【完整源码+数据集+部署教程】高速公路施工区域物体检测系统源码和数据集:改进yolo11-RepNCSPELAN
背景意义
随着城市化进程的加快,高速公路建设与维护工作日益频繁,施工区域的安全管理成为亟待解决的重要问题。在高速公路施工区域,工人和设备的安全是首要考虑因素,而有效的物体检测系统能够显著提高施工现场的安全性与工作效率。传统的人工监控方式不仅耗时耗力,而且容易出现疏漏,因此,基于计算机视觉的自动化检测系统逐渐成为研究的热点。
本研究旨在开发一种基于改进YOLOv11的高速公路施工区域物体检测系统。YOLO(You Only Look Once)系列模型因其高效的实时检测能力而广泛应用于各种视觉任务。通过对YOLOv11进行改进,结合针对特定施工区域的特征,我们期望提升其在复杂环境下的检测精度和速度。该系统将能够自动识别施工区域内的关键物体,如桶、引导器、锥形标志、护栏等,这些物体的准确检测对于保障施工安全至关重要。
本研究所使用的数据集包含1200张经过标注的图像,涵盖了六类重要的施工标志物。这些标志物在施工现场的分布和外观特征各异,给物体检测带来了挑战。通过利用先进的深度学习技术,我们希望实现对这些物体的高效识别与分类,从而为施工现场的智能监控提供技术支持。
综上所述,基于改进YOLOv11的高速公路施工区域物体检测系统不仅能够提升施工安全性,还能为未来的智能交通管理系统奠定基础。随着技术的不断进步,预计该系统将在实际应用中发挥重要作用,推动施工管理的智能化与自动化进程。
图片效果
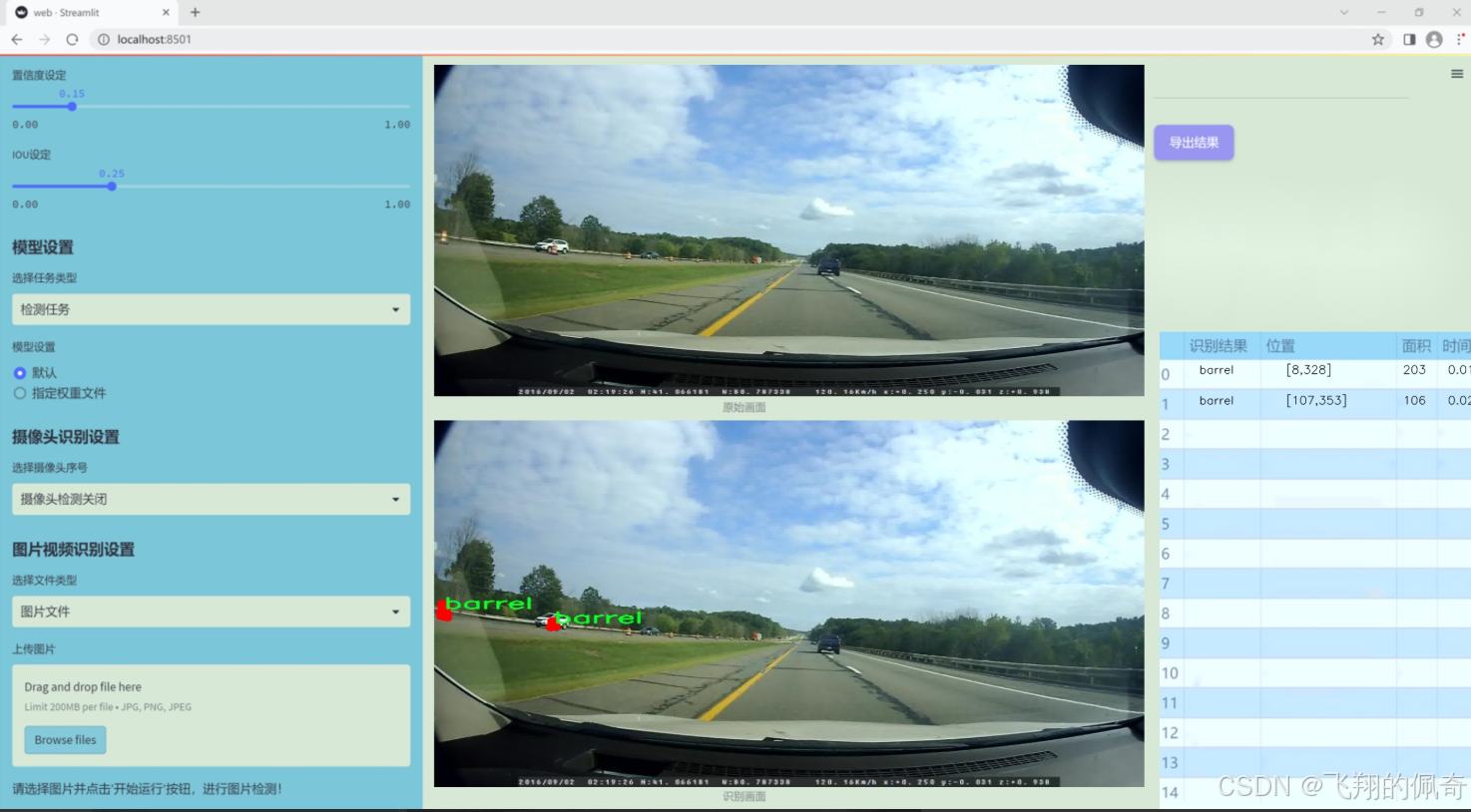
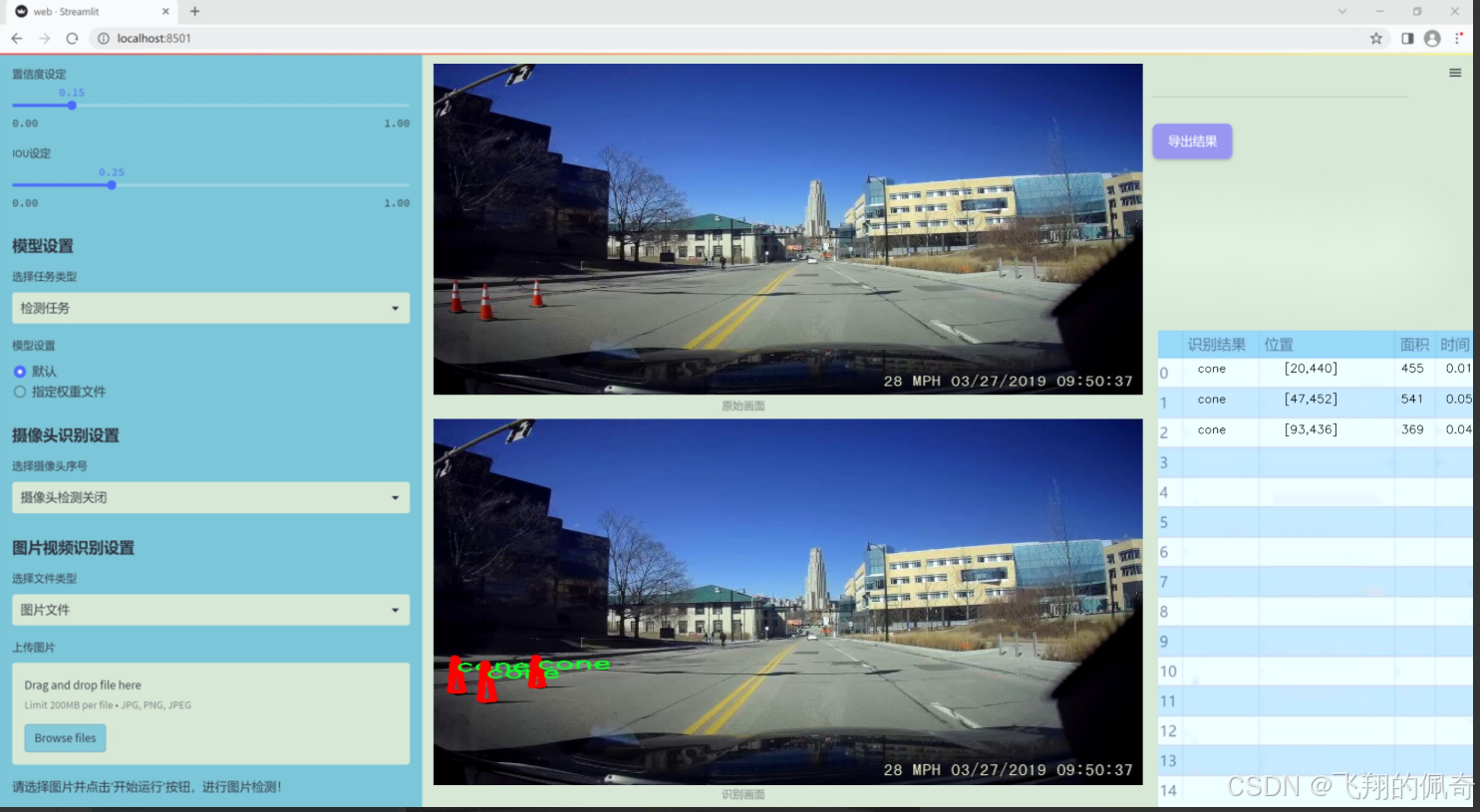
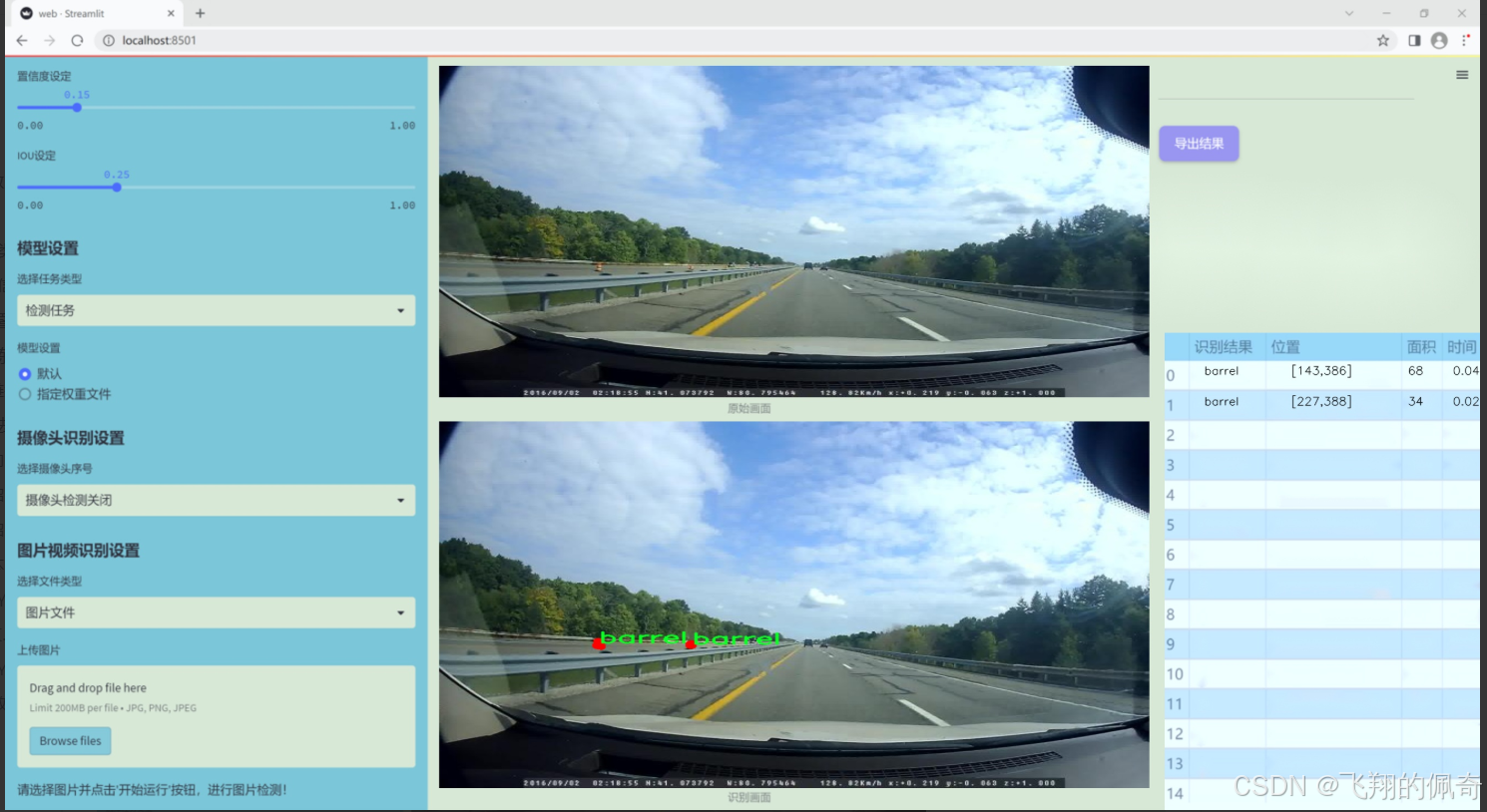
数据集信息
本项目所使用的数据集专注于高速公路施工区域的物体检测,旨在改进YOLOv11模型的性能,以实现更高效的施工安全监测。数据集的主题为“ConstructionZoneObjects”,涵盖了在施工区域内常见的六种物体类别,具体包括:桶(barrel)、引导器(channelizer)、锥形标志(cone)、护栏(guardrail)、多重引导器(many_channelizers)以及多重锥形标志(many_cones)。这些类别的选择不仅反映了高速公路施工环境的复杂性,也突显了在施工期间对交通安全的关注。
数据集中每一类物体都经过精心标注,确保在训练过程中模型能够准确识别和分类。这些物体在施工区域内的分布和外观各异,桶和锥形标志通常用于引导交通,而护栏则用于保护施工区域,防止车辆误入。多重引导器和多重锥形标志的存在则表明施工区域的规模和复杂性,增加了检测任务的挑战性。
通过对这些物体的有效识别,改进后的YOLOv11模型将能够实时监测施工区域的安全状况,及时发现潜在的安全隐患,从而提高高速公路施工的安全性和效率。此外,数据集的多样性和丰富性为模型的训练提供了坚实的基础,使其具备在不同环境和条件下的适应能力。这一数据集不仅为本项目的成功实施奠定了基础,也为未来相关研究提供了宝贵的资源,推动了高速公路施工安全监测技术的发展。





