SpringBoot+PDF.js实现按需分片加载(包含可运行样例源码)
SpringBoot+PDF.js实现按需分片加载
- 前言
- 一、实现思路与实现效果
- 1.1 pdf.js的分片加载的实现思路
- 1.2 pdf分片加载的效果
- 二、前端项目
- 2.1 项目引入
- 2.2 核心代码
- 2.3 项目运行
- 三、后端项目
- 3.1 项目结构
- 3.2 核心代码
- 3.3 项目运行
- 四、项目运行效果
- 4.1 首次访问
- 4.2 分片加载
- 五、项目优化
- 5.1滚动条拖动导致大量请求造成流量浪费
- 修改1:禁用预加载机制
- 修改2:优化可见性检测阈值
- 修改3:添加滚动防抖机制
- 可调整的参数:
- 5.2 引入ehcache缓存解决pdf加载速度问题
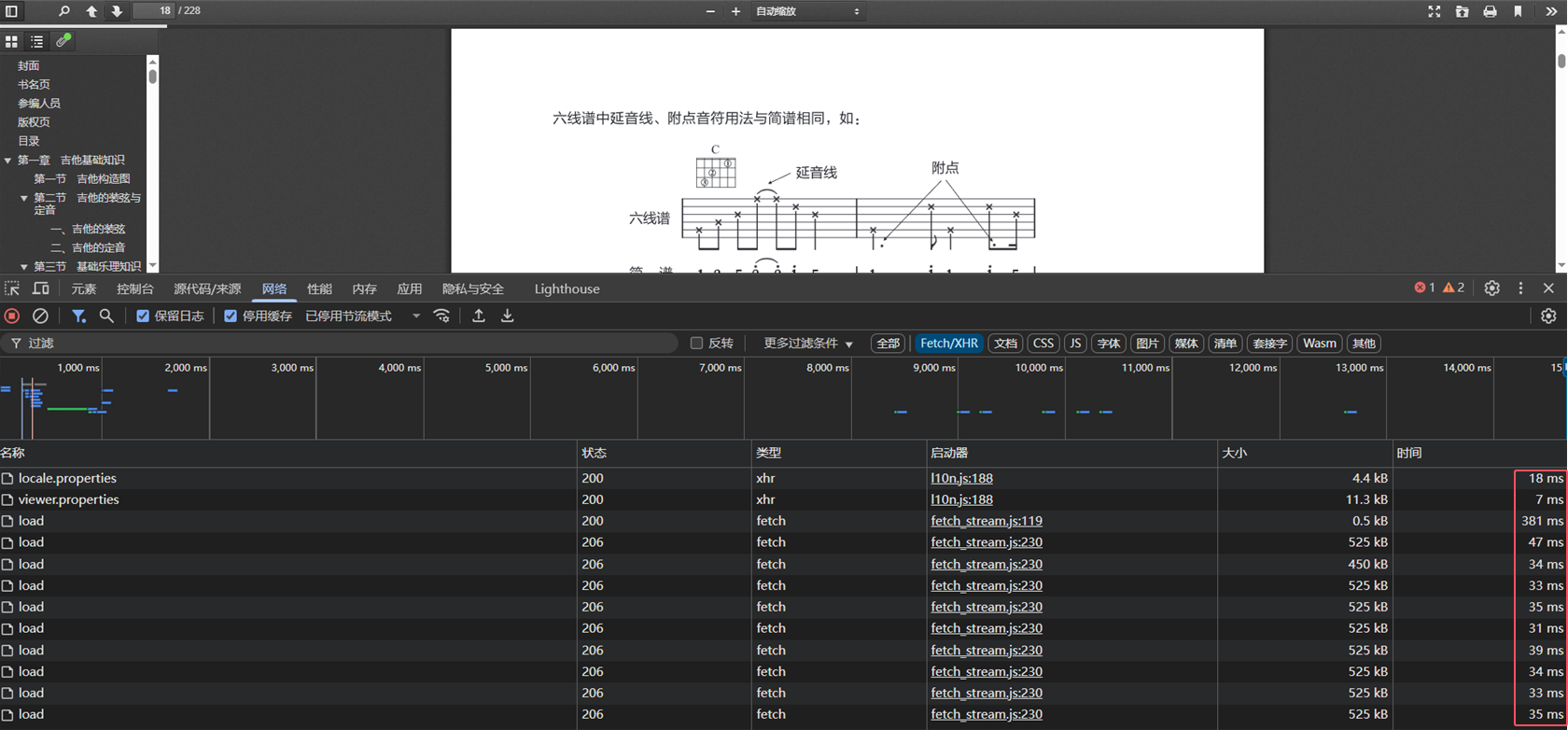
- 加载速度对比
- 六、可能会遇到的问题
- 1. app.js:2174 Uncaught (in promise) Error: file origin does not match viewer's
- 2. Expected a JavaScript module script but the server responded with a MIME type of "application/octet-stream
- 4. Uncaught TypeError: Promise.withResolvers is not a function
- 5.TypeError: pattern.at is not a function
- 6.火狐在pdf.js阅读时报错:An error occurred while loading the PDF.
- 六、可运行项目源码
- 七、参考链接
- 八、兼容性问题
**有问题可以在gitee上提issue **
前言
PDF(便携式文档格式)作为一种广泛使用的文档格式,如何在网页上高效地呈现和处理 PDF 文件,并且提升用户阅读体验是一个比较重要的课题。本文主要介绍使用PDF.js的解决方案, PDF.js 是由 Mozilla 开发的一个纯 JavaScript 库,旨在实现基于 Web 的 PDF 文件的解析和渲染。同时还会分享一些实际应用中的最佳实践和常见问题的解决方案, 来提升开发的效率和用户使用体验
本文涉及技术栈:
后端:Spring Boot、ehcache等
前端:vue、pdf.js,使用2.4.456版本 (推荐),对于常用浏览器的适配能力比较好
gitee项目地址:https://gitee.com/zhouquanstudy/pdfjs
一、实现思路与实现效果
1.1 pdf.js的分片加载的实现思路
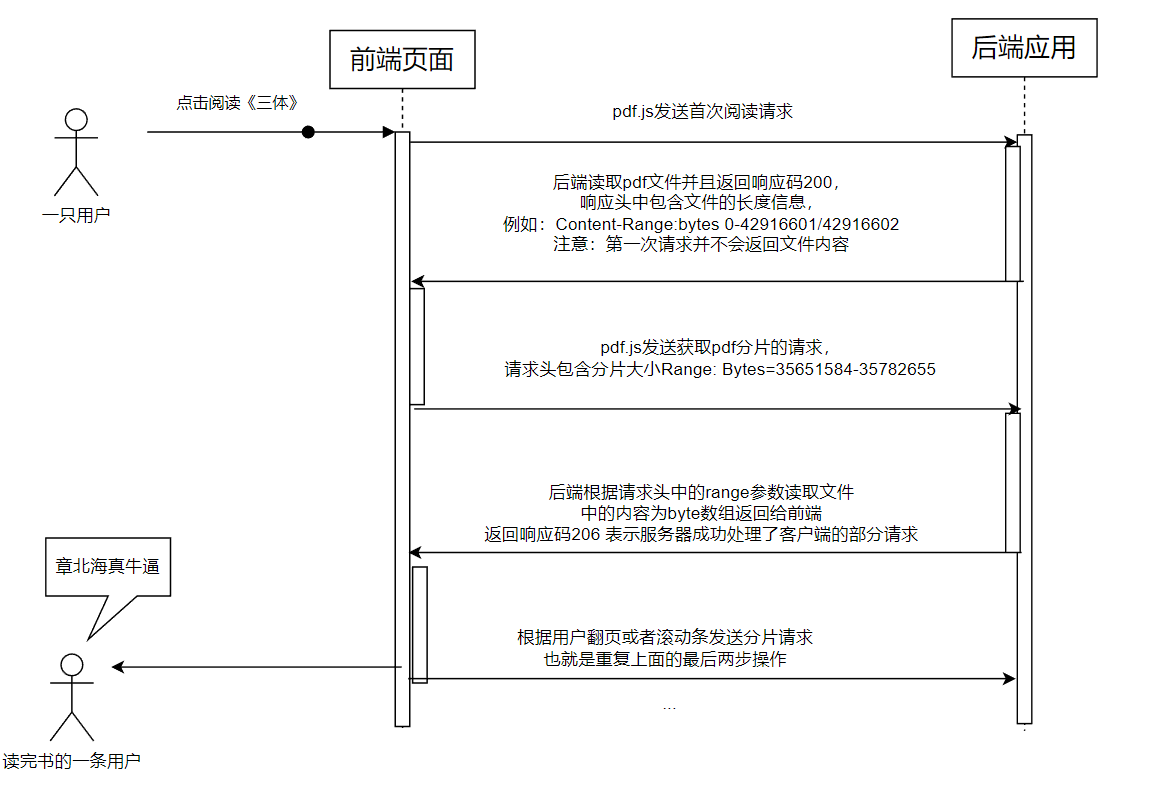
PDF.js 通过分片加载(chunked loading)技术来优化大文件的加载和渲染过程。这种技术使得用户在查看大型 PDF 文件时无需等待整个文件下载完成,从而提升了加载速度和用户体验。以下是 PDF.js 分片加载的核心实现思路:
PDF 文件分片:
- 字节范围请求:PDF.js 使用 HTTP 的 Range 请求头来请求 PDF 文件的特定字节范围。这样,浏览器可以按需下载文件的部分内容,而不是一次性下载整个文件。
- 文件头部解析:首先下载并解析 PDF 文件的头部信息,获取文件的基本结构、页数和索引信息。
动态加载:
- 按需加载页面:根据用户的操作(如翻页),PDF.js 动态请求并加载所需的页面数据。当用户滚动到未加载的页面时,发送相应的字节范围请求以获取该页面的数据。
- 并行加载:为了提升性能,PDF.js 可以并行请求多个页面的内容,减少等待时间。
实现思路流程图如下:
1.2 pdf分片加载的效果
