Linux awk命令完全指南:从原理到实战,搞定文本处理难题
在Linux世界里,文本处理是运维、开发绕不开的日常——从分析日志、提取配置信息到统计数据,都需要高效的工具支撑。而awk,作为一款强大的文本分析语言,凭借“按字段处理”的核心能力,成为了比grep(单纯匹配)、sed(整行编辑)更灵活的“文本处理瑞士军刀”。今天这篇文章,我们从原理到实战,带你彻底掌握awk的用法,解决90%的文本处理场景。
一、认识awk:它是什么,从哪里来?
awk并非简单的命令,而是一门专为文本处理设计的编程语言,诞生于20世纪70年代的贝尔实验室,名字取自三位创始人Alfred Aho、Peter Weinberger、Brian Kernighan的姓氏首字母。
1.1 awk的版本区别
在Linux系统中,我们实际使用的awk大多是GNU awk(gawk)——因为所有GNU/Linux发行版(如CentOS、Ubuntu)都自带gawk,且它完全兼容早期的AWK(AT&T原版)和NAWK(New AWK,原版升级版)。
你可以通过以下命令验证:
# 查看awk的实际路径
which awk # 输出:/usr/bin/awk
# 查看是否为gawk的软链接
ll `which awk` # 输出:lrwxrwxrwx. 1 root root 4 ... /usr/bin/awk -> gawk