核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
class MF_Attention(nn.Module):
“”"
自注意力机制实现,来源于Transformer。
“”"
def init(self, dim, head_dim=32, num_heads=None, qkv_bias=False,
attn_drop=0., proj_drop=0., proj_bias=False):
super().init()
# 头的维度self.head_dim = head_dim# 缩放因子self.scale = head_dim ** -0.5# 计算头的数量self.num_heads = num_heads if num_heads else dim // head_dimif self.num_heads == 0:self.num_heads = 1# 注意力的维度self.attention_dim = self.num_heads * self.head_dim# Q、K、V的线性变换self.qkv = nn.Linear(dim, self.attention_dim * 3, bias=qkv_bias)# 注意力的dropoutself.attn_drop = nn.Dropout(attn_drop)# 投影层self.proj = nn.Linear(self.attention_dim, dim, bias=proj_bias)# 投影后的dropoutself.proj_drop = nn.Dropout(proj_drop)def forward(self, x):# 获取输入的形状B, H, W, C = x.shapeN = H * W # 计算总的token数量# 计算Q、K、Vqkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)q, k, v = qkv.unbind(0) # 将Q、K、V分开# 计算注意力分数attn = (q @ k.transpose(-2, -1)) * self.scaleattn = attn.softmax(dim=-1) # 归一化attn = self.attn_drop(attn) # 应用dropout# 计算输出x = (attn @ v).transpose(1, 2).reshape(B, H, W, self.attention_dim)x = self.proj(x) # 投影x = self.proj_drop(x) # 应用dropoutreturn x # 返回输出
class MetaFormerBlock(nn.Module):
