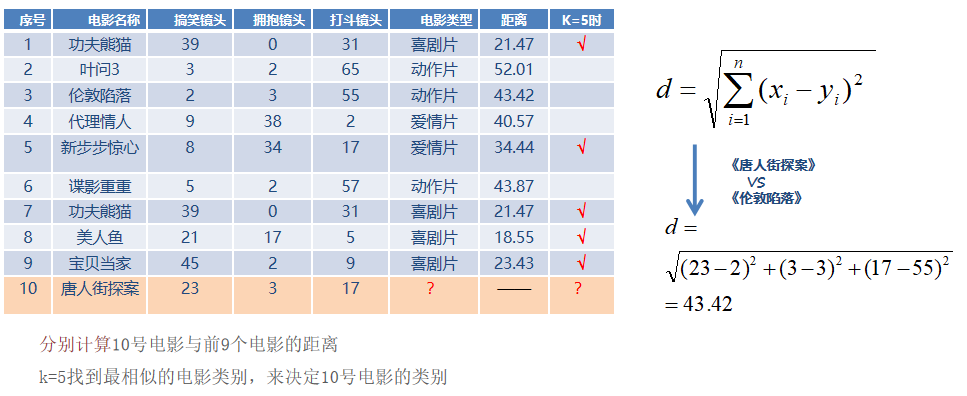
KNN算法(K近邻算法)
附 鸢尾花预测案例 与 手写数字识别案例
思想:
如果一个样本在特征空间中的 k 个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别
目录
一、K-近邻算法
k值选择
KNN分类流程
KNN回归流程
二、距离度量
欧氏距离
曼哈顿距离(城市街区距离)
切比雪夫距离
闵可夫斯基距离(闵式距离)
三、特征预处理
归一化
标准化
四、交叉验证网格搜索
案例1:鸢尾花预测
流程
完整代码
案例2:手写数字识别
流程
完整代码
一、K-近邻算法
样本相似性:样本都是属于一个任务数据集的。样本距离越近则越相似。
k值选择
- K值过小:用较小邻域中的训练实例进行预测
- 容易受到异常点的影响K值的减小就意味着整体模型变得复杂
- 容易发生过拟合
- K值过大:用较大邻域中的训练实例进行预测
- 受到样本均衡的问题且K值的增大就意味着整体的模型变得简单
- 容易发生欠拟合
- 如何对K超参数进行调优?
- 交叉验证、网格搜索
KNN分类流程
- 计算未知样本到每一个训练样本的距离
- 将训练样本根据距离大小升序排列
- 取出距离最近的 K 个训练样本
- 进行多数表决,统计 K 个样本中哪个类别的样本个数最多
- 将未知的样本归属到出现次数最多的类别
KNN回归流程
- 计算未知样本到每一个训练样本的距离
- 将训练样本根据距离大小升序排列
- 取出距离最近的 K 个训练样本
- 把这个 K 个样本的目标值计算其平均值
- 将未知的样本预测
二、距离度量
欧氏距离
两个点在空间中的距离
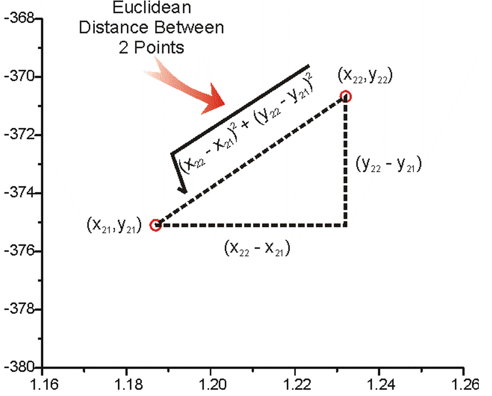
欧氏距离公式

曼哈顿距离(城市街区距离)
曼哈顿城市特点:横平竖直
曼哈顿距离公式

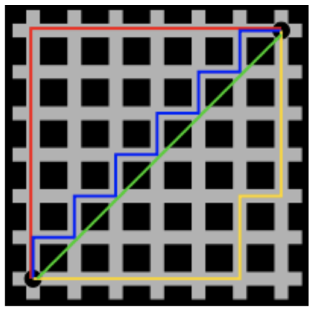
切比雪夫距离
国际象棋中,国王可以直行、横行、斜行,所以国王走一步可以移动到相邻8个方格中的任意一个。
国王从格子(x1,y1)走到格子(x2,y2)最少需要多少步?这个距离就叫切比雪夫距离。
切比雪夫距离公式

闵可夫斯基距离(闵式距离)
不是一种新的距离的度量方式。
是对多个距离度量公式的概括性的表述

三、特征预处理
归一化
原因:特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响(支配)目标结果,使得一些模型(算法)无法学习到其它的特征。

公式

- 1.sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)… )
- 2. fit_transform(X) 将特征进行归一化缩放
API

