MySQL中的聚合函数与分组查询
精选专栏链接 🔗
- MySQL技术笔记专栏
- Redis技术笔记专栏
- 大模型搭建专栏
- Python学习笔记专栏
- 深度学习算法专栏
欢迎订阅,点赞+关注,每日精进1%,与百万开发者共攀技术珠峰
更多内容持续更新中!希望能给大家带来帮助~ 😀😀😀
MySQL中的聚合函数与分组查询
- 1,MySQL函数的分类
- 2,MySQL内置函数的分类
- 3,不同DBMS函数差异显著
- 4,五大常用的聚合函数
- 4.1,AVG和SUM
- 4.2,MAX和MIN
- 4.3,COUNT
- 5,GROUP BY的使用
- 5.1,GROUP BY的基本使用
- 5.2,GROUP BY使用多个列进行分组
- 5.3,易错点
- 6,HAVING的使用
- 7,SQL语句底层执行原理
1,MySQL函数的分类
函数在计算机语言的使用中贯穿始终,从函数定义的角度出发,我们可以将函数分成内置函数和自定义函数。
- 内置函数是系统内置的通用函数;
- 而自定义函数是我们根据自己的需要编写的;
在 SQL 语言中,同样也包括了内置函数和自定义函数。
2,MySQL内置函数的分类
MySQL提供了丰富的内置函数,这些函数使得数据的维护与管理更加方便,能够更好地提供数据的分析与统计功能,在一定程度上提高了开发人员进行数据分析与统计的效率。
MySQL提供的内置函数从实现的功能角度可以分为:
- 数值函数;
- 字符串函数;
- 日期和时间函数;
- 流程控制函数;
- 加密与解密函数;
- 获取MySQL信息函数;
- 聚合函数等…
这里,我们将这些丰富的内置函数再分为两类:单行函数、聚合函数(或多行函数)。上一篇博文中我们已经讲解了 MySQL内置的单行函数链接。因此本文主要讲解MySQL内置函数中的聚合函数。
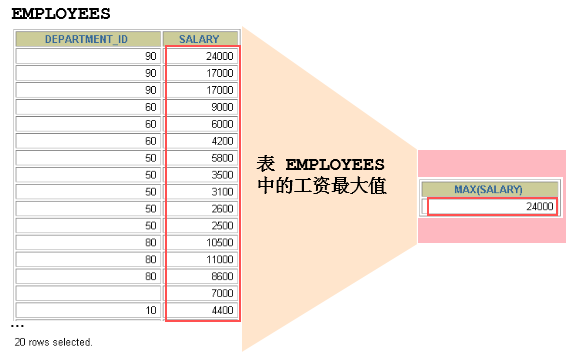
聚合函数是
对多行数据进行汇总的函数,只输出一个结果。聚合函数图示如下:(求表中最大的工资值)
3,不同DBMS函数差异显著
我们在使用 SQL 语言的时候,不是直接和这门语言打交道,而是通过它使用不同的数据库软件,即 DBMS。DBMS 之间的差异性很大。
