YOLO系列对指定图片绘制模型热力图
RTDETR系列绘制热力图指路:
RT-DETR系列对指定图片绘制模型热力图-CSDN博客![]() https://blog.csdn.net/qq_54708219/article/details/148657372?spm=1001.2014.3001.5502任务:实现类激活映射(Class Activation Mapping, CAM)可视化,生成热力图以展示模型在图像中关注的关键区域。
https://blog.csdn.net/qq_54708219/article/details/148657372?spm=1001.2014.3001.5502任务:实现类激活映射(Class Activation Mapping, CAM)可视化,生成热力图以展示模型在图像中关注的关键区域。
核心功能:
-
加载YOLOv8模型:使用预训练权重和配置文件初始化检测模型
-
图像预处理:通过
letterbox函数调整图像尺寸并添加填充 -
热力图生成:使用Grad-CAM系列算法(GradCAM/GradCAM++/XGradCAM)可视化模型关注区域
-
结果保存:为每张输入图像生成多个检测目标的热力图
注意:在运行以下代码时,安装grad-cam库:
pip install grad-cam然后准备以下参数:
def get_params():params = {'weight': '/data/ctc/yolov11/YOLO11m.pt', # 训练出来的权重文件'cfg': '/data/ctc/yolov11/ultralytics/cfg/models/11/yolo11m.yaml', # 训练权重对应的yaml配置文件'device': 'cuda:1', # CPU/GPU'method': 'GradCAM', # GradCAMPlusPlus, GradCAM, XGradCAM , 使用的热力图库文件不同的效果不一样可以多尝试'layer': 'model.model[9]', # 想要检测的对应层'backward_type': 'all', # class, box, all'conf_threshold': 0.01, # 0.6 # 置信度阈值,有的时候你的进度条到一半就停止了就是因为没有高于此值的了'ratio': 0.02 # 0.02-0.1}return paramsif __name__ == '__main__':img_folder_path = "/data/ctc/yolov11/jitan_images" # 需要绘制热力图的图片,放在一个文件夹下面output_path = "result" # 输出文件夹,里面每个文件夹的名字就是img_folder_path的图片名字注意:cfg的yaml文件请严格指定模型大小:在yolo[版本号]后面添加n,s,m,l,x
img_folder_path:
其余的都是YOLO目标检测框架常用文件,这里不作过多解释。
完整代码如下:
import warnings
warnings.filterwarnings('ignore')
warnings.simplefilter('ignore')
import torch, yaml, cv2, os, shutil
import numpy as np
np.random.seed(0)
import matplotlib.pyplot as plt
from tqdm import trange
from PIL import Image
from ultralytics.nn.tasks import DetectionModel as Model
from ultralytics.utils.torch_utils import intersect_dicts
from ultralytics.utils.ops import xywh2xyxy
from pytorch_grad_cam import GradCAMPlusPlus, GradCAM, XGradCAM
from pytorch_grad_cam.utils.image import show_cam_on_image
from pytorch_grad_cam.activations_and_gradients import ActivationsAndGradientsdef letterbox(im, new_shape=(1024, 1024), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True, stride=32):# Resize and pad image while meeting stride-multiple constraintsshape = im.shape[:2] # current shape [height, width]if isinstance(new_shape, int):new_shape = (new_shape, new_shape)# Scale ratio (new / old)r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])if not scaleup: # only scale down, do not scale up (for better val mAP)r = min(r, 1.0)# Compute paddingratio = r, r # width, height ratiosnew_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh paddingif auto: # minimum rectangledw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh paddingelif scaleFill: # stretchdw, dh = 0.0, 0.0new_unpad = (new_shape[1], new_shape[0])ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratiosdw /= 2 # divide padding into 2 sidesdh /= 2if shape[::-1] != new_unpad: # resizeim = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))left, right = int(round(dw - 