神经语言学视角:脑科学与NLP深层分析技术的交叉融合
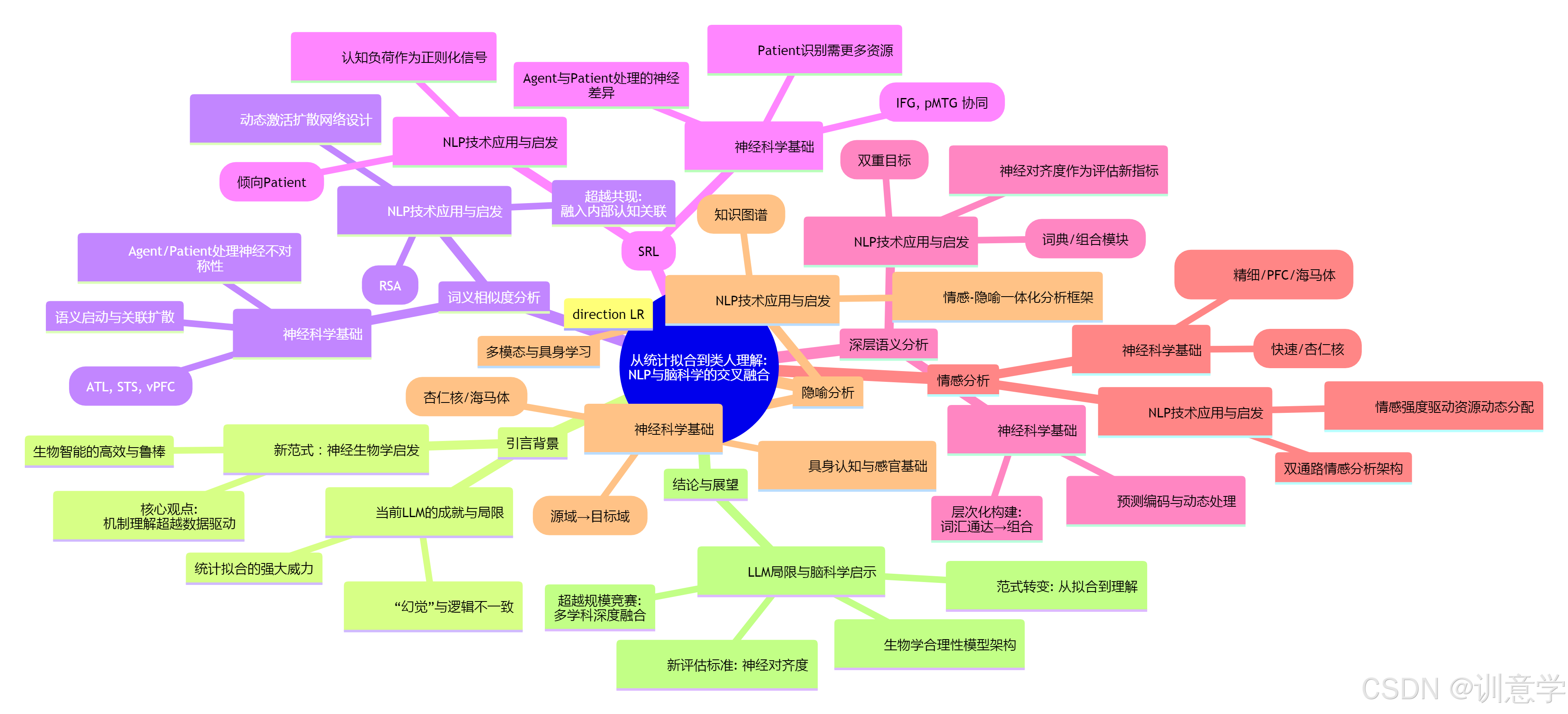
引言:从“统计拟合”到“类人理解”——NLP的下一个范式
近年来,以Transformer架构为核心的大型语言模型(LLM)在自然语言处理(NLP)领域取得了前所未有的成功 。它们能够生成流畅的文本、回答复杂的问题,甚至进行代码编写。然而,这些模型的辉煌成就背后,一个根本性的挑战日益凸显:它们在很大程度上是“知其然,而不知其所以然”的统计拟合机器。尽管能够捕捉海量数据中的复杂模式 但在面对需要真正逻辑推理、常识运用和创造性语言表达的任务时,它们往往会暴露出“幻觉”(Hallucination)和逻辑不一致等瓶颈 (Pan et al., 2025)。
正是在这一背景下,脑科学,特别是神经语言学(Neurolinguistics),为NLP的发展提供了全新的视角和强大的生物学约束。人类大脑是迄今为止已知的最高效、最鲁棒的语言处理器。它并非依赖无穷尽的数据和算力,而是通过一套精妙的、历经亿万年演化而来的神经机制来理解和生成语言。核心观点在于,通过模拟大脑处理语言的底层机制,我们有望引导NLP实现一次深刻的范式转变——从单纯依赖数据驱动的“统计拟合”,迈向基于生物学原理的“机制理解”。
正如一份前沿研究所指出的,当前大多数计算模型缺乏明确的神经生物学基础,而一个“神经生物学启发的因果建模方法”能够为弥合这一鸿沟提供框架 (Fitz et al., 2024)。这种方法旨在从神经生物学的第一性原理出发,构建能够解释语言行为生成器的模型。
本文旨在深入探索这一交叉融合的前沿领域。我们将聚焦于五个核心的NLP深层分析任务——词义相似度、语义角色标注、深层语义分析、情感分析和隐喻分析。通过逐一剖析相关的神经科学发现,我们将揭示大脑的解决方案如何为这些领域带来革命性的技术启示,并展望一个整合了认知机制与计算模型的NLP新未来。
一、 词义相似度:从向量空间到大脑的语义网络
词义相似度计算是NLP的基础任务之一,其核心在于量化词语之间意义的远近。传统NLP模型,如Word2Vec或GloVe 通过“一个词的含义由其上下文决定”的分布假说,在巨大的向量空间中为词语定位。然而,大脑的语义表征机制远比静态的向量空间更为复杂和动态。
神经科学基础:大脑中的语义表征
大脑对词义的表征并非孤立的“词典式”存储,而是一个动态、关联的分布式网络。
分布式网络:研究表明,语义知识并非存储于单一脑区,而是由一个广泛的神经网络共同支撑 。这一网络的核心节点包括前颞叶(Anterior Temporal Lobe, ATL)、颞上沟(Superior Temporal Sulcus, STS)和腹侧前额叶皮层(ventral Prefrontal Cortex, vPFC)等区域 (Jackson et al., 2015)。这些区域协同工作,构成了大脑皮层上的“语义地图” 共同支撑着我们庞大而灵活的“语义记忆”系统 。
关联与启动:“语义启动”(Semantic Priming)现象为我们揭示了大脑语义网络的运作方式。当人们看到“医生”这个词后,他们能更快地识别出“护士”,因为“医生”的神经元激活会自动扩散到与之相关的“护士”的神经元网络。这表明大脑的语义网络是基于概念关联进行组织的,而非简单的几何距离。