实际上,只有很少的函数是被 DBMS 同时支持的。比如,大多数 DBMS 使用(||)或者(+)来做拼接符,而在 MySQL 中的字符串拼接函数为concat()。大部分 DBMS 会有自己特定的函数,这就意味着 采用 SQL 函数的代码可移植性是很差的 ,因此在使用函数的时候需要特别注意。
4,五大常用的聚合函数
MySQL常用的聚合函数有五类:
- AVG() :求数值型字段的平均值,
只会计算非NULL值的平均数; - SUM():对数值型字段进行求和运算,会自动过滤掉Null值;
- MAX() :返回字段的最大值。支持数值、日期、字符串类型,返回非NULL值中的最大值
- MIN() :返回字段的最小值。支持数值、日期、字符串类型,返回非NULL值中的最小值
- COUNT() :统计行数或
非NULL值的数量;
但需要特别注意的是:
MySQL中聚合函数不能嵌套调用。(Oracle)比如不能出现类似 “AVG(SUM(字段名称))” 形式的调用。
接下来对这些聚合函数进行详细讲解。
4.1,AVG和SUM
AVG函数 和 SUM 函数适用于数值型数据,对其它类型数据没有意义。(计算时过滤掉Null值 )
需求:查询employees表中,员工的月平均工资记为avg_aslary、公司每个月应付给员工的工资记为pay_salary。
SQL代码如下:
SELECT AVG(salary) avg_salary,SUM(salary) pay_salary
FROM employees;
运行结果如下:

需要特别注意的是:AVG(salary)返回的是salary不为空的那些记录的平均salary,而不是所有记录的平均salary。
4.2,MAX和MIN
MAX 函数和 MIN 函数适用于数值类型、字符串类型、日期时间类型的字段(或变量)。(计算时过滤掉Null值)
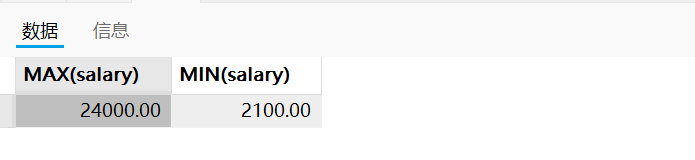
需求:查询公司开出的的最高工资金额和最低工资金额
SQL语句如下:
SELECT MAX(salary),MIN(salary)
FROM employees;
运行结果如下:
此外:对一些字符串类型和日期类型的字段也可以应用MAX函数和MIN函数
SQL示例如下:
SELECT MAX(last_name),MIN(last_name),MAX(hire_date),MIN(hire_date)
