MobileCLIP2:优化多模态强化训练,实现低延迟下的图像文本模型性能突破
现有低延迟图像文本模型(如 MobileCLIP)在追求高分辨率任务性能时,面临多模态强化训练效率不足、教师模型质量有限、合成 caption 多样性不足等问题,导致模型在零样本分类、检索等任务中难以进一步突破性能瓶颈,同时难以平衡模型大小、延迟与精度的关系。为解决这一问题,Apple 团队提出MobileCLIP2模型,核心方法是改进多模态强化训练框架,通过采用更优质的基础数据集(DFN)、更强的 CLIP 教师模型集合、优化的 CoCa caption 生成器(基于 DFN 预训练并在高质量数据集上微调),同时设计新的混合视觉编码器架构,在低延迟场景下实现了 ImageNet-1k 零样本精度的显著提升。
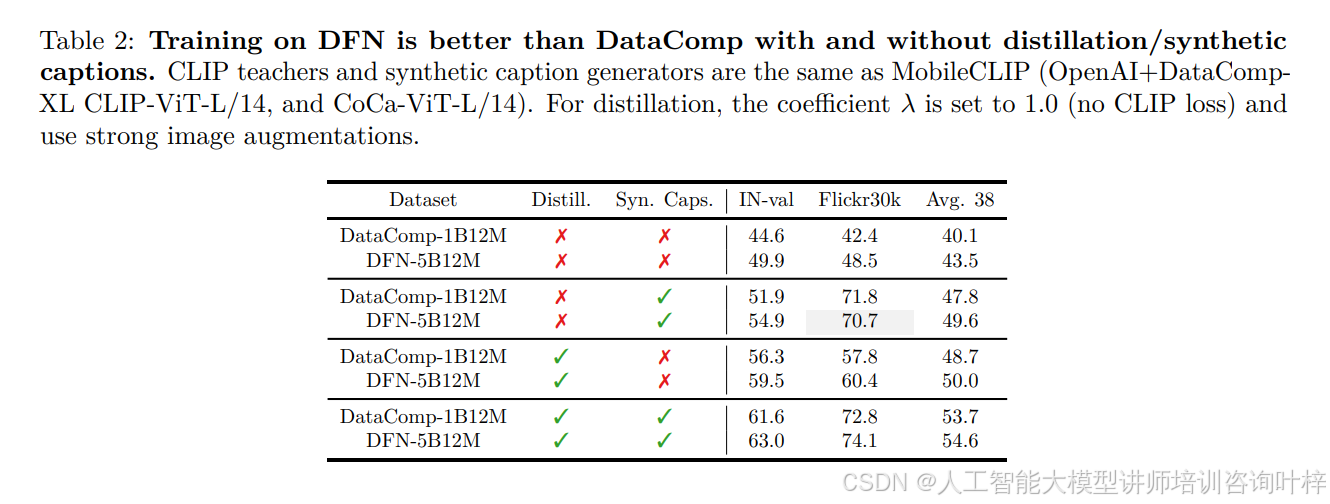
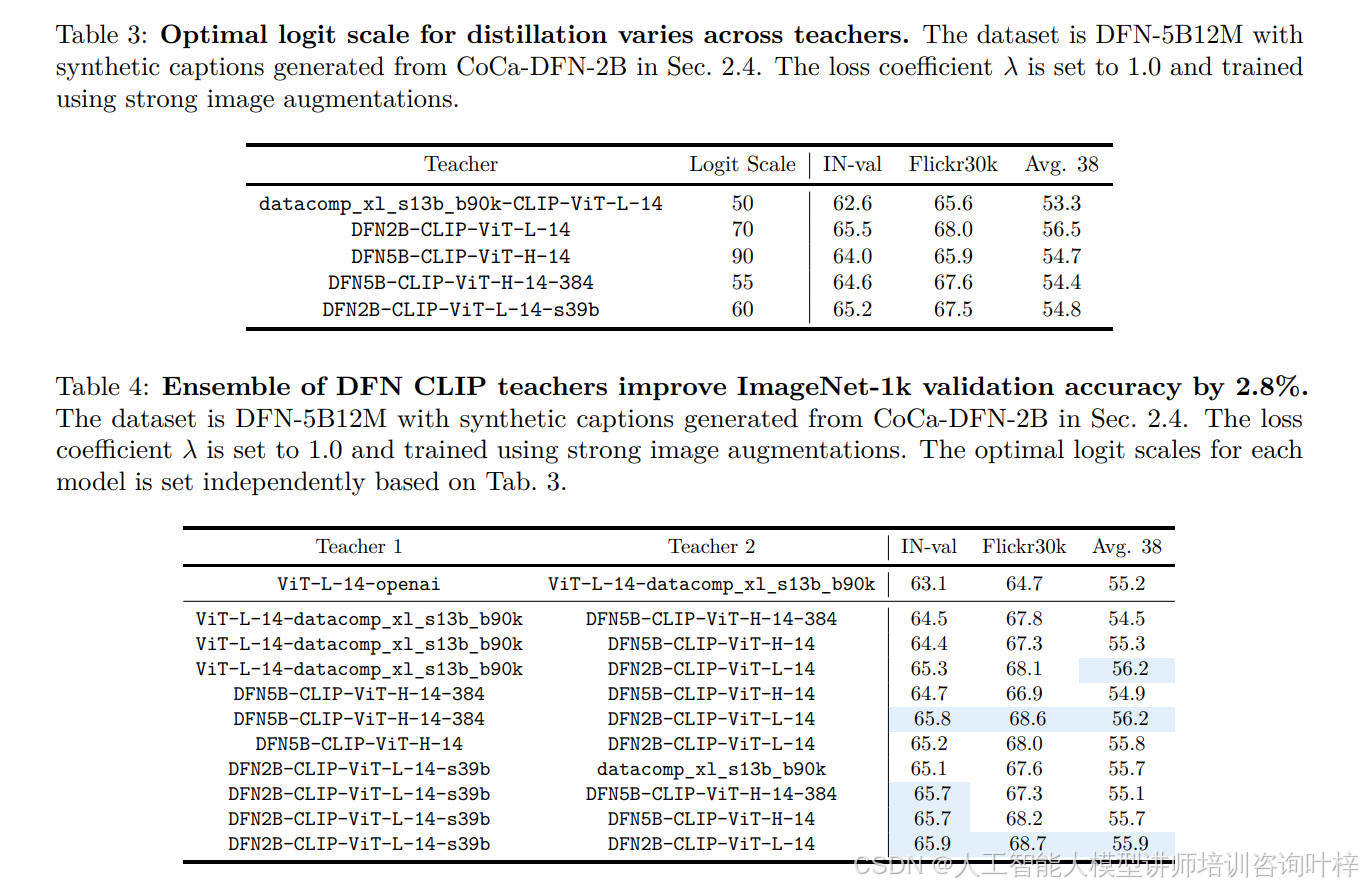
MobileCLIP2 的改进首先体现在多模态强化训练的优化上。团队将 MobileCLIP 原有的基础数据集从 DataComp-1B 替换为 DFN-5B,表 2数据显示,在相同训练配置下(含蒸馏和合成 caption),基于 DFN-5B12M 训练的模型在 ImageNet-1k 