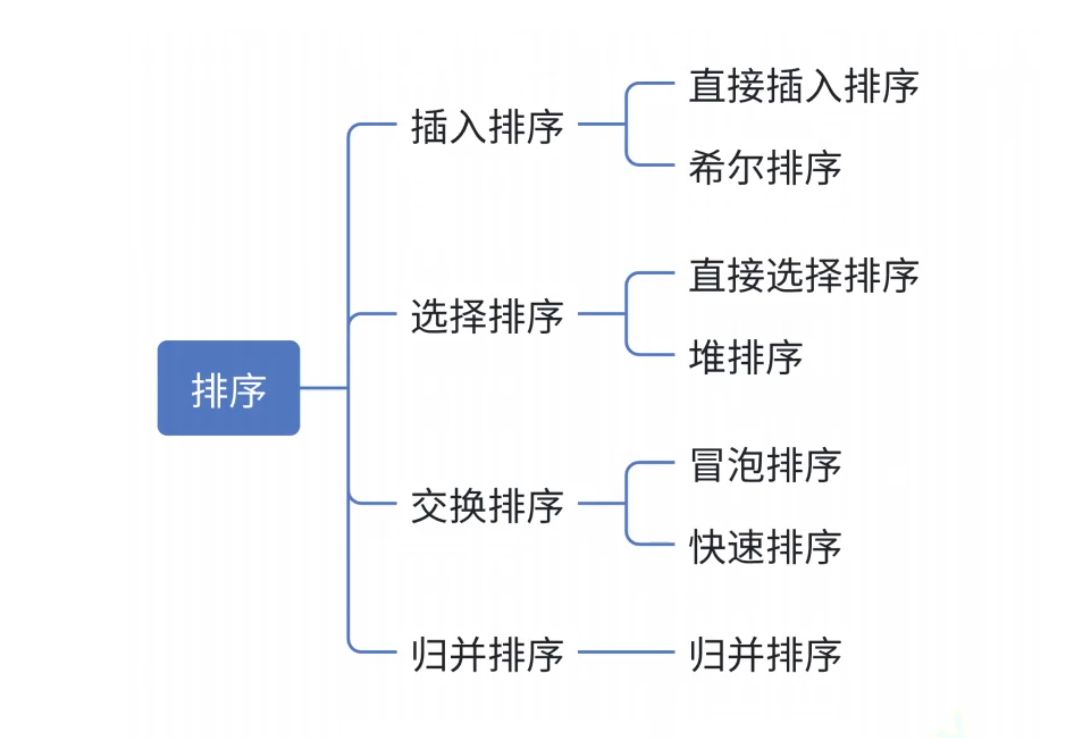
数据结构之排序大全(3)
今天我们的主角是交换排序。
交换排序
冒泡排序
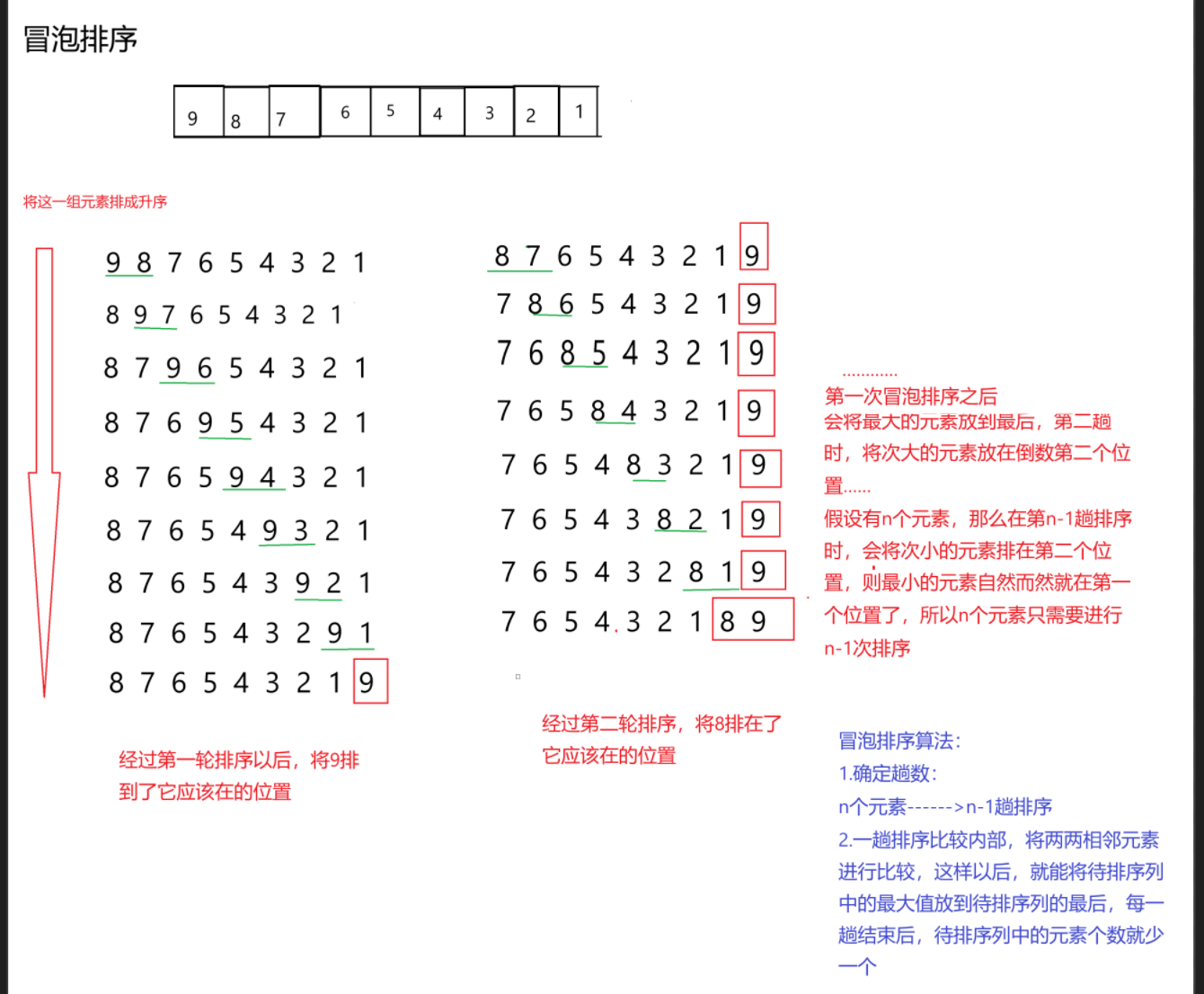
冒泡排序的本质:两两相邻的元素进行比较。
图示解析:
那我们就来动手写一下代码吧:
void BubbleSort(int* arr, int n)
{int i = 0;//确定趟数:若有n个元素,则需要进行n-1趟排序for (i = 0; i < n - 1; i++){//每趟排序内部,两两相邻比较for (int j = 0; j < n - 1 - i; j++){//升序:if (arr[j] > arr[j + 1]){int tmp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = tmp;}}}
}
冒泡排序的代码就是这样的,有没有什么可以再改进一下的地方呢?
