(Arxiv-2025)OVIS-U1技术报告
OVIS-U1技术报告
paper title:Ovis-U1 Technical Report
paper是Ovis Team, Alibaba Group发布在Arxiv 2025的工作
Code:链接
Abstract
在本报告中,我们介绍了 Ovis-U1,这是一款拥有 30 亿参数的统一模型,集成了多模态理解、文本生成图像以及图像编辑能力。Ovis-U1 构建于 Ovis 系列模型的基础之上,采用了基于扩散的视觉解码器,并配备了一个双向 token 精炼器,使其在图像生成任务中的表现可与 GPT-4o 等领先模型相媲美。与一些在生成任务中采用冻结 MLLM 的模型不同,Ovis-U1 从语言模型出发,采用统一训练方法进行训练。与仅在理解或生成任务上进行训练的模型相比,统一训练展现出更优的性能,证明了融合这两类任务所带来的增强效果。在 OpenCompass 多模态学术基准测试中,Ovis-U1 取得了 69.6 的得分,超越了当前的先进模型 Ristretto-3B 和 SAIL-VL-1.5-2B。在文本生成图像任务中,Ovis-U1 在 DPG-Bench 和 GenEval 基准上分别获得了 83.72 和 0.89 的高分。在图像编辑方面,Ovis-U1 在 ImgEdit-Bench 和 GEdit-Bench-EN 基准上分别取得了 4.00 和 6.42 的成绩。作为 Ovis 统一模型系列的初始版本,Ovis-U1 在多模态理解、生成和编辑等方面拓展了现有模型的边界。

图 1:Ovis-U1 功能能力的全面示意图。
1 Introduction
多模态大语言模型(MLLMs)的快速发展,成为推动通用人工智能(AGI)日益精进的核心力量。近期由 OpenAI(2025)发布的 GPT-4o 显示出,能够在多种模态中统一理解与生成的模型,正在极大地改变各类现实应用场景。GPT-4o 原生集成了图像生成与先进语言能力,使用户能够通过自然语言对话完成复杂的视觉任务。这些任务(如图像编辑(Brooks 等,2023)、多视角合成(Mildenhall 等,2021)、风格迁移(Gatys 等,2016)、目标检测(Zou 等,2023)、实例分割(Hafiz & Bhat,2020)、深度估计(Mertan 等,2022)、法线估计(Qi 等,2018)),以往依赖多个专用模型,现在可被统一、高效且准确地完成。这标志着多模态感知能力的一次突破,也预示着统一的多模态理解与生成模型(Zhang 等,2025a)将在处理文本与视觉任务上实现无缝协作的新时代的到来。