注意观察第一次请求,响应码为200,后面的每次请求都为206 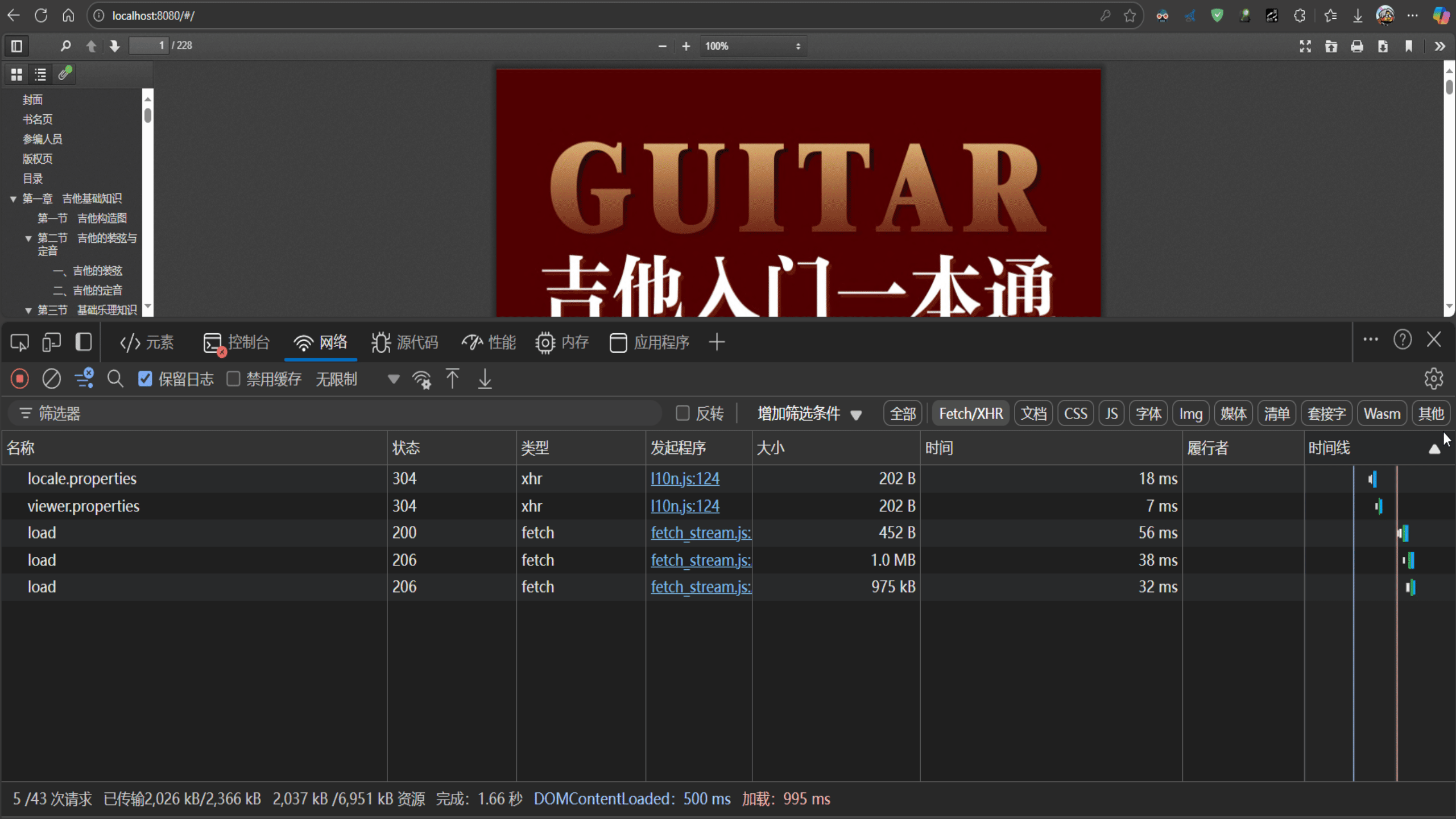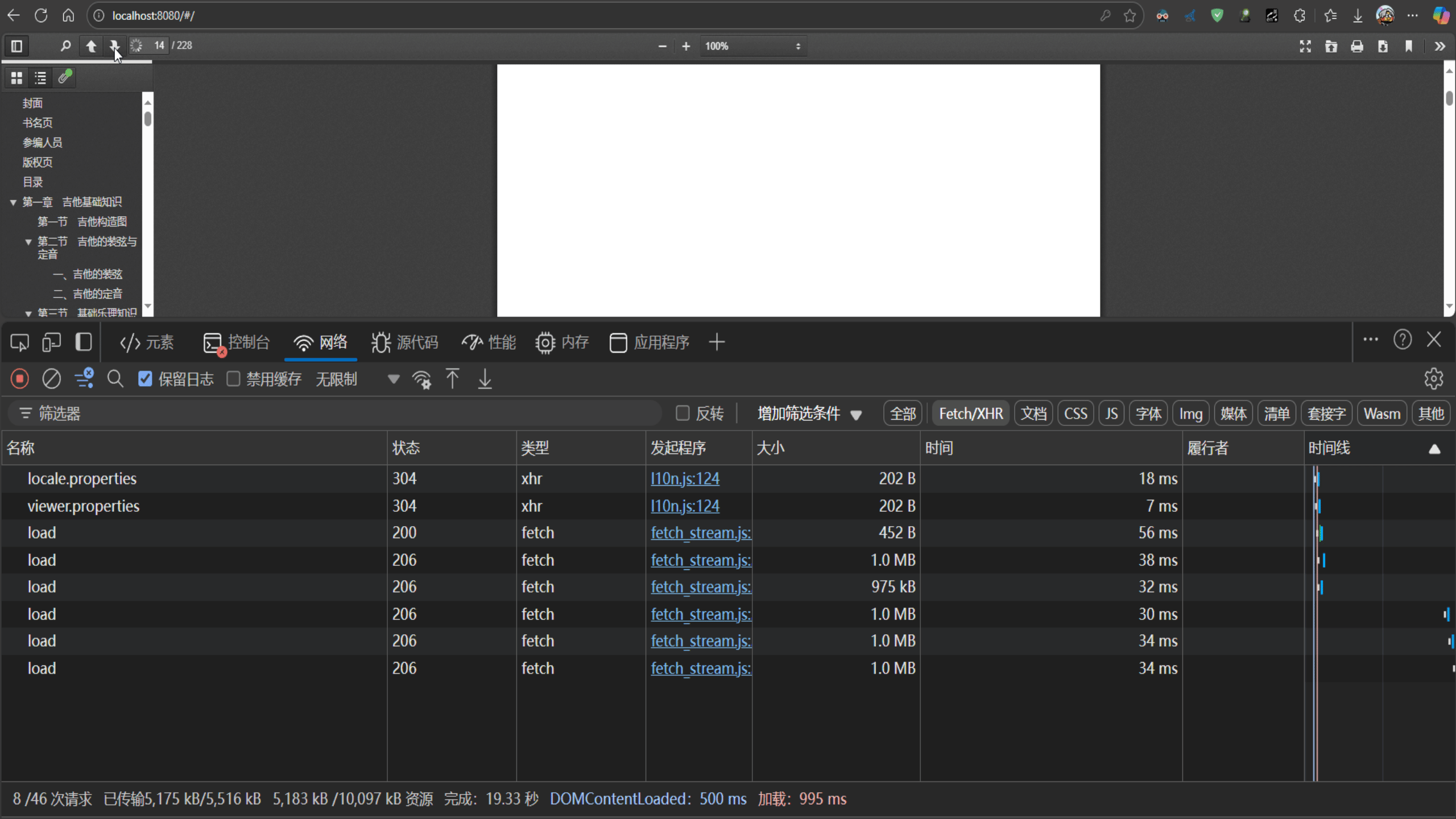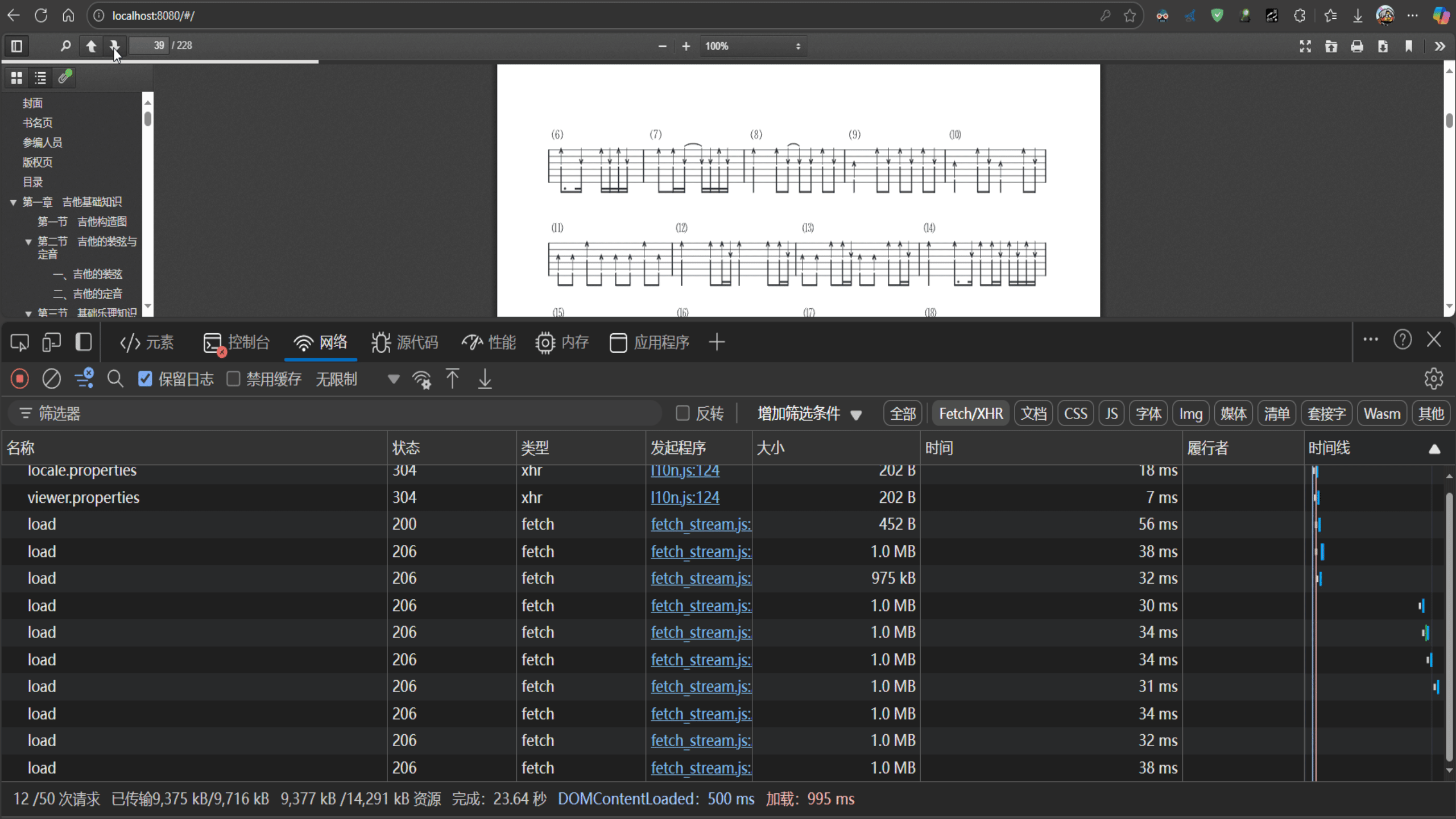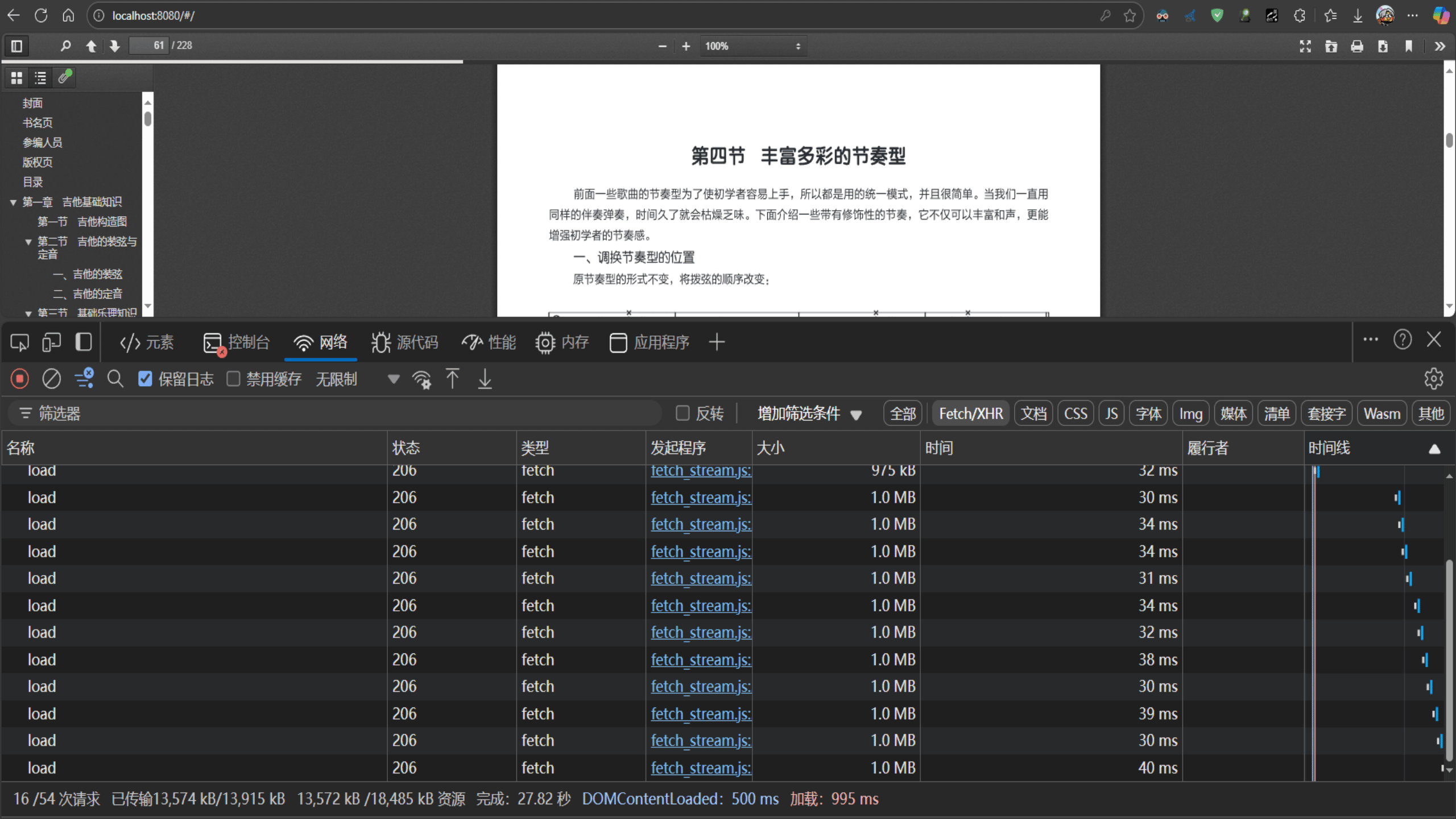
二、前端项目
vue版本:3.2.13
nodejs版本:v14.14.0
pdfjs版本:2.4.456
官方项目地址: GitHub - mozilla/pdf.js: PDF Reader in JavaScript
中文文档地址:PDF.js 中文文档 (gitcode.host)
2.1 项目引入
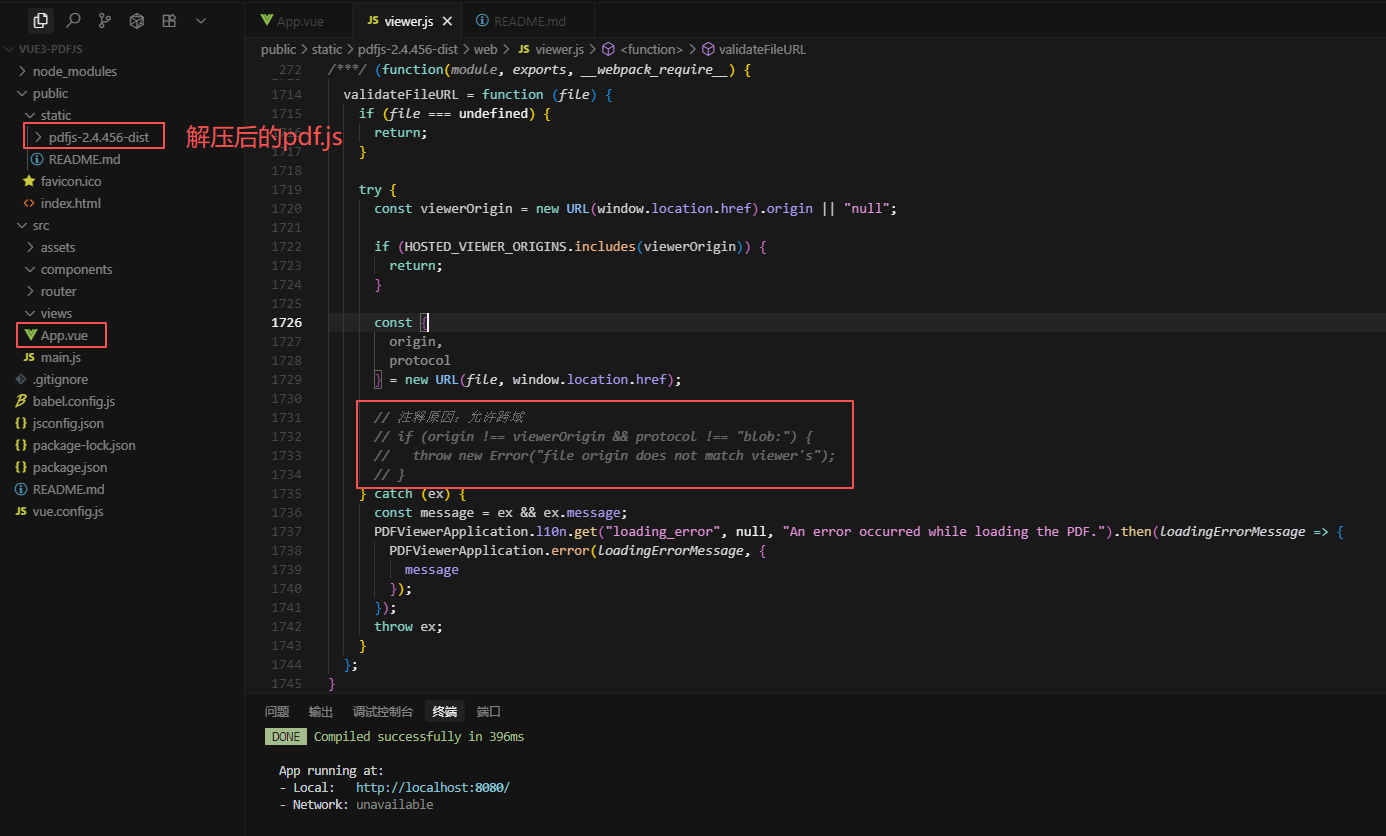
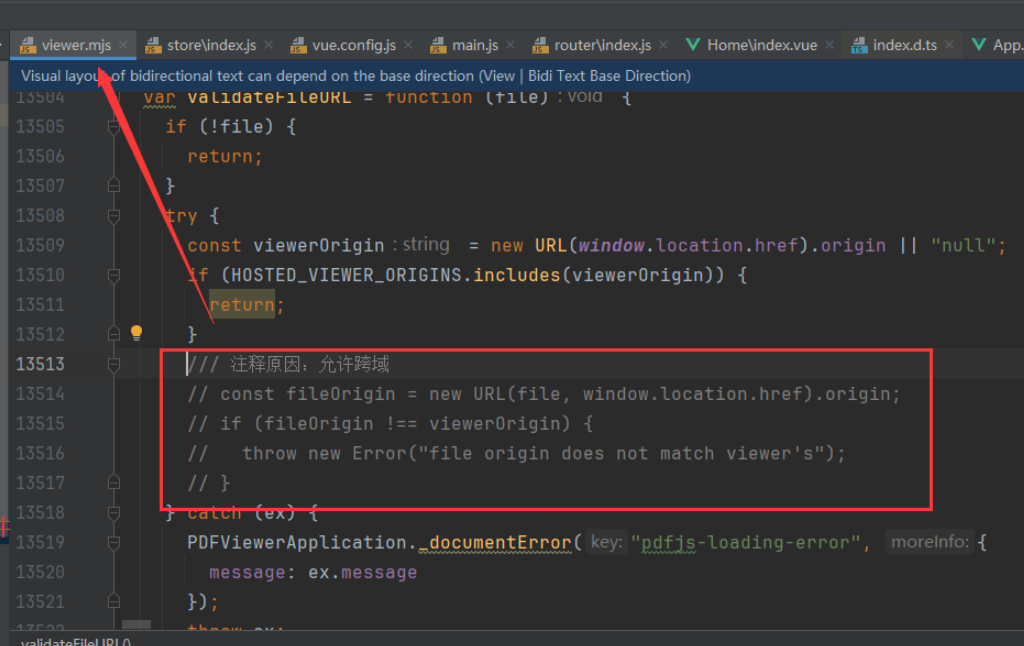
首先下载官网需要版本的zip文件,当前下载:pdfjs-2.4.456,解压后的文件引入到vue项目中,同时在viewer.mjs文件中找到下图中跨域判断位置,注释后即表明允许跨域。否则可能会有报错:
app.js:2174 Uncaught (in promise) Error: file origin does not match viewer'sat validateFileURL (app.js:2174:15)at Object.run (app.js:642:7)
配置后端接口访问路径
2.2 核心代码
App.vue
主要功能是:
-
使用iframe嵌入PDF.js的web查看器并通过URL参数传递PDF文件地址
-
使用encodeURIComponent对URL进行编码,确保特殊字符正确处理
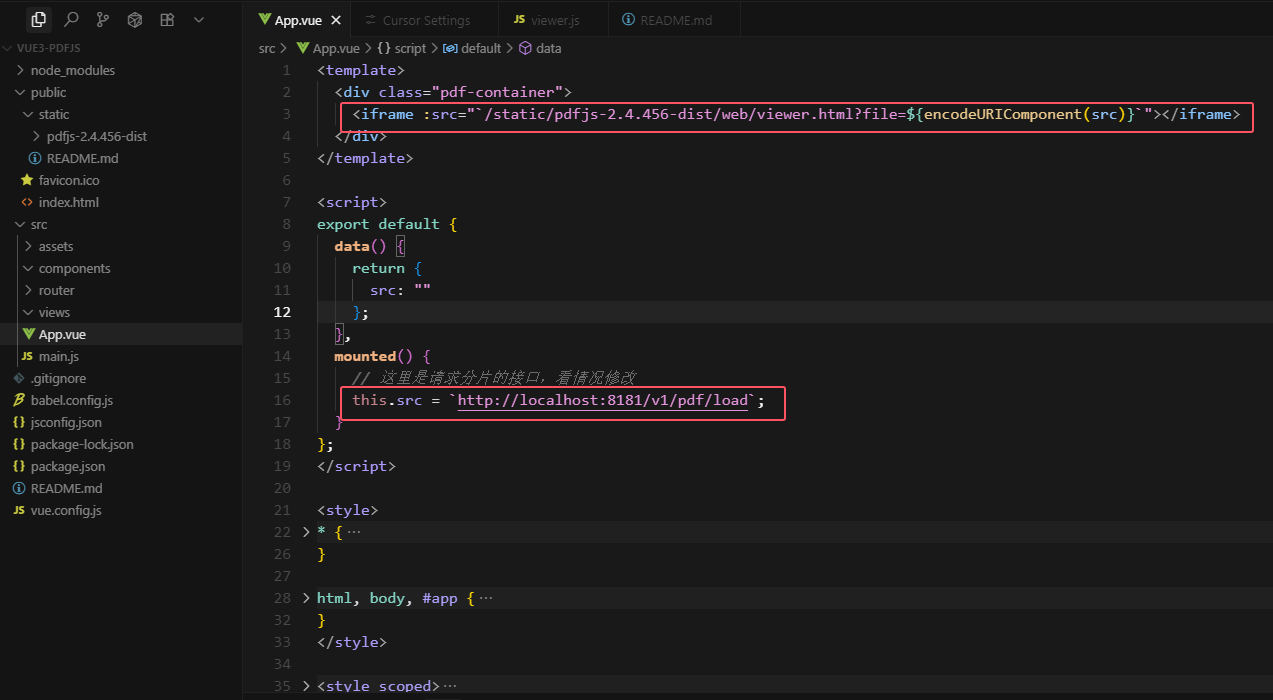
<iframe :src="`/static/pdfjs-2.4.456-dist/web/viewer.html?file=${encodeURIComponent(src)}`"></iframe> -
组件挂载时设置PDF源地址并指向本地API接口,用于获取PDF文件
mounted() {this.src = `http://localhost:8181/v1/pdf/load`; }
当组件被渲染时,它会自动从指定的 URL 加载 PDF 文件,并在页面中显示
<template><div class="pdf-container"><iframe :src="`/static/pdfjs-2.4.456-dist/web/viewer.html?file=${encodeURIComponent(src)}`"></iframe></div>
</template><script>
export default {data() {return {src: ""};},mounted() {// 这里是请求分片的接口,看情况修改this.src = `http://localhost:8181/v1/pdf/load`;}
};
</script><style>
* {margin: 0;padding: 0;box-sizing: border-box;
}html, body, #app {width: 100%;height: 100%;overflow: hidden;
}
</style><style scoped>
.pdf-container {width: 100vw;height: 100vh;
}iframe {width: 100%;height: 100%;border: none;
}
</style>2.3 项目运行
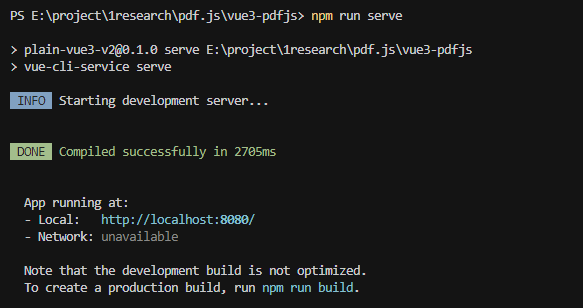
首先确保vue需要的运行环境已经安装(nodejs),使用的版本:v14.14.0,然后使用idea或者vscode打开项目,在终端输入命令:
npm install
