粗粮厂的基于flink的汽车实时数仓解决方案
基于flink的实时数仓解决方案
- 1 背景
- 2 业务模型
- 1 业务框架
- 2 难点痛点
- 3技术选型
- 1 计算引擎
- 2 中间存储
- 3 查询引擎
- 4 flink计算架构设计
- 1 纯实时架构
- 2 纯实时+定期补充离线数据
- 3 纯实时+定期刷新过期binlog
- 4 lamdba + 分字段更新 + 历史过期数据刷新
- 5 痛点解决
- delta join
- merge-engine
- hologres分字段更新
这里主要是做一个记录毕竟工作了这么多年,想要总结一下,所以就慢慢写,慢慢更新了,想到哪里写哪里吧。
1 背景
其实背景很简单,就是要做实时数仓,总的原因是提高数据的可用性与时效性,所以单纯的批处理已经无法满足业务需求了,甚至有些业务从动作发生,到业务处理,到数仓处理,到展示可能 要求整体流程在5s以内,所以就有了这么一个项目的诞生。
2 业务模型
1 业务框架
汽车领域的业务其实都大差不差,包含生产,销售,交付等等,所以在博主这里,主要分为以下数据域:线索,销售,交付,售后 四大部分。
其中有一些数据域的融合,例如 线索到销售的漏斗转化,线索到客服之类的融合。
2 难点痛点
其实具体的业务模型,对于开发汽车领域的同学来说,没什么具体作用,而痛点难点,却是相同的,例如:
- flink超长周期的,秒级运算如何维护,一个客户21年留下来联系方式,今天忽然买了一辆汽车,这个转化率 如何能够秒级更新?有两张表,用户信息表(uid, tag_id, level),和用户标签表(tag_id,tag_name),下游想要一个,能够获取全部数据的,全量数据做主流推送,去更新宽表,两边数据的时间跨度会有好几年,这时候数据要怎么使用维护?
- 一张300个字段的宽表,怎么保证实时更新每个字段?
3技术选型
1 计算引擎
这里可选的不多,在满足秒级更新与吞吐量的情况下,这里首选flink
2 中间存储
中间存储指的是,实时数仓中间存储层,flink内部状态,各种关联的维度表等等。
维度表:这里指实时维表,一个任务不停写入数据,另一个任务把他当做维度表来使用。
考察了 MySQL,iceberg,paimon,hologres 几个存储:
- 其中MySQL吞吐量和单表不太够
- iceberg 延迟太高,写入后可读要有一定延迟,达不到业务要求,而且hdfs查询也慢
- paimon与iceberg差不多,但能好很多
- hologres,性能最好,但价格最高
- kafka 可读性与永久存储达不到要求
所以综合比较,最后选择了hologres来做中间存储,消费cdc消费binlog可以达到类似使用kafka的模式
3 查询引擎
这里主要指服务端查询数据的存储,这里用过很多存储,mysql ,doris,iceberg,hologres,最终目前采用的是iceberg+hologres的方案。
- mysql还是那个样子,对于实时汇总的明细,例如百万 ,千万级明细,多维度汇总展示,性能上有欠缺。
- doris 会有热点问题,而且需要专门的集群维护,另外服务端使用,经常会关联维度表展示,这部分性能也不是特别好
- iceberg 便宜,量大,慢,除了慢,似乎没有不好的地方了
