gsplat在windows本地部署
背景
3DGS的cuda提效和优化内存的版本gsplat,使得在有一定GPU计算能力的电脑上也能够尝尝3DGS的效果。我在2025年的开年之初尝试配置过gsplat,由于过程中遇到很多问题,最终还是有一些windows上字符编码的问题,没有跑通,最近看gsplat的github更新了3DGUT,优化了反射和二次折射,以及适用于非线性相机模型,如鱼眼相机等。并且有人提供了windows上的配置教程,我将按照此教程配置过程,并仍然存在的问题进行了解决,最终跑通。
环境配置
- 基本的环境是利用anaconda,创建虚拟环境gsplat并激活;
conda create --name gsplat -y python=3.10
conda activate gsplat
- 在windows上安装visual studio 2022,vs2019也可以,但是后续的cuda toolkit版本需要与之匹配;
下载visual studio installer,按提示安装vs2022,其中注意要勾选c++桌面开发工具。接下来激活MSVC的环境,进入到你的安装目录下面,例如
C:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools\VC\Auxiliary\Build
在此目录下右键打开windows终端的命令窗口,输入
./vcvars64.bat
激活编译器
-
在windows上安装cuda toolkit 12.6
注意!安装cuda toolkit的时候一定要勾选visual studio integration, 这样MSVC在编译时才能找到CUDA -
安装pytorch,安装与cuda v12.6对应的pytorch版本即可,可以进入官网自己选择pytorch版本,也可以执行如下命令,默认更新最新符合cuda v12.6的版本
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
- 安装gsplat
接着第一步anaconda创建并激活的虚拟环境,下载gsplat源码
git clone --recursive https://github.com/nerfstudio-project/gsplat.git
cd gsplat
并安装
pip install -e .
安装其他工具和依赖
pip install -r examples/requirements.txt
其中,requirements.txt需要git下载4个源码并安装
// requirements.txt
# assume torch is already installed# pycolmap for data parsing
git+https://github.com/rmbrualla/pycolmap@cc7ea4b7301720ac29287dbe450952511b32125e
# (optional) nerfacc for torch version rasterization
# git+https://github.com/nerfstudio-project/nerfaccviser
git+https://github.com/nerfstudio-project/nerfview@4538024fe0d15fd1a0e4d760f3695fc44ca72787
imageio[ffmpeg]
numpy<2.0.0
scikit-learn
tqdm
torchmetrics[image]
opencv-python
tyro>=0.8.8
Pillow
tensorboard
tensorly
pyyaml
matplotlib
git+https://github.com/rahul-goel/fused-ssim@328dc9836f513d00c4b5bc38fe30478b4435cbb5
git+https://github.com/harry7557558/fused-bilagrid@90f9788e57d3545e3a033c1038bb9986549632fe
splines我在安装fused-bilagrid时遇到了cuda编译的问题,对原始的uniform_sample_backward_v1.cu文件进行了适配,修改后的文件如下
// uniform_sample_backward_v1.cu
#include "config.h"#include <cooperative_groups.h>
