【DSP笔记 · 第4章】算法的奇迹:快速傅里叶变换(FFT)如何改变世界
算法的奇迹:快速傅里叶变换(FFT)如何改变世界
在上一章,我们学习了离散傅里叶变换(DFT)。DFT是一座坚固的桥梁,它将信号处理的理论成功地带入了计算机可以操作的实践领域。有了DFT,我们终于可以用有限的、离散的数据来分析信号的频谱,实现快速卷积等强大的功能。
然而,这座桥梁虽然坚固,但走起来却有点“慢”。直接根据定义计算N点DFT,需要的复数乘法次数大约是 N 2 N^2 N2 次。当N比较小时,比如N=8,计算量是64次,计算机还能应付。但如果N=1024呢?计算量将飙升到 1024 × 1024 1024 \times 1024 1024×1024,超过一百万次!如果是在实时高清视频处理中,N可能更大,这样的计算量是任何现代处理器都无法接受的。在很长一段时间里,DFT的巨大计算量限制了它在许多实时应用中的推广。
直到1965年,两位美国数学家库利(J. W. Cooley)和图基(J. W. Tukey)重新发现并推广了一种算法,彻底改变了这一切。这个算法,就是我们今天的主角——快速傅里叶变换(Fast Fourier Transform, FFT)。
FFT并不是一种新的变换,它不是DFT的替代品或近似品。FFT就是DFT,它是一种计算DFT的极其高效的算法。它的出现,将DFT的计算复杂度从 O ( N 2 ) O(N^2) O(N2) 戏剧性地降低到了 O ( N log N ) O(N \log N) O(NlogN)。这个看似微小的改变,却引发了数字信号处理领域的一场革命,让实时频谱分析、数字通信、雷达信号处理等无数应用从不可能变为了可能。FFT被公认为20世纪最重要的算法之一,它的思想和影响力,至今仍在不断延伸。
今天,我将带你揭开FFT神秘的面纱。我们将不再满足于仅仅“调用”一个FFT函数,而是要深入其内部,理解它那“化繁为简”的惊人智慧。
FFT的核心思想:分而治之的艺术
FFT算法的精髓,可以用四个字来概括:分而治之(Divide and Conquer)。这是一个在计算机科学中无处不在的强大思想:面对一个复杂的大问题,不要硬着头皮去解,而是想办法把它分解成若干个结构相同、规模更小的子问题。然后分别解决这些子问题,最后再将子问题的解合并起来,得到原问题的解。
FFT正是将这种思想运用到了极致。它发现,一个大规模的N点DFT问题,可以通过巧妙的数学变换,分解成两个规模为N/2点的DFT问题。
让我们来看这个分解是如何发生的。这里我们以最经典的按时间抽取(Decimation-In-Time, DIT) 的FFT算法为例。
时间抽取(DIT):奇偶分组的魔术
我们回顾一下N点DFT的定义(为了简化,假设N是2的幂次方):
X ( k ) = ∑ n = 0 N − 1 x ( n ) W N k n , k = 0 , 1 , … , N − 1 X(k) = \sum_{n=0}^{N-1} x(n) W_N^{kn}, \quad k=0, 1, \dots, N-1 X(k)=n=0∑N−1x(n)WNkn,k=0,1,…,N−1
DIT-FFT的第一步,就是把时域输入序列 x ( n ) x(n) x(n) 按照下标的奇偶性分成两组:
- 偶数下标序列: x e ( m ) = x ( 2 m ) x_e(m) = x(2m) xe(m)=x(2m),其中 m = 0 , 1 , … , N / 2 − 1 m=0, 1, \dots, N/2 - 1 m=0,1,…,N/2−1
- 奇数下标序列: x o ( m ) = x ( 2 m + 1 ) x_o(m) = x(2m+1) xo(m)=x(2m+1),其中 m = 0 , 1 , … , N / 2 − 1 m=0, 1, \dots, N/2 - 1 m=0,1,…,N/2−1
现在,我们将原来的求和式拆分成两部分,一部分对所有偶数项求和,另一部分对所有奇数项求和:
X ( k ) = ∑ m = 0 N / 2 − 1 x ( 2 m ) W N k ( 2 m ) + ∑ m = 0 N / 2 − 1 x ( 2 m + 1 ) W N k ( 2 m + 1 ) X(k) = \sum_{m=0}^{N/2-1} x(2m) W_N^{k(2m)} + \sum_{m=0}^{N/2-1} x(2m+1) W_N^{k(2m+1)} X(k)=m=0∑N/2−1x(2m)WNk(2m)+m=0∑N/2−1x(2m+1)WNk(2m+1)
对这个式子进行整理:
X ( k ) = ∑ m = 0 N / 2 − 1 x ( 2 m ) ( W N 2 ) k m + W N k ∑ m = 0 N / 2 − 1 x ( 2 m + 1 ) ( W N 2 ) k m X(k) = \sum_{m=0}^{N/2-1} x(2m) (W_N^2)^{km} + W_N^k \sum_{m=0}^{N/2-1} x(2m+1) (W_N^2)^{km} X(k)=m=0∑N/2−1x(2m)(WN2)km+WNkm=0∑N/2−1x(2m+1)(WN2)km
这里,我们观察到一个关键的性质: W N 2 = ( e − j 2 π / N ) 2 = e − j 2 π / ( N / 2 ) = W N / 2 W_N^2 = (e^{-j2\pi/N})^2 = e^{-j2\pi/(N/2)} = W_{N/2} WN2=(e−j2π/N)2=e−j2π/(N/2)=WN/2。代入上式:
X ( k ) = ∑ m = 0 N / 2 − 1 x e ( m ) W N / 2 k m + W N k ∑ m = 0 N / 2 − 1 x o ( m ) W N / 2 k m X(k) = \sum_{m=0}^{N/2-1} x_e(m) W_{N/2}^{km} + W_N^k \sum_{m=0}^{N/2-1} x_o(m) W_{N/2}^{km} X(k)=m=0∑N/2−1xe(m)WN/2km+WNkm=0∑N/2−1xo(m)WN/2km
我们发现,第一个求和项正好是偶数序列 x e ( m ) x_e(m) xe(m) 的 N/2点DFT,我们记为 X e ( k ) X_e(k) Xe(k)。第二个求和项是奇数序列 x o ( m ) x_o(m) xo(m) 的 N/2点DFT,我们记为 X o ( k ) X_o(k) Xo(k)。
所以,上式可以写成:
X ( k ) = X e ( k ) + W N k X o ( k ) X(k) = X_e(k) + W_N^k X_o(k) X(k)=Xe(k)+WNkXo(k)
一个N点DFT问题,就这样被我们成功地分解成了两个N/2点DFT问题!这就是FFT的第一层分解。
但是,这个分解还没结束。 X e ( k ) X_e(k) Xe(k) 和 X o ( k ) X_o(k) Xo(k) 本身也是DFT,它们的周期是N/2。而我们要求的 X ( k ) X(k) X(k) 的周期是N。当 k k k 从 N / 2 N/2 N/2 增加到 N − 1 N-1 N−1 时会发生什么?
令 k = k ′ + N / 2 k = k' + N/2 k=k′+N/2,其中 k ′ = 0 , 1 , … , N / 2 − 1 k'=0, 1, \dots, N/2-1 k′=0,1,…,N/2−1。利用DFT的周期性和旋转因子的性质( W N k + N / 2 = − W N k W_N^{k+N/2} = -W_N^k WNk+N/2=−WNk),我们可以推导出:
X ( k ′ + N / 2 ) = X e ( k ′ ) − W N k ′ X o ( k ′ ) X(k' + N/2) = X_e(k') - W_N^{k'} X_o(k') X(k′+N/2)=Xe(k′)−WNk′Xo(k′)