验证集(IN-val)精度达 63.0%,比 DataComp-1B12M 的 61.6% 提升 1.4%,Flickr30k 检索精度也从 72.8% 提升至 74.1%,验证了更高质量基础数据集对性能的增益。在 CLIP 教师模型选择上,团队摒弃 MobileCLIP 使用的 OpenAI+DataComp-XL 组合,转而采用 DFN 预训练的教师模型,表 3通过对比不同教师模型的最优 logit scale 发现,DFN2B-CLIP-ViT-L/14 在 logit scale 为 70 时,IN-val 精度达 65.5%,显著高于 DataComp-XL 教师模型的 62.6%;表 4进一步验证,由 DFN2B-CLIP-ViT-L-14-s39b 与 DFN2B-CLIP-ViT-L-14 组成的教师集合,能使 IN-val 精度提升至 65.9%,较 MobileCLIP 的教师组合提升 2.8%,同时 Flickr30k 检索精度达 68.7%,Avg.38 指标达 55.9%,全面优于传统教师组合。
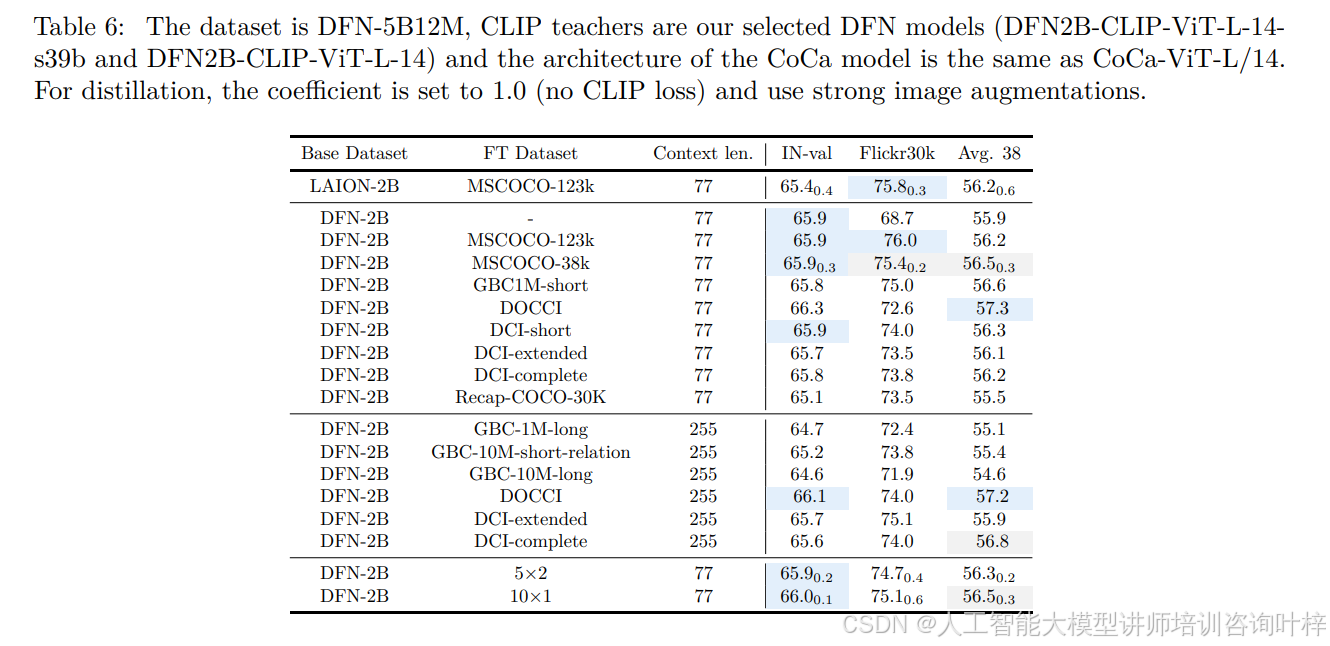