npm run serve
三、后端项目
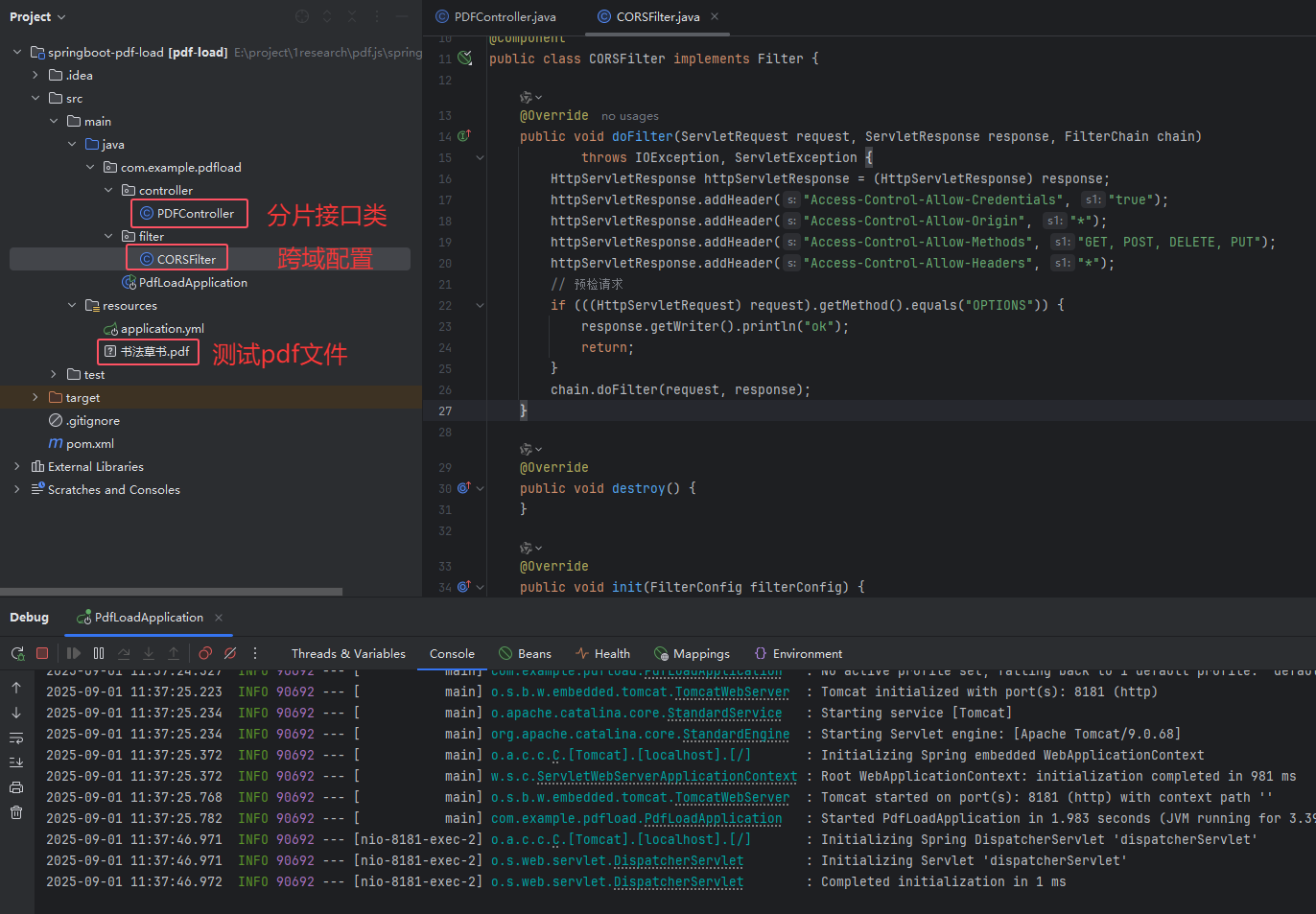
3.1 项目结构
本示例基于java8实现简单的springboot项目,核心文件PDFController.java用于分片加载接口,CORSFilter.java为跨域配置
3.2 核心代码
这段代码实现了使用 PDF.js 进行分片加载 PDF 文件的功能。下面是代码的主要实现思路:
- 首先,通过
ResourceUtils.getFile方法获取类路径下的 PDF 文件,并将其读取为字节数组pdfData。 - 然后,判断文件大小是否小于指定的阈值(1MB),如果小于阈值,则直接将整个文件作为响应返回。修改了小体积pdf小于分片大小时无法访问的bug
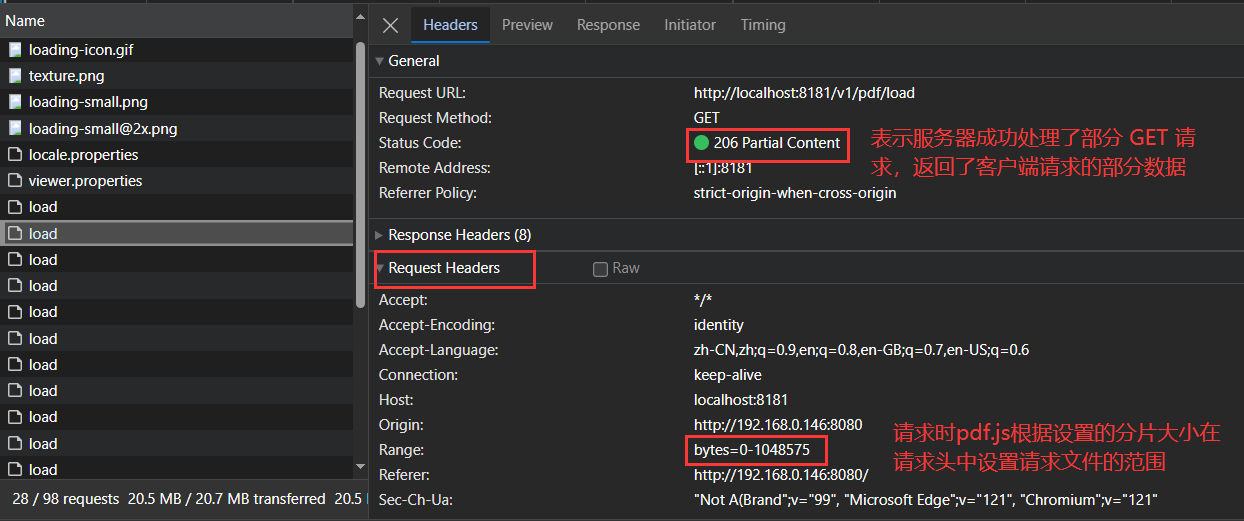
- 如果文件大小超过阈值,就根据请求头中的
Range字段判断是否为断点续传请求。 - 如果是首次请求或者没有
Range字段,则返回整个文件的字节范围,并设置响应状态为SC_OK(响应码200)。 - 如果是断点续传请求,则解析
Range字段获取请求的起始位置和结束位置,并根据这些位置从文件中读取相应的字节进行响应。 - 在响应头中设置
Accept-Ranges和Content-Range属性,告知客户端服务器支持分片加载,并指定本次返回的文件范围。 - 最后,设置响应的内容类型为
application/octet-stream,内容长度为本次返回的字节数,然后刷新输出流,将数据返回给客户端。
PDFController.java——pdf分片加载核心方法
package com.example.pdfload.controller;import org.apache.commons.io.FileUtils;
import org.springframework.util.ResourceUtils;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
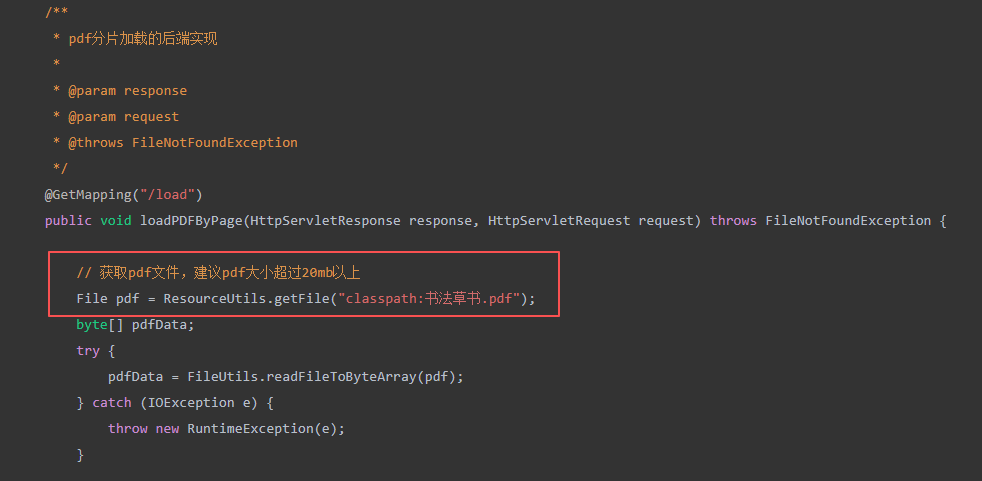
import java.io.*;/*** @author zhouquan* @description pdf分片加载* @data 2025-09-01**/
@RestController
@RequestMapping("/v1/pdf")
public class PDFController {/*** pdf分片加载的后端实现** @param response* @param request* @throws FileNotFoundException*/@GetMapping("/load")public void loadPDFByPage(HttpServletResponse response, HttpServletRequest request) throws FileNotFoundException {// 获取pdf文件,建议pdf大小超过20mb以上File pdf = ResourceUtils.getFile("classpath:书法草书.pdf");byte[] pdfData;try {pdfData = FileUtils.readFileToByteArray(pdf);} catch (IOException e) {throw new RuntimeException(e);}// 以下为pdf分片的代码try (InputStream is = new ByteArrayInputStream(pdfData);BufferedInputStream bis = new BufferedInputStream(is);OutputStream os = response.getOutputStream();BufferedOutputStream