“”"
MetaFormer模块的实现。
“”"
def init(self, dim,
token_mixer=nn.Identity, mlp=Mlp,
norm_layer=partial(LayerNormWithoutBias, eps=1e-6),
drop=0., drop_path=0.,
layer_scale_init_value=None, res_scale_init_value=None):
super().init()
# 第一层归一化self.norm1 = norm_layer(dim)# 令牌混合器self.token_mixer = token_mixer(dim=dim, drop=drop)# 路径dropoutself.drop_path1 = DropPath(drop_path) if drop_path > 0. else nn.Identity()# 层缩放self.layer_scale1 = Scale(dim=dim, init_value=layer_scale_init_value) if layer_scale_init_value else nn.Identity()self.res_scale1 = Scale(dim=dim, init_value=res_scale_init_value) if res_scale_init_value else nn.Identity()# 第二层归一化self.norm2 = norm_layer(dim)# MLP模块self.mlp = mlp(dim=dim, drop=drop)# 路径dropoutself.drop_path2 = DropPath(drop_path) if drop_path > 0. else nn.Identity()# 层缩放self.layer_scale2 = Scale(dim=dim, init_value=layer_scale_init_value) if layer_scale_init_value else nn.Identity()self.res_scale2 = Scale(dim=dim, init_value=res_scale_init_value) if res_scale_init_value else nn.Identity()def forward(self, x):# 交换维度以适应后续操作x = x.permute(0, 2, 3, 1)# 第一部分前向传播x = self.res_scale1(x) + \self.layer_scale1(self.drop_path1(self.token_mixer(self.norm1(x))))# 第二部分前向传播x = self.res_scale2(x) + \self.layer_scale2(self.drop_path2(self.mlp(self.norm2(x))))return x.permute(0, 3, 1, 2) # 恢复原始维度
代码核心部分说明:
MF_Attention: 实现了自注意力机制,计算输入的Q、K、V并通过softmax归一化得到注意力权重,最后输出经过投影的结果。
MetaFormerBlock: 组合了归一化、令牌混合、MLP等模块,形成一个完整的MetaFormer块,支持残差连接和层缩放。
这个程序文件 metaformer.py 实现了一种名为 MetaFormer 的深度学习模型的各个组件,主要用于图像处理和特征提取。文件中定义了多个类,每个类实现了特定的功能,以下是对这些类及其功能的详细说明。
首先,Scale 类用于对输入张量进行元素级别的缩放。它通过一个可训练的参数 scale 来实现缩放,允许模型在训练过程中自适应调整缩放因子。
接下来,SquaredReLU 和 StarReLU 类实现了两种不同的激活函数。SquaredReLU 是一种将 ReLU 激活函数的输出平方的变体,而 StarReLU 则在 ReLU 的基础上引入了可学习的缩放和偏置参数。
MF_Attention 类实现了自注意力机制,这是 Transformer 模型的核心部分。它通过线性变换生成查询、键和值,然后计算注意力权重并应用于值,最后通过线性变换将结果映射回原始维度。
RandomMixing 类用于对输入进行随机混合,生成一个随机矩阵并应用于输入特征。这种操作可以增加模型的鲁棒性。
LayerNormGeneral 类实现了一种通用的层归一化方法,允许在不同的输入形状和归一化维度下使用。它支持可选的缩放和偏置参数,并通过计算均值和方差来标准化输入。
LayerNormWithoutBias 类是对 LayerNormGeneral 的一个优化版本,去掉了偏置项,直接使用 PyTorch 的优化函数进行层归一化。
SepConv 类实现了分离卷积,这是一种有效的卷积操作,首先通过逐点卷积(1x1卷积)扩展通道数,然后通过深度卷积(3x3卷积)进行特征提取,最后再通过逐点卷积将通道数恢复到原始维度。
Pooling 类实现了一种池化操作,具体是平均池化,目的是减少特征图的尺寸并提取重要特征。
Mlp 类实现了多层感知机(MLP),包含两个线性层和激活函数,常用于特征变换和维度转换。
ConvolutionalGLU 类实现了一种卷积门控线性单元(GLU),结合了卷积操作和门控机制,增强了模型的表达能力。
MetaFormerBlock 和 MetaFormerCGLUBlock 类实现了 MetaFormer 的基本构建块。它们包含归一化层、特征混合层(可以是自注意力或其他形式的混合)、以及 MLP 结构。每个块都使用了残差连接和可选的层缩放,确保信息在网络中有效传递。
总体而言,这个文件定义了一系列用于构建 MetaFormer 模型的基本组件,结合了现代深度学习中的多种技术,如自注意力机制、层归一化、激活函数、卷积操作等。这些组件可以灵活组合,以构建出适应不同任务需求的深度学习模型。