在 caption 生成器优化方面,MobileCLIP2 对 CoCa 模型进行了两阶段改进:先在 DFN-2B 数据集上预训练,再在高质量数据集上微调。表 5显示,仅在 DFN-2B 预训练的 CoCa 模型虽能提升 IN-val 精度(59.5%),但 Flickr30k 检索性能(60.3%)低于 MobileCLIP 使用的 LAION-2B 微调模型(70.6%);而表 6证明,经 MSCOCO-38k(含宽松许可证样本)微调后,DFN-CoCa 模型的性能短板被弥补 ——IN-val 精度维持 65.9%,Flickr30k 检索精度回升至 75.4%,Avg.38 指标达 56.5%,且微调数据集选择对性能影响可控,如 DOCCI 数据集微调虽使 Flickr30k 精度降至 72.6%,但 Avg.38 指标提升至 57.3%,高于 MSCOCO 微调结果。此外,团队还发现合成 caption 数量对性能的影响存在饱和效应,生成 10 个合成 caption 时(对比 5 个),IN-val 精度仅提升 0.1 个百分点(66.0%),验证了 MobileCLIP 中 “1-2 个合成 caption 即可获取主要增益” 的结论仍适用。

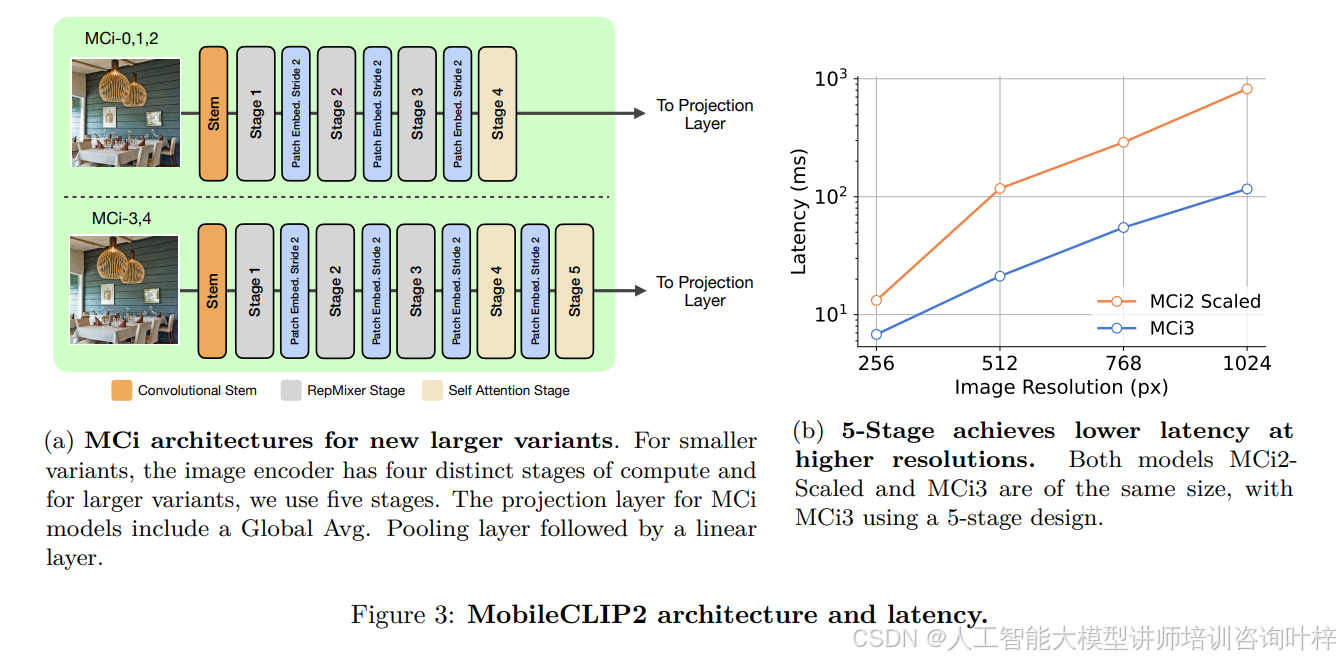