FROM employees;
运行结果如下:

注意:
- MAX函数和MIN函数当对字符串类型数据使用时,是从第一个字符开始,按 ASCII 码值逐字符比较,取最大或最小值。
- MAX函数和MIN函数对日期类型数据使用时,数据库将日期转换为内部的时间戳,直接比较数值大小。 例如:MAX(hire_date) 会返回最晚的入职日期。
4.3,COUNT
COUNT函数的作用是计算指定字段在查询结构中出现的个数(计算时过滤掉NULL值)。
SQL示例如下:
SELECT COUNT(employee_id),COUNT(salary),COUNT(2 * salary),COUNT(*)
FROM employees ;
运行结果如下:

COUNT(*)可以用来计算表中有多少条记录,比如:
需求:查询部门ID为50的员工的总数
SELECT COUNT(*)
FROM employees
WHERE department_id = 50;
运行结果如下:

其中需要特别注意的是:
- COUNT(*)是计算表中的
记录总数。也可以使用COUNT(1)实现; - COUNT(某字段)是计算表中
某字段不为空的记录总数;
5,GROUP BY的使用
MySQL中,可以使用GROUP BY子句将表中的数据分成若干组。
- GROUP BY子句声明的位置应该在FROM和WHERE子句后面,在ORDER BY和LIMIT子句前面。
5.1,GROUP BY的基本使用
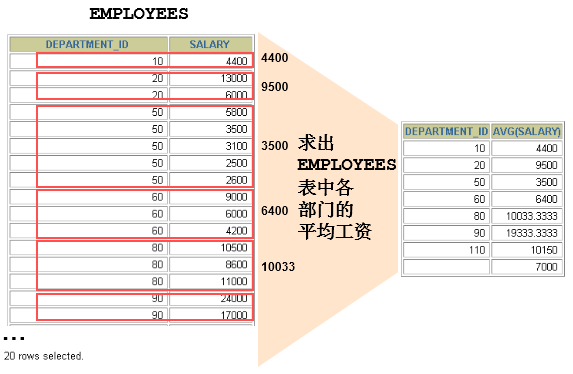
需求一:求出employees表中各部门的平均薪资和最高薪资
SQL语句如下:
SELECT department_id,AVG(salary),SUM(salary)
FROM employees
# 使用department_id字段进行分组
GROUP BY department_id
运行结果如下:
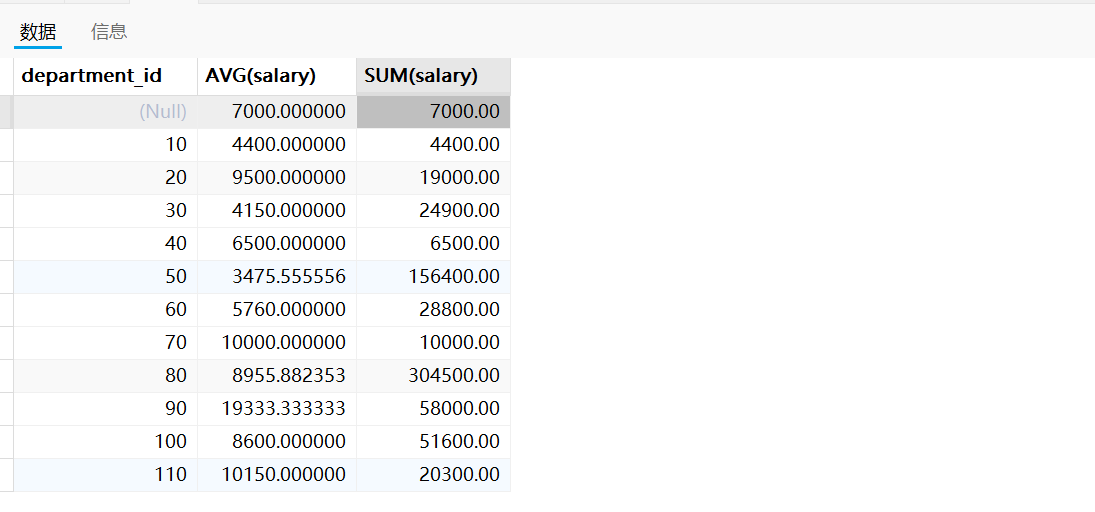
注意:可以发现查询结果中存在为Null的记录,这是因为employees表中存在department_id为空的员工,GROUP BY时默认将这些员工放到一组。