GPT-4o 的出现,标志着 AGI 相关领域向统一的多模态理解与生成框架迈出关键一步。这也引发了两个根本性问题:第一,如何使一个多模态理解模型具备图像生成能力?这需要设计一个能够与 MLLM 无缝协作的视觉解码器。第二,如何有效地在理解与生成任务上对统一模型进行训练?我们观察到,GPT-4o 的理解能力因集成了图像生成能力而增强,这表明统一训练可能协同提升多任务表现。本文将通过 Ovis-U1 模型探讨这两个问题。
借鉴 GPT-4o 的设计思路,我们提出 Ovis-U1,一个拥有 30 亿参数的统一模型,扩展了 Ovis 系列(Lu 等,2024)的能力。该模型采用了一个基于扩散 Transformer 架构的全新视觉解码器(Labs,2024a;Esser 等,2024)以及一个双向 token 精炼器(Ma 等,2024;Kong 等,2024),以增强文本和视觉嵌入之间的交互能力。这些改进使 Ovis-U1 能够根据文本描述生成高质量图像,并根据文本指令对图像进行优化与编辑。Ovis-U1 使用统一的训练策略,在各类多模态数据上同时执行多任务训练。全面的消融实验表明,我们的统一训练策略协同提升了理解与生成的表现。
Ovis-U1 的目标有两个:其一是通过引入新颖的架构与训练策略,改进现有的 MLLM 模型,在处理复杂任务时增强其多模态数据的理解、生成和编辑能力,提高精度与灵活性;其二是通过开源发布 Ovis-U1,推动社区中的 AI 发展,促进协同研究与创新,加速构建具备先进多模态推理与操作能力的通用 AI 系统。
在本报告中,Ovis-U1 的发布标志着多模态 AI 系统发展中的关键进展,不仅延续了 Ovis 系列的强项,也为未来的突破奠定基础。以下是 Ovis-U1 的主要特性:
-
数据多样性:Ovis-U1 在涵盖文本-图像理解、文本生成图像以及图像编辑等多任务的多模态数据上进行训练。这种多样化训练使模型能够在广泛应用场景中表现出色,从文本描述中生成精细图像,到根据复杂指令对图像进行编辑与优化。通过在统一框架中学习多任务,Ovis-U1 提升了泛化能力,能够以高准确度应对现实世界中的多模态挑战。
-
架构改进:在以往 Ovis 模型的基础上,Ovis-U1 进一步增强了其多模态理解能力。它引入了一个基于扩散架构的新视觉解码器和一个双向 token 精炼器,用于强化文本和视觉特征间的交互。视觉解码器采用多模态扩散 Transformer(MMDiT)作为主干,并使用旋转位置编码(RoPE),实现从文本到高保真图像的生成。双向 token 精炼器提升了文本-图像合成和图像编辑的能力。
-
统一训练:与以往专注于单一任务的模型不同,Ovis-U1 采用了统一的训练方法,在 6 个训练阶段(详见表 2)中全面利用其多模态能力。该方法确保模型能在理解文本与视觉输入、生成与编辑图像等各任务间进行有效整合和学习。统一训练框架使 Ovis-U1 能够在不同应用场景中无缝运行,进一步拓展了多模态 AI 的性能边界。
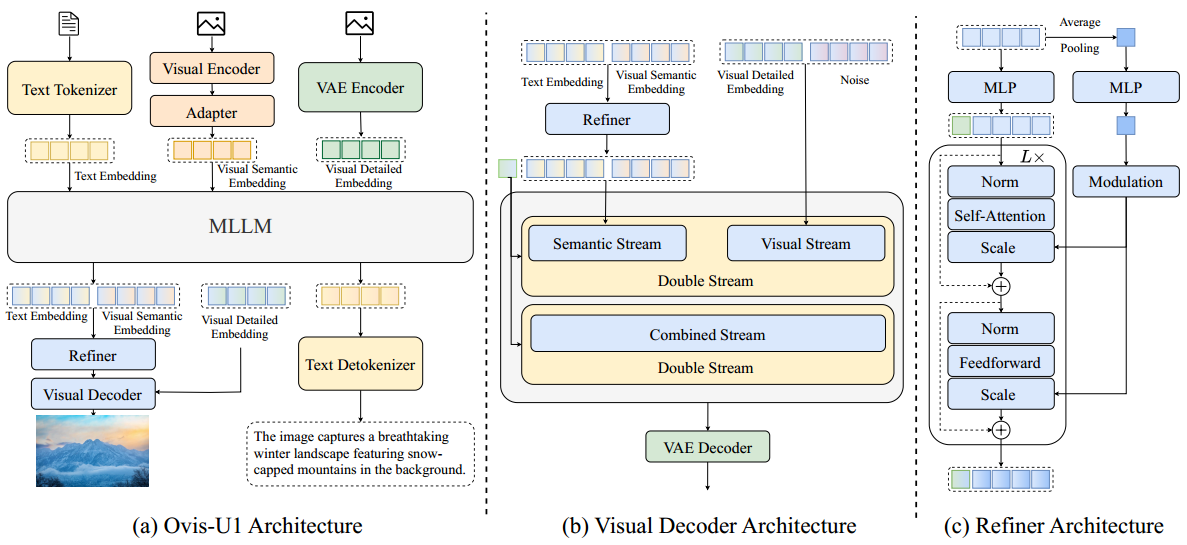
