
-
生成原型掩码 (Prototype Masks):一个全卷积网络(FCN)分支(称为Protonet)接收主干网络的特征,输出一组k个图像大小的“原型掩码”(prototype masks)。这些原型掩码是类别无关的,它们负责编码图像中各种可能的形状、边缘和纹理等基础特征。
-
预测掩码系数 (Mask Coefficients):在目标检测分支(预测边界框和类别)上,额外为每个检测到的锚点(anchor)预测一个k维的“掩码系数”向量。这个向量定义了如何将那些原型掩码线性组合起来,以形成当前实例独有的掩码1。
最终实例掩码的生成,就是通过将原型掩码与该实例对应的掩码系数进行线性组合(通常是矩阵乘法)。
2.5.3 实例分割示例
下面这段代码还用到了python的os库(一些文件目录操作),opencv库(一些文件操作),numpy库(是 Python 中用于科学计算和数值分析的核心库,也是整个 Python 数据科学、机器学习、工程计算生态的基础。它的主要作用是提供高性能的多维数组对象和一系列用于数组操作的工具,解决了 Python 原生数据结构(如列表)在数值计算中的效率问题。)要完全理解还需要一点语法知识。
from ultralytics import YOLO
import cv2
import numpy as np
import os # 添加os模块用于创建目录# 创建result目录(如果不存在)
os.makedirs('result', exist_ok=True)model = YOLO('yolo11n-seg.pt') # 注意模型后缀-seg# 对图像进行预测
results = model('origin/testmasks.jpg',classes = [0]) # 图片路径
result = results[0] # 获取图片结果# 检查是否检测到任何实例
if result.masks is not None:# 获取Masks对象masks = result.masks# 方法1: 获取所有掩码的张量数据 (n, H, W)masks_data = masks.data # torch.Tensorprint(f"检测到 {len(masks_data)} 个实例")print(f"掩码张量形状: {masks_data.shape}")# 方法2: 获取每个实例的轮廓坐标(绝对坐标)masks_xy = masks.xyprint(f"第一个实例的轮廓坐标点:\n {masks_xy[0]}")# 方法3: 获取每个实例的轮廓坐标(归一化坐标)masks_xyn = masks.xynprint(f"第一个实例的归一化轮廓坐标点:\n {masks_xyn[0]}")# 读取原始图像img = cv2.imread('origin/testmasks.jpg')img_copy = img.copy()# 为不同的实例随机生成颜色colors = [tuple(np.random.randint(0, 255, 3).tolist()) for _ in range(len(masks_data))]# 方法1: 使用轮廓坐标在原图上绘制轮廓for i, mask_points in enumerate(masks.xy):# 将点转换为整数类型points = np.array(mask_points, dtype=np.int32)# 绘制多边形轮廓cv2.polylines(img_copy, [points], isClosed=True, color=colors[i], thickness=2)# (设置透明度)overlay = img.copy()cv2.fillPoly(overlay, [points], color=colors[i])alpha = 0.3 # 透明度img_copy = cv2.addWeighted(overlay, alpha, img_copy, 1 - alpha, 0)# 保存绘制轮廓的图像到result目录cv2.imwrite('result/contours_filled.jpg', img_copy)# 显示结果cv2.imshow('Mask Visualization', img_copy)cv2.waitKey(0)cv2.destroyAllWindows()# 方法2: 直接使用掩码数据(需要调整到原图大小)if masks_data is not None:# 获取原图尺寸orig_h, orig_w = img.shape[:2]# 获取模型输出掩码的尺寸mask_h, mask_w = masks_data.shape[1:]for i, mask_tensor in enumerate(masks_data):# 将掩码张量转换为NumPy数组,并调整到原图大小mask_resized = cv2.resize(mask_tensor.cpu().numpy(), (orig_w, orig_h))# 二值化处理_, binary_mask = cv2.threshold(mask_resized, 0.5, 255, cv2.THRESH_BINARY)binary_mask = binary_mask.astype(np.uint8)# 在原图上应用掩码masked_region = cv2.bitwise_and(img, img, mask=binary_mask)# 保存每个实例的掩码区域到result目录cv2.imwrite(f'result/instance_{i}_mask.jpg', masked_region)# 显示每个实例的掩码区域(这里只是示例,实际可能需要组合显示)cv2.imshow(f'Instance {i} Mask', masked_region)cv2.waitKey(0)cv2.destroyAllWindows()# 创建一个黑色背景,用于放置抠出的实例for i, mask_tensor in enumerate(masks_data):# 调整掩码大小至原图尺寸orig_h, orig_w = img.shape[:2]mask_resized = cv2.resize(mask_tensor.cpu().numpy(), (orig_w, orig_h))# 创建二值掩码_, binary_mask = cv2.threshold(mask_resized, 0.5, 255, cv2.THRESH_BINARY)binary_mask = binary_mask.astype(np.uint8)# 使用二值掩码从原图中抠出实例segmented_obj = cv2.bitwise_and(img, img, mask=binary_mask)# (可选) 将背景设置为黑色以外的颜色,例如白色white_bg = np.full_like(img, 255)segmented_obj_white_bg = cv2.bitwise_or(white_bg, white_bg, mask=cv2.bitwise_not(binary_mask))segmented_obj_white_bg = cv2.bitwise_or(segmented_obj, segmented_obj_white_bg)# 保存抠出的实例到result目录cv2.imwrite(f'result/instance_{i}.png', segmented_obj_white_bg)print(f"实例 {i} 已保存为 result/instance_{i}.png")
else:print("未检测到任何实例。")实验结果我这里因为篇幅问题也只放出结果图,其实图中的滑板也是可以作为检测目标的大家可以试一试。

最后讲一讲我对于掩码这个专业术语的理解,把掩码比作一个由0,1组成的二维矩阵,我们认为为1的像素点组成的一片区域就是我们要检测的目标。把这一片“1”的区域提取出来就是每个目标的实例掩码。

2.6 yolo的姿态估计

姿势估计是一项涉及识别图像中特定点的位置的任务,这些点通常称为关键点。关键点可以代表对象的各个部分,例如关节、地标或其他独特特征。关键点的位置通常表示为一组 2D [x, y] 或 3D [x, y, visible] 坐标。
姿势估计模型的输出是一组点,这些点代表图像中对象上的关键点,通常还包括每个点的置信度分数。当您需要识别场景中对象的特定部分及其彼此之间的位置时,姿势估计是一个不错的选择。
2.6.1 Results对象的Keypoint属性
在YOLO-pose等模型中(后缀带pose),执行实例姿态估计预测后,会返回一个Results对象,其中包含的keypoints属性就是关键。它包含了模型分割出的所有实例的掩码信息。
Keypoints 对象的构成:
YOLO 中每个 Keypoint(单个关键点)通常由 3 个核心参数组成,而一个目标的 Keypoints 则是这些单个关键点的集合:
1. 坐标(x, y)
表示关键点在图像中的位置,通常为归一化坐标(即相对于图像宽高的比例,范围 [0,1]),也可转换为像素坐标(x = x_norm × 图像宽度,y = y_norm × 图像高度)。
例如:(0.5, 0.3) 表示关键点位于图像水平中线、垂直方向 30% 的位置。
2. 置信度(confidence)
表示模型对该关键点 "存在性" 的信任程度(范围 [0,1])。
置信度越高,说明模型认为该位置确实存在一个关键点;若低于阈值(如 0.5),通常会被过滤掉。
3. 可见性(visibility,可选)
部分版本中会包含该参数,用于标识关键点是否被遮挡:
0:完全不可见(被遮挡);
1:部分可见;
2:完全可见。
2.6.2 Keypoints 的数据集与标注规范
在官方的文档中我们可以找到这样一段重要内容!