假设待排序序列是:9 1 2 3 4 6 7 8
那么经过一趟排序算法以后,他会变成:1 2 3 4 5 6 7 8 9
这个序列就已经有序了,就不需要再进行排序了,但是根据我们这个算法来看,他还会再次将进入循环,这其实是没有必要的,也就是说,我们的代码还是有很大的优化空间的,当数组已经排好序以后,就不必再进入循环,可以直接跳出循环了。
那么,怎样判断数组是否有序呢?
从算法中来看,如果数组不是有序的,就会进行相邻元素的交换,那么当数组是有序时,就不会进行交换,我们可以根据这个来优化代码 :
//arr表示待排序数组,n表示数组中元素个数
void BubbleSort(int* arr, int n)
{int i = 0;//确定趟数:若有n个元素,则需要进行n-1趟排序for (i = 0; i < n - 1; i++){//标志变量flag:初始假设数组是有序的int flag = 1;//每趟排序内部,两两相邻比较for (int j = 0; j < n - 1 - i; j++){//升序:if (arr[j] > arr[j + 1]){//当发生相邻元素交换时,数组就不是有序的flag = 0;int tmp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = tmp;}}if(flag==1)break;}
}时间复杂度:O(n²)
最好情况:O(n)(已排序数组,优化后)
最坏情况:O(n²)(完全逆序)
快速排序
快速排序是 Hoare 于 1962 年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
我们来画图理解一下上面说的快速排序究竟是什么意思,怎么又跟二叉树结构扯上关系了?
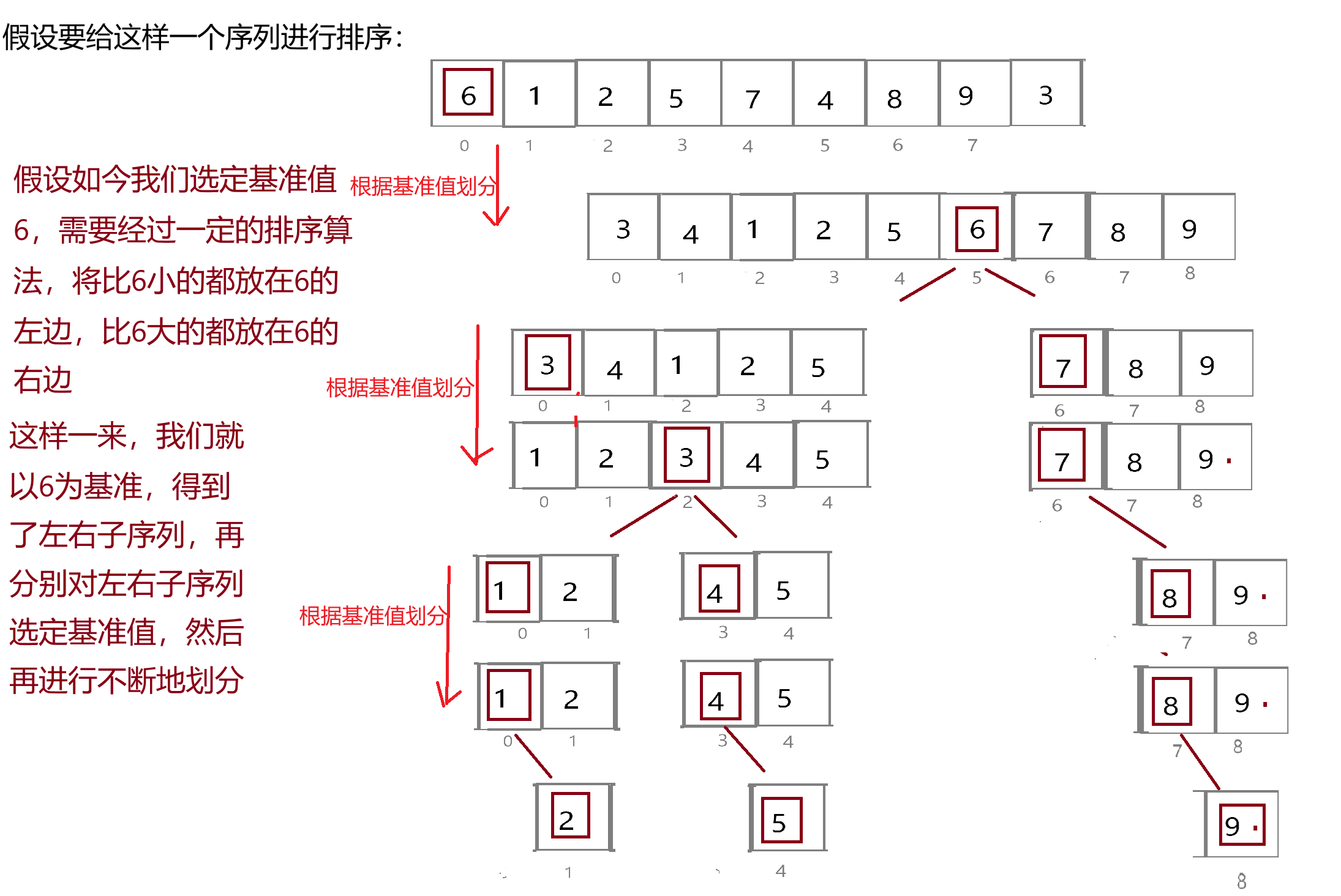
可以看到,在上面的划分过程中,序列会被划分成二叉树的结构,在不断找基准值并通过一定序列排序的时候,我们看到数组会不断变成有序的。根据基准值将序列化分成左右子序列之后,我们又要分别对左右子序列找基准值再进行划分,这是一个大问题拆解为小问题的过程,我们就很容易想到用递归来实现。
基于上面的分析我们把代码的大体框架给写出来:
//快速排序
//left表示序列的左端点下标 right表示序列的右端点下标
void QuickSort(int* arr, int left, int right)
{if (left >= right)//左端点>=右端点,说明这个序列中已经有序{return;}//找基准值keyi//找到基准值后,将序列划分:left keyi rightQuickSort(arr, left, keyi - 1);QuickSort(arr, keyi + 1, right);}现在,我们要做的就是如何通过一定的算法选定基准值,并将基准值放到指定的位置上。
