Fast-dLLM:为扩散大模型按下加速键
想要掌握如何将大模型的力量发挥到极致吗?叶梓老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具。
1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其最大潜力。
CSDN教学平台录播地址:https://edu.csdn.net/course/detail/39987
视频号(直播分享):sphuYAMr0pGTk27 抖音号:44185842659
基于扩散的大型语言模型(Diffusion LLMs)因其独特的非自回归文本生成方式而备受关注。然而,这些模型在实际应用中面临着一个棘手的问题:推理速度远远落后于传统的自回归模型。这主要是因为它们无法像自回归模型那样利用关键的键值(KV)缓存来加速推理,同时在同时解码多个标记时,生成质量也会显著下降。为了解决这一难题,研究人员们提出了 Fast-dLLM,这是一种无需训练即可加速扩散大模型的方法。
https://arxiv.org/abs/2505.22618
https://github.com/NVlabs/Fast-dLLM
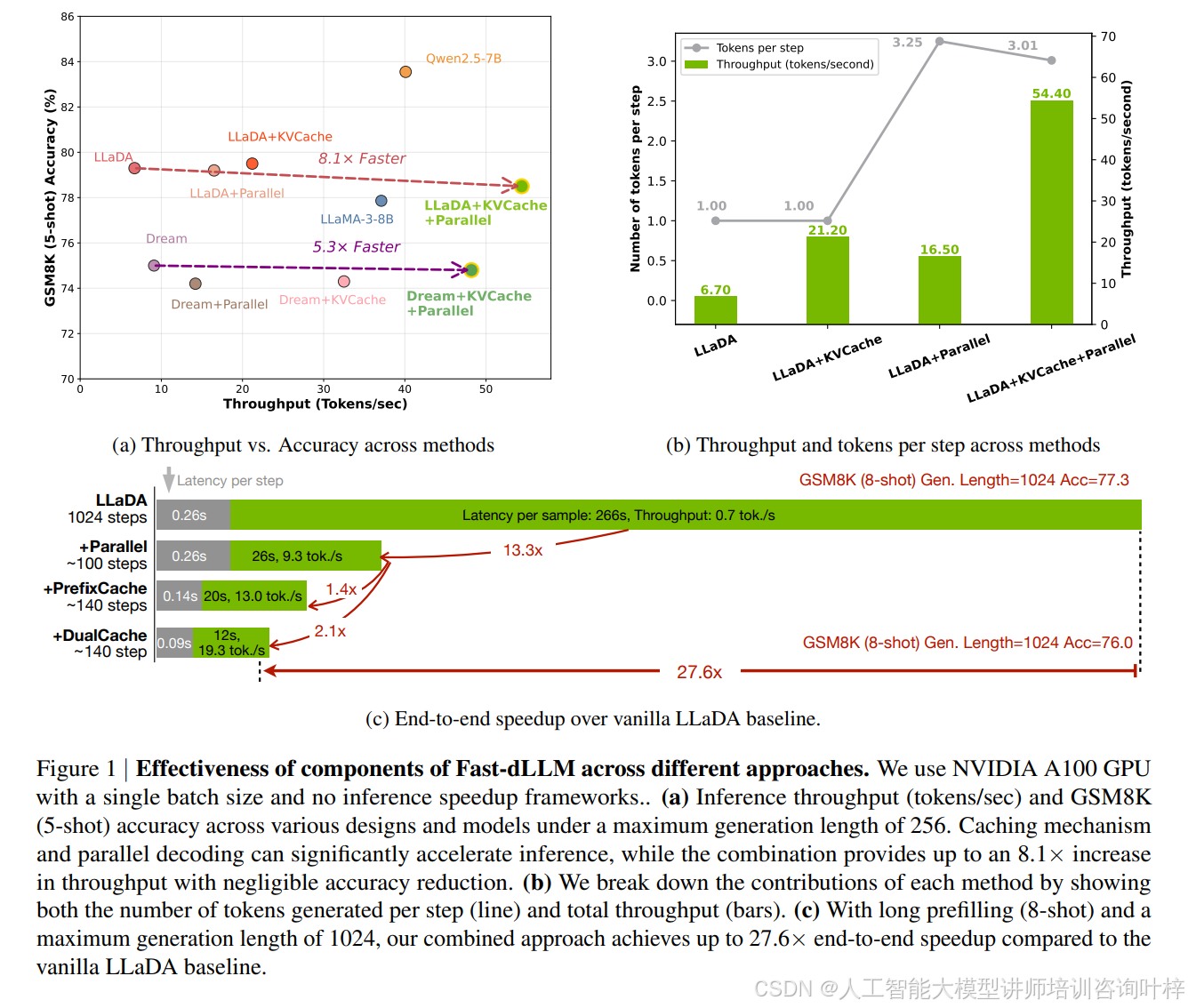
KV 缓存机制 是 Fast-dLLM 的核心创新之一。在自回归模型中,KV 缓存是一种常见的优化手段,它通过存储和重用之前计算的注意力状态来加快推理速度。然而,由于扩散大模型的双向注意力机制,直接应用 KV 缓存并非易事。Fast-dLLM 通过引入一种新颖的块状近似 KV 缓存机制,巧妙地解决了这一问题。
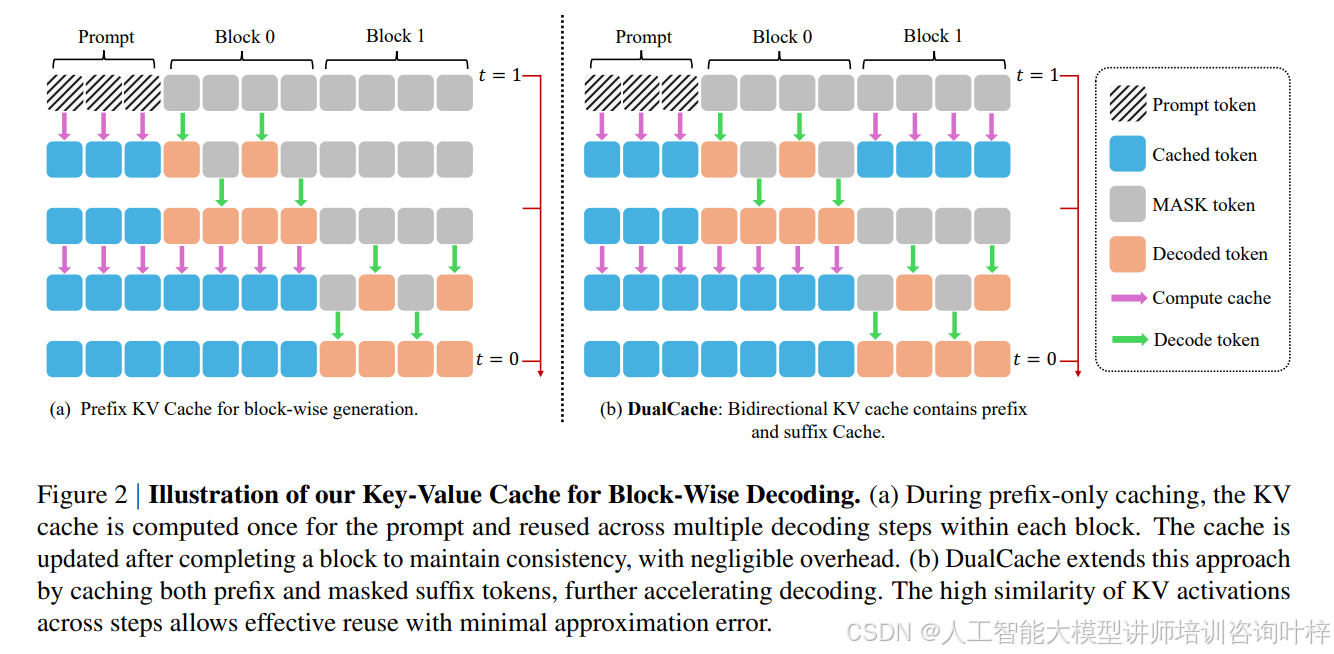
图 2 展示了 Fast-dLLM 的 KV 缓存机制。在块状解码过程中,KV 缓存被计算一次并用于整个块的解码步骤,从而减少了重复计算。这种机制利用了扩散大模型中相邻推理步骤之间 KV 激活的高相似性,使得缓存重用成为可能,且对模型性能的影响微乎其微。
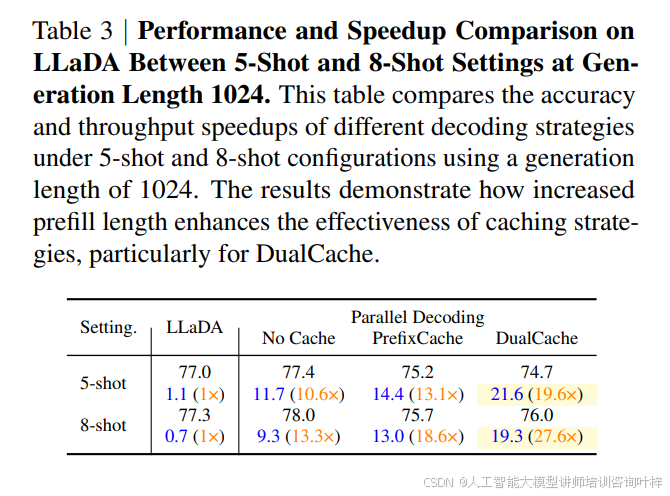
进一步地,Fast-dLLM 提出了 DualCache 版本,它不仅缓存前缀标记的键和值,还缓存了完全由掩码标记组成的后缀标记的键和值。表 3 显示了在不同设置下,DualCache 版本相比于普通 KV 缓存的性能提升。