 MobileCLIP2 在架构设计上新增了 MCi3 和 MCi4 两种变体,采用五阶段混合卷积 - Transformer 结构(相较于 MobileCLIP 的四阶段设计),通过增加下采样阶段减少高分辨率输入时的 token 数量,提升编码效率。图 3b对比相同参数规模(125M)的 MCi2(四阶段)与 MCi3(五阶段)在不同分辨率下的延迟:256×256 分辨率时,MCi3 延迟仅为 MCi2 的 1/1.9;1024×1024 分辨率时,MCi3 延迟降至 MCi2 的 1/7.1,且分辨率越高,五阶段设计的延迟优势越显著,这对图像分割等需高分辨率输入的密集预测任务至关重要。
MobileCLIP2 在架构设计上新增了 MCi3 和 MCi4 两种变体,采用五阶段混合卷积 - Transformer 结构(相较于 MobileCLIP 的四阶段设计),通过增加下采样阶段减少高分辨率输入时的 token 数量,提升编码效率。图 3b对比相同参数规模(125M)的 MCi2(四阶段)与 MCi3(五阶段)在不同分辨率下的延迟:256×256 分辨率时,MCi3 延迟仅为 MCi2 的 1/1.9;1024×1024 分辨率时,MCi3 延迟降至 MCi2 的 1/7.1,且分辨率越高,五阶段设计的延迟优势越显著,这对图像分割等需高分辨率输入的密集预测任务至关重要。
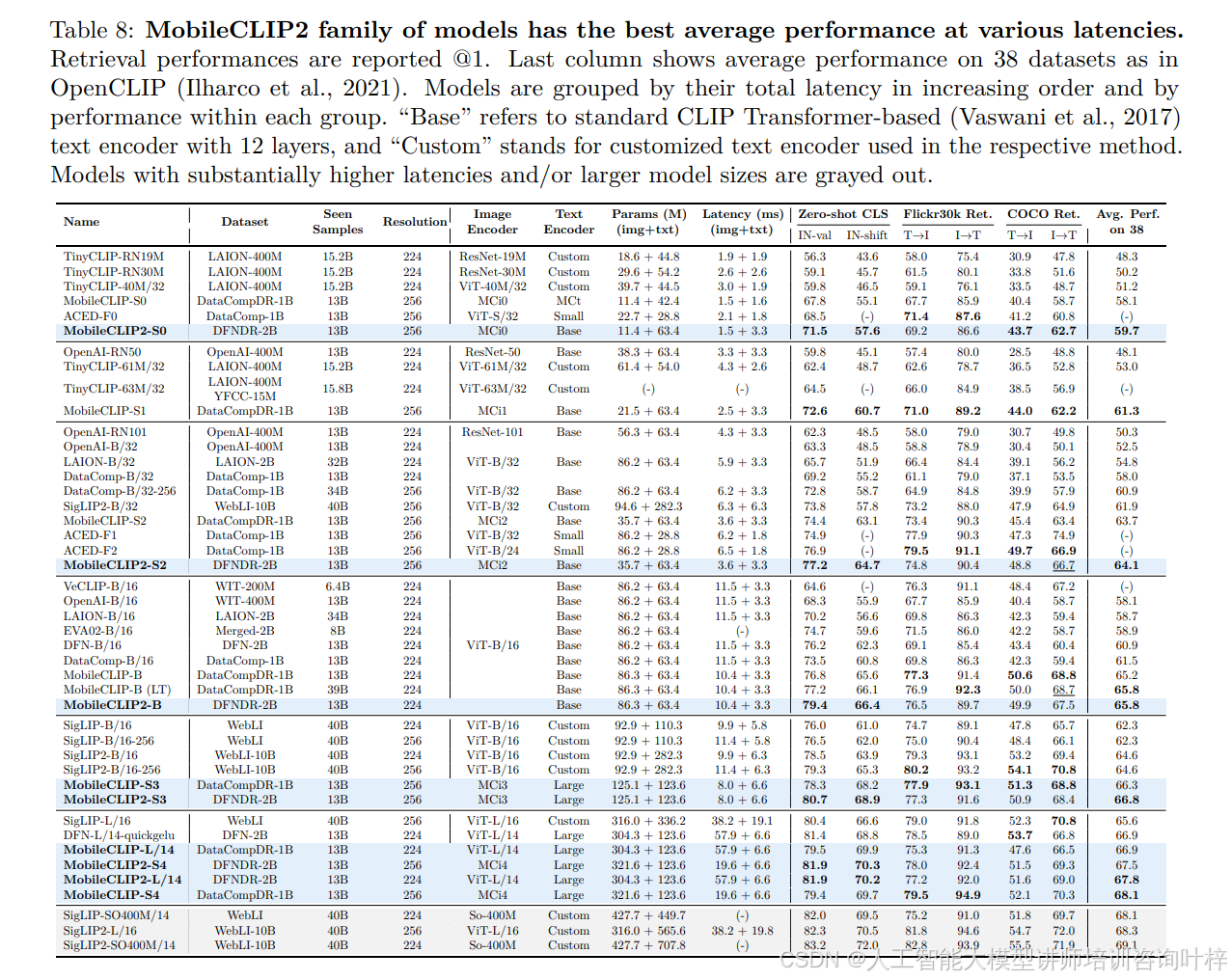