Hoare法找基准值
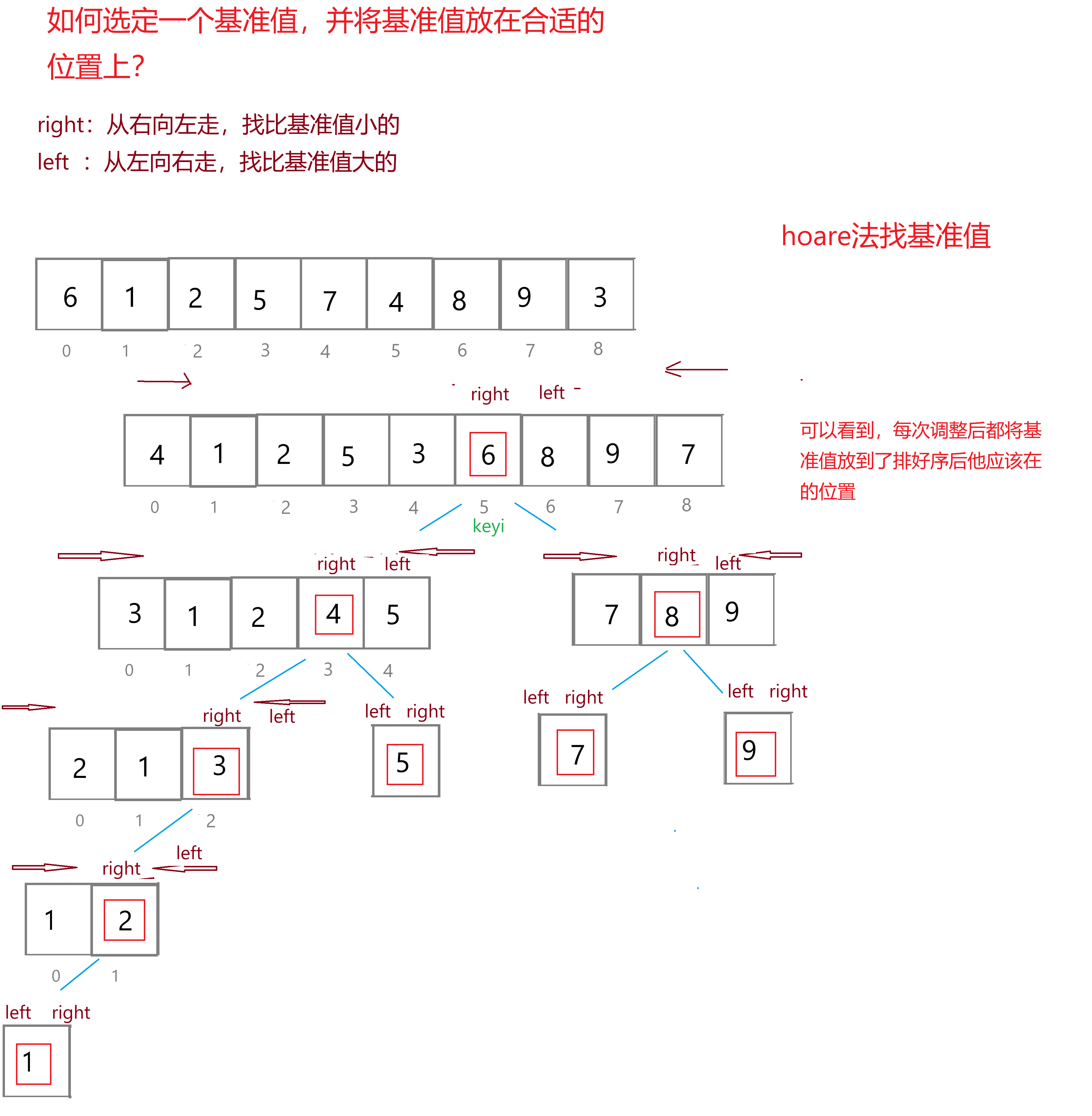
上面的方法就是hoare法找基准值,我们再来说明一下这个方法的思路:
1.选定基准值为left所指向的元素,即使基准值的位置keyi与left指向相同,keyi=left
2.right不断地从右往左走,直到right所指向位置的值比基准值要小;left不断地从左往右走,直到left指向位置的值比基准值要大,在移动right和left'的过程中要保证left不大于right
3.找到符合条件的right和left之后,交换left和right所指向位置的值
4.left>right后,终止移动,此时right所指向的位置就是基准值应当在的位置
//指定基准值,将基准值放到对应的位置,函数会返回基准值的下标
int _QuickSort(int* arr, int left, int right)
{//指定基准值为左端点位置上的数int keyi = left;//left从左往右走,直到找到不小于基准值的数//keyi初始与left指向相同,不妨就先让left向右走一步left++;//right从右往左走,直到找到不大于基准值的数while (left <= right){//在right和left移动的过程中始终要满足left<=rightwhile (left<=right&&arr[right] > arr[keyi]){right--;}while (left <= right && arr[left] < arr[keyi]){left++;}//走到这一步,有两种可能://1) left>right//2)left<=right并且left指向的值大于arr[keyi],right指向的值小于arr[keyi]if (left <= right){swap(&arr[left], &arr[right]);left++;right--;}}//此时left>right(left=right+1),那么就有right以及right前面的位置所存放的值都小于arr[keyi]//left以及left后面的位置所存放的值都大于arr[keyi]swap(&arr[keyi], &arr[right]);keyi = right;return keyi;
}//快速排序
//left表示序列的左端点下标 right表示序列的右端点下标
void QuickSort(int* arr, int left, int right)