bos = new BufferedOutputStream(os)) {// 下载的字节范围int startByte, endByte, totalByte;// 获取文件总大小int fileSize = pdfData.length;int minSize = 1024 * 1024;// 如果文件小于1 MB,直接返回数据,不需要进行分片if (fileSize < minSize) {// 直接返回整个文件response.setStatus(HttpServletResponse.SC_OK);response.setContentType("application/octet-stream");response.setContentLength(fileSize);bos.write(pdfData);return;}// 根据HTTP请求头的Range字段判断是否为断点续传if (request == null || request.getHeader("range") == null) {// 如果是首次请求,返回全部字节范围 bytes 0-7285040/7285041totalByte = is.available();startByte = 0;endByte = totalByte - 1;response.setStatus(HttpServletResponse.SC_OK);// 写入一些数据到输出流中,否则火狐浏览器会报错:ns_error_net_partinal_transferbos.write(1);} else {// 断点续传逻辑String[] range = request.getHeader("range").replaceAll("[^0-9\\-]", "").split("-");// 文件总大小totalByte = is.available();// 下载起始位置startByte = Integer.parseInt(range[0]);// 下载结束位置endByte = range.length > 1 ? Integer.parseInt(range[1]) : totalByte - 1;// 跳过输入流中指定的起始位置bis.skip(startByte);// 表示服务器成功处理了部分 GET 请求,返回了客户端请求的部分数据。response.setStatus(HttpServletResponse.SC_PARTIAL_CONTENT);int bytesRead, length = endByte - startByte + 1;byte[] buffer = new byte[1024 * 64];while ((bytesRead = bis.read(buffer, 0, Math.min(buffer.length, length))) != -1 && length > 0) {bos.write(buffer, 0, bytesRead);length -= bytesRead;}}// 表明服务器支持分片加载response.setHeader("Accept-Ranges", "bytes");// Content-Range: bytes 0-65535/408244,表明此次返回的文件范围response.setHeader("Content-Range", "bytes " + startByte + "-" + endByte + "/" + totalByte);// 告知浏览器这是一个字节流,浏览器处理字节流的默认方式就是下载response.setContentType("application/octet-stream");// 表明该文件的所有字节大小response.setContentLength(endByte - startByte + 1);// 需要设置此属性,否则浏览器默认不会读取到响应头中的Accept-Ranges属性,// 因此会认为服务器端不支持分片,所以会直接全文下载response.setHeader("Access-Control-Expose-Headers", "Accept-Ranges,Content-Range");// 第一次请求直接刷新输出流,返回响应response.flushBuffer();} catch (IOException e) {e.printStackTrace();}}