 在实验验证中,MobileCLIP2 展现出卓越的性能 - 延迟权衡。图 1通过对比 MobileCLIP2 与 SigLIP、DFN 等模型的 ImageNet-1k 零样本精度与延迟(iPhone12 Pro Max 测试)发现,MobileCLIP2-S4 在延迟仅为 SigLIP-SO400M/14 的 1/2.5 时,零样本精度(81.9%)与之持平(82.0%),且模型参数规模仅为后者的 1/2;相较于 DFN ViT-L/14,MobileCLIP2-S4 在精度提升 0.5 个百分点的同时,延迟降低至 1/2.5。表 8进一步对比多模型性能,MobileCLIP2-S2(35.7M+63.4M 参数,3.6+3.3ms 延迟)的 IN-val 精度达 77.2%,显著高于同延迟区间的 ACED-F1(74.9%),且参数规模仅为 ACED-F1(86.2M+28.8M)的 0.8 倍;MobileCLIP2-B(86.3M+63.4M 参数,10.4+3.3ms 延迟)的 IN-val 精度达 79.4%,高于 SigLIP2-B/16(78.5%),同时参数规模(149.7M)仅为后者(375.2M)的 1/2.5。
在实验验证中,MobileCLIP2 展现出卓越的性能 - 延迟权衡。图 1通过对比 MobileCLIP2 与 SigLIP、DFN 等模型的 ImageNet-1k 零样本精度与延迟(iPhone12 Pro Max 测试)发现,MobileCLIP2-S4 在延迟仅为 SigLIP-SO400M/14 的 1/2.5 时,零样本精度(81.9%)与之持平(82.0%),且模型参数规模仅为后者的 1/2;相较于 DFN ViT-L/14,MobileCLIP2-S4 在精度提升 0.5 个百分点的同时,延迟降低至 1/2.5。表 8进一步对比多模型性能,MobileCLIP2-S2(35.7M+63.4M 参数,3.6+3.3ms 延迟)的 IN-val 精度达 77.2%,显著高于同延迟区间的 ACED-F1(74.9%),且参数规模仅为 ACED-F1(86.2M+28.8M)的 0.8 倍;MobileCLIP2-B(86.3M+63.4M 参数,10.4+3.3ms 延迟)的 IN-val 精度达 79.4%,高于 SigLIP2-B/16(78.5%),同时参数规模(149.7M)仅为后者(375.2M)的 1/2.5。
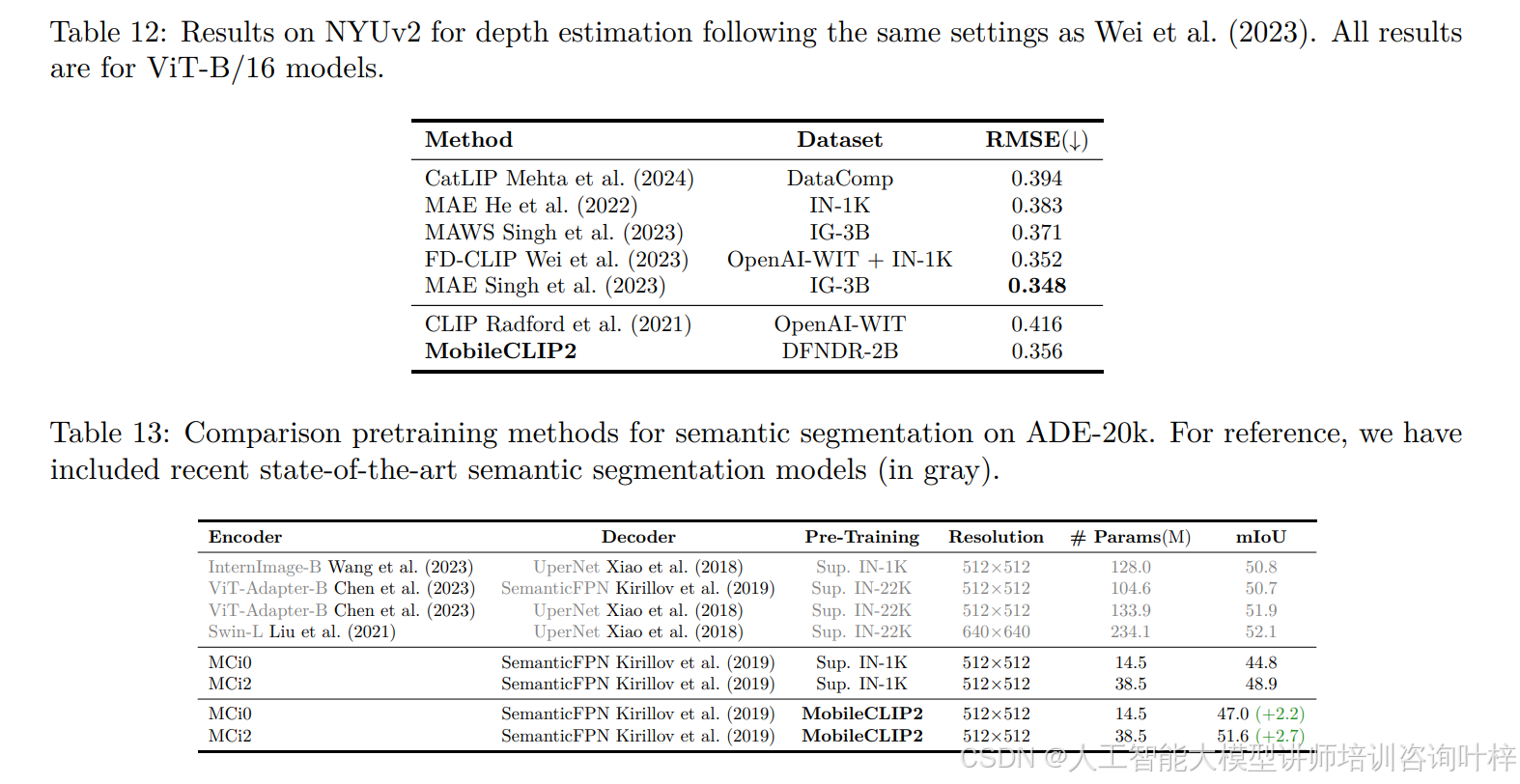
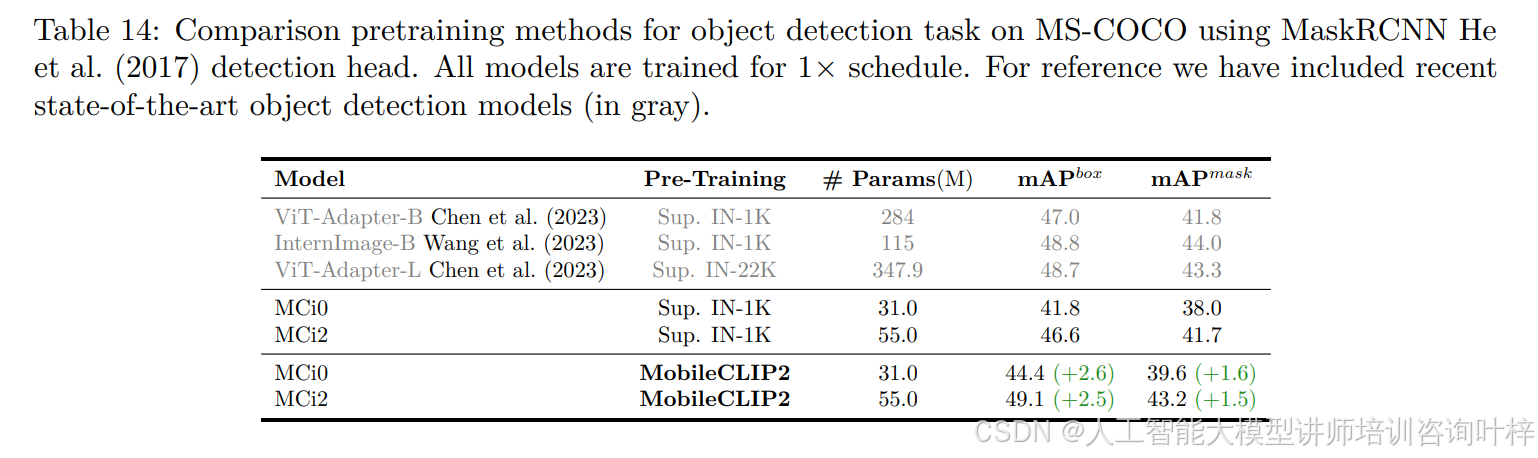