标准化
- 通过对原始数据进行标准化,转换为均值为0标准差为1的标准正态分布的数据

公式

- 1.sklearn.preprocessing. StandardScaler()
- 2. fit_transform(X) 将特征进行归一化缩放
API

四、交叉验证网格搜索
是一种数据集的分割方法,将训练集划分为 n 份,拿一份做验证集(测试集)、其他n-1份做训练集

只需要将若干参数传递给网格搜索对象,它自动帮我们完成不同超参数的组合、模型训练、模型评估,最终返回一组最优的超参数

案例1:鸢尾花预测
流程
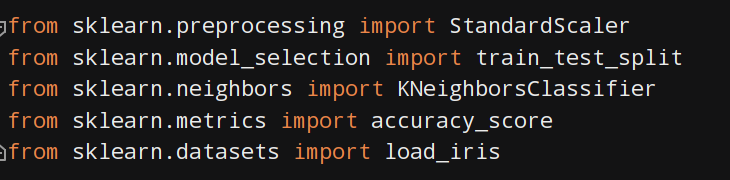
1、导包
2、加载在线数据
![]()
3、数据分割
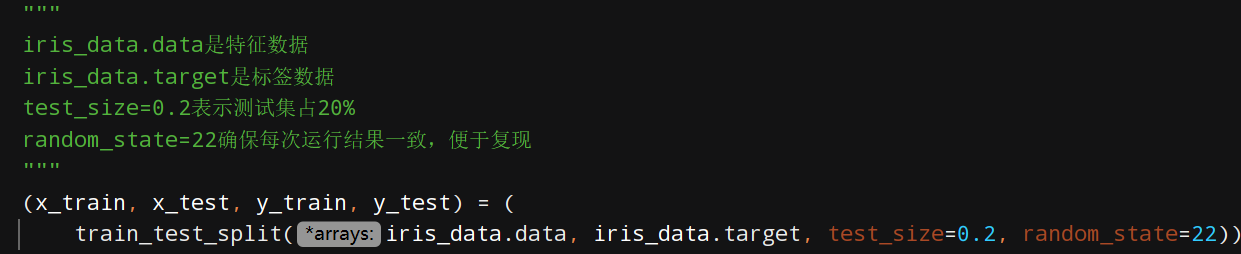
4、创建标准化对象、数据标准化

5、创建knn模型、训练模型
![]()
6、预测结果
![]()
7、输出结果
![]()
8、模型评估

9、新的预测
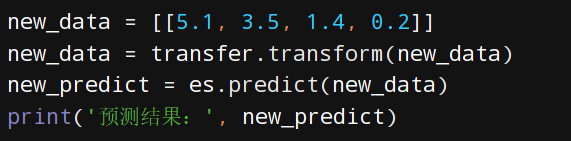
完整代码
def dm01_loasd_iris():iris_data = load_iris()"""iris_data.data是特征数据iris_data.target是标签数据test_size=0.2表示测试集占20%random_state=22确保每次运行结果一致,便于复现"""(x_train, x_test, y_train, y_test) = (train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=22))transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)es = KNeighborsClassifier(n_neighbors=5)es.fit(x_train, y_train)y_predict = es.predict(x_test)print('预测结果:', y_predict)print('真实结果:', y_test)print('准确率:', accuracy_score(y_test, y_predict))print('准确率:', es.score(x_test, y_test))new_data = [[5.1, 3.5, 1.4, 0.2]]new_data = transfer.transform(new_data)new_predict = es.predict(new_data)print('预测结果:', new_predict)if __name__ == '__main__':dm01_loasd_iris()案例2:手写数字识别
流程
1、导包

2、读取数据、选取数据

3、数据分割

4、创建knn模型、训练模型
![]()
5、预测结果、模型分析

6、模型保存本地

7、导入模块进行预测
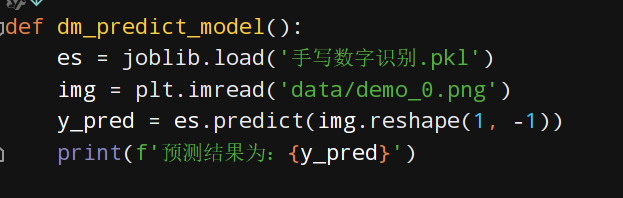
完整代码
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
import joblib # 持有化保存本地def dm_train_model():df = pd.read_csv('data/手写数字识别.csv')x = df.iloc[:, 1:]y = df.iloc[:, 0](X_train, X_test, y_train, y_test) = (train_test_split(x, y, test_size=0.2, random_state=14, stratify=y))es = KNeighborsClassifier(n_neighbors=5)es.fit(X_train, y_train)acc = accuracy_score(y_test, es.predict(X_test))print('准确率:%.2f' % acc)joblib.dump(es, '手写数字识别.pkl')print('模型保存成功')def dm_predict_model():es = joblib.load('手写数字识别.pkl')img = plt.imread('data/demo_0.png')y_pred = es.predict(img.reshape(1, -1))print(f'预测结果为:{y_pred}')if __name__ == '__main__':dm_train_model()dm_predict_model()