}CORSFilter.java 通用的跨域配置
package com.example.pdfload.filter;import org.springframework.stereotype.Component;import javax.servlet.*;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;@Component
public class CORSFilter implements Filter {@Overridepublic void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)throws IOException, ServletException {HttpServletResponse httpServletResponse = (HttpServletResponse) response;httpServletResponse.addHeader("Access-Control-Allow-Credentials", "true");httpServletResponse.addHeader("Access-Control-Allow-Origin", "*");httpServletResponse.addHeader("Access-Control-Allow-Methods", "GET, POST, DELETE, PUT");httpServletResponse.addHeader("Access-Control-Allow-Headers", "*");// 预检请求if (((HttpServletRequest) request).getMethod().equals("OPTIONS")) {response.getWriter().println("ok");return;}chain.doFilter(request, response);}@Overridepublic void destroy() {}@Overridepublic void init(FilterConfig filterConfig) {}
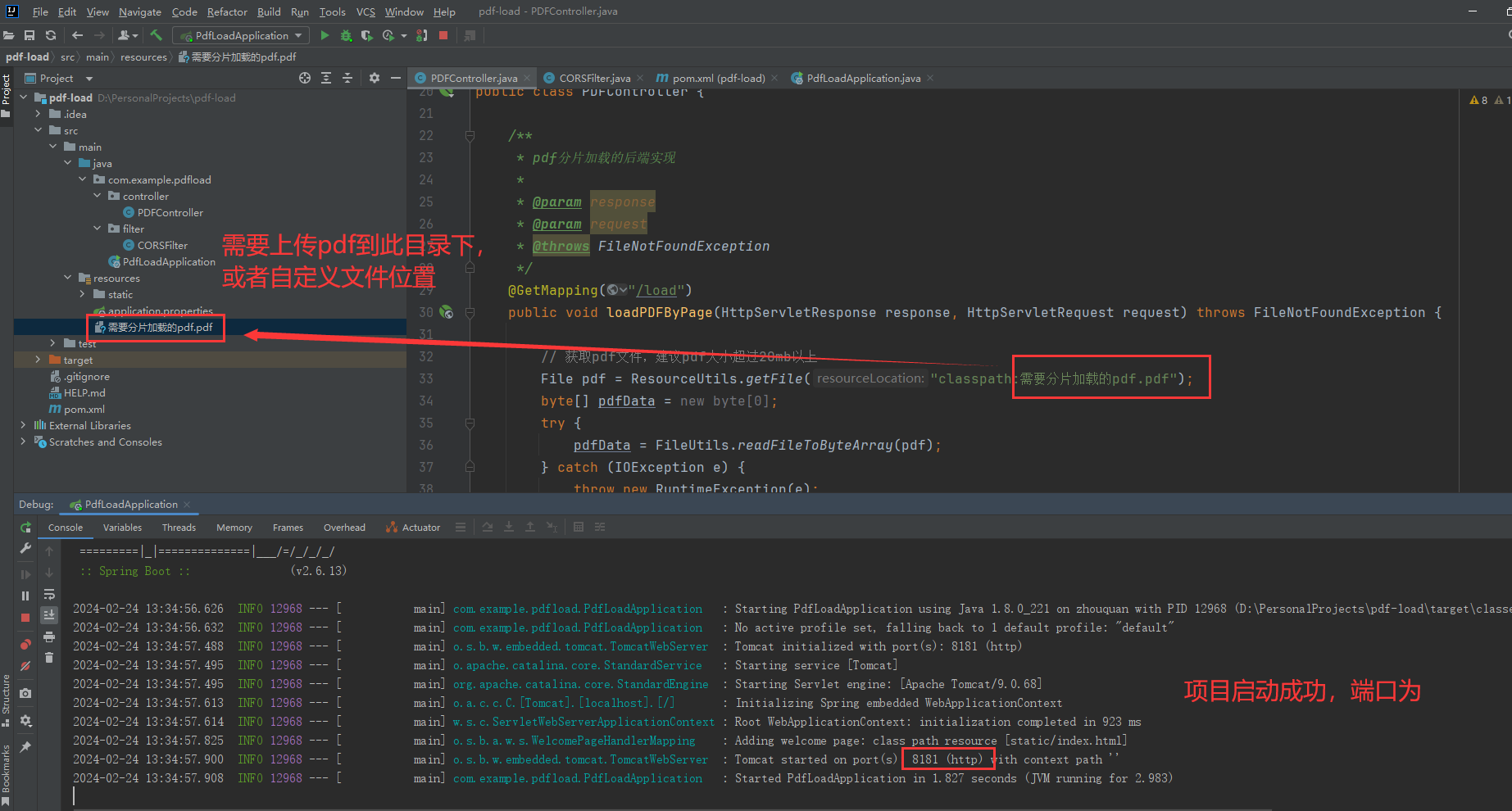
}3.3 项目运行
四、项目运行效果
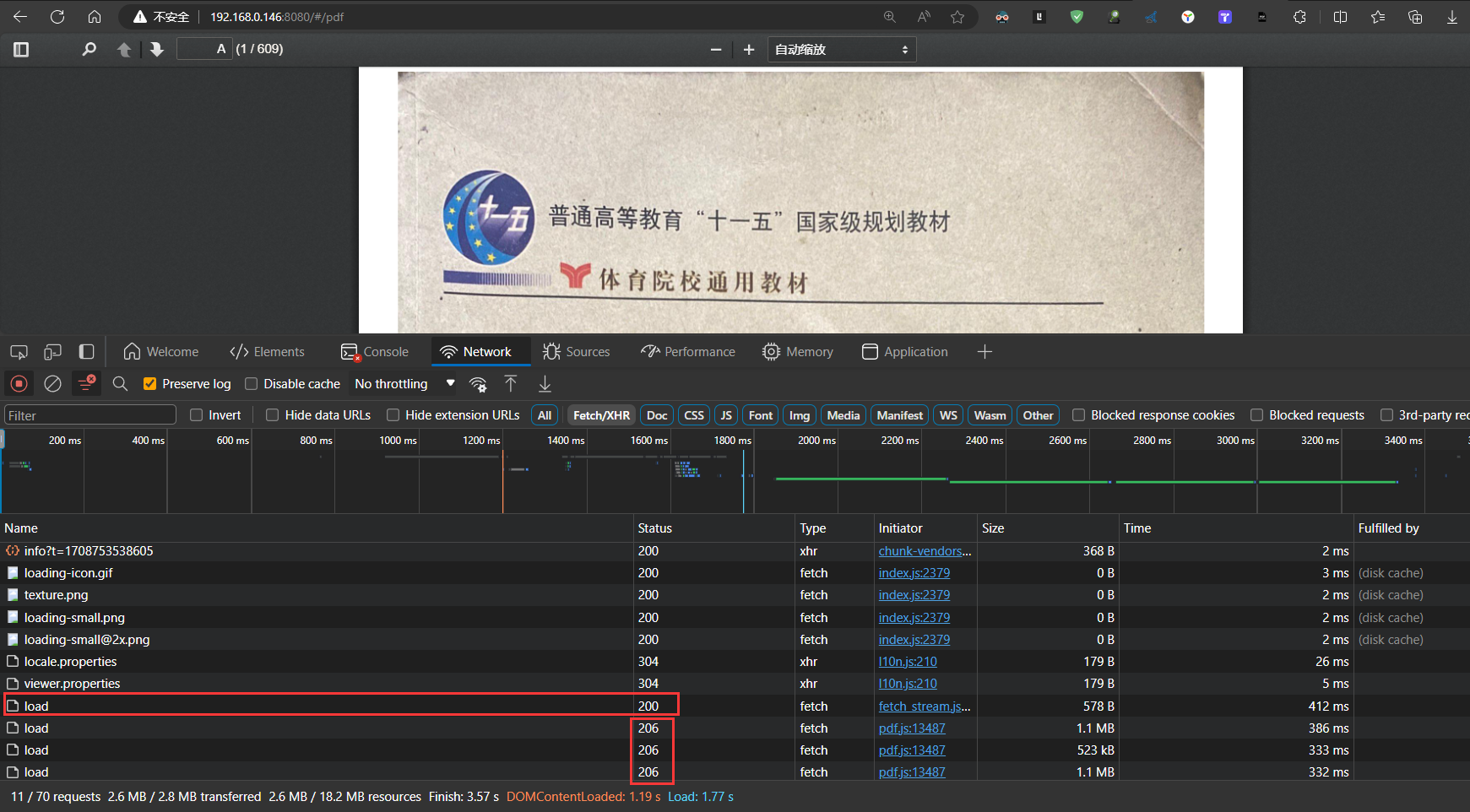
4.1 首次访问
首次访问返回状态码200,返回响应信息如下:
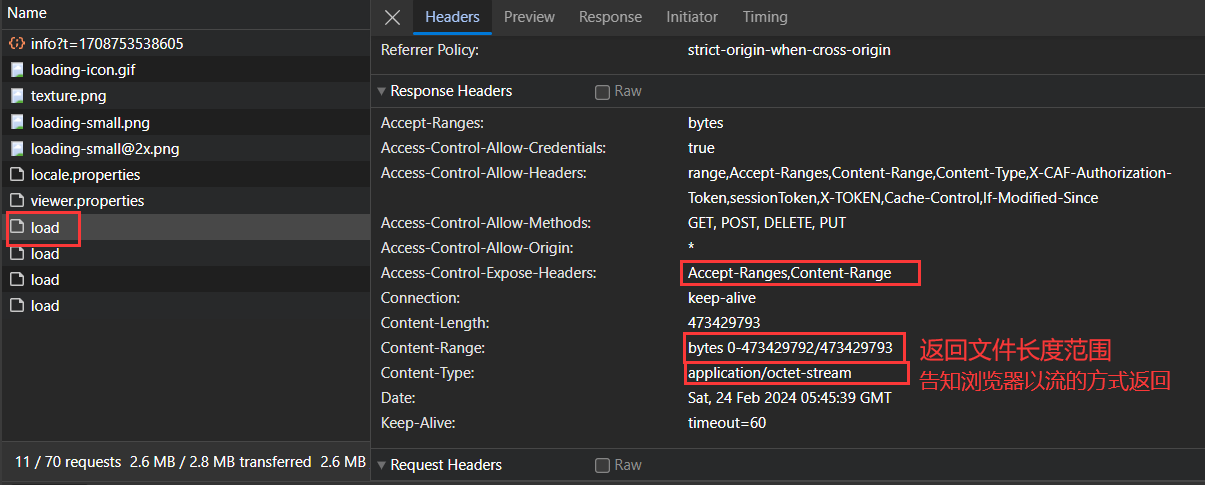
// 表明服务器支持分片加载response.setHeader("Accept-Ranges", "bytes");// Content-Range: bytes 0-65535/408244,表明此次返回的文件范围response.setHeader("Content-Range", "bytes " + startByte + "-" + endByte + "/" + totalByte);// 告知浏览器这是一个字节流,浏览器处理字节流的默认方式就是下载response.setContentType("application/octet-stream");// 表明该文件的所有字节大小response.setContentLength(endByte - startByte + 1);// 需要设置此属性,否则浏览器默认不会读取到响应头中的Accept-Ranges属性,// 因此会认为服务器端不支持分片,所以会直接全文下载response.setHeader("Access-Control-Expose-Headers", "Accept-Ranges,Content-Range");