#include <cooperative_groups/reduce.h>namespace cg = cooperative_groups;__global__ void bilagrid_uniform_sample_backward_v1_kernel_bilagrid(const float *__restrict__ rgb, // [N,m,h,w,3]const float *__restrict__ v_output, // [N,m,h,w,3]float *__restrict__ v_bilagrid, // [N,12,L,H,W]int N,int L,int H,int W,int m,int h,int w,int mult_x,int mult_y
) {int x_idx = blockIdx.x * blockDim.x + threadIdx.x;int y_idx = blockIdx.y * blockDim.y + threadIdx.y;int idx = blockIdx.z * blockDim.z + threadIdx.z;int xi = x_idx / mult_x, xf = x_idx % mult_x;int yi = y_idx / mult_y, yf = y_idx % mult_y;bool inside = (xi < W && yi < H && idx < (N * L));if (!inside && (mult_x * mult_y == 1 ||(mult_x % blockDim.x != 0 || mult_y % blockDim.y != 0)))return;int zi = idx % L;idx /= L;int ni = idx;// Loop boundsfloat sw = float(w - 1) / float(W - 1);int block_wi0 =max((int)ceil((xi - 1) * sw), 0); // same for all threads in the blockint block_wi1 = min((int)floor((xi + 1) * sw), w - 1) + 1;float sh = float(h - 1) / float(H - 1);int block_hi0 = max((int)ceil((yi - 1) * sh), 0);int block_hi1 = min((int)floor((yi + 1) * sh), h - 1) + 1;int x_step = (block_wi1 - block_wi0 + mult_x - 1) / mult_x;int y_step = (block_hi1 - block_hi0 + mult_y - 1) / mult_y;int wi0 = block_wi0 + xf * x_step;int hi0 = block_hi0 + yf * y_step;// int wi1 = min(block_wi0+(xf+1)*x_step, w);// int hi1 = min(block_hi0+(yf+1)*y_step, h);int wi1 = min(block_wi0 + (xf + 1) * x_step, block_wi1);int hi1 = min(block_hi0 + (yf + 1) * y_step, block_hi1);// Result for each affine mat channelfloat accum[12] = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0};// Loop over all samples for this batchif (inside)for (int mi = 0; mi < m; ++mi) {for (int wi = wi0; wi < wi1; wi++)for (int hi = hi0; hi < hi1; hi++) {int g_off = (((ni * m + mi) * h + hi) * w + wi) * 3;float sr = rgb[g_off + 0];float sg = rgb[g_off + 1];float sb = rgb[g_off + 2];float x = (float)wi / (float)(w - 1) * (float)(W - 1);float y = (float)hi / (float)(h - 1) * (float)(H - 1);float z = (kC2G_r * sr + kC2G_g * sg + kC2G_b * sb);z = min(max(z, 0.0f), 1.0f) * (float)(L - 1);int x0 = floorf(x), y0 = floorf(y), z0 = floorf(z);int x1 = min(x0 + 1, W - 1);int y1 = min(y0 + 1, H - 1);int z1 = min(z0 + 1, L - 1);if (zi != z0 && zi != z1)continue;float fx = x - x0, fy = y - y0, fz = z - z0;float accum_t = 0.0;if (zi == z0) {if (xi == x0 && yi == y0)accum_t += (1 - fx) * (1 - fy) * (1 - fz);if (xi == x1 && yi == y0)accum_t += fx * (1 - fy) * (1 - fz);if (xi == x0 && yi == y1)accum_t += (1 - fx) * fy * (1 - fz);if (xi == x1 && yi == y1)accum_t += fx * fy * (1 - fz);}if (zi == z1) {if (xi == x0 && yi == y0)accum_t += (1 - fx) * (1 - fy) * fz;if (xi == x1 && yi == y0)accum_t += fx * (1 - fy) * fz;if (xi == x0 && yi == y1)accum_t += (1 - fx) * fy * fz;if (xi == x1 && yi == y1)accum_t += fx * fy * fz;}float dr = v_output[g_off + 0];float dg = v_output[g_off + 1];float db = v_output[g_off + 2];#pragma unrollfor (int ci = 0; ci < 12; ci++) {int si = ci % 4;int di = ci / 4;float r_coeff =(si == 0 ? sr: si == 1 ? sg: si == 2 ? sb: 1.f);float gout = (di == 0 ? dr : di == 1 ? dg : db);float grad_weight = r_coeff * gout;accum[ci] += accum_t * grad_weight;}}}// Write resultint out_idx_start = ((ni * 12 * L + zi) * H + yi) * W + xi;int out_idx_offset = L * H * W;// simply write in this caseif (mult_x * mult_y == 1) {
#pragma unrollfor (int ci = 0; ci < 12; ci++) {int out_idx = out_idx_start + ci * out_idx_offset;if (isfinite(accum[ci]))v_bilagrid[out_idx] = accum[ci];}return;}// out_idx can be different for each thread, fall back to global atomicAddif (mult_x % blockDim.x != 0 || mult_y % blockDim.y != 0) {
#pragma unrollfor (int ci = 0; ci < 12; ci++) {int out_idx = out_idx_start + ci * out_idx_offset;if (isfinite(accum[ci]))atomicAdd(v_bilagrid + out_idx, accum[ci]);}return;}// fast atomicAdd__shared__ float sharedData[64];int blockSize = blockDim.x * blockDim.y * blockDim.z;int tid =(threadIdx.z * blockDim.y + threadIdx.y) * blockDim.x + threadIdx.x;#pragma unrollfor (int ci = 0; ci < 12; ci++) {int out_idx = out_idx_start + ci * out_idx_offset;sharedData[tid] = isfinite(accum[ci]) ? accum[ci] : 0.0f;__syncthreads();for (int s = blockSize / 2; s > 0; s >>= 1) {if (tid < s)sharedData[tid] += sharedData[tid + s];__syncthreads();}if (tid == 0)atomicAdd(v_bilagrid + out_idx, sharedData[0]);}
}__global__ void bilagrid_uniform_sample_backward_v1_kernel_rgb(const float *__restrict__ bilagrid, // [N,12,L,H,W]const float *__restrict__ rgb, // [N,m,h,w,3]const float *__restrict__ v_output, // [N,m,h,w,3]float *__restrict__ v_rgb, // [N,m,h,w,3]int N,int L,int H,int W,int m,int h,int w
) {int idx = blockIdx.x * blockDim.x + threadIdx.x;int total = N * m * h * w;if (idx >= total)return;int tmp = idx;int wi = tmp % w;tmp /= w;int hi = tmp % h;tmp /= h;int mi = tmp % m;tmp /= m;int ni = tmp;// input and output colorsint g_off = (((ni * m + mi) * h + hi) * w + wi) * 3;float sr = rgb[g_off + 0];float sg = rgb[g_off + 1];float sb = rgb[g_off + 2];float dr = v_output[g_off + 0];float dg = v_output[g_off + 1];float db = v_output[g_off + 2];float vr = 0.0, vg = 0.0, vb = 0.0;// grid coordsfloat x = (float)wi / (float)(w - 1) * (float)(W - 1);float y = (float)hi / (float)(h - 1) * (float)(H - 1);float z = (kC2G_r * sr + kC2G_g * sg + kC2G_b * sb) * (L - 1);int x0 = floorf(x), y0 = floorf(y), z0 = floorf(z);int x1 = min(x0 + 1, W - 1);int y1 = min(y0 + 1, H - 1);int z1 = z0 + 1;z0 = min(max(z0, 0), L - 1);z1 = min(max(z1, 0), L - 1);// fractional partsfloat fx = x - x0, fy = y - y0, fz = z - z0;float w000 = (1 - fx) * (1 - fy) * (1 - fz);float w001 = fx * (1 - fy) * (1 - fz);float w010 = (1 - fx) * fy * (1 - fz);float w011 = fx * fy * (1 - fz);float w100 = (1 - fx) * (1 - fy) * fz;float w101 = fx * (1 - fy) * fz;float w110 = (1 - fx) * fy * fz;float w111 = fx * fy * fz;// accumulate bilagrid gradient over 12 channels
#pragma unrollfor (int si = 0; si < 3; si++) {