上述操作的示意图如下:
需求二:查询各个job_id(不同工种)的平均工资
SQL语句如下:
SELECT job_id,AVG(salary)
FROM employees
GROUP BY job_id;
运行结果如下:

5.2,GROUP BY使用多个列进行分组
我们上面已经演示了根据department_id对不同部门进行分组,如果我想再分完组结果的基础之上再次对同一个部门内部不同的job_id(工种)进行分组,那就需要借助多列GROUP BY进行多列分组 。
需求:查询各个department_id,job_id的平均工资
实现方式一:先按照department_id分组,再按照job_id分组
SELECT department_id,job_id,AVG(salary)
FROM employees
GROUP BY department_id,job_id;
运行结果如下:
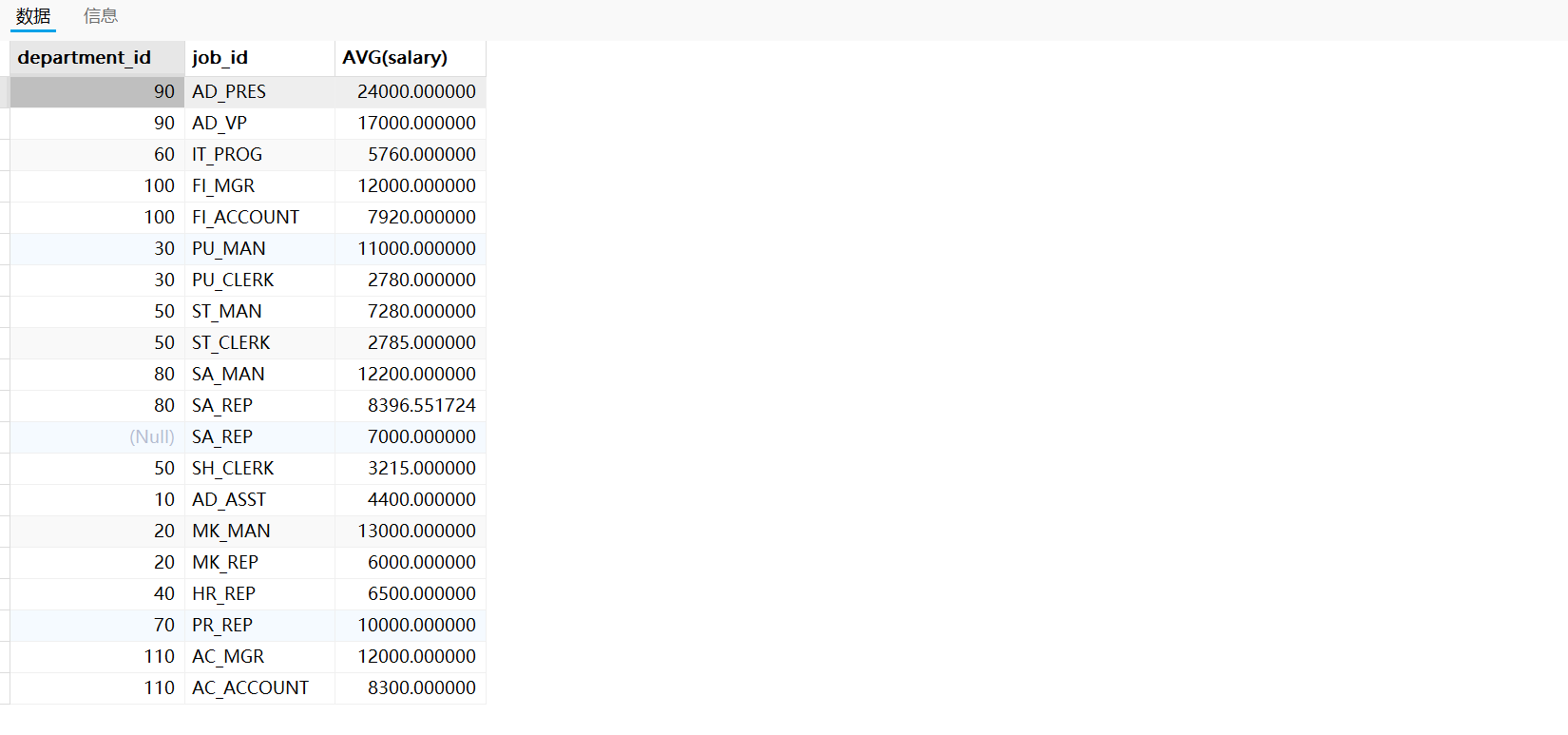
实现方式二:先按照job_id分组,再按照department_id分组
SELECT job_id,department_id,AVG(salary)
FROM employees
GROUP BY job_id,department_id;
运行结果如下:
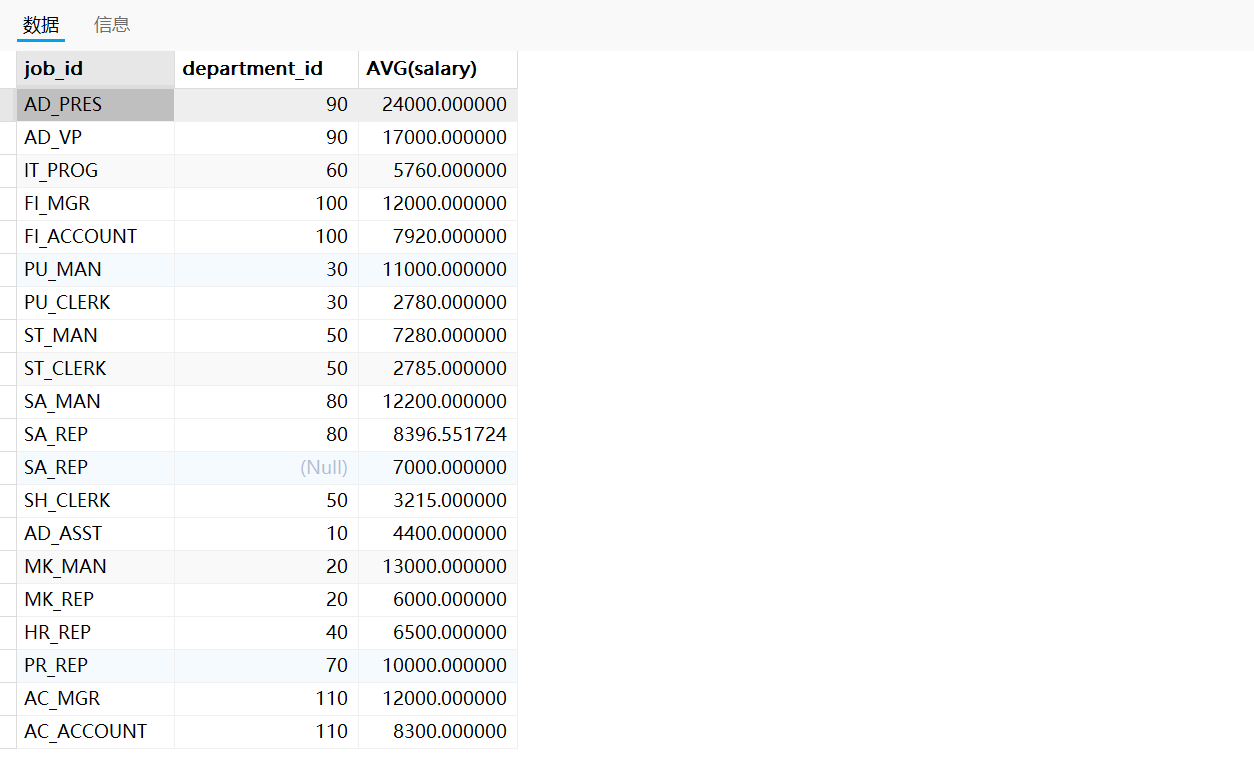
上述两种实现方式实现的效果是相同的:同一个部门同一个工种的才会分到一组。
5.3,易错点
错误SQL示例:
SELECT department_id,job_id,AVG(salary)
FROM employees
GROUP BY department_id;
这段SQL代码是错误的,原因是因为SELECT的字段内不能包括 job_id ,根据 department_id 分组后,一个 department_id 占一条数据,而每个部门的 job_id 有很多,job_id 此处不应该出现。
规律总结:
- SELECT中出现的非聚合函数的字段必须声明在GROUP BY 中;
- GROUP BY中声明的字段可以不出现在SELECT中;
6,HAVING的使用
HAVING子句 是SQL中用于对分组后的结果集进行过滤的关键工具。需要注意的是:
-
满足HAVING 子句中条件的分组会被显示;
-
HAVING子句必须声明在GROUP BY后面,否则会报错; -
HAVING 不能单独使用,必须要跟 GROUP BY 一起使用;
-
如果过滤条件中使用了聚合函数,则必须使用HAVING来替换WHERE。 否则会报错,因为不能在 WHERE 子句中使用聚合函数;
-
当过滤条件中没有聚合函数时,则此过滤条件声明在WHERE中或HAVING中都可以。 但建议声明在WHERE子句中,因为先执行的WHERE子句做筛选掉一些冗余信息,效率会更高。而如果过滤条件全部放到HAVING子句中,会有冗余信息保留,影响SQL执行效率。
需求一:查询各个部门中最高工资比10000高的部门信息
SQL语句如下:
SELECT department_id,MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000;
运行结果如下:
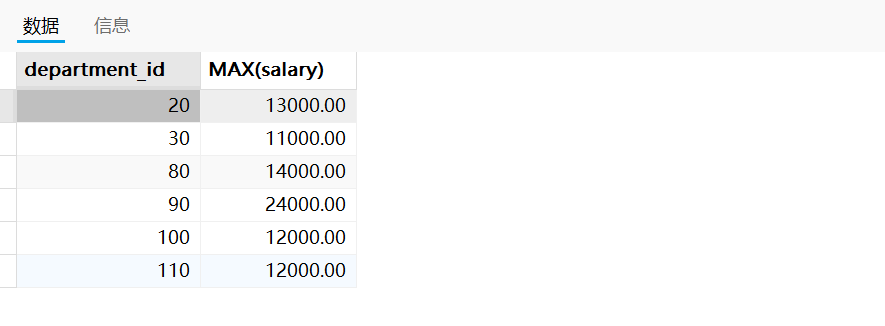
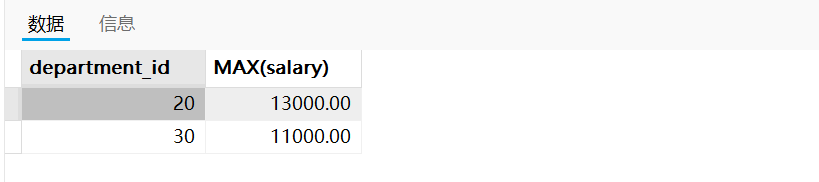
需求二:查询部门id为10,20,30,40这4个部门中最高工资比10000高的部门信息
实现方式一(推荐,效率更高):
SELECT department_id,MAX(salary)
FROM employees
WHERE department_id IN (10,20,30,40)
GROUP BY department_id
HAVING MAX(salary) > 10000;
实现方式二(过滤条件全部放在HAVING子句中):
SELECT department_id,MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000 AND department_id IN (10,20,30,40);
两种实现方式得到的结果一致,如下图:
7,SQL语句底层执行原理
首先,SQL语句的关键字声明的顺序是不能颠倒的,SQL关键字声明顺序如下:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... LIMIT...