图 2:Ovis-U1 的整体架构。(a) Ovis-U1 模型通过共享的多模态大语言模型(Multimodal Large Language Model,MLLM)整合文本与视觉输入。图像生成通过视觉解码器(Visual Decoder)完成,文本生成通过文本反编码器(Text Detokenizer)实现。一个适配器(Adapter)用于连接视觉编码器与 MLLM。解码前,条件嵌入会通过精炼模块(Refiner Module)进行质量提升。(b) 精炼模块的架构由两个堆叠的 Transformer 块组成,调制操作应用于平均池化后的特征。绿色的 token 表示一个可学习的 [CLS] token,用于从条件嵌入中聚合全局信息。
表1:OVIS-U1的模型结构细节。

2 Architecture
Ovis-U1 的结构如图 2 所示,各模块的详细信息总结于表 1 中。总体来看,Ovis-U1 延续了 Ovis(Lu 等人,2024)的架构,在其基础上添加了一个视觉解码器以生成图像。
LLM 与文本分词器:我们采用 Qwen3 系列(Yang 等人,2025)作为大语言模型的主干。为了构建一个具有 30 亿参数的统一模型,我们使用了 Qwen3-1.7B。与之前直接使用多模态大语言模型(如 Qwen-VL(Bai 等人,2025))并在训练期间保持冻结不同,Ovis-U1 从一个语言模型初始化,并通过视觉理解与生成数据进行训练。该统一训练策略协同提升了模型在理解与生成任务上的表现。
视觉编码器与适配器:我们在 Ovis 的基础上增强了视觉编码器并保留其原始视觉适配器。视觉编码器从 Aimv2-large-patch14-448(Fini 等人,2025)初始化,经过修改以原生支持任意分辨率图像,避免了对图像进行分块处理的策略。为实现这一点,我们对原始的固定尺寸位置编码进行插值调整,并引入了二维旋转位置编码(2D RoPE)(Su 等人,2024)以增强空间感知能力。该结构还使用了变长序列注意力机制(Dao 等人,2022;Dao,2024),并借鉴了 NaViT(Dehghani 等人,2023)中的 token packing 策略,高效处理不同分辨率图像的批处理数据。编码器之后,视觉适配器通过与 Ovis 相同的概率化分词方法将视觉模态与语言模态桥接起来。该模块首先通过像素重排(pixel shuffle)进行空间压缩,然后接线性头与 softmax 函数将特征转化为对视觉词汇表的概率分布。最终输入至 LLM 的嵌入是基于该分布对可学习嵌入表的加权平均。