0.1)), int(round(dw + 0.1))im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add borderreturn im, ratio, (dw, dh)class yolov8_heatmap:def __init__(self, weight, cfg, device, method, layer, backward_type, conf_threshold, ratio):device = torch.device(device)ckpt = torch.load(weight)model_names = ckpt['model'].namescsd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32model = Model(cfg, ch=3, nc=len(model_names)).to(device)csd = intersect_dicts(csd, model.state_dict(), exclude=['anchor']) # intersectmodel.load_state_dict(csd, strict=False) # loadmodel.eval()print(f'Transferred {len(csd)}/{len(model.state_dict())} items')target_layers = [eval(layer)]method = eval(method)colors = np.random.uniform(0, 255, size=(len(model_names), 3)).astype(np.int32)self.__dict__.update(locals())def post_process(self, result):logits_ = result[:, 4:]boxes_ = result[:, :4]sorted, indices = torch.sort(logits_.max(1)[0], descending=True)return torch.transpose(logits_[0], dim0=0, dim1=1)[indices[0]], torch.transpose(boxes_[0], dim0=0, dim1=1)[indices[0]], xywh2xyxy(torch.transpose(boxes_[0], dim0=0, dim1=1)[indices[0]]).cpu().detach().numpy()def draw_detections(self, box, color, name, img):xmin, ymin, xmax, ymax = list(map(int, list(box)))cv2.rectangle(img, (xmin, ymin), (xmax, ymax), tuple(int(x) for x in color), 2)cv2.putText(img, str(name), (xmin, ymin - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.8, tuple(int(x) for x in color), 2, lineType=cv2.LINE_AA)return imgdef __call__(self, img_path, save_path):# remove dir if existif os.path.exists(save_path):shutil.rmtree(save_path)# make dir if not existos.makedirs(save_path, exist_ok=True)# img processimg = cv2.imread(img_path)img = letterbox(img)[0]img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)img = np.float32(img) / 255.0tensor = torch.from_numpy(np.transpose(img, axes=[2, 0, 1])).unsqueeze(0).to(self.device)# init ActivationsAndGradientsgrads = ActivationsAndGradients(self.model, self.target_layers, reshape_transform=None)# get ActivationsAndResultresult = grads(tensor)# len(result): 2# result[0].shape: torch.Size([1, 8, 21504])# len(result[1]): 3# result[1][0].shape: torch.Size([1, 68, 128, 128])# result[1][1].shape: torch.Size([1, 68, 64, 64])# result[1][2].shape: torch.Size([1, 68, 32, 32])activations = grads.activations[0].cpu().detach().numpy()# postprocess to yolo outputpost_result, pre_post_boxes, post_boxes = self.post_process(result[0])for i in trange(int(post_result.size(0) * self.ratio)):try:if float(post_result[i].max()) < self.conf_threshold:breakself.model.zero_grad()# get max probability for this predictionif self.backward_type == 'class' or self.backward_type == 'all':score = post_result[i].max()score.backward(retain_graph=True)if self.backward_type == 'box' or self.backward_type == 'all':for j in range(4):score = pre_post_boxes[i, j]score.backward(retain_graph=True)# process