10.4 test_selective_scan.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn.functional as F
def build_selective_scan_fn(selective_scan_cuda: object = None, mode=“mamba_ssm”, tag=None):
“”"
构建选择性扫描函数的工厂函数,返回一个自定义的选择性扫描函数。
参数:
selective_scan_cuda: 选择性扫描的CUDA实现
mode: 选择性扫描的模式
tag: 额外的标签信息
"""class SelectiveScanFn(torch.autograd.Function):@staticmethoddef forward(ctx, u, delta, A, B, C, D=None, z=None, delta_bias=None, delta_softplus=False, return_last_state=False, nrows=1, backnrows=-1):"""前向传播函数,执行选择性扫描的计算。参数:ctx: 上下文对象,用于保存信息以供反向传播使用u: 输入张量delta: 变化率张量A, B, C: 权重张量D: 可选的偏置张量z: 可选的门控张量delta_bias: 可选的变化率偏置delta_softplus: 是否使用softplus激活return_last_state: 是否返回最后的状态nrows: 行数backnrows: 反向传播时的行数返回:输出张量或输出张量和最后状态的元组"""# 确保输入张量是连续的if u.stride(-1) != 1:u = u.contiguous()if delta.stride(-1) != 1:delta = delta.contiguous()if D is not None:D = D.contiguous()if B.stride(-1) != 1:B = B.contiguous()if C.stride(-1) != 1:C = C.contiguous()if z is not None and z.stride(-1) != 1:z = z.contiguous()# 处理权重张量的维度if B.dim() == 3:B = rearrange(B, "b dstate l -> b 1 dstate l")ctx.squeeze_B = Trueif C.dim() == 3:C = rearrange(C, "b dstate l -> b 1 dstate l")ctx.squeeze_C = True# 检查输入的形状是否符合要求assert u.shape[1] % (B.shape[1] * nrows) == 0 assert