深度学习之PyTorch框架(安装,手写数字识别)
PyTorch框架认识
PyTorch是一个由Facebook人工智能研究院(FAIR)在2016年发布的开源深度学习框架,专为GPU加速的深度神经网络(DNN)编程而设计。它以其简洁、灵活和符合Python风格的特点,在科研和工业生产中得到了广泛应用。
1. Tensor张量
在PyTorch中,张量(Tensor)是核心数据结构,它是一个多维数组,用于存储和变换数据。张量类似于Numpy中的数组,但具有更丰富的功能和灵活性,特别是在支持GPU加速方面。
定义与特性
- 多维数组:张量可以看作是一个n维数组,其中n可以是任意正整数。它可以是标量(零维数组)、向量(一维数组)、矩阵(二维数组)或具有更高维度的数组。
- 数据类型统一:张量中的元素具有相同的数据类型,这有助于在GPU上进行高效的并行计算。
- 支持GPU加速:PyTorch中的张量可以存储在CPU或GPU上,通过将张量转移到GPU上,可以利用GPU的强大计算能力来加速深度学习模型的训练和推理过程。
创建方式
- 直接使用torch.tensor():根据提供的Python列表或Numpy数组创建张量。
- 下载数据集时:transform=ToTensor()直接将数据转化为Tensor张量类型。
2. 下载数据集
在PyTorch中,有许多封装了很多与图像相关的模型、数据集,那么如何获取数据集呢?
导入datasets模块:
from torchvision import datasets #封装了很多与图像相关的模型,数据集
以datasets模块中的MNIST数据集为例,包含70000张手写数字图像:60000张用于训练,10000张用于测试。图像是灰度的,28*28像素,并且居中的,以减少预处理和加快运行。
下载测试
我们来下载MNIST数据集:
from torchvision.transforms import ToTensor # 数据转换,张量,将其他类型数据转换为tensor张量
"""-----下载训练集数据集-----"""
training_data = datasets.MNIST(root="data",train=True,# 取训练集download=True,transform=ToTensor(),# 张量,图片是不能直接传入神经网络模型的
) # 对于pytorch库能够识别的数据,一般是tensor张量"""-----下载测试集数据集-----"""
test_data = datasets.MNIST(root="data",train=False,download=True,transform=ToTensor(),
)# numpy数组只能在CPU上运行,Tensor可以在GPU上运行,这在深度学习中可以显著提高计算速度
下载完成之后可在project栏查看。
展现下载内容
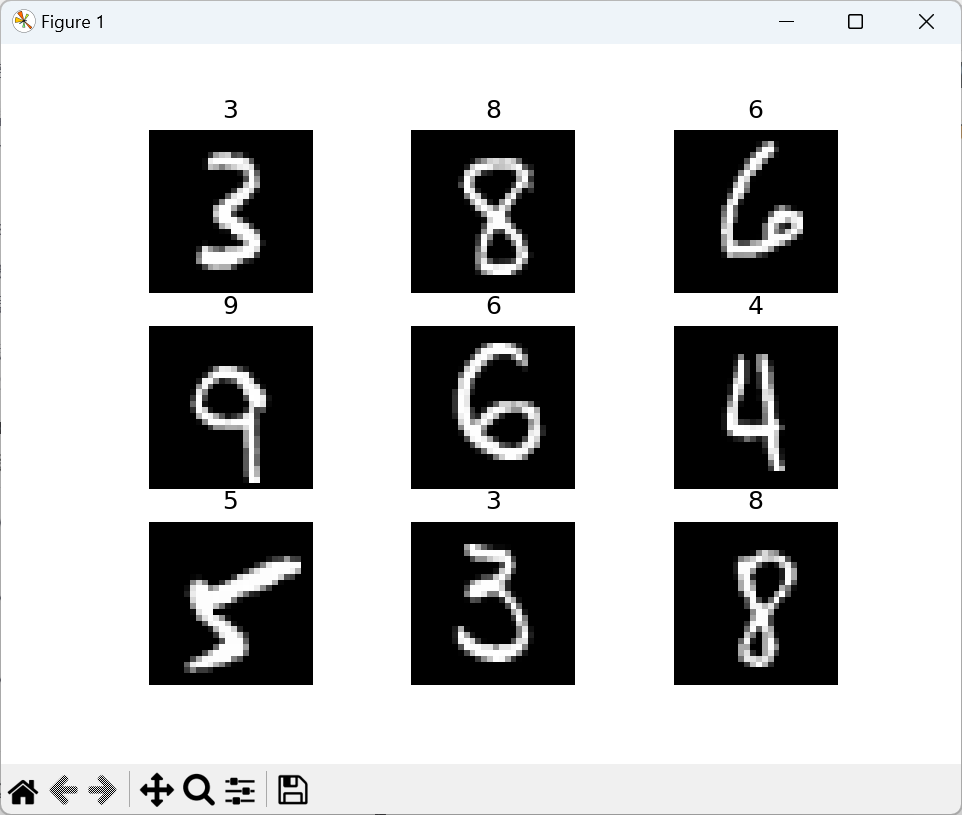
我们来查看部分图片(第59000张到第59009张):
"""-----展现手写字图片-----"""
# tensor -->numpy 矩阵类型数据
from matplotlib import pyplot as plt
figure = plt.figure() # 创建一个新的图形
for i in range(9):img,label = training_data[i+59000] #提取第59000张图片figure.add_subplot(3,3,i+1) #图像窗口中创建多个小窗口,小窗口用于显示图片plt.title(label)plt.axis("off")# 关闭当前轴的坐标轴plt.imshow(img.squeeze(),cmap="gray")a = img.squeeze()# squeeze()从张量img中去掉维度为1的。如果该维度不为1则张量不会改变
plt.show()
我们通过squeeze()函数,去掉维度为1的。这样我们就可以得到图片的高宽大小,将它展现出来:
3. 创建DataLoader(数据加载器)
在PyTorch中,创建DataLoader的主要作用是将数据集(Dataset)加载到模型中,以便进行训练或推理。DataLoader通过封装数据集,提供了一个高效、灵活的方式来处理数据。
DataLoader通过batch_size参数将数据集自动划分为多个小批次(batch),每一批次的放入模型训练,减少内存的使用,提高训练速度。
import torch
from torch.utils.data import DataLoader
"""
创建数据DataLoader(数据加载器)
batch_size:将数据集分成多份,每一份为batch_size(指定数值)个数据。
优点:减少内存的使用,提高训练速度
"""
train_dataloder = DataLoader(training_data,batch_size=64)# 64张图片为一个包
test_datalodar = DataLoader(test_data,batch_size=64)
# 查看打包好的数据
for x,y in test_datalodar: #x是表示打包好的每一个数据包print(f"Shape of x [N, C, H, W]:{x.shape}")print(f"Shape of y:{y.shape} {y.dtype}")break
-----------------------
Shape of x [N, C, H, W]:torch.Size([64, 1, 28, 28])
Shape of y:torch.Size([64]) torch.int64
4. 选择处理器
我们知道,电脑中的处理器有CPU和GPU两种,CPU擅长执行复杂的指令和逻辑操作,而GPU则擅长处理大量并行计算任务。
所以,在可以的条件下,我们选择使用GPU处理器来学习深度学习,因为计算量比较大:
"""---判断当前设备是否支持GPU,其中mps是苹果m系列芯片的GPU"""
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")
----------------
Using cuda device