简单说:在Linux中输入awk命令,实际执行的是gawk。
二、awk的核心:工作原理与流程
要用好awk,必须先理解它的“做事逻辑”——这也是它和sed最大的区别:
- sed:以“整行”为单位处理文本;
- awk:先将每行拆分为“字段”(默认用空格/制表符分隔),再按字段处理,支持逻辑判断、数学运算。
2.1 工作原理
awk的处理流程可以概括为“逐行读取→字段拆分→条件匹配→执行操作”:
- 从标准输入(如管道)或文件中逐行读取文本;
- 按默认分隔符(空格/制表符)或自定义分隔符,将当前行拆分为多个“字段”,用
$1(第一列)、$2(第二列)…$n(第n列)表示,$0表示整行; - 根据指定的“模式”(如包含某个关键词、行号范围)判断是否处理当前行;
- 若匹配模式,执行指定的“动作”(如打印字段、统计计数);
- 重复1-4,直到文件读取完毕。
2.2 三大核心模块:BEGIN → 主体 → END
awk的脚本结构由三个可选模块组成,执行顺序严格固定,这是它的灵魂:
| 模块 | 执行时机 | 作用示例 |
|---|---|---|
| BEGIN | 读取文本前执行(仅1次) | 初始化变量、打印表头 |
| 主体 | 逐行读取文本时执行(每行会触发) | 字段提取、条件判断 |
| END | 读取文本后执行(仅1次) | 汇总统计结果、打印最终值 |
用流程图理解更直观:
开始 → 执行BEGIN模块 → 读取一行文本 → 执行主体模块(按模式处理) → 文件是否结束?↑ ↓└──────────────────────┘(否)↓(是)执行END模块 → 结束
三、awk基础:语法与核心内置变量
掌握语法和内置变量,是玩转awk的第一步。
3.1 基本语法
awk有两种常用命令格式,根据场景选择:
格式1:直接在命令行写逻辑
awk [选项] '模式{动作}' 文件名1 文件名2...
- 选项:常用
-F指定字段分隔符(如-F:表示用冒号分隔); - 模式:可选,如行号(
NR==5)、关键词匹配(/root/); - 动作:必须用
{}包裹,如print $1(打印第一列)、变量运算。
格式2:用脚本文件(适合复杂逻辑)
当逻辑复杂时,将模式和动作写入脚本文件,用-f指定:
awk -f 脚本文件 文件名
3.2 必学内置变量
awk预定义了一批“开箱即用”的变量,覆盖90%的实战场景,务必牢记:
| 内置变量 | 含义说明 | 实战常用场景 |
|---|---|---|
FS | 输入字段分隔符(默认:空格/制表符) | BEGIN{FS=“:”}(用冒号分隔) |
NF | 当前行的字段总数(列数) | 打印最后一列:print $NF |
NR | 当前处理的行号(所有文件统一计数) | 打印前5行:NR<=5 |
FNR | 当前处理的行号(每个文件单独计数) | 多文件对比时用 |
$0 | 当前处理的整行内容 | 打印整行:print $0 |
$n | 当前行的第n个字段(n为数字,如$1是第一列) | 提取用户名:print $1 |
OFS | 输出字段分隔符(默认:空格) | 输出用“—”分隔:BEGIN{OFS=“—”} |
FILENAME | 当前处理的文件名 | 多文件处理时标记来源 |
四、awk实战:从基础到生产级案例
理论讲完,直接上案例——这些场景都是Linux运维/开发的高频需求,跟着练一遍就能上手。
4.1 基础案例:字段提取与格式控制
案例1:提取/etc/passwd的关键信息
/etc/passwd用冒号分隔,包含用户名、UID、家目录等信息,用awk轻松提取:
# 1. 用冒号分隔,打印用户名($1)和家目录($6),输出用制表符分隔
awk -F: '{print $1 "\t" $6}' /etc/passwd
# 输出示例:
# root /root
# bin /bin
# 2. 只打印包含“root”的行,且显示行号(NR)
awk -F: '/root/{print NR, $1, $6}' /etc/passwd
# 输出示例:
# 1 root /root
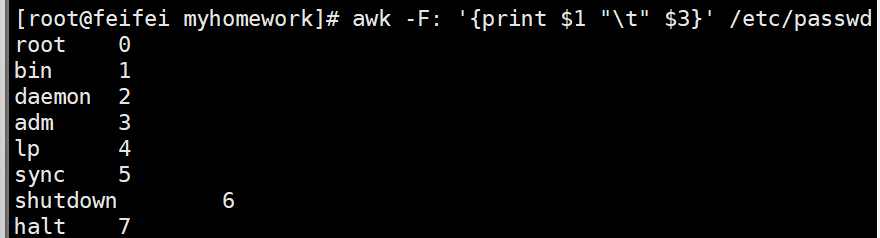
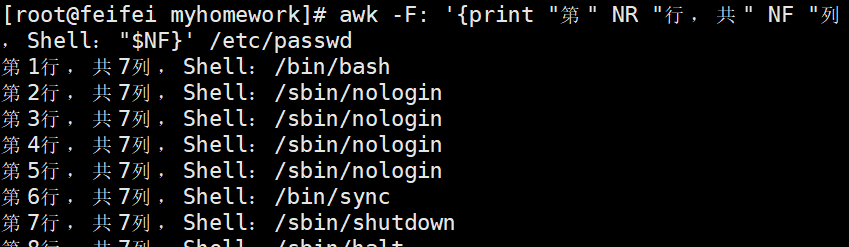
# 10 operator /root# 3. 打印最后一列(登录Shell),并标注“行号-列数”
awk -F: '{print "第" NR "行,共" NF "列,Shell:" $NF}' /etc/passwd
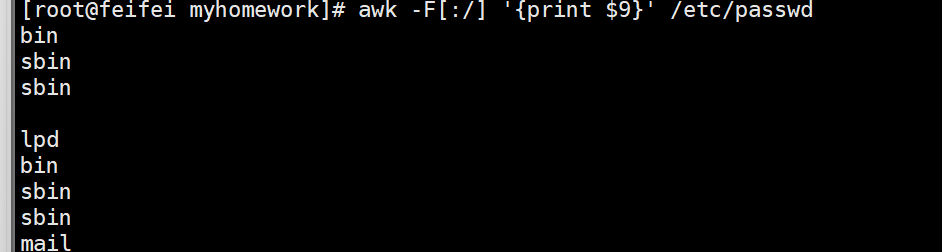
案例2:自定义多分隔符
如果文本用多种符号分隔(如:和/),可在-F后用[]指定:
# 用“:”或“/”分隔,打印第9列(适用于/etc/passwd的Shell路径提取)
awk -F[:/] '{print $9}' /etc/passwd
# 输出示例:
# bash
# nologin
4.2 进阶案例:条件判断与统计
案例1:数值与字符串比较
awk支持数值比较(==、<、>、>=)和字符串精确匹配(需加引号):
# 1. 打印UID=0的用户(管理员用户,$3是UID)
awk -F: '$3==0{print $1 "是管理员"}' /etc/passwd
# 输出:root是管理员# 2. 打印UID>=1000的普通用户($3>=1000)
awk -F: '$3>=1000{print $1 "是普通用户,UID:" $3}' /etc/passwd# 3. 精确匹配用户名“root”(字符串必须加双引号!)
awk -F: '$1=="root"{print $0}' /etc/passwd
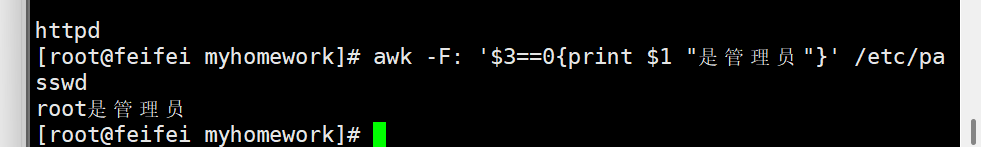
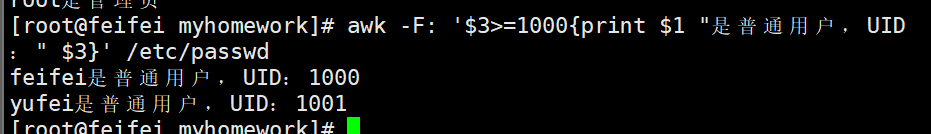
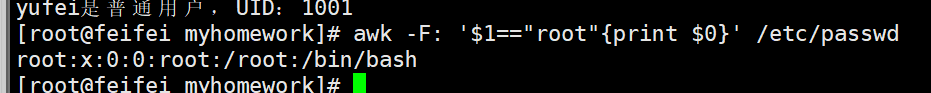
案例2:模糊匹配(~ 和 !~)
用~表示“包含”,!~表示“不包含”,结合正则表达式使用:
# 1. 打印Shell包含“bash”的用户(即能登录的用户)
awk -F: '$7~"bash"{print $1}' /etc/passwd# 2. 打印Shell不包含“nologin”且不包含“bash”的用户
awk -F: '$7!~"nologin" && $7!~"bash"{print $1}' /etc/passwd
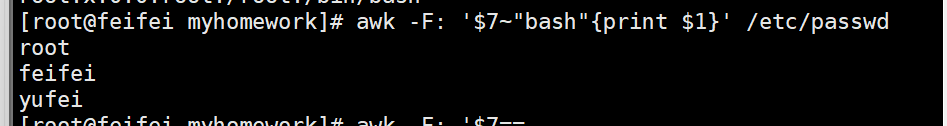