nrows in [1, 2, 3, 4] # 限制行数为1到4# 选择性扫描的前向计算out, x, *rest = selective_scan_cuda.fwd(u, delta, A, B, C, D, z, delta_bias, delta_softplus)# 保存用于反向传播的张量ctx.save_for_backward(u, delta, A, B, C, D, delta_bias, x)# 获取最后状态last_state = x[:, :, -1, 1::2] # (batch, dim, dstate)return out if not return_last_state else (out, last_state)@staticmethoddef backward(ctx, dout, *args):"""反向传播函数,计算梯度。参数:ctx: 上下文对象dout: 输出的梯度返回:输入张量的梯度"""# 从上下文中恢复保存的张量u, delta, A, B, C, D, delta_bias, x = ctx.saved_tensors# 计算反向传播的梯度du, ddelta, dA, dB, dC, dD, ddelta_bias, *rest = selective_scan_cuda.bwd(u, delta, A, B, C, D, delta_bias, dout, x, None, ctx.delta_softplus, False)return (du, ddelta, dA, dB, dC, dD if D is not None else None, None, ddelta_bias if delta_bias is not None else None)def selective_scan_fn(u, delta, A, B, C, D=None, z=None, delta_bias=None, delta_softplus=False, return_last_state=False, nrows=1, backnrows=-1):"""选择性扫描函数的接口,调用自定义的选择性扫描函数。参数:u, delta, A, B, C, D, z, delta_bias, delta_softplus, return_last_state, nrows, backnrows: 同上返回:输出张量或输出张量和最后状态的元组"""return SelectiveScanFn.apply(u, delta, A, B, C, D, z, delta_bias, delta_softplus, return_last_state, nrows, backnrows)return selective_scan_fn
代码核心部分说明:
选择性扫描函数的构建:build_selective_scan_fn函数用于创建一个选择性扫描的自定义函数。它接收一个CUDA实现和模式,并返回一个自定义的selective_scan_fn函数。