其次,SQL语句的实际执行顺序和声明顺序并不一致。SQL语句执行顺序如下:
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT 的字段 -> DISTINCT -> ORDER BY -> LIMIT
比如你写了一个 SQL 语句,那么它的关键字顺序和执行顺序是下面这样的:
SELECT DISTINCT player_id, player_name, count(*) as num # 顺序 5
FROM player JOIN team ON player.team_id = team.team_id # 顺序 1
WHERE height > 1.80 # 顺序 2
GROUP BY player.team_id # 顺序 3
HAVING num > 2 # 顺序 4
ORDER BY num DESC # 顺序 6
LIMIT 2 # 顺序 7
之前我们提到过: 在SELECT子句中给字段起别名之后,可以在ORDER BY子句中使用,但不可以在WHERE子句中使用,原因就是:WHERE子句的执行在SELECT之前,WHERE子句执行的时候还没有起别名。
在 SELECT 语句执行这些步骤的时候,每个步骤都会产生一个虚拟表,然后将这个虚拟表传入下一个步骤中作为输入。需要注意的是,这些步骤隐含在 SQL 的执行过程中,对于我们来说是不可见的。
SELECT 是先执行 FROM 这一步的。在这个阶段,如果是多张表联查,还会经历下面的几个步骤(vt为virtual table):
- 首先先通过 CROSS JOIN 求笛卡尔积,相当于得到虚拟表 vt1-1;
- 通过 ON 进行筛选,在虚拟表 vt1-1 的基础上进行筛选,得到虚拟表 vt1-2;
- 添加外部行。如果我们使用的是左连接、右链接或者全连接,就会涉及到外部行,也就是在虚拟表 vt1-2 的基础上增加外部行,得到虚拟表 vt1-3。
当然如果我们操作的是两张以上的表,还会重复上面的步骤,直到所有表都被处理完为止。这个过程得到是我们的原始数据。
当我们拿到了查询数据表的原始数据,也就是最终的虚拟表
vt1,就可以在此基础上再进行WHERE 阶段。在这个阶段中,会根据 vt1 表的结果进行筛选过滤,得到虚拟表vt2。
然后进入第三步和第四步,也就是
GROUP 和 HAVING 阶段。在这个阶段中,实际上是在虚拟表 vt2 的基础上进行分组和分组过滤,得到中间的虚拟表vt3和vt4。
当我们完成了条件筛选部分之后,就可以筛选表中提取的字段,也就是进入到
SELECT 和 DISTINCT 阶段。
首先在 SELECT 阶段会提取想要的字段,然后在 DISTINCT 阶段过滤掉重复的行,分别得到中间的虚拟表 vt5-1 和 vt5-2。
当我们提取了想要的字段数据之后,就可以按照指定的字段进行排序,也就是
ORDER BY 阶段,得到虚拟表vt6。
最后在 vt6 的基础上,取出指定行的记录,也就是
LIMIT 阶段,得到最终的结果,对应的是虚拟表vt7。
当然我们在写 SELECT 语句的时候,不一定存在所有的关键字,相应的阶段就会省略。同时因为 SQL 是一门类似英语的结构化查询语言,所以我们在写 SELECT 语句的时候,还要注意相应的关键字顺序,所谓底层运行的原理,就是我们刚才讲到的执行顺序。