例如,在 8-shot 设置下,生成长度为 1024 时,DualCache 实现了高达 27.6 倍的加速,而普通 KV 缓存的加速比为 18.6 倍。这表明 DualCache 在利用并行性和缓存局部性方面具有显著优势。
并行解码策略 是 Fast-dLLM 的另一大亮点。在传统的扩散大模型中,同时解码多个标记会导致生成质量下降,这是因为模型在解码时假设了标记之间的条件独立性,而实际上标记之间存在着复杂的依赖关系。Fast-dLLM 通过理论分析和实证研究,发现了这一问题的根源,并提出了基于置信度的并行解码策略。
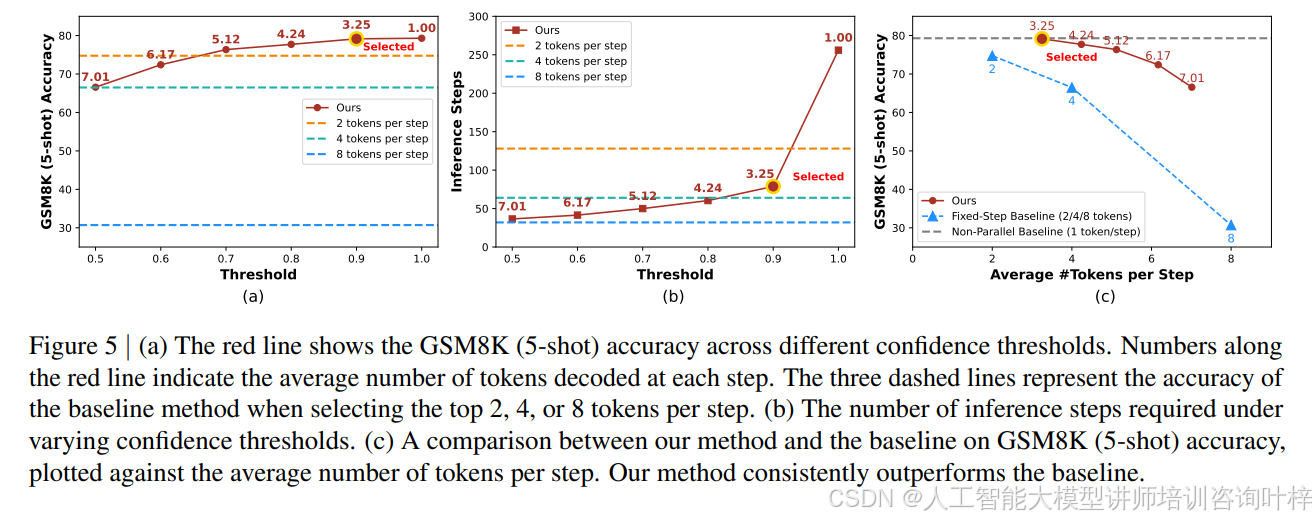 图 5 展示了置信度感知并行解码策略的效果。与传统的固定每步解码标记数量的方法相比,Fast-dLLM 的动态策略可以根据每个标记的置信度动态选择解码的标记。这种方法不仅能够显著提高推理速度,还能在保持输出质量的同时,有效减少因违反标记依赖而产生的错误。例如,在 GSM8K 数据集上,置信度感知策略在平均每步解码 3.25 个标记的情况下,准确度达到了 78.5%,而固定每步解码 2 个标记的策略准确度仅为 75.1%。