{if (left >= right)//左端点>=右端点,说明这个序列中已经有序{return;}//找基准值keyiint keyi = _QuickSort(arr, left, right);//找到基准值后,将序列划分:left keyi rightQuickSort(arr, left, keyi - 1);QuickSort(arr, keyi + 1, right);}算法的时间复杂度
该过程中使用了递归,递归算法的时间复杂度=单次递归的时间复杂度*递归次数
单次递归的时间复杂度自然就取决于我们找基准值的算法,看上去找基准值的算法好像有两层嵌套循环,实际上,我们只是遍历了一遍数组,所以时间复杂度是O(N)。
再来看递归次数:我们说过,形成的序列是一个二叉树形状的,通过图中我们也可以看到,递归的次数就是这棵二叉树的高度,这棵二叉树的高度与节点个数(数据个数)的关系就是h=logN。
综上,快速排序的时间复杂度是O(N*logN)。
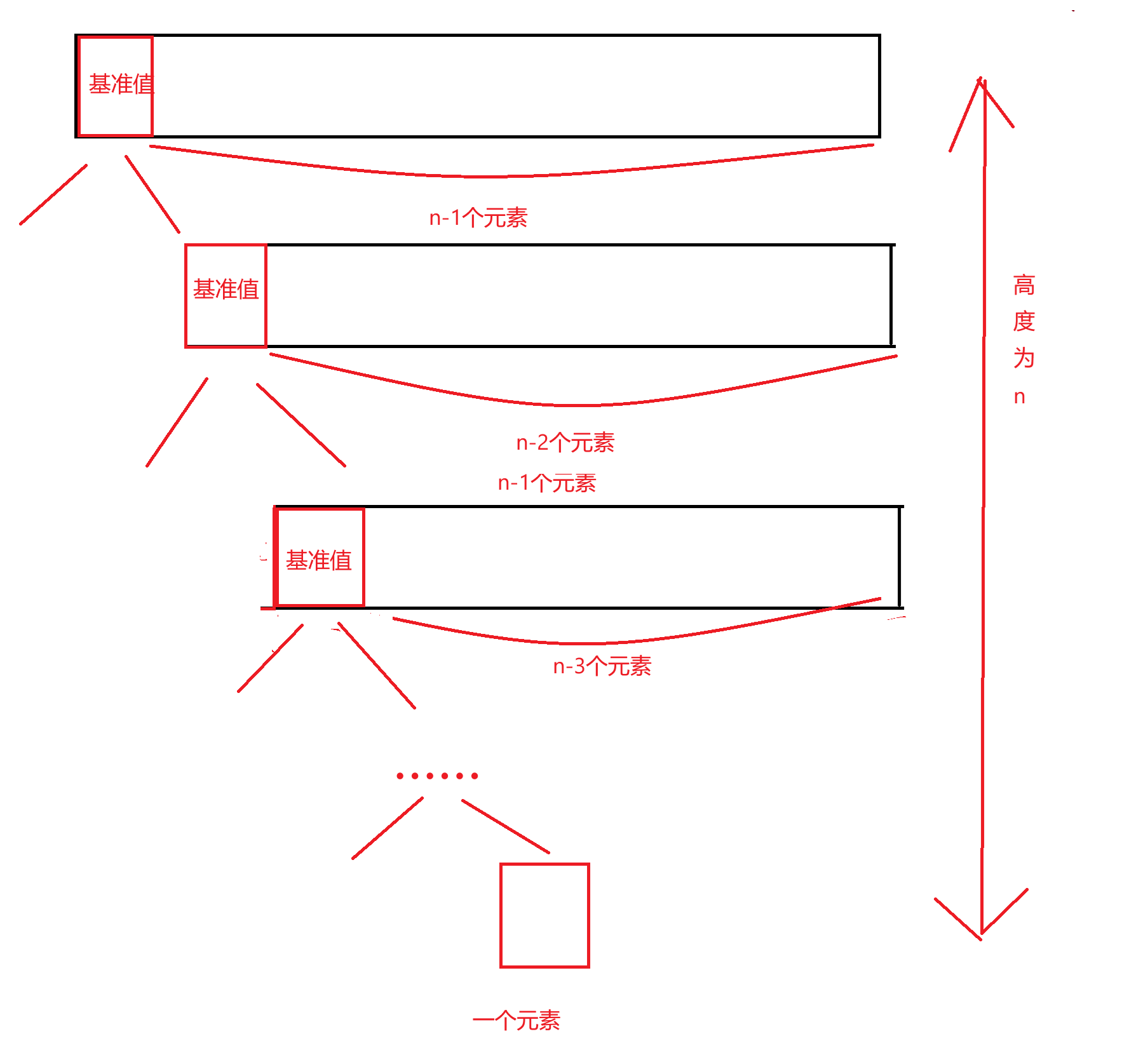
如果数字本身是有序的,而我们的算法中直接指定基准值就是最左边的元素,此时,我们找完一次基准值以后,基准值的左子序列元素个数为0,基准值的右子序列元素个数为n-1,又要对剩下的n-1个元素继续递归找子序列,这样不断递归下去,产生的二叉树的高度就是N,此时时间复杂度达到最大,为O(n^2),如下图:
在写代码中一定要注意的是:
- 在找基准值的过程中一定要保证left<=right,不能将代码写成这样:
//指定基准值,将基准值放到对应的位置,函数会返回基准值的下标
int _QuickSort(int* arr, int left, int right)
{//指定基准值为左端点位置上的数int keyi = left;//left从左往右走,找比基准值大的数//keyi初始与left指向相同,不妨就先让left向右走一步left++;//right从右往左走,找比基准值小的数while (left <= right){while (arr[right] > arr[keyi]){right--;}while (arr[left] < arr[keyi]){left++;}if (left <= right){swap(&arr[left], &arr[right]);left++;right--;}}swap(&arr[keyi], &arr[right]);keyi = right;return keyi;
}
我们拿具体例子来说明一下,假设我们要排序的数组是 {2,2,2,2},刚进入循环时,基准值的位置keyi=0,left=1,right=3,现在就要让right不断向右走,直到找到比基准值要小的,但是这里面不存在比基准值要大的元素,最后right会超出数组的界限,发生错误,所以在循环过程中一定要保证right>=left.