综合起来,我们得到了FFT算法最核心的结构:
- 对于前半部分输出 ( k = 0 , … , N / 2 − 1 k=0, \dots, N/2-1 k=0,…,N/2−1):
X ( k ) = X e ( k ) + W N k X o ( k ) X(k) = X_e(k) + W_N^k X_o(k) X(k)=Xe(k)+WNkXo(k) - 对于后半部分输出 ( k = N / 2 , … , N − 1 k=N/2, \dots, N-1 k=N/2,…,N−1):
X ( k ) = X e ( k − N / 2 ) − W N k − N / 2 X o ( k − N / 2 ) X(k) = X_e(k-N/2) - W_N^{k-N/2} X_o(k-N/2) X(k)=Xe(k−N/2)−WNk−N/2Xo(k−N/2)
(上图就是著名的FFT“蝶形运算”单元。它展示了如何用两个N/2点DFT的输出 X e ( k ) X_e(k) Xe(k) 和 X o ( k ) X_o(k) Xo(k),通过一次复数乘法和两次复数加/减法,来计算出N点DFT的两个输出点 X ( k ) X(k) X(k) 和 X ( k + N / 2 ) X(k+N/2) X(k+N/2)。它的形状像一只蝴蝶,因此得名。)
递归分解与运算流图
这个分解过程并不会止步于此。“分而治之”的思想会继续递归下去。
- 每个N/2点的DFT问题,又可以被分解成两个N/4点的DFT问题。
- N/4点的DFT问题,再分解成N/8点的…
- … 这个过程一直持续下去,直到最后分解成最简单的2点DFT问题。而2点DFT的计算非常简单,可以直接写出。
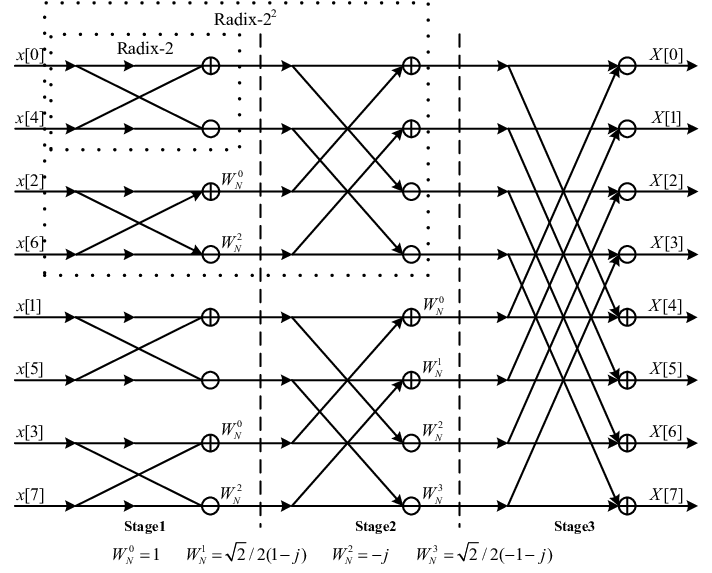
(上图展示了一个完整的8点DIT-FFT运算流图。你可以清晰地看到信号是如何从输入端流向输出端,并逐级进行蝶形运算的。)
观察这个流图,我们可以发现几个关键特征:
- 分级结构:整个计算过程分为 log 2 N \log_2 N log2N 级(例如8点FFT有3级)。每一级都由N/2个蝶形运算单元构成。
- 原位运算: 一个非常巧妙的设计是,每一级蝶形运算的输出,都可以直接覆盖掉其输入所占用的存储空间,而不会影响到同一级的其他运算。这使得整个FFT计算可以在原始的N个存储单元内“原地”完成,极大地节省了内存。
- 输入倒序: 为了实现原位运算,DIT-FFT算法要求输入序列 x ( n ) x(n) x(n) 必须按照一种特殊的顺序排列,叫做位反转序(Bit-Reversal Order)。例如,在8点FFT中,输入序列的下标顺序应该是0, 4, 2, 6, 1, 5, 3, 7。这个顺序是通过将正常顺序的下标(0-7)写成二进制,然后将二进制位前后颠倒得到的(例如,6的二进制是110,颠倒后是011,即3)。
- 输出顺序: 经过位反转输入的DIT-FFT计算后,得到的输出 X ( k ) X(k) X(k) 则是按正常顺序排列的。
频率抽取(DIF)- 另一种视角
除了按时间(输入)进行奇偶抽取的DIT-FFT,还有一种等效的算法是按频率(输出)进行前后抽取的DIF-FFT (Decimation-In-Frequency)。
DIF-FFT的推导过程与DIT类似,但它先进行蝶形运算,再将结果分成两组,分别进行N/2点DFT。它的运算流图看起来像是DIT流图的“转置”版本。
DIF-FFT的特点是:
- 输入顺序: 输入序列 x ( n ) x(n) x(n) 按正常顺序排列。
- 输出倒序: 计算得到的输出 X ( k ) X(k) X(k) 是按位反转序排列的。
在实际应用中,选择DIT还是DIF通常取决于具体的硬件架构或软件设计偏好,它们的计算量和效率是完全一样的。
FFT带来的革命性效率提升
现在,让我们回到最初的问题:FFT到底比直接计算DFT快多少?