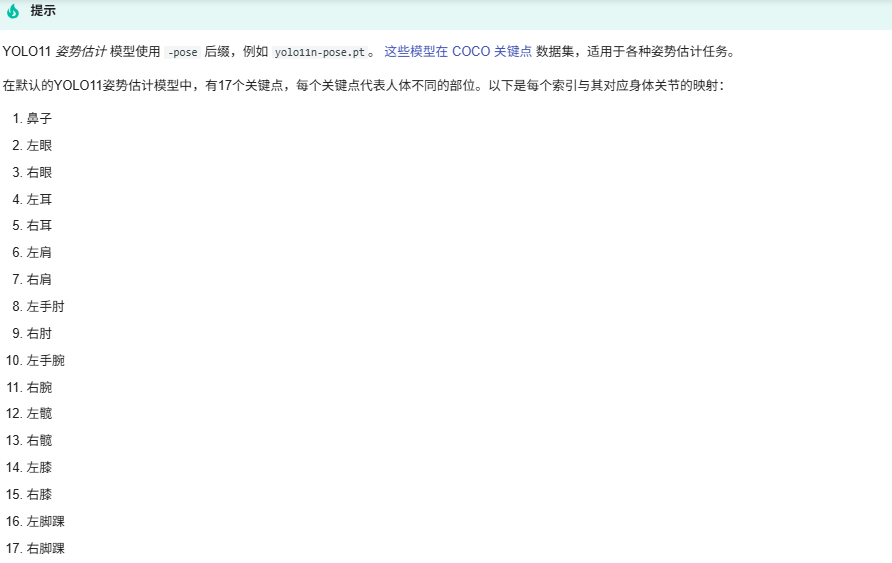
简单解释就是
Keypoints 的定义依赖于数据集的标注规范,不同数据集对关键点的数量和含义有不同约定:COCO(Common Objects in Context):
人体姿态:17 个关键点(如 0 - 鼻子、1 - 左眼、2 - 右眼、3 - 左耳、4 - 右耳、5 - 左肩、6 - 右肩等);标注格式:每个目标对应一个长度为 3×N 的数组(N 为关键点数量),依次存储 (x1, y1, c1, x2, y2, c2, ..., xN, yN, cN),其中 c 为置信度 / 可见性。
MPII Human Pose:人体姿态:16 个关键点(侧重四肢细节,如脚踝、膝盖、髋关节等)。
自定义数据集:可根据任务需求定义关键点(如手势估计中的 5 个手指端点)。
2.6.3 姿态检测示例
import cv2
from ultralytics import YOLO# 实例化模型
model = YOLO('yolo11n-pose.pt') # 注意模型后缀-pose
# 实例化对象
results = model('origin/testkeypoint.jpg',show = True,save = True,project = 'result',name = 'key.jpg') # 图片路径# 获取结果
result = results[0] # 因为这里只推理了一张图片,所以取第一个结果# 获取原图尺寸,用于将归一化坐标转换回像素坐标
img_height, img_width = result.orig_shape# 可视化结果(可选,Ultralytics 自带绘图功能,但这里我们手动绘制以理解过程)
# result.show() # 最简单的方法,直接显示带注释的图片# 手动处理 Keypoints 数据
# 复制一份原图用于绘制
annotated_img = result.orig_img.copy()# 定义关键点名称(COCO数据集的关键点顺序)
keypoint_names = ["nose", "left_eye", "right_eye", "left_ear", "right_ear","left_shoulder", "right_shoulder", "left_elbow", "right_elbow","left_wrist", "right_wrist", "left_hip", "right_hip","left_knee", "right_knee", "left_ankle", "right_ankle"
]# 遍历每一个被检测到的人
for person_idx, person in enumerate(result):# 获取该人的所有关键点数据 (Tensor形状为 [17, 3])keypoints = person.keypoints.data[0] # 取出当前人的关键点数据# 遍历每一个关键点 (共17个)for i, (x, y, conf) in enumerate(keypoints):# 将归一化坐标转换为像素坐标x_pixel = int(x * img_width)y_pixel = int(y * img_height)# 如果关键点置信度高于阈值,则绘制它if