#pragma unrollfor (int di = 0; di < 3; di++) {int ci = 4 * di + si;float gout = (di == 0 ? dr : di == 1 ? dg : db);int base = ((ni * 12 + ci) * L * H * W);float val = bilagrid[base + (z0 * H + y0) * W + x0] * w000 +bilagrid[base + (z0 * H + y0) * W + x1] * w001 +bilagrid[base + (z0 * H + y1) * W + x0] * w010 +bilagrid[base + (z0 * H + y1) * W + x1] * w011 +bilagrid[base + (z1 * H + y0) * W + x0] * w100 +bilagrid[base + (z1 * H + y0) * W + x1] * w101 +bilagrid[base + (z1 * H + y1) * W + x0] * w110 +bilagrid[base + (z1 * H + y1) * W + x1] * w111;(si == 0 ? vr : si == 1 ? vg : vb) += val * gout;}}// spatial derivatives for coordsfloat dwdz[8] = {-(1 - fx) * (1 - fy),-fx * (1 - fy),-(1 - fx) * fy,-fx * fy,(1 - fx) * (1 - fy),fx * (1 - fy),(1 - fx) * fy,fx * fy};// accumulate gradient into coords (chain through bilagrid values and rgb)float gx_grad = 0.f, gy_grad = 0.f, gz_grad = 0.f;
#pragma unrollfor (int corner = 0; corner < 8; ++corner) {int xi = (corner & 1) ? x1 : x0;int yi = (corner & 2) ? y1 : y0;int zi = (corner & 4) ? z1 : z0;float trilerp = 0.f;
// gather the corresponding bilagrid value for each of the 12 channels
#pragma unrollfor (int ci = 0; ci < 12; ++ci) {const float *vol = bilagrid + ((ni * 12 + ci) * L * H * W);float v = vol[(zi * H + yi) * W + xi];int si = ci % 4, di = ci / 4;float r_coeff = (si == 0 ? sr : si == 1 ? sg : si == 2 ? sb : 1.f);float gout = (di == 0 ? dr : di == 1 ? dg : db);trilerp += v * r_coeff * gout;}gz_grad += dwdz[corner] * (L - 1) * trilerp;}vr += kC2G_r * gz_grad;vg += kC2G_g * gz_grad;vb += kC2G_b * gz_grad;v_rgb[g_off + 0] = isfinite(vr) ? vr : 0.0f;v_rgb[g_off + 1] = isfinite(vg) ? vg : 0.0f;v_rgb[g_off + 2] = isfinite(vb) ? vb : 0.0f;
}void bilagrid_uniform_sample_backward_v1(const float *bilagrid,const float *rgb,const float *v_output,float *v_bilagrid,float *v_rgb,int N,int L,int H,int W,int m,int h,int w,const int block_x,const int block_y,const int target_tile_size