- 在交换right和left所指向位置的值的时候,一定要保证left<=right,不能将代码写成下面的样子:
int _QuickSort(int* arr, int left, int right)
{//指定基准值为左端点位置上的数int keyi = left;//left从左往右走,找比基准值大的数//keyi初始与left指向相同,不妨就先让left向右走一步left++;//right从右往左走,找比基准值小的数while (left <= right){//在right和left移动的过程中始终要满足left<=rightwhile (left<=right&&arr[right] > arr[keyi]){right--;}while (left <= right && arr[left] < arr[keyi]){left++;}swap(&arr[left], &arr[right]);left++;right--;}swap(&arr[keyi], &arr[right]);keyi = right;return keyi;
}举例说明:如果我们要排列的顺序是{3,2,1,5},初始时left指向的是2这个元素,right指向的是5这个元素,然后right先要从右往左走,找到比3还要小的值,后来就找到了1这个元素,right终止移动,left开始从左往右走,最后left会走到存放元素5的这个位置(注意哦,left走到这个位置后终止循环的原因不是因为找到了5>3,而是因为left<=right不满足循环条件),此时left>right了,如果此时交换left和right指向的值,就会发生错误:交换值以后,数组的元素变成 {3,2,5,1},此时left指向元素1,right指向元素5,然后执行left++,right--,left越界,right指向元素2,接着进入最外层循环的判断条件,不满足left<=right,就会跳出循环,跳出循环后,又要交换基准值和right所指向的元素的值,数组就变成了{2,3,5,1},但我们预想的情况是基准值3前面的元素都比3要小,后面的元素都比3要大,这显然未达到预期。
- 内部两个循环的顺序不能交换,也就是说,不能将代码写成:
//指定基准值,将基准值放到对应的位置,函数会返回基准值的下标
int _QuickSort(int* arr, int left, int right)
{int keyi = left;left++;while (left <= right){//在right和left移动的过程中始终要满足left<=rightwhile (left <= right && arr[left] < arr[keyi]){left++;}while (left<=right&&arr[right] > arr[keyi]){right--;}if (left <= right){swap(&arr[left], &arr[right]);left++;right--;}}swap(&arr[keyi], &arr[right]);keyi = right;return keyi;
}
- 交换完right和left所指向的位置的值以后,一定要移动left和right,否则会发生错误,也就是说,不能将代码写成:
int _QuickSort(int* arr, int left, int right)
{//指定基准值为左端点位置上的数int keyi = left;//left从左往右走,找比基准值大的数//keyi初始与left指向相同,不妨就先让left向右走一步left++;//right从右往左走,找比基准值小的数while (left <= right){while (left<=right&&arr[right] > arr[keyi]){right--;}while (left <= right && arr[left] < arr[keyi]){left++;}if (left <= right){swap(&arr[left], &arr[right]);}}swap(&arr[keyi], &arr[right]);keyi = right;return keyi;
}