-
直接计算DFT:
- 复数乘法: N 2 N^2 N2 次
- 复数加法: N ( N − 1 ) N(N-1) N(N−1) 次
- 复杂度: O ( N 2 ) O(N^2) O(N2)
-
FFT算法:
- 复数乘法: ( N / 2 ) log 2 N (N/2)\log_2 N (N/2)log2N 次
- 复数加法: N log 2 N N \log_2 N Nlog2N 次
- 复杂度: O ( N log N ) O(N \log N) O(NlogN)
让我们用一个具体的例子来感受这种差异。假设我们要计算一个4096点( 4096 = 2 12 4096 = 2^{12} 4096=212)的DFT:
- 直接计算:
- 乘法次数 = 4096 2 ≈ 16 , 777 , 216 4096^2 \approx 16,777,216 40962≈16,777,216 次(约一千七百万次)
- FFT计算:
- 乘法次数 = ( 4096 / 2 ) × log 2 ( 4096 ) = 2048 × 12 = 24 , 576 (4096/2) \times \log_2(4096) = 2048 \times 12 = 24,576 (4096/2)×log2(4096)=2048×12=24,576 次(约两万五千次)
计算量相差了将近 700倍!这就是算法的力量。正是这种指数级的效率提升,使得DFT从一个理论工具,真正变成了可以广泛应用于各种实时系统的实用技术。
FFT的应用:无处不在的“加速引擎”
由于FFT极大地降低了DFT的计算成本,它成为了许多高级信号处理技术的“加速引擎”。
快速卷积
正如我们在上一章讨论的,利用DFT可以高效地计算线性卷积。而将这个过程中的DFT和IDFT计算全部换成FFT和IFFT(快速逆傅里叶变换),我们就得到了快速卷积算法。
一个有趣的问题是,如何用FFT来计算IDFT?
其实非常简单,观察DFT和IDFT的公式:
X ( k ) = ∑ n = 0 N − 1 x ( n ) ( W N ) k n X(k) = \sum_{n=0}^{N-1} x(n) (W_N)^{kn} X(k)=n=0∑N−1x(n)(WN)kn
x ( n ) = 1 N ∑ k = 0 N − 1 X ( k ) ( W N − 1 ) k n x(n) = \frac{1}{N} \sum_{k=0}^{N-1} X(k) (W_N^{-1})^{kn} x(n)=N1k=0∑N−1X(k)(WN−1)kn
它们的形式高度相似,唯一的区别在于旋转因子是 W N W_N WN 还是 W N − 1 W_N^{-1} WN−1(即共轭关系),以及最后是否除以N。利用这个关系,我们可以用同一个FFT程序来计算IDFT,只需要:
- 先对频域序列 X ( k ) X(k) X(k) 取共轭。
- 对共轭后的序列做一次标准的FFT。
- 将得到的结果再取一次共轭。
- 最后将所有结果除以N。
这样,我们就能用同一个高效的FFT核心,完成正向和反向的变换。
实时频谱分析
有了FFT,实时显示音频的频谱图(就像音乐播放器里的那样)变得轻而易举。系统可以不断地采集一小段音频数据(例如1024个采样点),迅速对其进行FFT,然后将计算出的频谱幅度绘制出来。这个过程可以每秒进行几十次,从而形成流畅的动态频谱动画。
OFDM通信
在现代无线通信中,比如4G LTE、5G和Wi-Fi,都使用了一种叫做正交频分复用(OFDM) 的技术。OFDM的核心思想就是将高速的数据流,分成很多路低速的子数据流,然后用这些子数据流分别去调制大量的、相互正交的子载波(不同频率的正弦波)来进行传输。
在发射端,将数据调制到各个子载波上的过程,在数学上等价于一次IDFT。而在接收端,将各个子载波上的数据解调分离出来的过程,则等价于一次DFT。在实际的通信芯片中,这些复杂的调制解调过程,都是通过高效的IFFT和FFT硬件电路来实现的。没有FFT,现代高速无线通信将无从谈起。
总结:站在巨人的肩膀上
今天,我们深入探索了FFT这个伟大的算法。我们不仅理解了它的原理,更感受到了它所带来的革命性影响。
- FFT不是新变换,而是快算法。它和DFT计算的是完全相同的东西,但效率天差地别。
- 核心思想是“分而治之”。通过将大问题递归地分解为小问题,FFT将计算复杂度从 O ( N 2 ) O(N^2) O(N2) 降低到了 O ( N log N ) O(N \log N) O(NlogN)。
- 蝶形运算是基本单元。FFT的运算流图由许多级蝶形运算构成,通过巧妙的结构实现了高效的原位运算。
- DIT和DIF是两种经典实现。它们在输入输出的顺序上有所不同(正常序 vs. 位反转序),但核心思想和效率一致。
- FFT是现代DSP的基石。从快速卷积到频谱分析,再到无线通信,FFT作为“加速引擎”,驱动着无数技术的进步。
理解FFT,不仅仅是学习一个算法,更是领略一种优雅而强大的工程思维方式。它告诉我们,面对看似无法解决的复杂问题时,换一个角度,运用“分而治之”的智慧,往往能找到通往奇迹的道路。
习题
第1题 (概念题)
FFT算法相比于直接计算DFT,其计算结果是否存在误差?为什么?