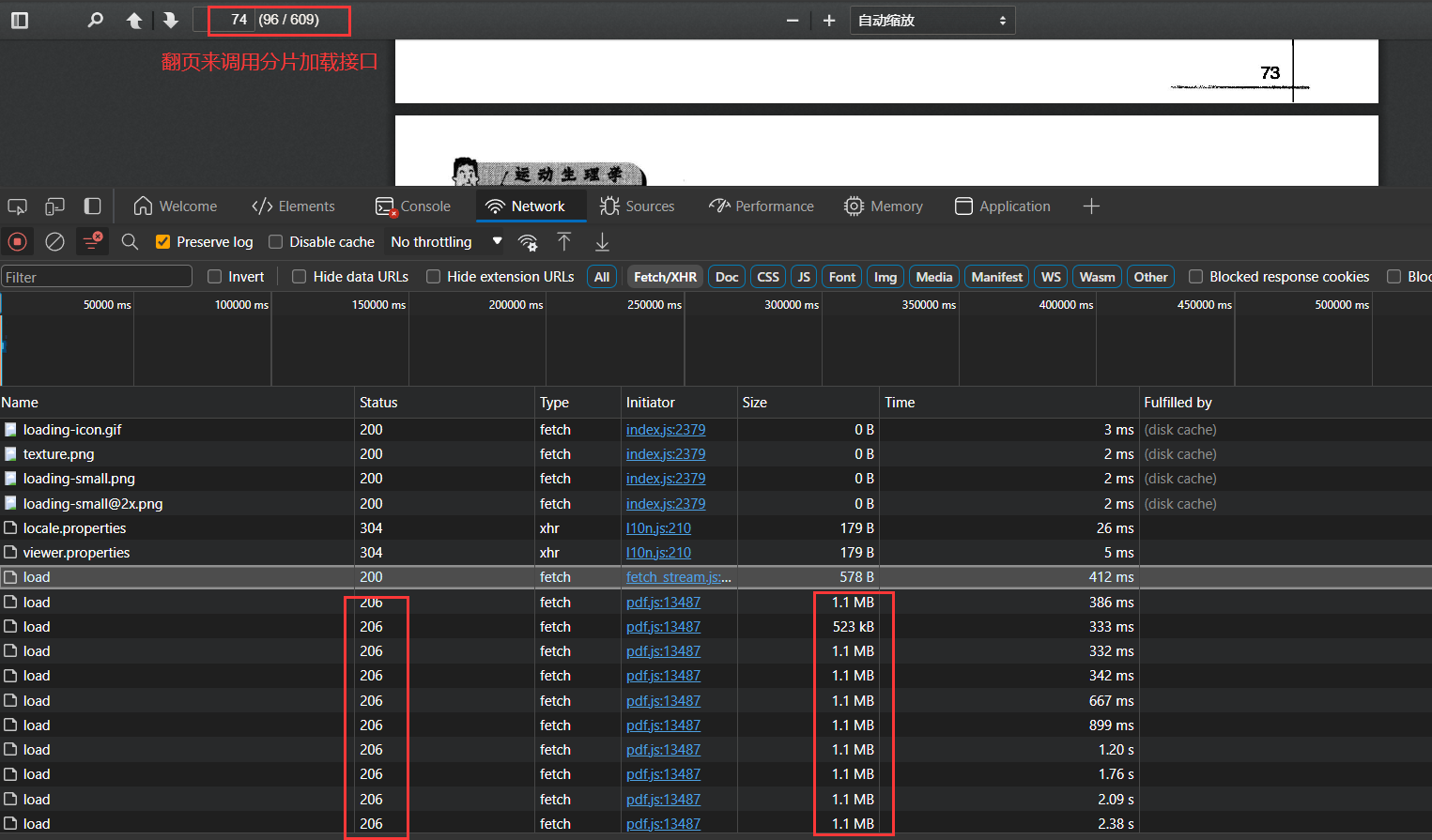
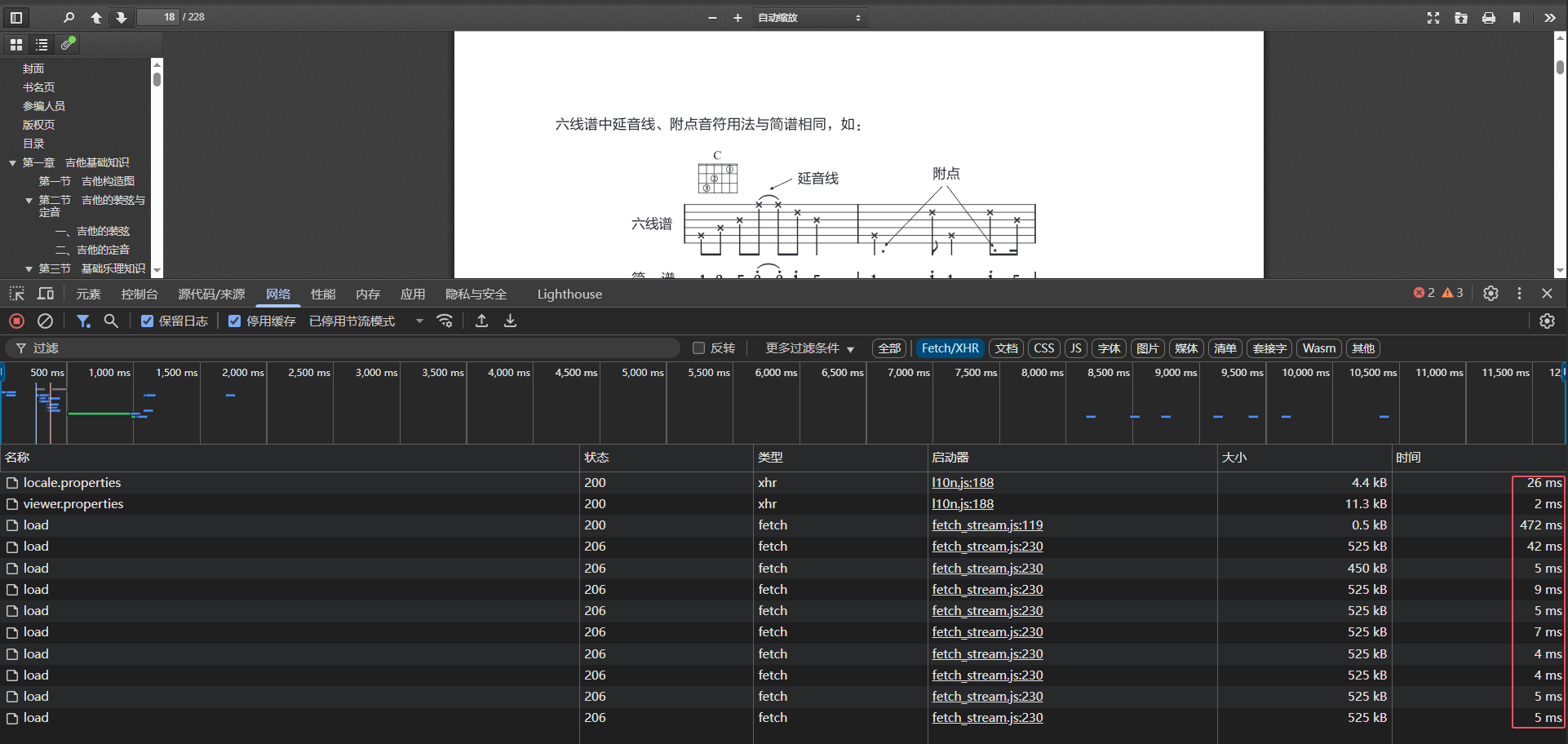
4.2 分片加载
分片加载返回状态码206,返回响应信息如下:
五、项目优化
5.1滚动条拖动导致大量请求造成流量浪费
主要问题:pdf.js拖动滚动条但是已经被拖过去的页面仍然调用后端接口
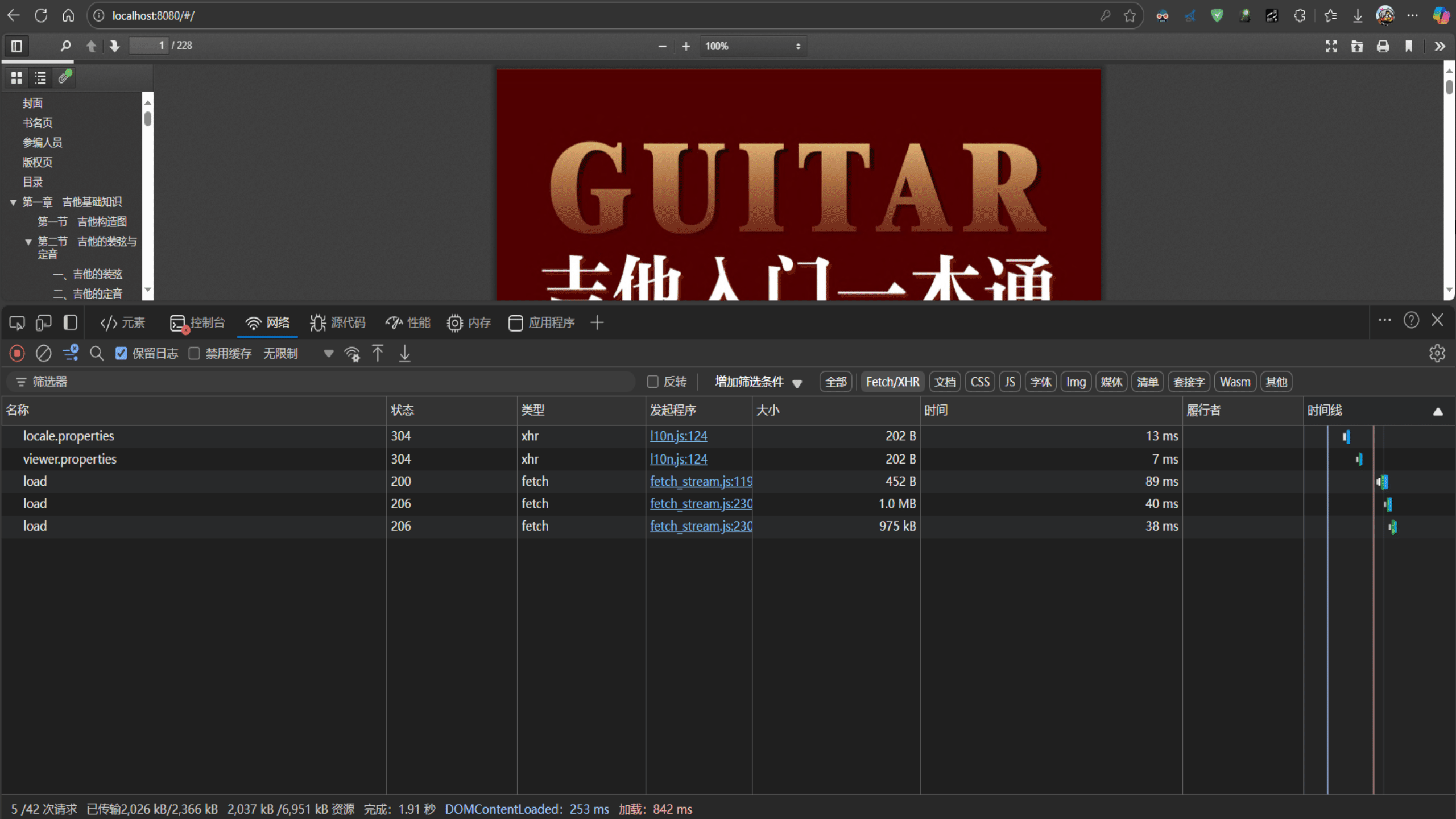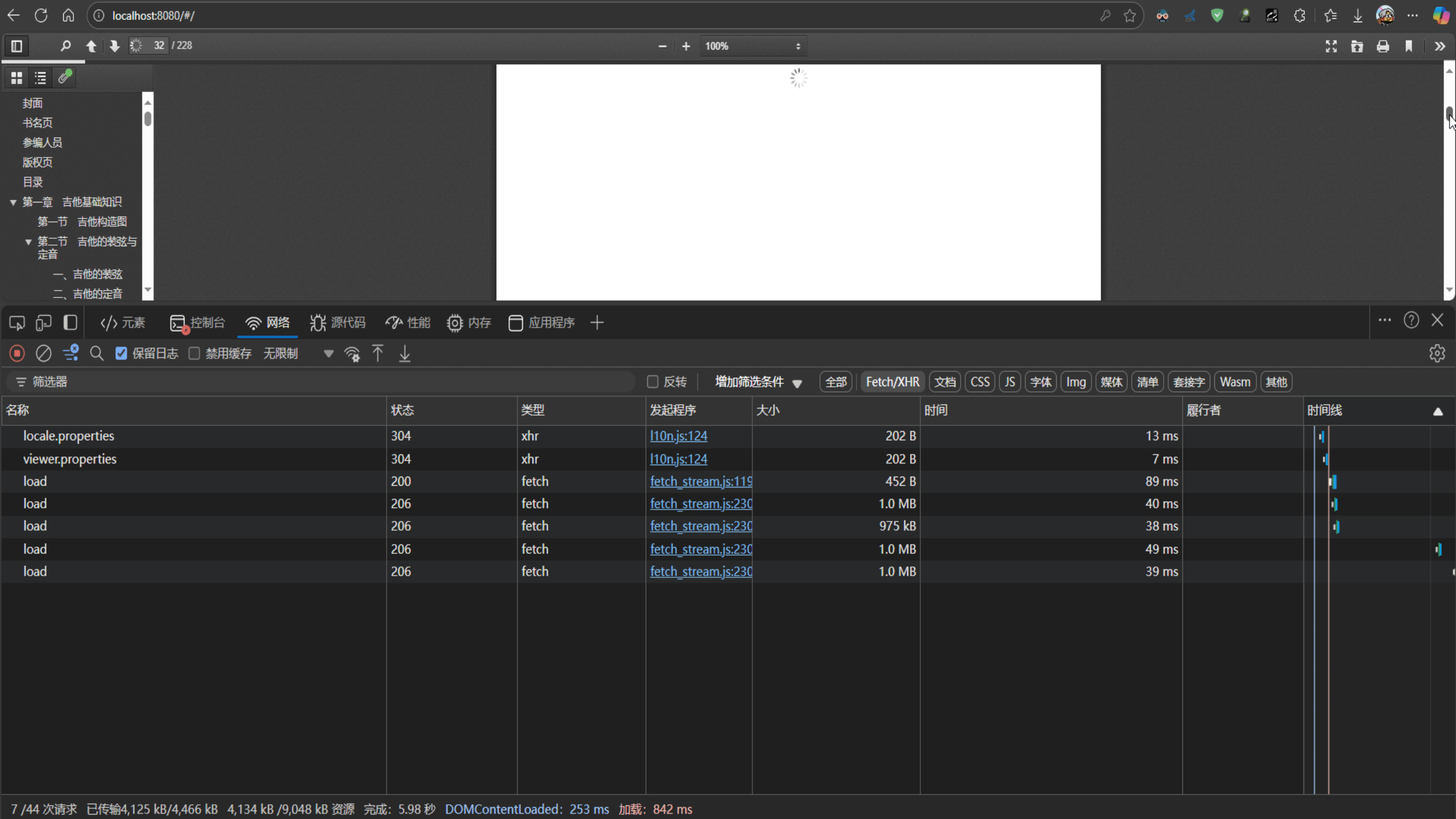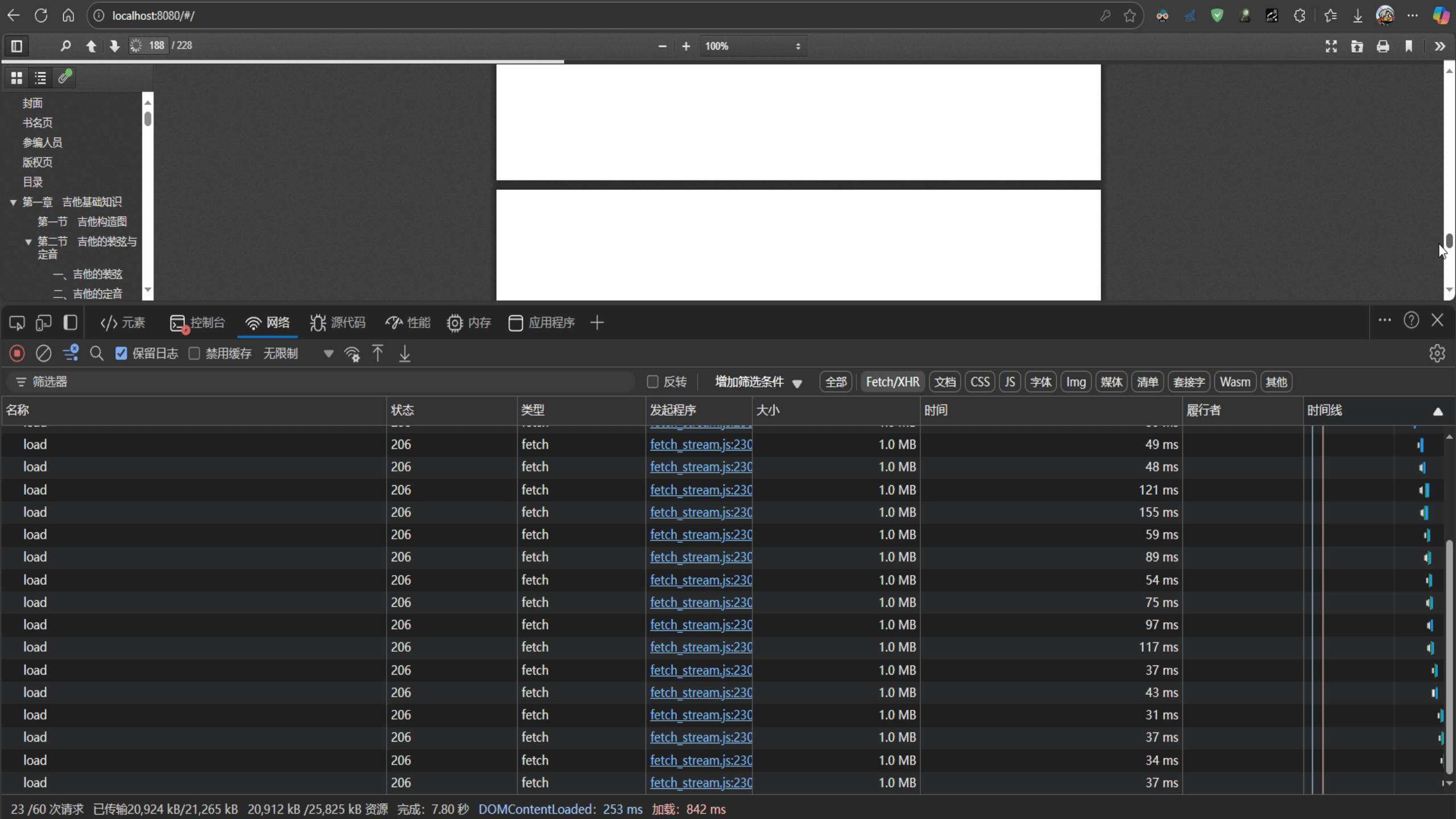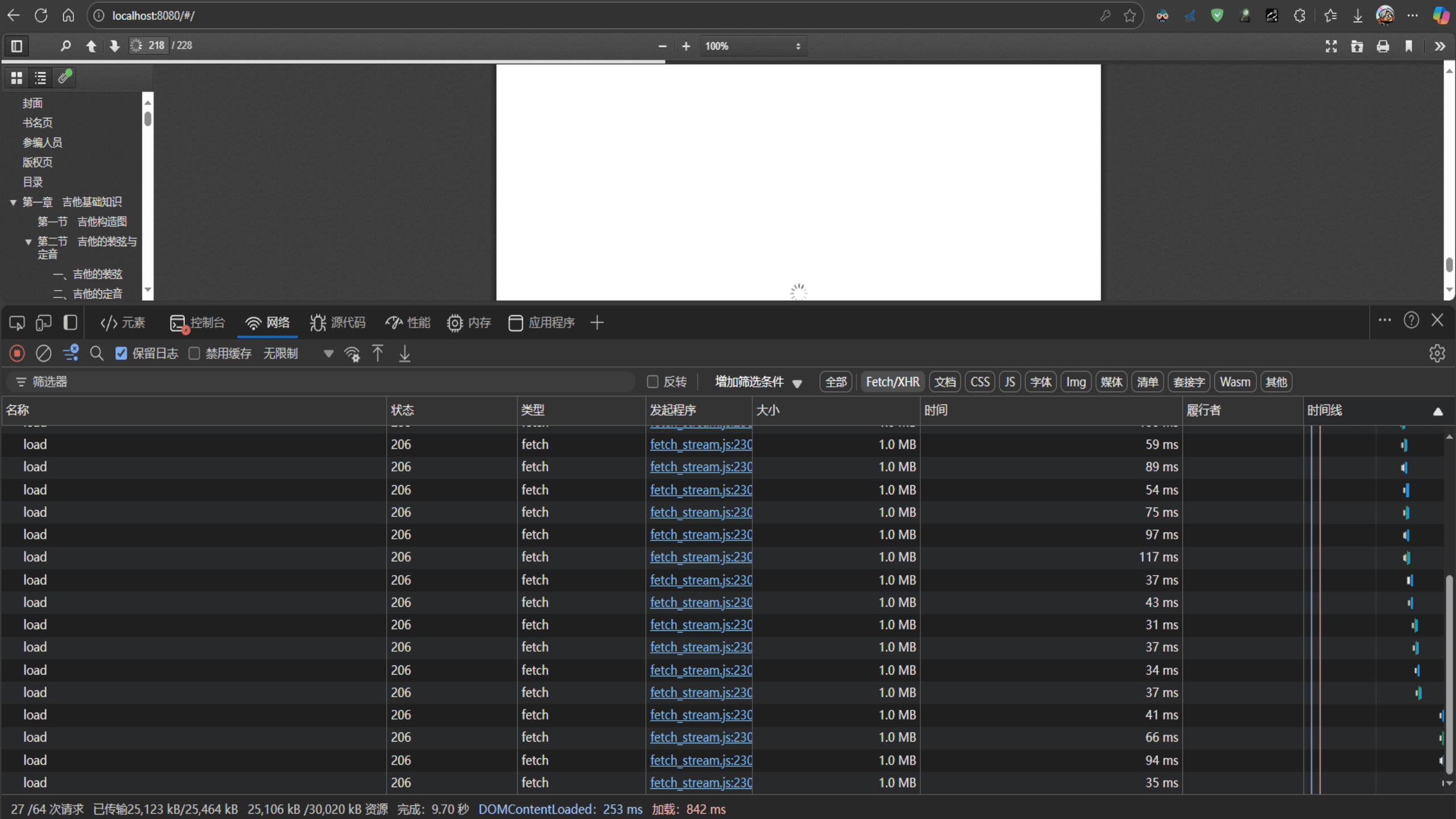
解决方案 :
通过禁用预加载机制、优化可见性检测和添加滚动防抖等方式,实现只加载当前可见区域内容的目标。
修改1:禁用预加载机制
文件位置: public/static/pdf/web/viewer.js
函数: PDFRenderingQueue.getHighestPriority()
行数: 约第4134-4146行
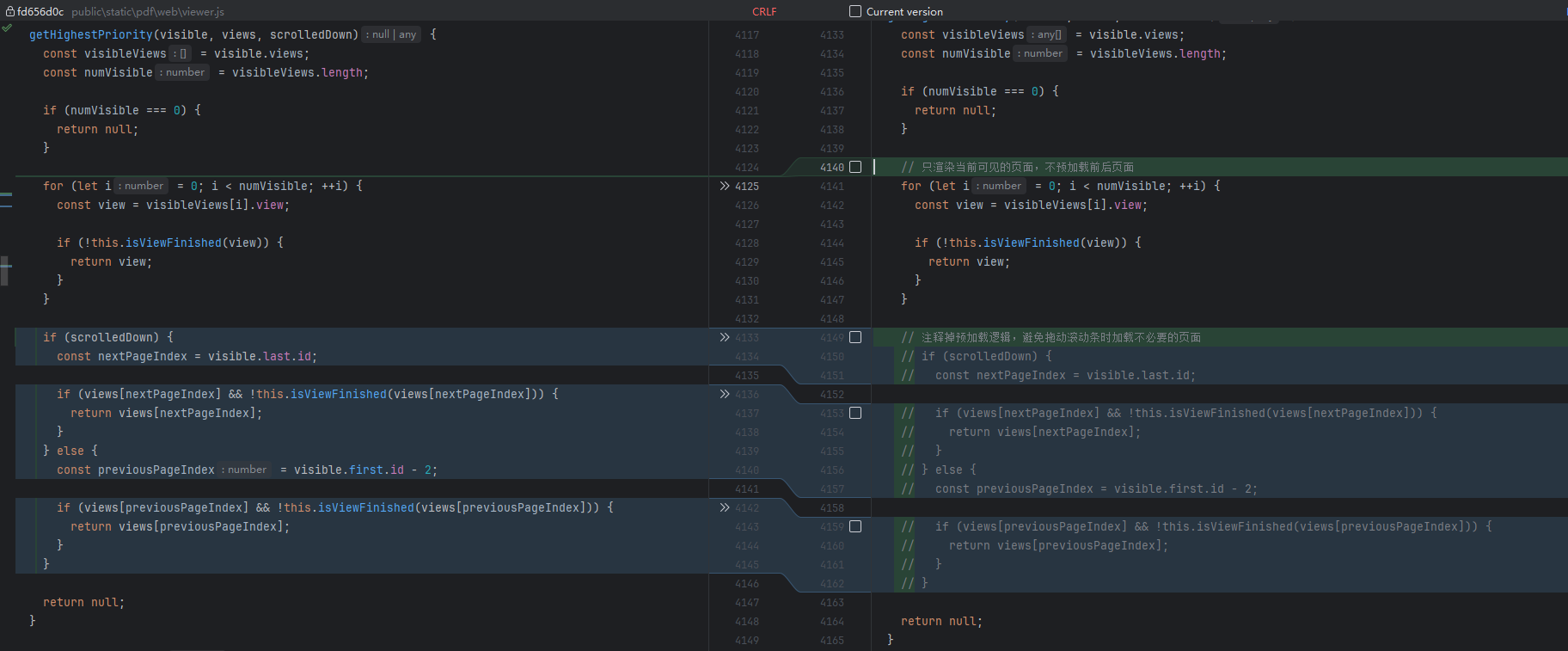
原始代码:
if (scrolledDown) {const nextPageIndex = visible.last.id;if (views[nextPageIndex] && !this.isViewFinished(views[nextPageIndex])) {return views[nextPageIndex];}
} else {const previousPageIndex = visible.first.id - 2;if (views[previousPageIndex] && !this.isViewFinished(views[previousPageIndex])) {return views[previousPageIndex];}
}
修改后代码:
// 注释掉预加载逻辑,避免拖动滚动条时加载不必要的页面
// if (scrolledDown) {
// const nextPageIndex = visible.last.id;
// if (views[nextPageIndex] && !this.isViewFinished(views[nextPageIndex])) {
// return views[nextPageIndex];
// }
// } else {
// const previousPageIndex = visible.first.id - 2;
// if (views[previousPageIndex] && !this.isViewFinished(views[previousPageIndex])) {
// return views[previousPageIndex];
// }
// }
修改作用:
- 禁用PDF.js的预加载机制
- 不再预先加载滚动方向上的下一页或上一页
- 只渲染用户当前真正需要查看的页面
修改2:优化可见性检测阈值
文件位置: public/static/pdf/web/viewer.js
函数: getVisibleElements()
行数: 约第3069-3076行
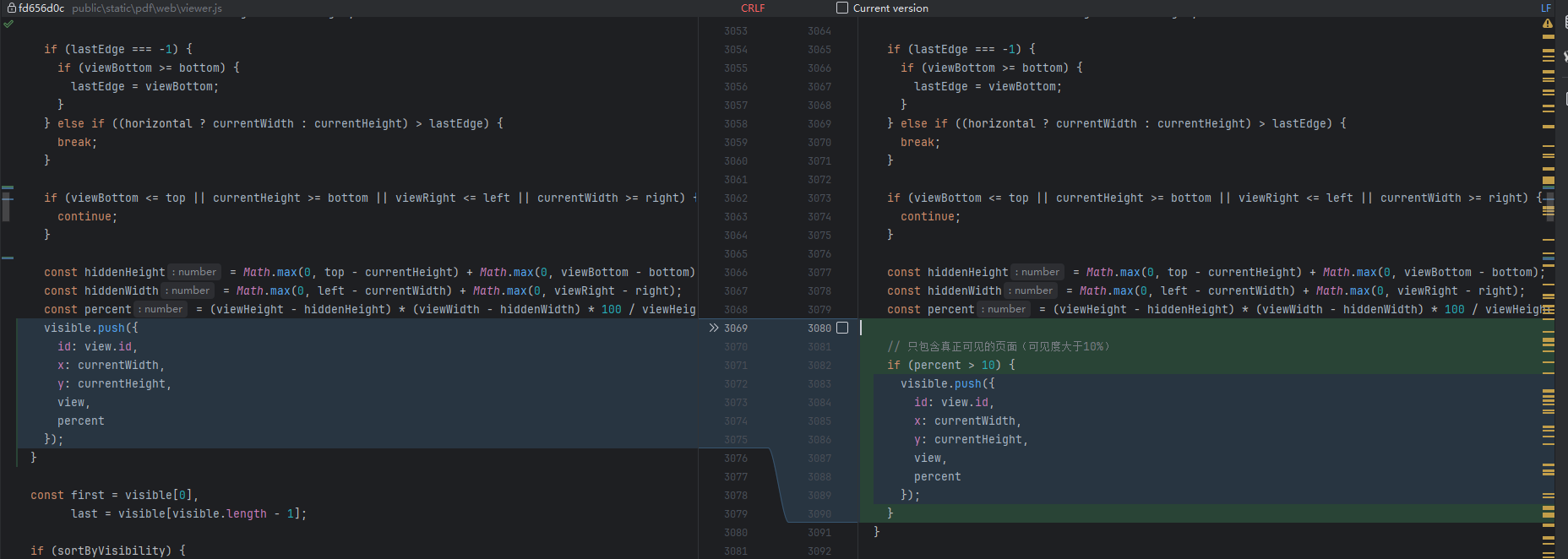
原始代码:
const percent = (viewHeight - hiddenHeight) * (viewWidth - hiddenWidth) * 100 / viewHeight / viewWidth | 0;
visible.push({id: view.id,x: currentWidth,y: currentHeight,view,percent
});
修改后代码:
const percent = (viewHeight - hiddenHeight) * (viewWidth - hiddenWidth) * 100 / viewHeight / viewWidth | 0;// 只包含真正可见的页面(可见度大于10%)
if (percent > 10) {visible.push({id: view.id,x: currentWidth,y: currentHeight,view,percent});
}
修改作用:
- 只有可见度超过10%的页面才被认为是"可见"
- 避免加载只有很小部分可见的页面
- 更精准地控制哪些页面需要被渲染
修改3:添加滚动防抖机制
文件位置: public/static/pdf/web/viewer.js
函数: watchScroll()
行数: 约第2840-2920行
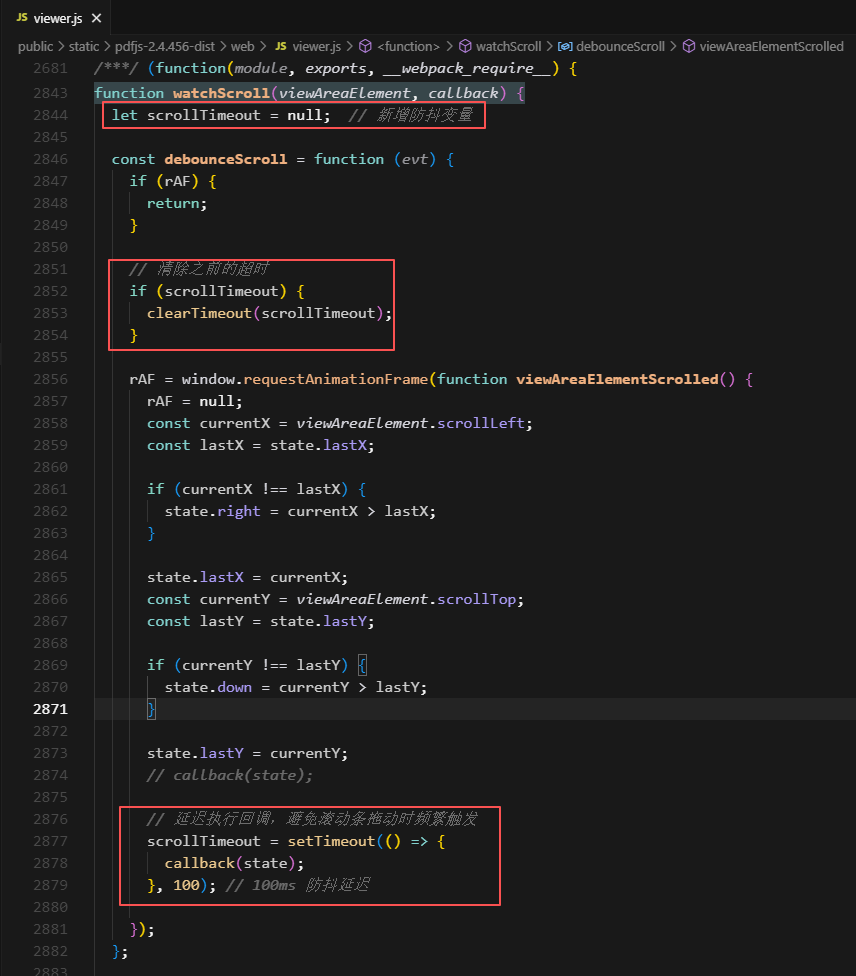
添加防抖:
function watchScroll(viewAreaElement, callback) {let scrollTimeout = null; // 新增防抖变量const debounceScroll = function (evt) {if (rAF) {return;}// 清除之前的超时if (scrollTimeout) {clearTimeout(scrollTimeout);}rAF = window.requestAnimationFrame(function viewAreaElementScrolled() {rAF = null;const currentX = viewAreaElement.scrollLeft;const lastX = state.lastX;if (currentX !== lastX) {state.right = currentX > lastX;}state.lastX = currentX;const currentY = viewAreaElement.scrollTop;const lastY = state.lastY;if (currentY !== lastY) {state.down = currentY > lastY;}state.lastY = currentY;// callback(state);// 延迟执行回调,避免滚动条拖动时频繁触发, 100ms 防抖延迟scrollTimeout = setTimeout(() => {callback(state);}, 100);});};const state = {right: true,down: true,lastX: viewAreaElement.scrollLeft,lastY: viewAreaElement.scrollTop,_eventHandler: debounceScroll};let rAF = null;viewAreaElement.addEventListener("scroll", debounceScroll, true);return state;
}
修改作用:
- 防抖延迟: 添加100ms的延迟,避免频繁触发
- 减少计算: 降低滚动时的CPU使用率
- 智能取消: 新的滚动事件会取消之前的延迟执行
可调整的参数:
-
可见性阈值 (当前: 10%)
// 在 getVisibleElements() 函数中 if (percent > 10) { // 可调整为 5, 15, 20 等 -
防抖延迟 (当前: 100ms)