举例,测试用例为:{5,3,8,6,2},right先移动到元素2所在的位置,left再移动到8所在的位置,此时有left<right,交换两个位置的值,数组变成{5,3,2,6,8},此时left指向2,right指向8,之后再进入循环,right继续往左走,直到走到3所在的位置,且left>right,跳出循环,需要交换基准值和right所指向位置的值,交换后数组变成{3,5,2,6,8},不满足基准值5之后的元素都大于5,所以这个算法不能写成这样。
挖坑法找基准值
思路:创建左右指针。首先从右向左找出比基准小的数据,找到后立即放入左边坑中,当前位置变为新的 "坑",然后从左向右找出比基准大的数据,找到后立即放入右边坑中,当前位置变为新的 "坑",结束循环后将最开始存储的分界值放入当前的 "坑" 中,返回当前 "坑" 下标(即分界值下标)。
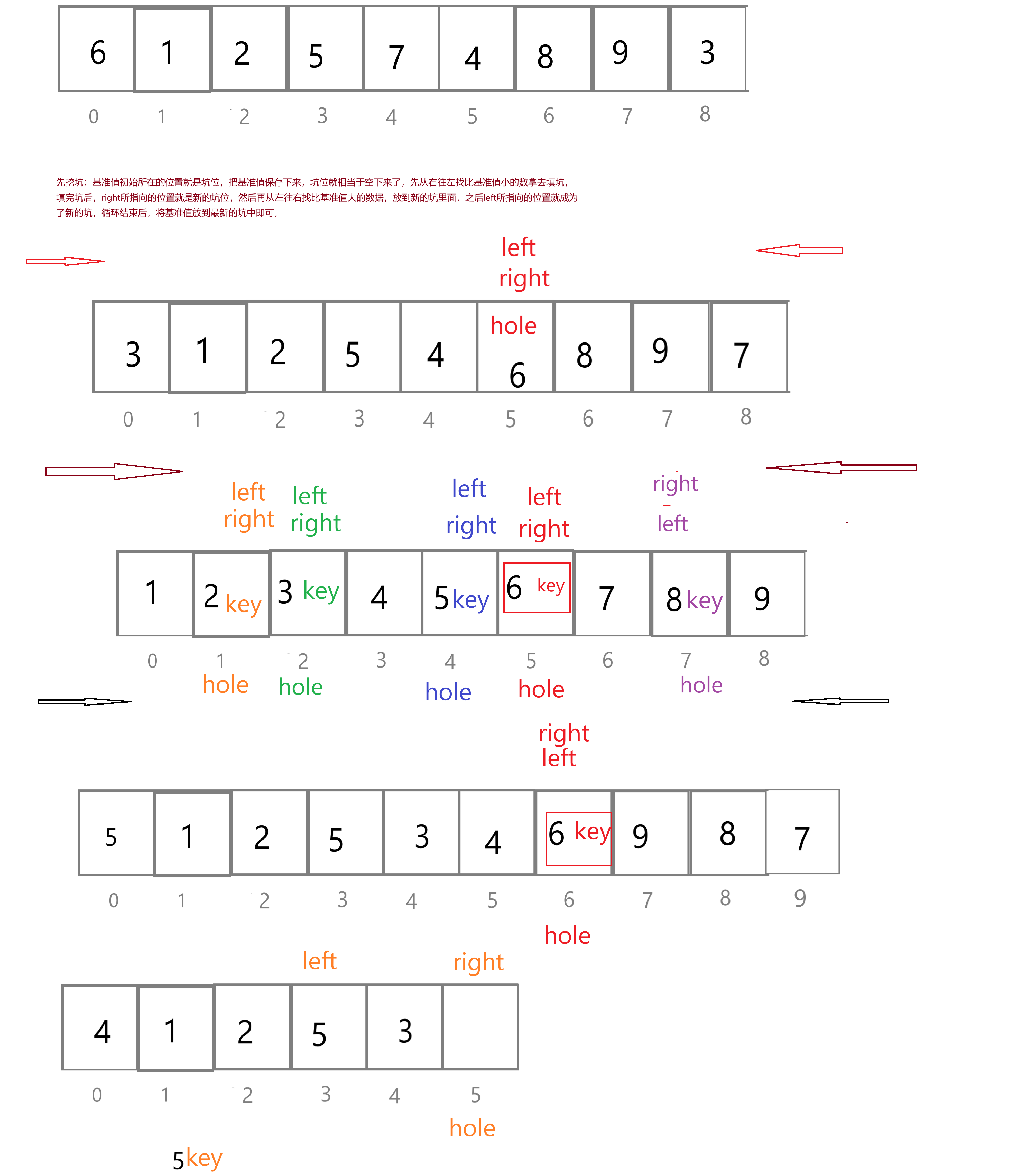
思路重述:
1.先挖坑,选定最左边的元素为基准值,把这个基准值key保存下来,就好像吧这个位置的值给拿了下来,这个位置就成为坑位hole
2.right从右往左走找比基准值小的,如果找到了,就把这个值拿出来去填坑,那这个位置就成为了新的坑位hole
3.left从左往右找比基准值大的,如果找到了,就把这个值拿去填坑,那这个位置就成为了新的坑位hole
4.依照前面的方法不断挖坑填坑,直到right<=left,此时hole就是基准值key存放的位置。
int _QuickSort_Hole(int* arr, int left, int right)
{//指定基准值int key = arr[left];//挖坑int hole = left;while (left < right){//right从右往左找比基准值要小的,注意一定是要找严格小于基准值的数,不能等于while (left<right && arr[right]>=key){right--;}//将right位置存放的值拿去填坑arr[hole] = arr[right];//更新坑位hole = right;//left从左往右找比基准值大的,注意一定是要找严格大于基准值的数,不能等于while (left < right && arr[left] <= key){left++;}//将left位置存放的值拿去填坑arr[hole] = arr[left];//更新坑位hole = left;}//跳出循环,必有left==right,此时left和right都指向坑位hole//而hole就是基准值应该在的位置//用基准值填最后一个坑arr[hole] = key;return hole;
}//快速排序
//left表示序列的左端点下标 right表示序列的右端点下标
void QuickSort(int* arr, int left, int right)
{if (left >= right)//左端点>=右端点,说明这个序列中已经有序{return;}//找基准值keyiint keyi = _QuickSort_Hole(arr, left, right);//找到基准值后,将序列划分:left keyi rightQuickSort(arr, left, keyi - 1);QuickSort(arr, keyi + 1, right);}需要注意的是
- 跟前面的Hoare版本相区别:在我们指定基准值以后,无需再给left++,如果执行了left++,就会发生错误。也就是代码不能写成:
int _QuickSort_Hole(int* arr, int left, int right)
{
int key = arr[left];
int hole = left;
left++;
while (left < right)
{
while (left<right && arr[right]>=key)
{
right--;
}
arr[hole] = arr[right];
hole = right;
while (left < right && arr[left] <= key)
{
left++;
}
arr[hole] = arr[left];
hole = left;}
arr[hole] = key;
return hole;
}
举例说明,假设要排序的是{6,1},如果率先执行了left++,那么left和right执行相同,不会进入到循环中,直接执行arr[hole]=key,那么执行后数组还是{6,1},没有实现基准值的后面都是比基准值大的数据。