heatmapif self.backward_type == 'class':gradients = grads.gradients[0]elif self.backward_type == 'box':gradients = grads.gradients[0] + grads.gradients[1] + grads.gradients[2] + grads.gradients[3]else:gradients = grads.gradients[0] + grads.gradients[1] + grads.gradients[2] + grads.gradients[3] + grads.gradients[4]b, k, u, v = gradients.size()weights = self.method.get_cam_weights(self.method, None, None, None, activations, gradients.detach().numpy())weights = weights.reshape((b, k, 1, 1))saliency_map = np.sum(weights * activations, axis=1)saliency_map = np.squeeze(np.maximum(saliency_map, 0))saliency_map = cv2.resize(saliency_map, (tensor.size(3), tensor.size(2)))saliency_map_min, saliency_map_max = saliency_map.min(), saliency_map.max()if (saliency_map_max - saliency_map_min) == 0:continuesaliency_map = (saliency_map - saliency_map_min) / (saliency_map_max - saliency_map_min)# add heatmap and box to imagecam_image = show_cam_on_image(img.copy(), saliency_map, use_rgb=True)"不想在图片中绘画出边界框和置信度,注释下面的一行代码即可"# cam_image = self.draw_detections(post_boxes[i], self.colors[int(post_result[i, :].argmax())], f'{self.model_names[int(post_result[i, :].argmax())]} {float(post_result[i].max()):.2f}', cam_image)cam_image = Image.fromarray(cam_image)cam_image.save(f'{save_path}/{i}.png')finally:# 清理当前目标的资源torch.cuda.empty_cache()def get_params():params = {'weight': '/data/ctc/yolov11/YOLO11m.pt', # 训练出来的权重文件'cfg': '/data/ctc/yolov11/ultralytics/cfg/models/11/yolo11m.yaml', # 训练权重对应的yaml配置文件'device': 'cuda:1', # CPU/GPU'method': 'GradCAM', # GradCAMPlusPlus, GradCAM, XGradCAM , 使用的热力图库文件不同的效果不一样可以多尝试'layer': 'model.model[9]', # 想要检测的对应层'backward_type': 'all', # class, box, all'conf_threshold': 0.01, # 0.6 # 置信度阈值,有的时候你的进度条到一半就停止了就是因为没有高于此值的了'ratio': 0.02 # 0.02-0.1}return paramsif __name__ == '__main__':img_folder_path = "/data/ctc/yolov11/jitan_images" # 需要绘制热力图的图片,放在一个文件夹下面output_path = "result" # 输出文件夹,里面每个文件夹的名字就是img_folder_path的图片名字for i, filename in enumerate(os.listdir(img_folder_path)):model = yolov8_heatmap(**get_params())print(f"({i + 1}/{len(os.listdir(img_folder_path))}):{filename}")base_name = os.path.splitext(filename)[0]img_path = os.path.join(img_folder_path, filename)result_heatmap_path = os.path.join(output_path, base_name)model(img_path, result_heatmap_path) # 第一个是检测的文件, 第二个是保存的路径看到以下界面运行成功:
批注:在 YOLOv11(以及类似架构)中,post_result.size(0) 的值 21504 表示模型在单张图像上生成的预测框总数。这个数字是由模型的架构设计和输入分辨率决定的,具体计算方式如下:
我都模型输入是1024×1024大小图片,模型使用三个不同尺度的特征图进行预测各特征图分辨率分别为:128×128(步长8),64×64(步长16),32×32(步长32)。在 YOLOv11 中,每个特征图位置生成1个预测框,因此预测总数是:
(128 × 128) + (64 × 64) + (32 × 32) = 16384 + 4096 + 1024 = 21504
如果改变输入分辨率,预测总数会相应变化:
-
输入 512×512:预测总数 = (64×64) + (32×32) + (16×16) = 4096 + 1024 + 256 = 5376
-
输入 1280×1280:预测总数 = (160×160) + (80×80) + (40×40) = 25600 + 6400 + 1600 = 33600
跑出来的结果文件夹output_path:
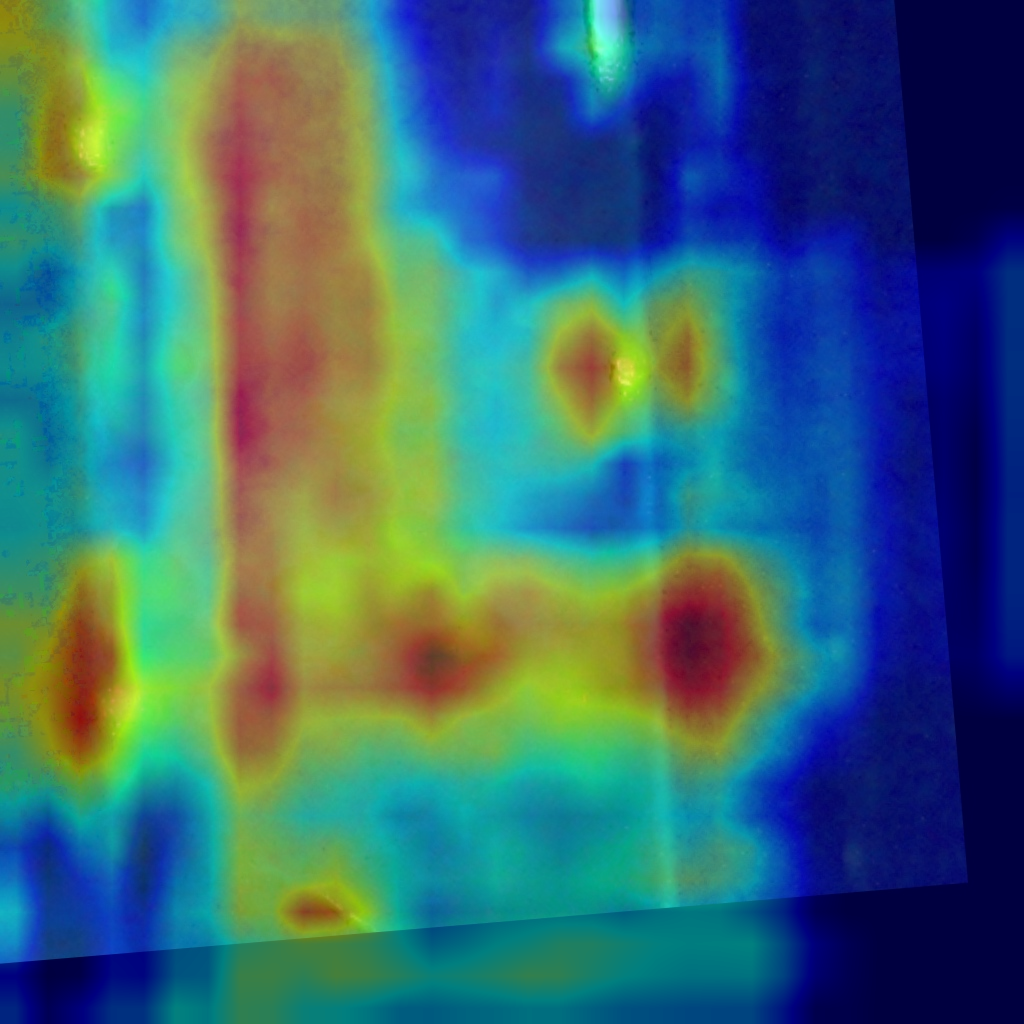
读者可以挑选效果较好的图片,进行展示。