案例3:用BEGIN/END做统计汇总
BEGIN初始化变量,END输出最终结果,适合统计场景:
# 1. 统计/etc/passwd的总行数(END中用NR,因为NR是总计数)
awk 'END{print "/etc/passwd共有" NR "行"}' /etc/passwd# 2. 统计能登录的用户数(Shell为bash)
awk -F: 'BEGIN{count=0} $7~"bash"{count++} END{print "能登录的用户数:" count}' /etc/passwd# 3. 计算1-10的总和(BEGIN中用循环)
awk 'BEGIN{sum=0; for(i=1;i<=10;i++){sum+=i}; print "1-10总和:" sum}'



4.3 生产级案例:系统监控与日志分析
awk常与其他命令结合,实现系统监控和日志统计,这是运维的核心技能。
案例1:查看内存使用率
用free -m获取内存信息,awk计算使用率:
# 计算内存使用率(已用/总内存 *100,保留整数)
free -m | awk '/Mem:/ {used=$3; total=$2; rate=int(used/total*100); print "内存使用率:" rate "%"}'
# 输出:内存使用率:35%

4.4 扩展生产案列:网卡的ip、流量
[root@localhost ~]# ifconfig ens33 | awk '/netmask/{print "本机的ip地址是"$2}'

[root@localhost ~]# ifconfig ens33 | awk '/RX p/{print $5"字节"}'

[root@localhost ~]# df -h | awk 'NR==2{print $4}'

4.5 逻辑运算
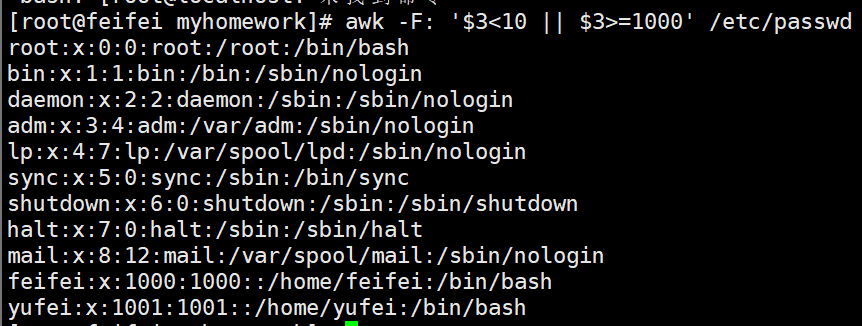
[root@localhost ~]# awk -F: '$3<10 || $3>=1000' /etc/passwd
[root@localhost ~]# awk -F: '$3>10 && $3<1000' /etc/passwd
[root@localhost ~]# awk -F: 'NR>4 && NR<10' /etc/passwd
4.6 其他内置变量
其他内置变量的用法FS(输入)、OFS、NR、FNR、RS、ORSFS:输入字段的分隔符 默认是空格OFS:输出字段的分隔符 默认也是空格
FNR:读取文件的记录数(行号),从1开始,新的文件重新重1开始计数
RS:输入行分隔符 默认为换行符
ORS:输出行分隔符 默认也是为换行符
五、awk vs grep vs sed:该用谁?
很多人分不清这三个工具,最后总结一张表,帮你快速选择:
| 工具 | 核心能力 | 适用场景 | 一句话总结 |
|---|---|---|---|
| grep | 文本搜索与匹配 | 单纯查找关键词、过滤行 | “找东西” |
| sed | 流式编辑(整行处理) | 替换文本、删除行、插入行 | “改东西” |
| awk | 字段处理、统计与格式化 | 提取列、计算数据、生成报告 | “拆字段、算数据” |
六、学习建议
awk的语法灵活,光看理论不够,建议:
- 先练基础案例:用
/etc/passwd、/var/log/messages等系统文件练手,熟悉内置变量; - 再做实战场景:尝试统计自己项目的日志(如用户访问次数、错误码统计);
- 复杂逻辑写脚本:当命令行逻辑过长时,用
-f脚本文件,方便维护。
掌握awk后,你会发现以前需要写几行Python的文本处理需求,用一行awk就能搞定——这就是Linux命令行的效率之美!
需要我帮你把某类awk案例(比如日志统计、系统监控)整理成可直接复用的脚本吗?