- 循环条件一定是
left < right,而不是left <= right,因为在挖坑法中,当left == right时,表示:
-
找到了基准值的最终位置
-
所有元素都已分区完成
-
循环应该立即终止
-
如果使用
left <= right,循环会多执行一次,导致错误。
- 在left从左往右找比基准值大的数时,注意一定是要找严格大于基准值的数,不能等于;同理right从右往左找比基准值要小的,注意一定是要找严格小于基准值的数,不能等于也就是说,代码不能写成:
int _QuickSort_Hole(int* arr, int left, int right)
{
int key = arr[left];
int hole = left;
while (left < right)
{
while (left<right && arr[right]>key)
{
right--;
}
arr[hole] = arr[right];
hole = right;
while (left < right && arr[left] < key)
{
left++;
}
arr[hole] = arr[left];
hole = left;}
arr[hole] = key;
return hole;
}
举例说明,假设待排序的数组是{2,2,2,2},初始left=0,right=3,如果按照上面的错误代码,由于arr[right]>key不成立,所以现在right指向的位置就是新的坑位,先将right的值拿去填坑,然后数组变成{2,2,2,2},right依然等于3;然后再进入第二个内层循环的判断条件,不满足arr[left]<key,所以现在left指向的就是新的坑位,先将left的值拿去填充原来right的坑,然后数组变成{2,2,2,2},然而现在right依旧等于3,也就是说,上面执行了一次循环体以后,什么也没有变,所以代码会陷入死循环。
lomuto前后指针法
思路:创建前后指针,从左往右找比基准值小的进行交换,使得小的都排在基准值的左边。
也就是说:
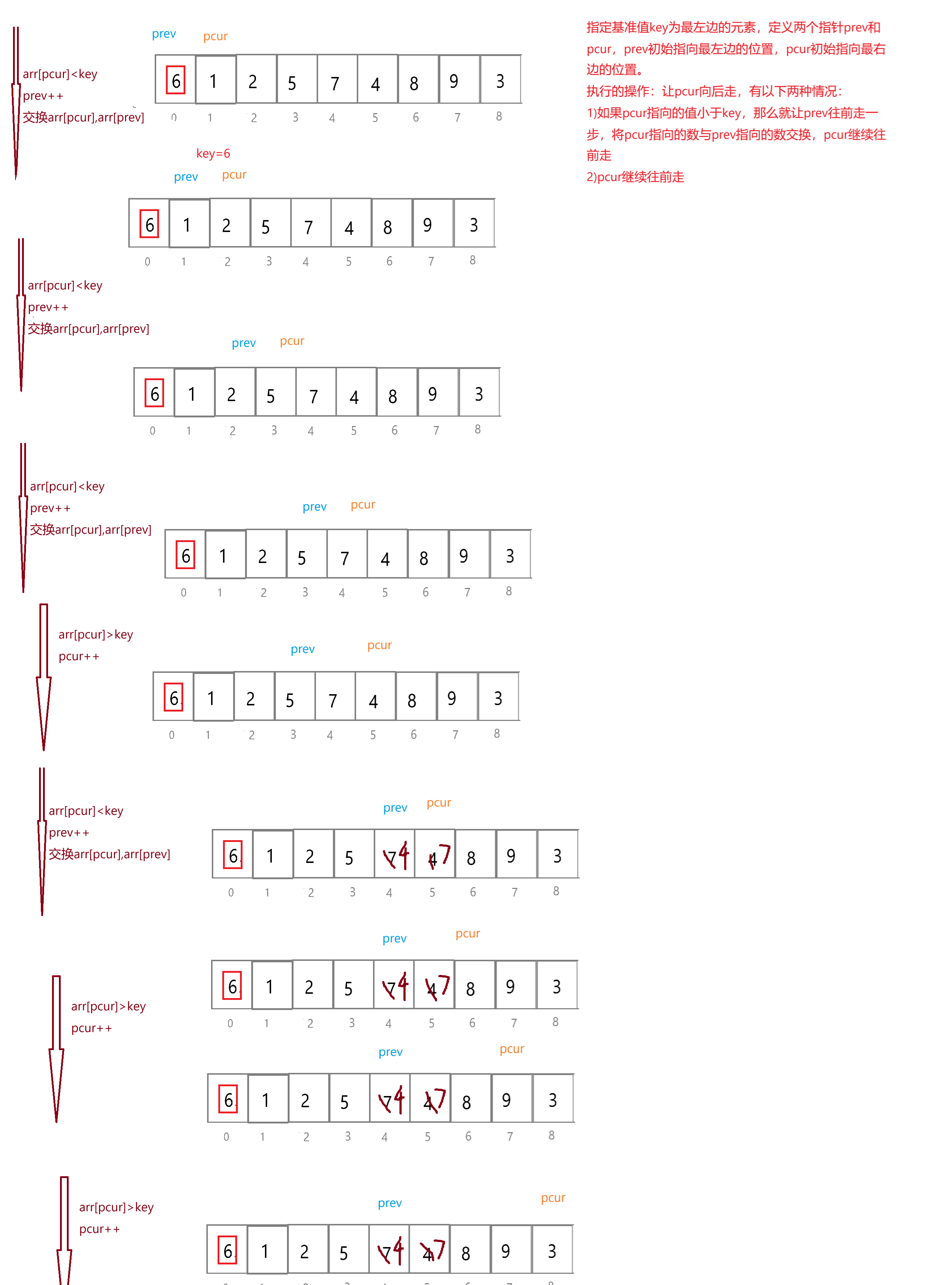
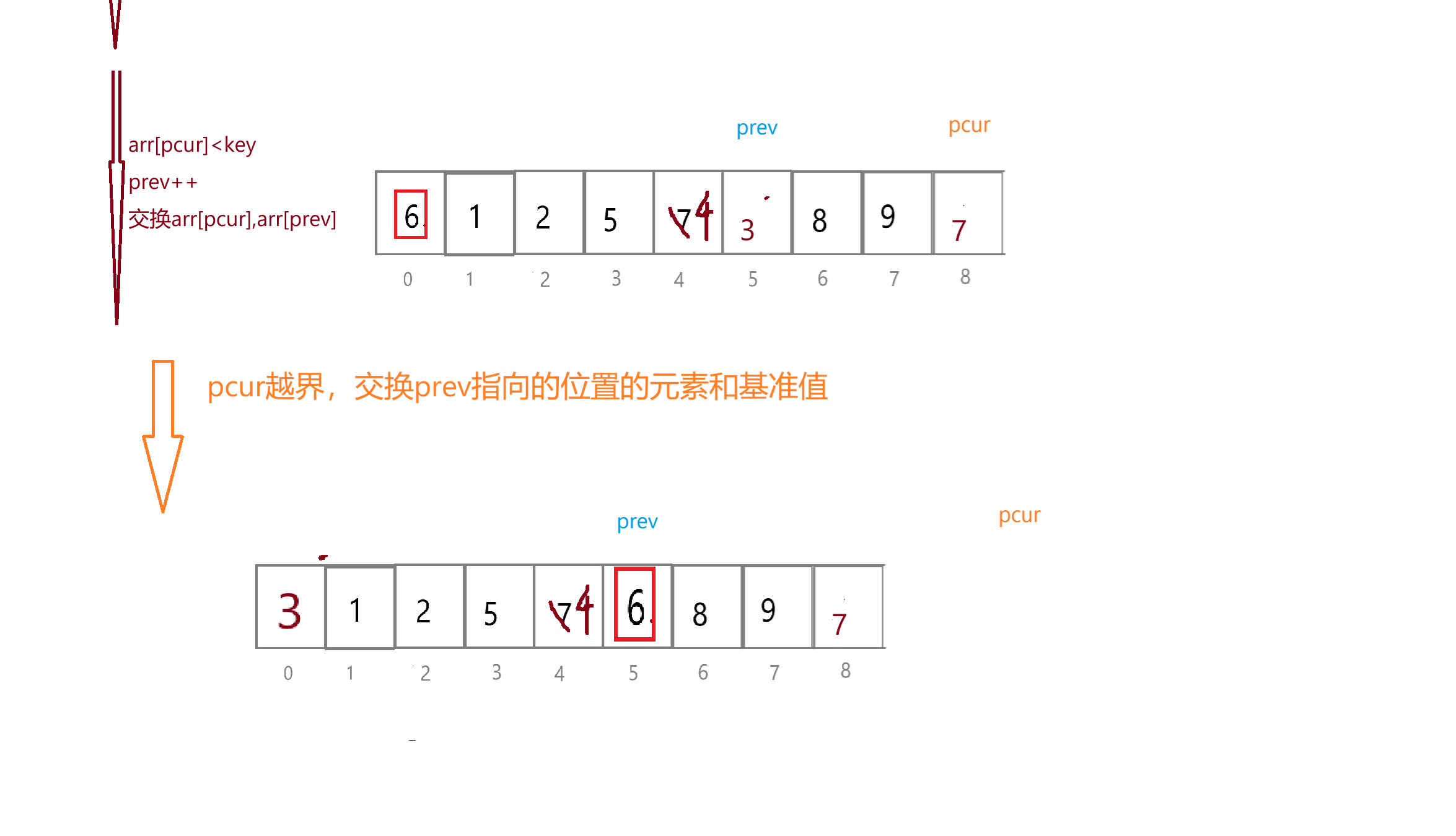
指定基准值key为最左边的元素,定义两个指针prev和pcur,prev初始指向最左边的位置,pcur初始指向最右边的位置。
需要执行的操作:让pcur向后走,有以下两种情况:
1)如果pcur指向的值小于key,那么就让prev往前走一步,将pcur指向的数与prev指向的数交换,pcur继续往前走
2)pcur继续往前走
看过解释和图示以后,我们就来写一下代码吧:
int _QuickSort_lomuto(int* arr, int left, int right)
{int keyi = left;int prev = left;int pcur = prev + 1;while (pcur <= right){if (arr[pcur] < arr[keyi]&&++prev!=pcur){swap(&arr[prev], &arr[pcur]);}pcur++;}//走到最后,prev的位置就是基准值应该存放的位置swap(&arr[prev], &arr[keyi]);return prev;
}//快速排序
//left表示序列的左端点下标 right表示序列的右端点下标
void QuickSort(int* arr, int left, int right)
{if (left >= right)//左端点>=右端点,说明这个序列中已经有序{return;}//找基准值keyiint keyi = _QuickSort_lomuto(arr, left, right);//找到基准值后,将序列划分:left keyi rightQuickSort(arr, left, keyi - 1);QuickSort(arr, keyi + 1, right);}可以看到,在理解了双指针法的原理以后,代码是十分清晰和简单的。
非递归版本的快速排序
前面我们讲的快速排序都是使用了递归实现的,那非递归的版本可以实现快速排序嘛?
