机器学习-集成算法
集成学习的核心思想:集体智慧的力量
集成学习(ensemble learning)的理念源于一个朴素的道理:对于一个复杂任务,将多个专家的判断进行适当综合,往往比任何一个专家单独判断的结果更好。在机器学习中,这意味着通过构建并结合多个个体学习器来完成学习任务,最终输出由这些个体学习器的结果通过特定策略组合而成。
一、集成学习的结合策略
得到多个个体学习器的结果后,如何有效结合它们是集成学习的关键环节。常见的结合策略主要有以下几种:
简单平均法
这种方法直接对多个个体学习器的输出结果进行平均。对于回归任务,就是计算所有模型预测值的算术平均值;对于分类任务,可看作是一种 “一人一票” 的平等投票方式。其公式可表示为H(x)=T1∑i=1Thi(x),其中hi(x)是第i个个体学习器的输出,T是学习器的数量。
加权平均法
为了体现不同个体学习器的重要性差异,加权平均法为每个学习器分配一个权重,权重之和为 1(即∑i=1Tωi=1,且ωi≥0)。最终结果是多个学习器输出的加权求和,公式为H(x)=∑i=1Tωihi(x)。性能更好的学习器会被赋予更高的权重,从而在最终结果中占据更大的影响力。
投票法
在分类任务中,投票法是常用的结合策略,遵循 “少数服从多数” 的原则。每个个体学习器对样本类别进行预测,最终选择得票最多的类别作为集成模型的输出。不过,投票法的效果并非绝对,当个体学习器性能参差不齐或存在明显偏差时,可能出现集成不起作用甚至起负作用的情况,这需要我们合理选择和训练个体学习器。
二、集成算法的分类:不同的 “团队协作” 模式
根据个体学习器的生成方式,集成学习方法大致可分为三类,它们有着不同的 “团队协作” 模式:
Bagging:并行化的 “独立专家” 模式
Bagging 是一种并行化方法,其全称是 bootstrap aggregation,核心思想是训练多个分类器并取平均。在这种模式下,个体学习器间不存在强依赖关系,可以同时生成。
- 工作流程:通过有放回的采样(bootstrap)从原始数据集中生成多个不同的训练子集,每个子集训练一个个体学习器。
- 输出策略:对于分类任务使用简单投票法,对于回归任务使用简单平均法,公式为f(x)=M1∑m=1Mfm(x),其中M是学习器数量,fm(x)是第m个学习器的输出。
随机森林:Bagging 的典型代表
随机森林是 Bagging 思想的成功实践,它的核心在于 “随机” 和 “森林”:
- 随机:体现在数据采样随机和特征选择随机。通过有放回采样得到不同训练集,每个决策树训练时随机选择部分特征,减少了模型的过拟合风险。
- 森林:由多个决策树并行组成,最终结果通过多数投票(分类)或平均(回归)得到。
随机森林具有诸多优势:能处理高维度数据且无需特征选择;训练后可评估特征重要性;易于并行化,训练速度快;还可通过可视化分析决策过程,深受从业者青睐。
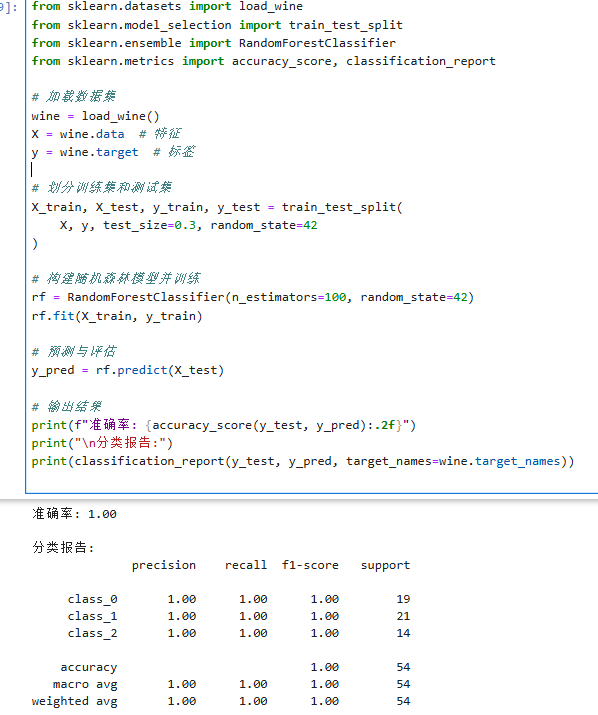
在实际应用中,RandomForestClassifier(分类)和RandomForestRegressor(回归)是常用的实现工具,关键参数包括树的数量(n_estimators,默认 100)、是否采用 Out of Bag 评估(oob_score)、采样方式(bootstrap,默认有放回采样)等。
Boosting:串行化的 “递进优化” 模式
Boosting 是一种序列化方法,个体学习器间存在强依赖关系,必须串行生成。它从弱学习器开始,通过不断加权调整训练数据,逐步提升模型性能,典型代表是 AdaBoost。
AdaBoost 的工作原理
- 初始化权重:训练样本初始时具有相同的权值分布。
- 训练弱分类器:根据当前样本权重训练弱分类器,若样本分类正确,下一轮权重降低;分类错误则权重提高,让模型更关注难分类的样本。
- 迭代训练:用更新权重后的样本集训练下一个弱分类器,重复迭代过程。
- 组合强分类器:所有弱分类器训练完成后,根据它们的分类误差率分配权重 —— 误差率小的弱分类器权重更高,最终通过加权组合形成强分类器。
这种 “递进优化” 的模式,让模型从 “弱” 到 “强” 逐步进化,不断修正错误,最终实现高性能的预测。
Stacking:多阶段的 “分层整合” 模式
Stacking(堆叠)是一种更 “暴力” 的集成方法,它可以整合多种不同类型的分类器(如 KNN、SVM、随机森林等),通过分阶段训练实现结果优化:
- 第一阶段:使用各种基础分类器对数据进行预测,得到各自的输出结果。
- 第二阶段:将第一阶段的预测结果作为新的特征,训练一个元分类器,最终输出整合后的预测结果。
Stacking 充分利用了不同模型的优势,通过分层训练实现 “强强联合”,在复杂任务中往往能取得出色表现。
三、总结
集成学习通过整合多个模型的力量,有效弥补了单一模型的不足,在分类、回归等任务中展现出卓越的性能。无论是并行化的 Bagging(如随机森林)、串行化的 Boosting(如 AdaBoost),还是分层整合的 Stacking,都为解决复杂机器学习问题提供了有力工具。