- 所以最终采用的是 hologres+iceberg的模式,直接页面展示的各种汇总值,明细值,使用的都是hologres存储,在优化好索引后,千万级别的数据做聚合也可以做到500ms以内,iceberg提供明细下载能力,详细数据使用iceberg+spark提供给用户
4 flink计算架构设计
1 纯实时架构
这里可以理解为 flink+kafka 这种方式,我们运行过一段时间,但仅限于比较简单的业务架构,像是复杂一点的,尤其是历史累计值那种,就会很被动了,例如上面说的,要统计用户转化率,这个转化率周期可能会跨度好几年,所以就不太合适这种指标的开发,但是用作etl的动作,提供明细数据是非常合适的
2 纯实时+定期补充离线数据
这个其实是第一种方案的升级版本,也是flink+kafka,但是会定期的用spark把离线的数据推送一份到kafka里,也就是kafka的topic里时刻,都会有全部的数据,可能会有重复,但不会少数据,所以这样用flink计算,无论是累计值,还是明细,都可以在flink state里取到。唯一的区别是什么呢,资源消耗会比较大,因为kafka和flink使用的资源会
3 纯实时+定期刷新过期binlog
这种则是第二种方式的升级版,使用的是flink+binlog的方式,如果数据量少,可能用的是mysql,数据量大,可能hologres,用flinkcdc的方式,消费binlog数据,例如 如果flink state是7天的生命周期,每天update原始数据库的 7天以前产生的数据,把etl时间更新成now,这样 所有now - 7day以前的数据,都是过期的了,每次刷新的数据量就少了,更新的数据也少了
这个方案也使用过大约1年左右,目前发现 一个flink任务中,总的数据量 不超过20G以上,用这种方式都非常方便,甚至可以说又方便又快。
4 lamdba + 分字段更新 + 历史过期数据刷新
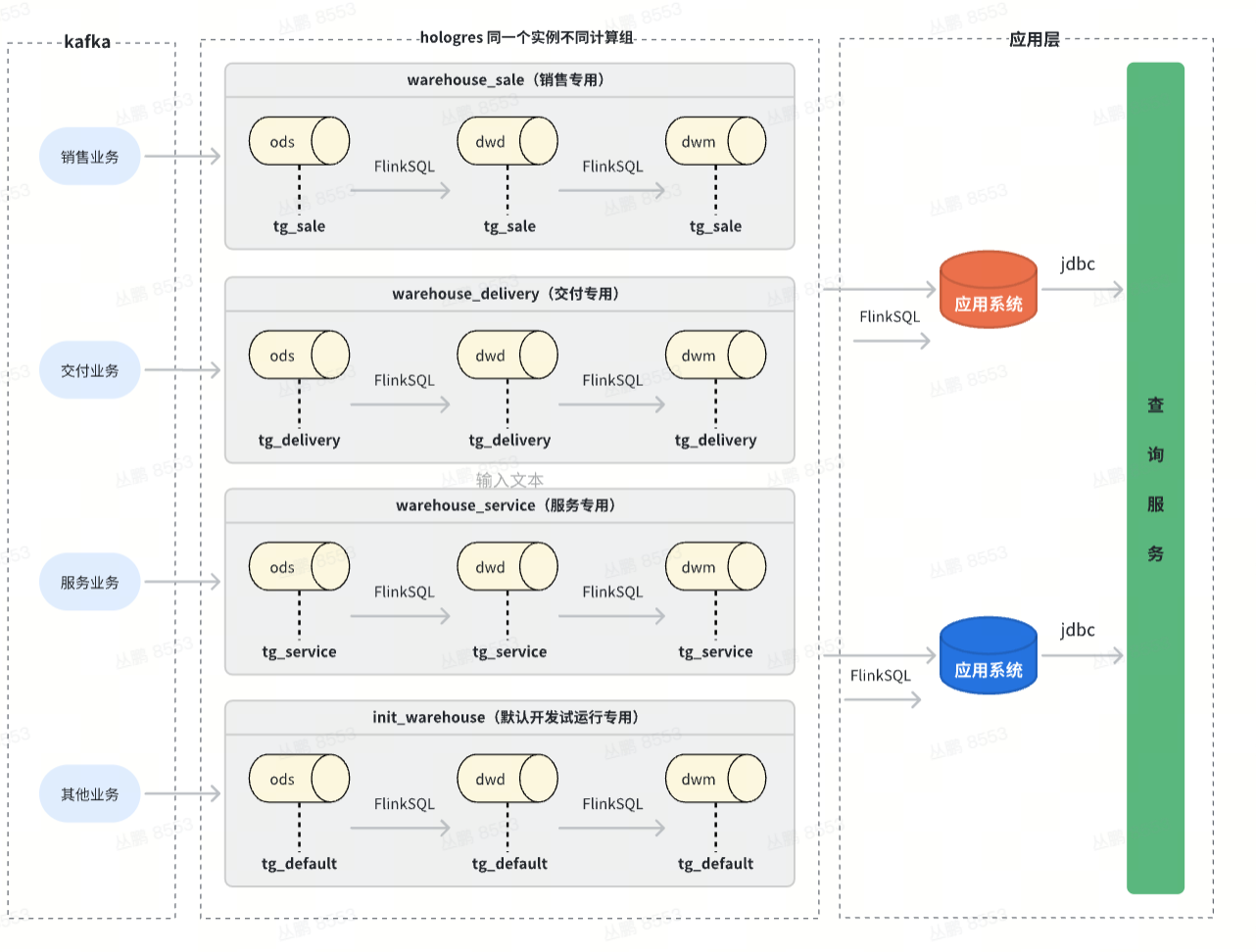
最后一种,也是正在使用的就是,用目前市面最常用的lamdba的方案 ,也就是实时+离线的方式,每次离线任务执行完,通过更新视图的方式,离线union实时 ,两张表 共同提供数据,使用业务时间做切分。
另外使用hologres的分字段更新,一个表10个字段,通过主键,多个flink任务共同更新一张hologres表,下游可以直接接binlog就可以一行数据,只要主键相同,就能接到好几个表的数据,而且不会过期,永久存储。这种方式,适用于上文说的 300个字段,多个数据域通过同一个主键来将数据打平一张大宽表。
5 痛点解决
delta join
这里主要是flink2.2中预计上线的一个能力,是双流 无状态join,需要双流都是binlog,也就是有原始的永久存储,也就是state中没有状态保留,每次都loop up join表,两个超级大表互相关联,flink只需要提供很小的内存就可以执行,并且不会有状态过期的问题,对于时间跨度超级大的场景最好用
merge-engine
这里主要是把paimon中的一些能力 应用到了flink 对于 hologres上,这里是对sink的 connector的改造
例如数据插入的时候,会默认保留首条,抛弃后续数据,或者保留最大最小等。
hologres分字段更新
这里是hologres的能力 ,通过相同数据,将不同数据写入到目标表的同一行里,省去了join的动作,一方面是解耦,另一方面解决的状态过期的问题