可以的,但这里我们就要借用一下栈这一数据结构了。
递归的“隐式栈”:函数调用栈
当你调用 QuickSort(arr, left, key-1) 时:
- 系统会自动把当前函数的“状态”(比如
left,right,key等)压入函数调用栈 - 然后跳去执行子任务
- 子任务执行完,系统自动从栈中弹出状态,恢复现场,继续执行下一个递归(右半部分)
👉 递归依赖系统维护的“调用栈”来保存“待处理的任务”
我们能不能自己用栈来保存“待处理的区间”?
既然系统用栈帮我们保存了“还没处理完的区间”,那我们完全可以:
自己创建一个栈,手动把“需要排序的区间”压进去,然后一个个拿出来处理!
这就引出了非递归版本的核心思想。
关于栈的数据结构的实现看这里哦:《栈:后进先出的 “数据容器”,程序世界的高效管家》-CSDN博客
现在我们就来实现以下非递归版本的快速排序吧:
//非递归版本的快速排序
void QuickSortNor(int* arr, int left, int right)
{if (left >= right){return;}//先创建栈ST stack;//初始化栈STInit(&stack);//将区间入栈,由于栈具有后进先出的性质,所以如果我们出栈时想先得到左区间,//就可以先让右区间入栈STPush(&stack, right);STPush(&stack, left);while (!STEmpty(&stack)){//取栈顶元素int left = STTop(&stack);STPop(&stack);int right= STTop(&stack);STPop(&stack);//利用双指针法得到基准值应该在的位置int keyi = left;int prev = keyi, pcur = keyi + 1;while (pcur <= right){if (arr[pcur] < arr[keyi] && ++prev != pcur){swap(&arr[prev], &arr[pcur]);}pcur++;}swap(&arr[keyi], &arr[prev]);keyi = prev;//现在就得到了keyi的值//利用keyi我们可以将序列划分成 [ left , keyi-1 ] , [ keyi +1 , right ]//如果区间有效,即left<keyi-1,keyi+1<right,就将区间存起来if(keyi+1<right){STPush(&stack, right);STPush(&stack, keyi + 1);}if(keyi-1>left){STPush(&stack, keyi - 1);STPush(&stack, left);}}STDesTroy(&stack);
}代码整合(非递归快速排序)
//sort.h
#include<stdio.h>
#include<stdlib.h>
#include"stack.h"//非递归版本的快速排序
void QuickSortNor(int* arr, int left, int right);//sort.c
//非递归版本的快速排序
void QuickSortNor(int* arr, int left, int right)
{if (left >= right){return;}//先创建栈ST stack;//初始化栈STInit(&stack);//将区间入栈,由于栈具有后进先出的性质,所以如果我们出栈时想先得到左区间,//就可以先让右区间入栈STPush(&stack, right);STPush(&stack, left);while (!STEmpty(&stack)){//取栈顶元素int left = STTop(&stack);STPop(&stack);int right= STTop(&stack);STPop(&stack);//利用双指针法得到基准值应该在的位置int keyi = left;int prev = keyi, pcur = keyi + 1;while (pcur <= right){if (arr[pcur] < arr[keyi] && ++prev != pcur){swap(&arr[prev], &arr[pcur]);}pcur++;}swap(&arr[keyi], &arr[prev]);keyi = prev;//现在就得到了keyi的值//利用keyi我们可以将序列划分成 [ left , keyi-1 ] , [ keyi +1 , right ]//如果区间有效,即left<keyi-1,keyi+1<right,就将区间存起来if(keyi+1<right){STPush(&stack, right);STPush(&stack, keyi + 1);}if(keyi-1>left){STPush(&stack, keyi - 1);STPush(&stack, left);}}STDesTroy(&stack);
}//stack.c
#include"stack.h"//初始化:形参的改变需要影响实参,所以采用传址调用方式
void STInit(ST* ps)
{assert(ps);//防止后续空指针解引用ps->arr = NULL;ps->top = 0;//如果使top=0,那么top指向栈顶元素的后一个位置,//如果想让top指向栈顶元素,就要让top初始化为-1ps->capacity = 0;
}//销毁
void STDesTroy(ST* ps)
{assert(ps);free(ps->arr);ps->arr = NULL;ps->capacity = ps->top = 0;
}//入栈——栈顶
void STPush(ST* ps, stdatatype x)
{assert(ps);//先判断是否需要扩容if (ps->top == ps->capacity){//需要扩容int newcapacity = ps->capacity > 0 ? 2 * ps->capacity : 4;stdatatype*tmp = (stdatatype*)realloc(ps->arr, newcapacity * sizeof(stdatatype));if (tmp == NULL){perror("realloc fail");return 1;}ps->arr = tmp;ps->capacity = newcapacity;}ps->arr[(ps->top)++] = x;
}//栈是否为空
bool STEmpty(ST* ps)
{assert(ps);return ps->top == 0;
}//出栈———栈顶
void STPop(ST* ps)
{assert(ps);//出栈之前先判空assert(ps->top);ps->top--;
}//取栈顶元素
stdatatype STTop(ST* ps)
{assert(ps);//去栈顶元素之前先判空assert(ps->top);return ps->arr[ps->top - 1];
}//获取栈中有效元素个数
int STSize(ST* ps)
{assert(ps);return ps->top;
}//stack.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>typedef int stdatatype;//定义栈的结构:
typedef struct Stack
{stdatatype* arr;int top;//指向栈顶的后一个位置,也可以表示有效数据个数int capacity;//栈中的最大容量
}ST;//栈中相关的实现方法:
//初始化
void STInit(ST* ps);
//销毁
void STDesTroy(ST* ps);//入栈——栈顶
void STPush(ST* ps, stdatatype x);
//出栈———栈顶
void STPop(ST* ps);
//取栈顶元素
stdatatype STTop(ST* ps);//栈是否为空
bool STEmpty(ST* ps);
//获取栈中有效元素个数
int STSize(ST* ps);小结:本节内容我们讲解了交换排序的实现,其实冒泡排序在C语言阶段我们就已经实现了。我们花了大量的篇幅去讲解快速排序,快速排序还是比较重要的,同时也是块难啃的骨头,但是它再难我们也要搞定它呀,不然就要饿肚子咯。
喜欢小编的兄弟们欢迎三连哦,小编会继续更新编程方面的内容的。对于本节内容有任何问题的朋友欢迎在评论区留言哦!!!