两种关系的处理:大脑如何区分“概念相似性”(如“狼”和“狗”,共享许多生物特征)与“主题关联性”(如“狗”和“骨头”,经常共同出现)?一项fMRI研究发现,在进行这两种判断时,被试激活了相同的核心语义网络。这表明大脑可能在一个统一的系统中表征这两种关系,其间的差异更多体现在任务难度和认知控制资源的调配上,而非依赖完全不同的神经模块 (Jackson et al., 2015; 。
NLP技术应用与启发
将大脑的语义表征机制引入NLP,为我们超越传统的词向量模型提供了明确的方向。
表征相似性分析 (RSA) :RSA是连接神经科学与NLP的关键桥梁。研究者通过记录被试在听到或看到一系列词语时的大脑活动(如fMRI或EEG信号),计算出大脑对任意两个词语反应模式的“神经相似度矩阵”。然后,将这个矩阵与NLP模型(如BERT)计算出的“向量相似度矩阵”进行比较 。研究发现,现代NLP模型与大脑的表征在一定程度上具有相似的几何结构 (Alick et al., 2021),这证实了从神经数据中验证和启发NLP模型的可行性 。
超越共现统计:更有趣的发现是,并非所有模型都与大脑同样“相似”。一项研究对比了三种模型:基于大规模文本语料库的“外部模型”(如Word2Vec)、基于人类自由联想任务数据的“内部模型”和结合两者的“混合模型”(如ConceptNet)。结果清晰地表明,“内部模型”能更好地预测大脑的神经激活模式 (Li et al., 2023)。这强烈暗示,单纯的词语共现统计不足以完全捕捉人类的语义表征,NLP模型需要更多地融入反映人类内在认知关联(如自由联想、感官经验等)的先验知识。
模型架构启示:受“语义启动”和关联网络的启发,未来的词义计算模型可以超越静态向量。例如,可以设计一个动态的“激活扩散网络”(Activation Diffusion Network),其中词语节点间的连接强度不仅由其固有相似度决定,还受当前上下文的动态调节。当一个词被激活时,激活能量会沿着网络路径扩散,暂时性地增强相关词语的“可及性”,从而更真实地模拟大脑在语境中计算语义关系的过程。
二、 语义角色标注:解码大脑中的“谁对谁做了什么”
语义角色标注(Semantic Role Labeling, SRL)旨在识别句子中的谓词-论元结构,即回答“谁(Agent)对谁(Patient)做了什么” 。这项任务是实现深层语言理解的核心。神经科学的研究揭示,大脑并非通过简单的线性流程来完成这一任务,而是依赖一个高效的、非对称的神经回路。
神经科学基础:大脑的句法与语义整合中枢
经典与现代模型:经典的语言模型将布洛卡区(Broca's Area)视为句法中心,韦尼克区(Wernicke's Area)视为语义中心。然而,现代神经成像研究表明,语言处理依赖于一个更广泛的分布式网络 。其中,额下回(Inferior Frontal Gyrus, IFG,包含布洛卡区)和后中颞回(posterior Middle Temporal Gyrus, pMTG)等区域的协同作用至关重要,它们共同负责句法构建和词汇-语义通达 (Skeide & Friederici, 2016; 。