图 5 展示了置信度感知并行解码策略的效果。与传统的固定每步解码标记数量的方法相比,Fast-dLLM 的动态策略可以根据每个标记的置信度动态选择解码的标记。这种方法不仅能够显著提高推理速度,还能在保持输出质量的同时,有效减少因违反标记依赖而产生的错误。例如,在 GSM8K 数据集上,置信度感知策略在平均每步解码 3.25 个标记的情况下,准确度达到了 78.5%,而固定每步解码 2 个标记的策略准确度仅为 75.1%。
 算法 1 提供了 Fast-dLLM 的整体流程。该算法结合了块状 KV 缓存和置信度感知并行解码策略,通过在每个块内重复使用缓存的 KV 激活,并根据置信度动态选择解码的标记,实现了高效的推理过程。具体来说,算法首先初始化 KV 缓存,然后在每个块内进行解码,每步根据置信度选择标记进行解码,并在块解码完成后更新缓存。
算法 1 提供了 Fast-dLLM 的整体流程。该算法结合了块状 KV 缓存和置信度感知并行解码策略,通过在每个块内重复使用缓存的 KV 激活,并根据置信度动态选择解码的标记,实现了高效的推理过程。具体来说,算法首先初始化 KV 缓存,然后在每个块内进行解码,每步根据置信度选择标记进行解码,并在块解码完成后更新缓存。
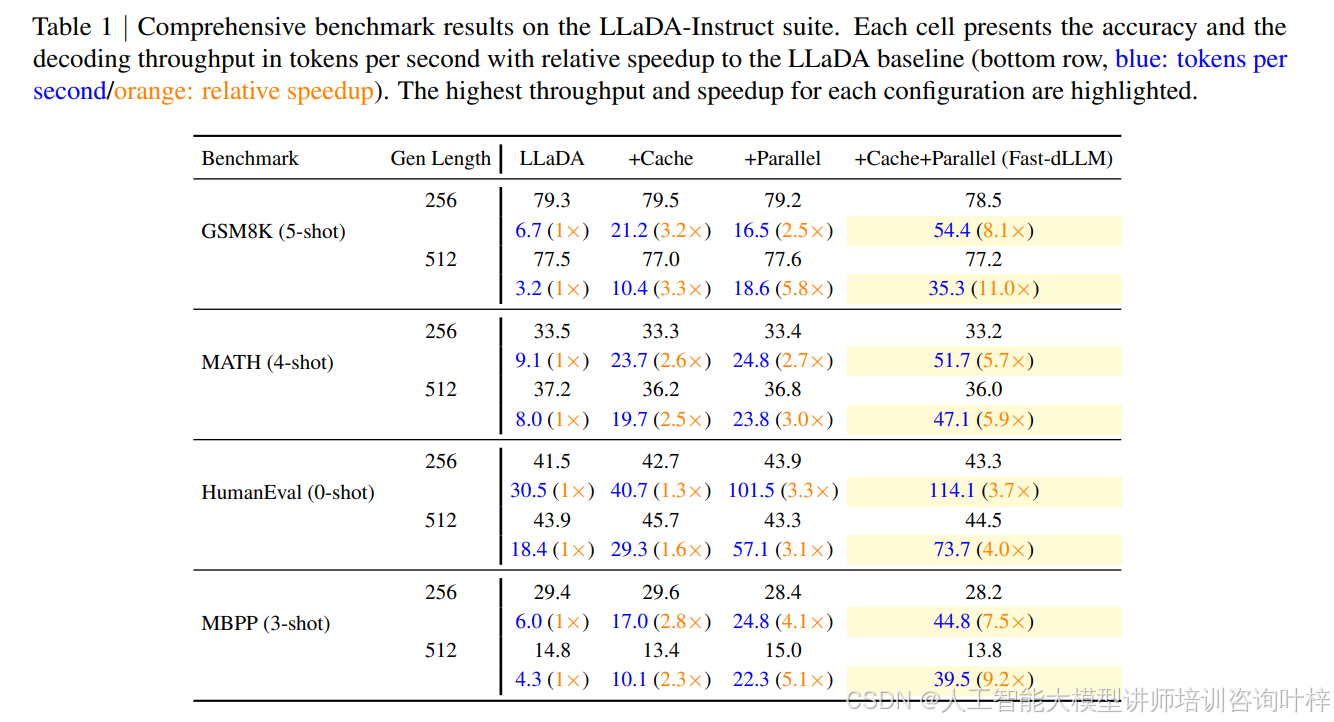