视觉解码器与 VAE:我们使用扩散 Transformer 作为视觉解码器。具体地,受 FLUX(Labs,2024a)启发,我们采用 MMDiT(Esser 等人,2024)与 RoPE(Su 等人,2024)为骨干网络,并使用流匹配(flow matching)作为训练目标。通过将层数和注意力头从 57 和 24 分别减少到 27 和 16,获得了一个参数量为 10 亿的视觉解码器。该解码器随机初始化,并从头训练。鉴于解码器容量有限,我们采用了 SDXL 的 VAE 模型(4 通道)并在训练中保持冻结。参考 FLUX.1 Redux(Labs,2024b),视觉语义嵌入与文本嵌入进行拼接,作为图像生成的语义条件。此外,参考 FLUX.1 Kontext(Labs 等人,2025),上下文图像会通过 VAE 编码器被编码为 latent token。相较于视觉语义嵌入,这些上下文图像 token 含有更丰富的细节信息。最终,这些包含详细视觉信息的嵌入,与图像 token(即噪声)一同输入至解码器的视觉流中。
精炼器(Refiner):我们引入了一个双向 token 精炼器,以增强视觉嵌入与文本嵌入之间的交互。参考 Kong 等人(2024)与 Ma 等人(2024),我们堆叠了两个带有调制机制(modulation)的 Transformer 块构成精炼器。考虑到 LLM 不同层对图像与文本捕获的信息粒度不同,为了充分利用这种差异,我们将倒数第一层与倒数第二层的特征进行拼接,并送入精炼器进行信息交互,从而生成更优的条件引导。值得注意的是,先前基于文本的生成模型 FLUX(Labs,2024a)通常引入 CLIP 来捕捉全局特征。为了替代 CLIP(Radford 等人,2021),我们引入了可学习的 [CLS] token。通过将该 token 与由 LLM 生成的嵌入拼接,并送入精炼器进行交互,模型得以捕获全局信息。
3 Data Composition and Training Procedure
3.1 Data Composition
为了训练 Ovis-U1,我们使用了三类多模态数据:多模态理解数据、文本生成图像数据(T2I)以及图像+文本生成图像数据。以下分别对每类数据进行详细说明。
多模态理解数据:该类数据包含公开数据和我们自建的数据。公开数据来源包括 COYO(Byeon 等人,2022)、Wukong(Gu 等人,2022)、Laion(Schuhmann 等人,2022)、ShareGPT4V(Chen 等人,2024a)和 CC3M(Sharma 等人,2018)。此外,我们还建立了一套数据预处理流程,用于过滤噪声数据、提升图文描述质量,并调整不同数据类型的比例以确保最优训练效果。
文本生成图像数据(T2I):对于文本生成图像任务,我们使用 Laion5B(Schuhmann 等人,2022)和 JourneyDB(Sun 等人,2023)。具体而言,在 Laion5B 中,我们筛选美学评分高于 6 的样本,并使用 Qwen 模型(Wang 等人,2024)为每张图像生成更详细的描述,从而构建 Laion-aes6 数据集。