Agent vs. Patient 的神经差异:这是神经科学为SRL带来的最深刻洞见之一。多项研究发现,大脑在处理施事者(Agent)和受事者(Patient)时,其神经资源消耗存在显著的非对称性。一项针对主题角色处理的神经表征研究指出,左半球的颞上沟(STS)区域对施事者和受事者的识别都非常敏感,但包括右后中颞叶和角回在内的其他区域也参与了这一过程,表明大脑在神经层面明确区分了这些语义角色 。进一步的研究发现,与处理Agent相比,处理Patient角色激活了更广泛、更强烈的大脑网络,这可能因为Patient角色的确定需要更复杂的句法和语义整合过程。在特定情境(如自我服务偏见)下,扮演“施事者”和“受事者”角色也会显著影响大脑活动,例如背内侧前叶(dmPFC)的激活模式 。
NLP技术应用与启发
大脑处理语义角色的非对称性为设计更高效、更具生物学合理性的SRL模型提供了全新的思路。
非对称模型架构:当前大多数基于Transformer的SRL模型 在结构上是“对称”的,即它们用相同的计算模块和参数量来处理句子中的所有成分。受大脑发现的启发,我们可以设计一种 “非对称SRL架构”。在该架构中,专门用于识别和处理Patient角色的网络路径可以被设计得比处理Agent的路径更深、更宽,或者拥有更复杂的注意力机制。这种架构将计算资源更倾向于分配给认知上更困难的任务,有望在不显著增加总计算成本的前提下,提高模型对复杂句式中受事者识别的准确性和鲁棒性。
认知负荷作为正则化信号:大脑在处理Patient时更高的激活水平可以被看作一种“认知负荷”信号。在模型训练中,我们可以将这一生物学先验知识转化为一个正则化项。例如,当模型错误地将一个Patient识别为Agent时,可以施加一个更大的惩罚,因为这种错误在认知上是“更不应该发生”的。这种方法将大脑的加工偏好直接注入到模型的学习过程中,引导模型学习到与人类更一致的语义角色识别策略。
三、 深层语义分析:从词袋到意义的组合与推理
深层语义分析超越了单个词语和简单的谓词-论元结构,旨在理解整个句子乃至段落的完整意义,包括其逻辑关系、言外之意和因果结构。这要求模型不仅能“看懂”词,更能“理解”它们如何组合成复杂的思想。
神经科学基础:大脑的意义构建层次
大脑通过一个层次化的、动态的网络来构建意义。
词汇通达与组合:当听到或读到一个句子时,大脑首先在颞叶的语义中枢(如ATL和STS)提取单个词汇的意义 。紧接着,以左侧额下回(IFG)为核心的区域开始工作,它像一个“句法工作台”,负责将这些词汇按照语法规则组合起来,构建句子的基本骨架 。
网络动态与预测编码:这个过程不是单向的。大脑无时无刻不在进行“预测编码”(Predictive Coding)。基于已经处理的信息,高级脑区(如前额叶)会不断预测接下来可能出现的词语或语法结构。当实际输入与预测相符时,神经活动较弱;当出现意外(如一个不合语法的词)时,则会引发强烈的神经信号(如P600事件相关电位)。这表明,语言理解是一个主动的、基于预测和纠错的动态过程,而非被动的信号接收 。
NLP技术应用与启发
模块化的类脑架构:当前的Transformer模型 虽然强大,但其内部结构是同质化的,所有层和注意力头都在执行类似的计算。一个更具生物学 plausible 的模型架构应该是模块化的。例如,可以设计包含专门处理词汇级语义的“词典模块”(模拟ATL/STS功能)和专门处理句法组合与长距离依赖的“组合模块”(模拟IFG功能)的深度模型。这种分工明确的架构可能更易于解释和调试 。