Fast-dLLM 的这些创新成果在多个开源的扩散大模型(如 LLaDA 和 Dream)以及四个主流基准测试(GSM8K、MATH、HumanEval、MBPP)上得到了验证。实验结果显示,Fast-dLLM 在保持极小准确度损失的情况下,能够实现高达 27.6 倍的吞吐量提升,极大地缩小了与自回归模型之间的性能差距,为扩散大模型的实际部署铺平了道路。
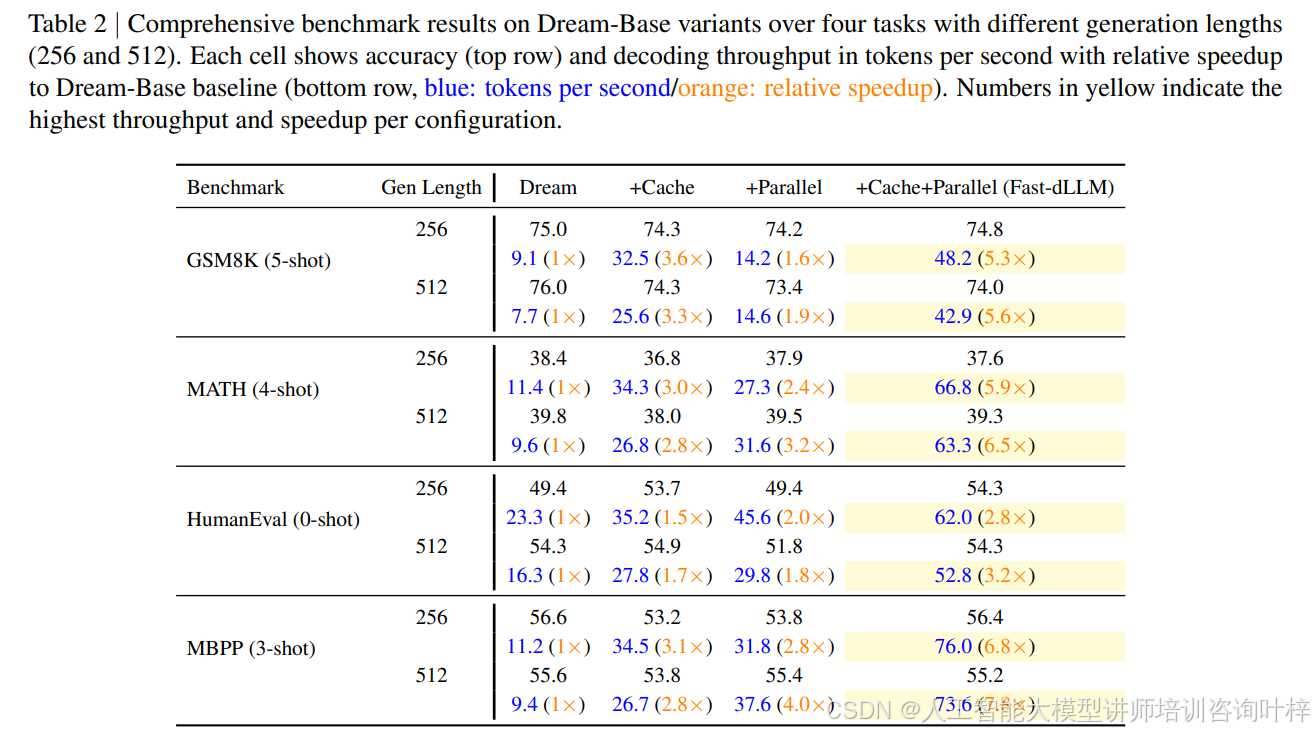
表 1 和 表 2 提供了详细的实验结果。在 LLaDA 模型上,Fast-dLLM 在 GSM8K 数据集上实现了 8.1 倍的吞吐量提升,而在 MBPP 数据集上,吞吐量提升达到了 9.2 倍。在 Dream 模型上,Fast-dLLM 在 GSM8K 数据集上实现了 5.3 倍的吞吐量提升,在 MBPP 数据集上,吞吐量提升达到了 7.8 倍。这些结果表明,Fast-dLLM 的方法不仅在不同的模型架构上具有通用性,而且在各种任务类型(如数学推理、程序合成等)上都表现出色。
https://arxiv.org/abs/2505.22618
https://github.com/NVlabs/Fast-dLLM