前向传播:SelectiveScanFn类中的forward静态方法实现了选择性扫描的前向计算。它处理输入张量的维度,确保它们是连续的,并进行必要的形状调整。然后调用CUDA实现的前向函数,并保存用于反向传播的张量。
反向传播:backward静态方法计算输入张量的梯度。它从上下文中恢复保存的张量,并调用CUDA实现的反向函数来计算梯度。
接口函数:selective_scan_fn函数是对外的接口,用户可以通过它来调用选择性扫描的计算。
这些部分是实现选择性扫描的核心逻辑,负责前向和反向传播的计算。
这个程序文件 test_selective_scan.py 是一个用于测试选择性扫描(Selective Scan)操作的 PyTorch 实现。文件中包含了选择性扫描的前向和反向传播函数,以及相应的测试代码。以下是对文件中主要部分的详细说明。
首先,文件导入了一些必要的库,包括 torch、torch.nn.functional、pytest 和 einops 等。torch 是 PyTorch 的核心库,einops 用于简化张量的重排操作。
接下来,定义了一个函数 build_selective_scan_fn,该函数接受一个 CUDA 实现的选择性扫描函数和一些参数,返回一个自定义的选择性扫描函数。这个函数内部定义了一个名为 SelectiveScanFn 的类,继承自 torch.autograd.Function,并实现了 forward 和 backward 方法。
在 forward 方法中,首先对输入张量进行连续性检查,确保它们在内存中是连续的。然后根据输入的维度和形状进行一些处理和重排。接着,根据不同的模式(如 mamba_ssm、ssoflex 等)调用相应的 CUDA 前向函数,计算输出结果。最后,将需要在反向传播中使用的张量保存到上下文中,并返回输出结果。
backward 方法则实现了反向传播的逻辑。它从上下文中恢复保存的张量,并调用相应的 CUDA 后向函数计算梯度。最终返回各个输入的梯度。
此外,文件中还定义了 selective_scan_ref 和 selective_scan_ref_v2 函数,这两个函数实现了选择性扫描的参考实现,用于与 CUDA 实现进行比较。它们的输入参数与前面的函数相同,计算逻辑类似,但不依赖于 CUDA。
在文件的最后部分,定义了一个测试函数 test_selective_scan,使用 pytest 框架进行参数化测试。该测试函数生成不同形状和类型的输入数据,调用选择性扫描函数,并与参考实现的输出进行比较。测试中还会检查梯度的正确性。
最后,程序会根据设定的模式导入相应的 CUDA 实现,并打印出当前使用的模式。整个文件的结构清晰,功能模块化,便于后续的维护和扩展。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式