引入预测编码机制:虽然大型语言模型在本质上是预测下一个词的机器 ,但它们的训练目标函数(如交叉熵损失)并未完全模拟大脑的预测编码机制。未来的模型可以设计一个双重目标:不仅要预测下一个词,还要预测整个句子表示的“意外程度”或“信息增益”。在模型内部建立一个显式的“预测生成器”和一个“误差检测器”,让模型在学习语言模式的同时,也学习评估自身的预测不确定性,这可能有助于缓解“幻觉”问题。
以大脑对齐度为评估指标:如何评估模型是否真正实现了“深层”理解?除了传统的GLUE、SQuAD等基准测试 我们可以引入全新的 “神经对齐度” 作为核心评估指标。通过比较模型内部激活状态与同步记录的人脑fMRI或EEG信号,我们可以量化模型的表征与大脑的表征在多大程度上一致 。一个在神经对齐度上得分高的模型,更有可能在模拟人类的深层语义处理过程,而不仅仅是拟合表面统计。
四、 情感分析:超越词典的复杂情感解码
情感分析旨在识别文本中蕴含的情感色彩(正面、负面、中性)或更具体的情绪(喜、怒、哀、惧等)。然而,人类情感表达常常是间接、含蓄甚至是反讽的,这给纯粹基于数据的NLP模型带来了巨大挑战 。
神经科学基础:情感处理的双通路模型
神经科学研究表明,大脑通过两条既独立又相互作用的通路来处理情感信息。
“低通路”(The Low Road) :这是一条快速、自动、潜意识的情感处理通路。当遇到具有强烈情感色彩的刺激(如一个辱骂性词汇)时,信息会绕过皮层,从丘脑直接投射到杏仁核(Amygdala)。杏仁核作为大脑的“情感警报器”,会迅速触发自主神经系统的反应(如心跳加速) 。这个通路保证了我们对潜在危险或重要机会的快速响应。
“高通路”(The High Road) :这是一条缓慢、精细、有意识的认知评估通路。信息从丘脑传递到感觉皮层,再到前额叶皮层(Prefrontal Cortex, PFC)进行深入分析。PFC会结合上下文、记忆和目标来评估情感刺激的真实含义。例如,它能帮助我们判断一句“你可真行”究竟是赞扬还是讽刺。海马体(Hippocampus)在此过程中也扮演关键角色,它负责提供与当前情境相关的记忆,帮助PFC进行决策 。
NLP技术应用与启发
大脑的情感双通路模型为设计更鲁棒、更智能的情感分析系统提供了完美的蓝图。
双通路情感分析架构:我们可以构建一个包含两个并行模块的NLP系统。
- 快速情感检测模块:该模块模拟大脑的“低通路”。它可以是一个基于高效情感词典或小型神经网络的模型 负责快速识别文本中明确、强烈的情感信号。此模块的优点是速度快、计算成本低。
- 深度情境推理模块:该模块模拟大脑的“高通路”。它可以是一个大型Transformer模型 甚至是一个与知识图谱相结合的混合模型。当快速模块检测到情感模糊、存在反讽线索或上下文冲突时,该模块被激活,进行深度的语义和语用分析。例如,通过分析对话历史(模拟海马体的记忆功能)和常识知识,来判断一个看似负面的表达在特定语境下是否为幽默。
情感强度与认知资源的动态分配:杏仁核的激活强度与情感刺激的显著性正相关。类似地,NLP系统可以根据快速模块输出的情感“置信度”或“强度”,来动态决定是否需要调用昂贵的深度推理模块。这种机制模仿了大脑的注意力资源分配策略,能够在保证准确性的同时,极大地优化整个系统的计算效率。
五、 隐喻分析:理解语言的创造性飞跃
隐喻是语言创造性的核心,它通过“将一件事物理解为另一件事物”来扩展我们的认知边界(如“时间就是金钱”)。对于计算机而言,隐喻是语义理解的“硬骨头”,因为它打破了词语的字面意义 。
神经科学基础:从概念映射到具身认知