) {// v_bilagrid{dim3 block = {(unsigned int)block_x, (unsigned int)block_y, 1u};int mult_x = (2 * w + W) / (block.x * W * target_tile_size);int mult_y = (2 * h + H) / (block.y * H * target_tile_size);if (mult_x * mult_y < 4)mult_x = mult_y = 1;else {mult_x = max(mult_x, 1) * block.x;mult_y = max(mult_y, 1) * block.y;}// printf("mult_x: %d, mult_y: %d\n", mult_x, mult_y);dim3 bounds = {(unsigned int)((W * mult_x + block.x - 1) / block.x),(unsigned int)((H * mult_y + block.y - 1) / block.y),(unsigned int)((N * L + block.z - 1) / block.z)};bilagrid_uniform_sample_backward_v1_kernel_bilagrid<<<bounds, block>>>(rgb, v_output, v_bilagrid, N, L, H, W, m, h, w, mult_x, mult_y);}// v_coords and v_rgb{int total = N * m * h * w;int threads = 256;int blocks = (total + threads - 1) / threads;bilagrid_uniform_sample_backward_v1_kernel_rgb<<<blocks, threads>>>(bilagrid, rgb, v_output, v_rgb, N, L, H, W, m, h, w);}
}-
替换scene_manager.py
上一步下载colmap中的scene_manager.py与windows环境不兼容,需要下载该链接中的scene_manager.py并替换掉colmap中的scene_manager.py。这一步非常重要! -
下载数据
python datasets/download_dataset.py
在data目录下下载好了360_v2的数据,进入之后images文件夹是原始分辨率的图像,images_2是下采样系数为2的数据,以此类推。
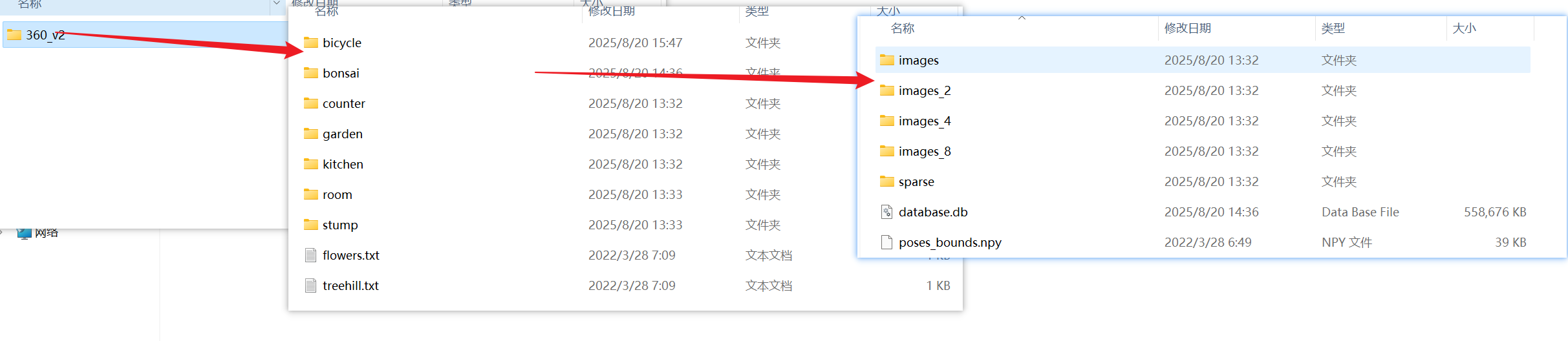
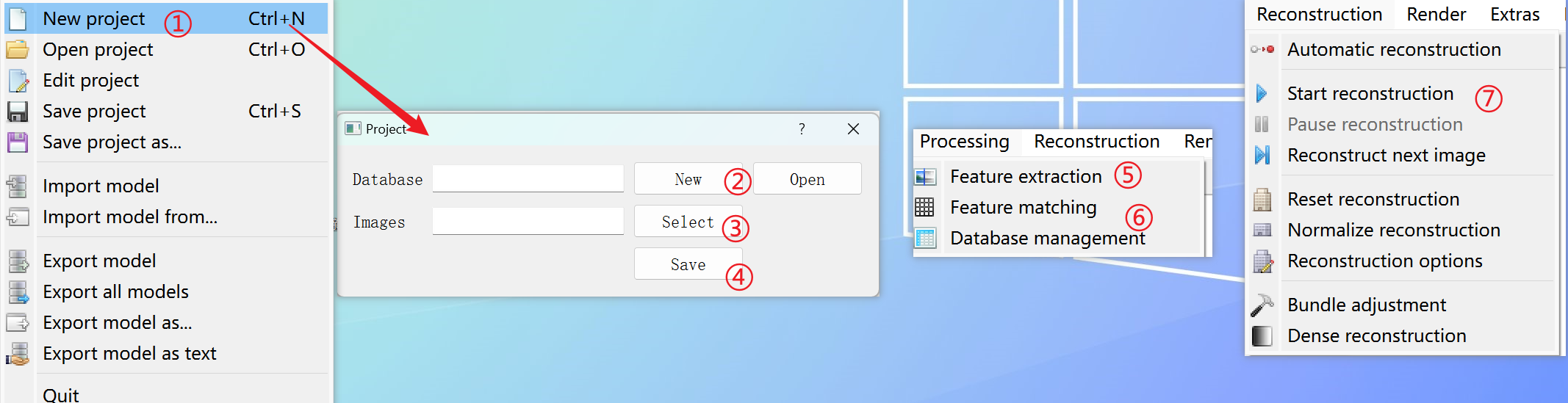
8. 使用colmap获取点云数据
利用colmap对下载的数据进行多视图重建,得到稀疏点云和相机位姿作为3DGS的基础。
下图是使用colmap新建工程、选择图像、特征提取、特征匹配和三维重建的流程
重建后选择导出模型到和图像文件夹同一级,命名为sparse\0\,导出后为三个.bin文件
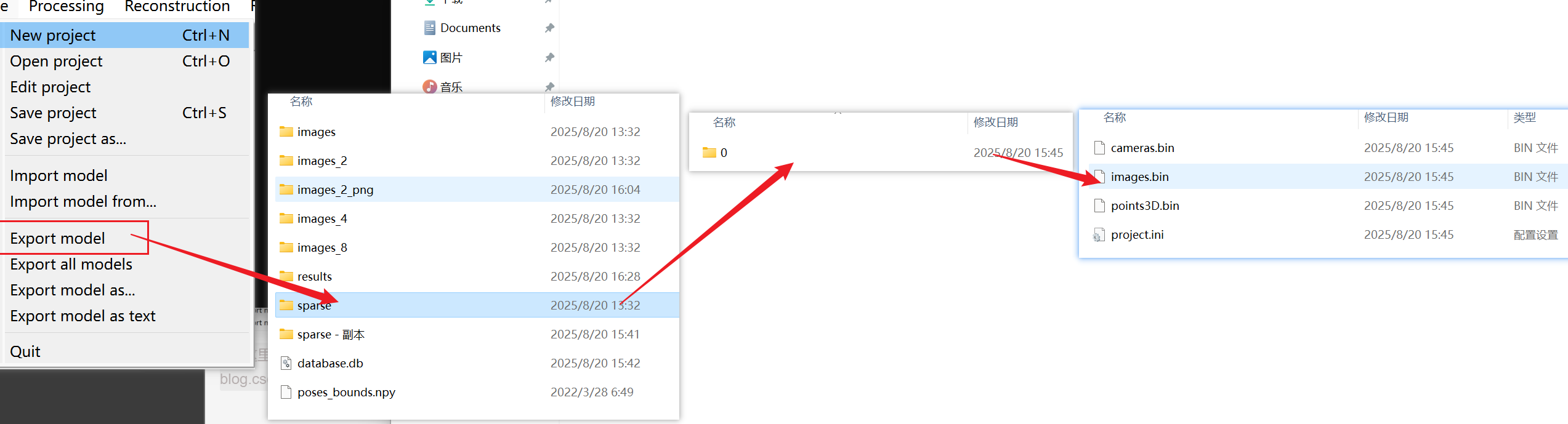
文件夹按照如下放置
<location>
|---images
| |---<image 0>
| |---<image 1>
| |---...
|---sparse|---0|---cameras.bin|---images.bin|---points3D.bin
- 3DGS训练获取椭球体的参数
在gsplat的虚拟环境中,cd到gsplat源码目录下,执行examples下的simple_trainer.py进行训练,需要修改的是数据的路径、选择图像下采样的系数和输出文件夹路径。
python examples/simple_trainer.py mcmc --data_dir data/<dataset> --data_factor 2 --result_dir results/<results name> --camera_model pinhole --save_ply --with_ut --with_eval3d
- 使用viewer查看
在results路径下会有如下的结果

在gsplat的虚拟环境中,cd到gsplat源码目录下,执行如下命令,需要修改你的,pt路径
python examples/simple_viewer_3dgut.py --ckpt data/360_v2/bicycle/results/ckpts/ckpt_29999_rank0.pt
打开如下的网页

等待网页加载完成后,即可查看3DGS和3DGUT的结果。