conf > 0.3: # 置信度阈值,可调整color = (0, 255, 0) # 绿色点cv2.circle(annotated_img, (x_pixel, y_pixel), 5, color, -1) # 画实心圆# 可选:添加关键点索引标签cv2.putText(annotated_img, str(i), (x_pixel+5, y_pixel), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1)# 绘制骨骼连接线# 定义需要连接的骨骼对 (使用上面提到的关键点索引)skeleton = [(5, 6), (5, 7), (7, 9), (6, 8), (8, 10), # 手臂和肩膀(5, 11), (6, 12), (11, 12), # 身体躯干(11, 13), (13, 15), (12, 14), (14, 16) # 腿和臀部]for start_idx, end_idx in skeleton:# 获取起始点和结束点的坐标和置信度start_kpt = keypoints[start_idx]end_kpt = keypoints[end_idx]# 提取坐标和置信度x1, y1, conf1 = start_kptx2, y2, conf2 = end_kpt# 转换为像素坐标x1_pix = int(x1 * img_width)y1_pix = int(y1 * img_height)x2_pix = int(x2 * img_width)y2_pix = int(y2 * img_height)# 如果两个点的置信度都足够高,才绘制这条骨骼线if conf1 > 0.3 and conf2 > 0.3:cv2.line(annotated_img, (x1_pix, y1_pix), (x2_pix, y2_pix), (255, 0, 0), 2) # 蓝色线,粗细为2# 显示手动绘制后的图像
cv2.imwrite('result/keypoint.jpg', annotated_img) # 保存识别后的图片
cv2.waitKey(0) # 按任意键关闭窗口
cv2.destroyAllWindows()# 打印详细的数值信息
print(f"检测到 {len(result)} 个人")
for i, person in enumerate(result):print(f"\n--- 第 {i+1} 个人 ---")print(f"边界框置信度: {person.boxes.conf.item():.2f}")keypoints = person.keypoints.data[0]for j, (x, y, conf) in enumerate(keypoints):# 使用预定义的关键点名称而不是模型名称print(f"关键点 {j} ({keypoint_names[j]}): X={x:.2f}, Y={y:.2f}, Conf={conf:.2f}")这段代码注释已经比较详细,最后直接展示识别效果。
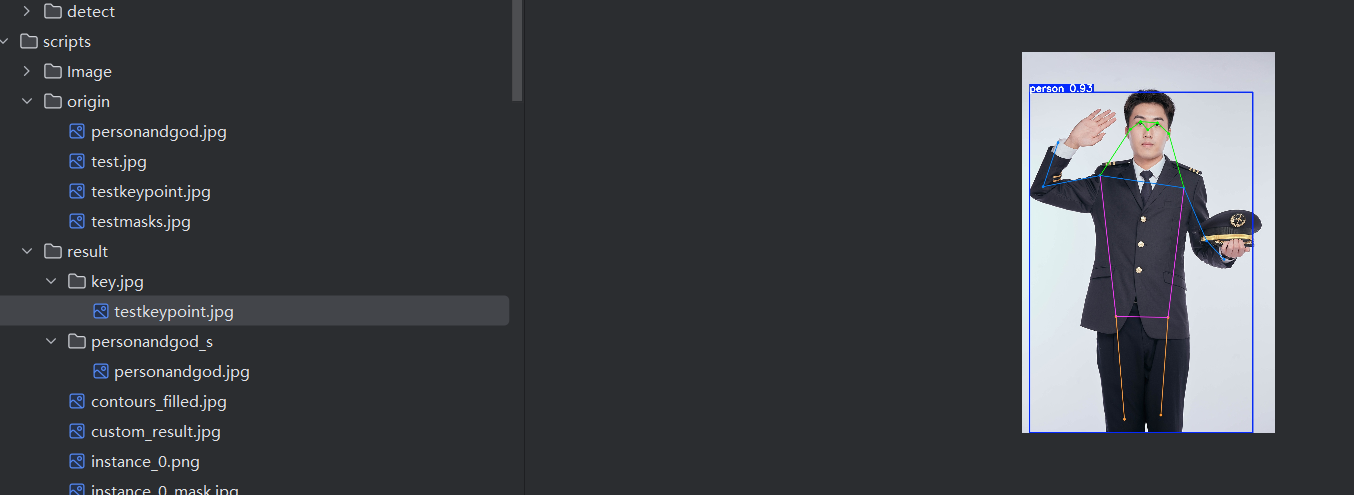
结语
最后到这里也就结束了,相信你看完一定惊叹于yolo的强大了,还有旋转角检测没有去做了。
如果有需要代码资源或者软件资源的可以直接找我。。