概念映射理论(Conceptual Metaphor Theory) :神经语言学研究有力地支持了Lakoff和Johnson提出的概念映射理论 。大脑在理解隐喻时,并非简单地进行词语替换,而是在两个概念域(源域和目标域)之间建立起系统性的神经映射。例如,在理解“激烈的辩论”时,大脑会激活与“战争”概念相关的神经回路,并将“攻击”、“防守”等概念属性映射到“辩论”中。
情感与记忆的深度参与:fMRI研究惊人地发现,处理隐喻性语言比处理字面语言更能激活杏仁核和海马体 。这表明,隐喻不仅是一种认知工具,更是一种强大的情感工具。杏仁核的激活赋予了隐喻更强的情感冲击力,而海马体的参与则表明隐喻的理解深度依赖于我们过去的经验和记忆。
具身认知与感官基础:许多研究指出,我们对抽象概念的理解,根植于我们的身体和感官经验(Sensorimotor Knowledge) 。例如,我们之所以能理解“温暖的欢迎”,是因为我们的大脑将抽象的“欢迎”概念与具体的“温暖”这一物理感觉的神经表征联系了起来。隐喻理解并非纯粹的符号操作,而是深深地“接地”(grounded)于我们的物理世界互动中。
NLP技术应用与启发
大脑处理隐喻的机制为我们攻克这一NLP难题指明了三个关键方向。
构建显式的概念映射模型:与其让模型在海量文本中隐式地学习隐喻,不如设计能够显式学习概念域之间映射关系的架构。例如,可以利用知识图谱定义源域和目标域的结构,然后训练一个神经网络来学习如何将源域的向量表示“转换”或“投射”到目标域的向量空间中。这种方法将隐喻理解从一个无监督的模式匹配问题,转变为一个有结构、有监督的转换学习任务。
拥抱多模态与具身学习:神经科学的“具身认知”观点强烈暗示,纯文本训练可能永远无法让模型真正“理解”隐喻。未来的NLP模型必须走向多模态学习。通过同时处理文本、图像、声音甚至模拟环境中的交互数据,模型可以将抽象的语言符号(如“沉重”)与具身的感官体验(如视觉上重物的图像、物理引擎中举起重物的力反馈)联系起来。这种“接地”的表征是理解“沉重的心情”这类隐喻的根基。
情感-隐喻一体化分析:大脑中情感和隐喻处理的神经回路高度重叠,这启发我们应该在NLP中将情感分析与隐喻分析作为一个统一的任务来处理,而非两个独立的任务。可以设计一个多任务学习框架,让模型在识别隐喻的同时,也预测其引发的情感极性和强度。这两个任务可以相互提供宝贵的线索,从而提高彼此的性能,更贴近人类一体化的语言理解过程 。
结论
大型语言模型的发展让我们看到了统计学习的强大威力,但其固有的“黑箱”特性和对海量数据的依赖也暴露了其局限性。本文通过对词义相似度、语义角色标注、深层语义分析、情感分析和隐喻分析这五大NLP任务的深入剖析,揭示了神经语言学如何为我们打开通往“类人理解”的大门。
从大脑分布式、关联性的语义网络,到处理语义角色的非对称神经回路;从构建意义的层次化预测编码机制,到解码情感的双通路模型;再到理解隐喻时对概念映射和具身认知的依赖——这些来自生物智能的深刻洞见,为我们提供了超越当前技术范式、构建下一代NLP模型的具体蓝图。
未来的NLP研究,不应仅仅是模型规模和数据量的竞赛,更应是一场认知科学、神经科学与计算科学的深度融合。通过构建具有生物学合理性的模型架构、引入认知过程作为训练目标、并以神经对齐度作为新的评估标准,我们有望创造出不仅能“拟合”语言,更能“理解”语言的真正人工智能。这场从“统计拟合”到“机制理解”的范式转变,已经拉开序幕。