 MobileCLIP2 的泛化能力在跨任务测试中同样突出。表 9显示,在 LLaVA-1.5 框架(Qwen2-7B 为大模型)下,基于 DFNDR-2B 预训练的 MobileCLIP2 视觉编码器,在 GQA(60.4)、MMMU(45.2)、VQAv2(72.4)等 VLM 任务上的平均精度达 62.6%,较 DFN-2B 预训练模型高 3.5 个百分点,较 DataCompDR-1B 模型高 0.6 个百分点;表 12显示其在 NYUv2 深度估计任务的 RMSE 为 0.356,接近 FD-CLIP 的 0.352,且优于 MAE(0.383)等单模态预训练模型。此外,表 13和表 14验证了 MobileCLIP2 预训练对分层架构的适配性 ——MCi2 经 MobileCLIP2 预训练后,语义分割 mIoU 从 48.9%(监督预训练)提升至 51.6%,目标检测 mAPbox 从 46.6% 提升至 49.1%,证明其可作为分层卷积 / 混合架构的优质预训练方案。
MobileCLIP2 的泛化能力在跨任务测试中同样突出。表 9显示,在 LLaVA-1.5 框架(Qwen2-7B 为大模型)下,基于 DFNDR-2B 预训练的 MobileCLIP2 视觉编码器,在 GQA(60.4)、MMMU(45.2)、VQAv2(72.4)等 VLM 任务上的平均精度达 62.6%,较 DFN-2B 预训练模型高 3.5 个百分点,较 DataCompDR-1B 模型高 0.6 个百分点;表 12显示其在 NYUv2 深度估计任务的 RMSE 为 0.356,接近 FD-CLIP 的 0.352,且优于 MAE(0.383)等单模态预训练模型。此外,表 13和表 14验证了 MobileCLIP2 预训练对分层架构的适配性 ——MCi2 经 MobileCLIP2 预训练后,语义分割 mIoU 从 48.9%(监督预训练)提升至 51.6%,目标检测 mAPbox 从 46.6% 提升至 49.1%,证明其可作为分层卷积 / 混合架构的优质预训练方案。
https://arxiv.org/pdf/2508.20691
项目链接:
- 预训练模型:GitHub - apple/ml-mobileclip: This repository contains the official implementation of the research papers, "MobileCLIP" CVPR 2024 and "MobileCLIP2" TMLR August 2025
- 数据生成代码:GitHub - apple/ml-mobileclip-dr: RayGen: Multi-Modal Dataset Reinforcement for MobileCLIP and MobileCLIP2