图像+文本生成图像数据:该类别进一步细分为以下四种类型:
• 图像编辑数据:我们采用的公开数据集包括 OmniEdit(Wei 等人,2024)、UltraEdit(Zhao 等人,2024)和 SeedEdit(Ge 等人,2024)。
• 参考图像驱动的图像生成数据:用于主体驱动图像生成的数据来源包括 Subjects200K(Tan 等人,2024)和 SynCD(Kumari 等人,2025);用于风格驱动图像生成的数据集为 StyleBooth(Han 等人,2024)。
• 像素级控制的图像生成数据:此类任务包括 canny-to-image、depth-to-image、图像修复(inpainting)、图像扩展(outpainting),数据来自 MultiGen 20M(Qin 等人,2023)。
• 自建数据:我们还构建了额外的数据集用于补充上述公开数据资源,涵盖风格驱动、内容移除、风格迁移、去噪/去模糊、图像上色、文本渲染等多个细分类别。
3.2 Training Procedure
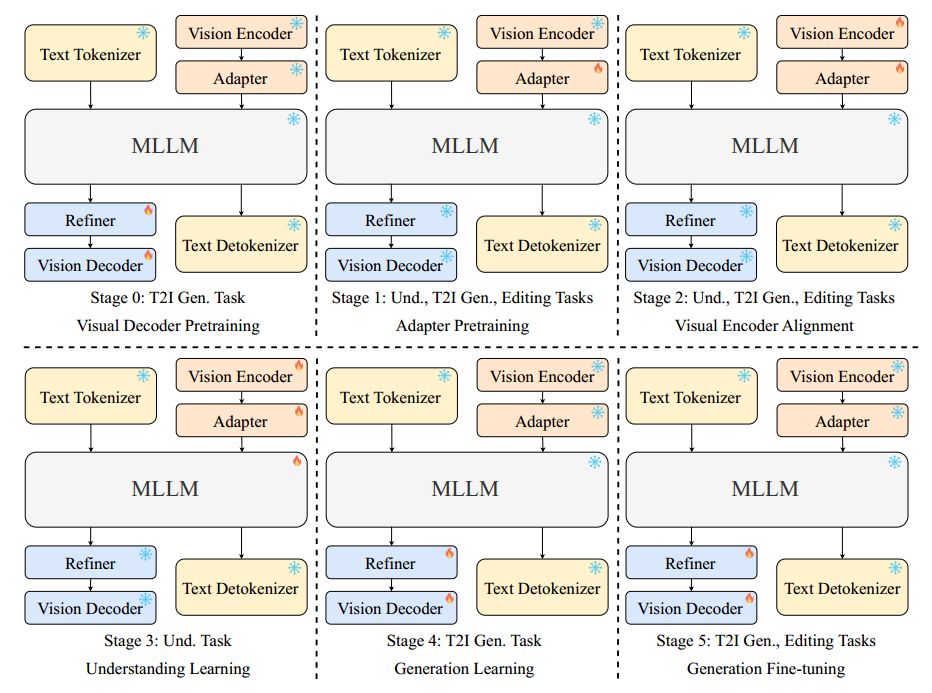
图 3:提出的六阶段训练流程概览。我们通过一系列精心设计的阶段逐步训练 Ovis-U1 模型。图中雪花图标表示冻结的模块,火焰图标表示可训练的模块。
与以往直接使用预训练多模态大语言模型(MLLM)(如 Qwen-VL(Bai 等人,2025))的方法不同,我们从预训练语言模型(LLM)出发进行训练。给定预训练的 LLM 和视觉编码器,Ovis 总共包含 4 个训练阶段:适配器预训练、视觉编码器对齐、理解学习和 DPO。为了增强生成能力,我们在 Ovis-U1 中新增了多个训练阶段。每个训练阶段的详细信息如表 2 所示。
阶段 0:视觉解码器预训练。我们为视觉解码器构建了一个 10 亿参数的扩散 Transformer(diffusion transformer),从随机初始化开始进行训练,以构建基础的图像生成能力。此阶段使用文本生成图像(T2I)训练数据,训练过程中,视觉解码器与细化器(refiner)联合,根据 LLM 的嵌入生成图像。
阶段 1:适配器预训练。适配器用于在视觉编码器与 LLM 之间建立桥梁,对齐图像和文本的嵌入向量。更多细节见 Ovis 原论文(Lu 等人,2024)。适配器从随机初始化开始,需要在此阶段进行训练。与 Ovis 不同,Ovis-U1 融合了理解、T2I 和图像编辑三类任务进行训练。
阶段 2:视觉编码器对齐。在本阶段中,视觉编码器和适配器将一起进行微调,进一步对齐图像与文本的嵌入。此阶段同样使用三类任务(理解、T2I 和图像编辑)进行训练,其中生成任务有助于不同模态嵌入之间的融合对齐。