第2题 (计算量对比)
某系统需要处理长度为2048点的信号。如果使用直接法计算DFT,大约需要 2048 2 ≈ 4.2 × 10 6 2048^2 \approx 4.2 \times 10^6 20482≈4.2×106 次复数乘法。如果使用FFT算法,大约需要多少次复数乘法?计算量的提升大约是多少倍?
第3题 (位反转序)
在一个16点的DIT-FFT算法中,输入序列需要按位反转序排列。请问,原始序列中下标为13的元素 x ( 13 ) x(13) x(13),应该被放在输入序列的哪个位置?
答案
第1题答案:
在理想的、无限精度计算下,FFT算法与直接计算DFT的结果完全相同,不存在任何误差。
原因: FFT不是DFT的近似算法,它仅仅是利用了旋转因子 W N W_N WN 的对称性和周期性,对DFT的求和公式进行了重新组合和分解,从而减少了冗余计算。整个推导过程是严格的数学等价变换,没有引入任何近似。在实际的有限精度计算机上,两者都存在舍入误差,但它们的误差来源和级别是相似的,并不能说FFT比直接计算的误差更大或更小。
第2题答案:
FFT算法的复数乘法次数公式为 ( N / 2 ) log 2 N (N/2)\log_2 N (N/2)log2N。
对于N=2048,我们有 2048 = 2 11 2048 = 2^{11} 2048=211,所以 log 2 ( 2048 ) = 11 \log_2(2048) = 11 log2(2048)=11。
-
FFT复数乘法次数 = ( 2048 / 2 ) × 11 = 1024 × 11 = 11 , 264 (2048/2) \times 11 = 1024 \times 11 = \mathbf{11,264} (2048/2)×11=1024×11=11,264 次。
-
计算量提升倍数 = 直接计算次数 / FFT计算次数
≈ ( 4.2 × 10 6 ) / 11264 ≈ 373 \approx (4.2 \times 10^6) / 11264 \approx \mathbf{373} ≈(4.2×106)/11264≈373 倍。
FFT算法将计算量减少了约373倍!
第3题答案:
-
将原始下标写成二进制:
N = 16 N=16 N=16,所以需要用4位二进制表示。
下标13的二进制表示为 1101 2 1101_2 11012。 -
将二进制位反转:
将 1101 2 1101_2 11012 的位进行前后颠倒,得到 1011 2 1011_2 10112。 -
将反转后的二进制转换为十进制:
1011 2 = 1 ⋅ 2 3 + 0 ⋅ 2 2 + 1 ⋅ 2 1 + 1 ⋅ 2 0 = 8 + 0 + 2 + 1 = 11 1011_2 = 1 \cdot 2^3 + 0 \cdot 2^2 + 1 \cdot 2^1 + 1 \cdot 2^0 = 8 + 0 + 2 + 1 = 11 10112=1⋅23+0⋅22+1⋅21+1⋅20=8+0+2+1=11。
所以,原始序列中下标为13的元素 x ( 13 ) x(13) x(13),应该被放在位反转输入序列的第11个位置(即新序列的下标为11)。