阶段 3:理解学习。此阶段与 Ovis 相同,训练视觉编码器、适配器和 LLM 在理解类任务中的表现。完成此阶段后,这些模块的参数将被冻结,以保持模型的多模态理解能力。
阶段 4:生成学习。由于在阶段 3 中对 LLM 参数进行了微调,因此我们在本阶段训练 refiner 和视觉解码器,使其更好地适应优化后的文本和图像嵌入。实验表明,与阶段 0 相比,文本生成图像的性能有显著提升,因为阶段 1-3 改善了文本嵌入与图像嵌入之间的对齐效果。
阶段 5:生成微调。在具备基本文本生成图像能力的基础上,本阶段进一步微调解码器,提升其在 T2I 与图像编辑任务中的表现。
表2:OVIS-U1的每个训练阶段的详细信息。
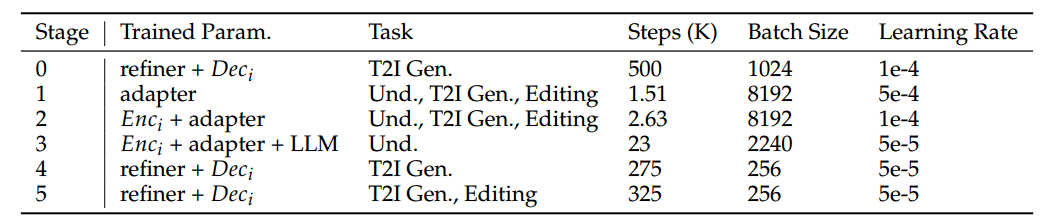
表3:OVIS-U1的每个训练阶段的详细信息。
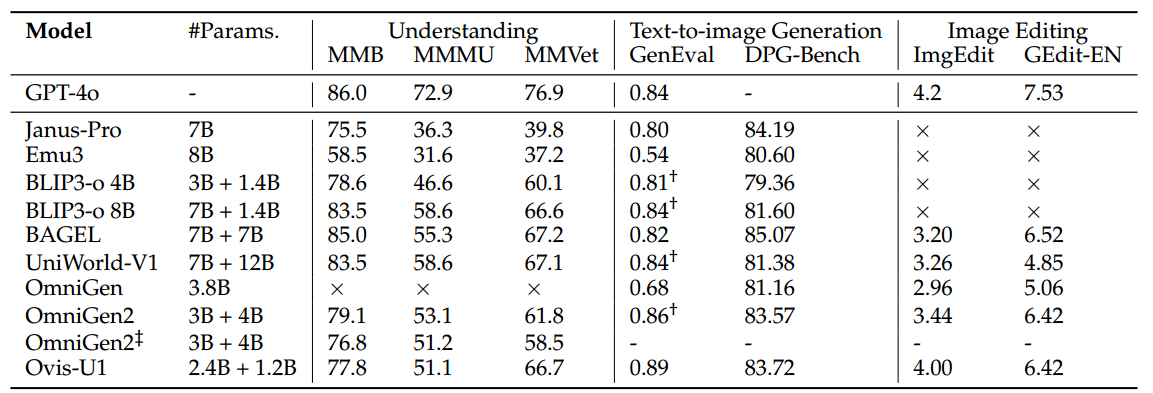
4 Evaluation
类似于 GPT-4o,近期的统一多模态模型具备理解输入图像、根据文本提示生成图像,以及根据指令编辑图像的能力。因此,我们从三个任务维度对这些模型进行基准评估:图像理解、文本生成图像和图像编辑。
图像理解:为评估模型的理解能力,我们采用了广泛使用的 OpenCompass 多模态学术基准测试集,包括 MMBench(Liu 等,2024a)、MMStar(Chen 等,2024b)、MMMU-Val(Yue 等,2024)、MathVista-Mini(Lu 等,2023)、HallusionAvg(Guan 等,2024)、AI2D-Test(Kembhavi 等,2016)、OCRBench(Liu 等,2024b)和 MMVet(Yu 等,2024)。Avg Score 为这 8 个基准的平均分。由于目前大多数主流多模态大语言模型均在该基准上进行了评估,因此统一模型可以与它们进行便捷对比。
文本生成图像(Text-to-Image Generation):为评估文本生成图像能力,我们采用了 CLIPScore(Hessel 等,2021)、DPG-Bench(Hu 等,2024)和 GenEval(Ghosh 等,2023)基准。CLIPScore 曾用于 DALL-E 3(Betker 等,2023),其中前 1K 个提示语被用于计算 CLIPScore。DPG-Bench 和 GenEval 是文本生成图像和统一模型领域广泛使用的两个基准。部分前期研究会对 GenEval 的提示语进行改写以提升性能,而本文报告使用的是原始提示语下的性能结果。
图像编辑(Image Editing):为评估图像编辑能力,我们采用 GEdit-Bench(Liu 等,2025)和 ImgEdit(Ye 等,2025)两个近期提出的基准数据集,分别包含 606 和 811 对图像-指令对。这两个基准都使用先进的 GPT 模型来评估编辑后图像的效果。