// 在 watchScroll() 函数中 }, 100); // 可调整为 50, 150, 200 等 -
禁用自动加载全部
// 在默认配置中 \web\viewer.js "disableAutoFetch": true -
单次请求大小开关,默认65kb,可以根据需要设置 乘以8或16
// \build\pdf.js const DEFAULT_RANGE_CHUNK_SIZE = 65536;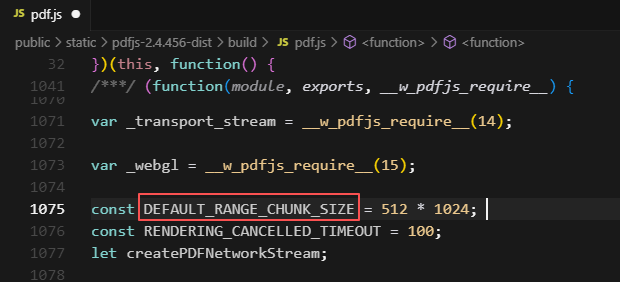
5.2 引入ehcache缓存解决pdf加载速度问题
问题描述
由于分片请求会导致此接口被频繁调用,导致大量的重复pdf被加载到内存中,导致内存占用过多同时响应速度变慢
解决方案
引入ehcache缓存等
pom.xml
<!-- Spring Boot Cache Starter -->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId>
</dependency><!-- Ehcache 3.x -->
<dependency><groupId>org.ehcache</groupId><artifactId>ehcache</artifactId><version>3.10.8</version>
</dependency><!-- JSR-107 Cache API -->
<dependency><groupId>javax.cache</groupId><artifactId>cache-api</artifactId>
</dependency>
ehcache.xml
<?xml version="1.0" encoding="UTF-8"?>
<config xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns="http://www.ehcache.org/v3"xsi:schemaLocation="http://www.ehcache.org/v3 http://www.ehcache.org/schema/ehcache-core-3.10.xsd"><!-- 磁盘存储路径配置 --><persistence directory="${java.io.tmpdir}/ehcache-pdf"/><!-- 缓存别名模板 --><cache-template name="default"><expiry><!-- 缓存过期时间:30分钟 --><ttl unit="minutes">30</ttl></expiry><resources><!-- 堆内存最多缓存10个条目 --><heap unit="entries">10</heap><!-- 堆外内存最大100MB --><offheap unit="MB">100</offheap><!-- 磁盘缓存最大500MB,当内存不足时会溢出到磁盘 --><disk unit="MB" persistent="false">500</disk></resources></cache-template><!-- PDF文件缓存配置 --><cache alias="pdfCache"><key-type>java.lang.String</key-type><value-type>[B</value-type> <!-- byte数组类型 --><expiry><!-- PDF缓存时间更长:2小时 --><ttl unit="hours">2</ttl></expiry><resources><!-- 堆内存最多缓存5个PDF --><heap unit="entries">5</heap><!-- 堆外内存最大200MB --><offheap unit="MB">200</offheap><!-- 磁盘缓存最大1GB --><disk unit="GB" persistent="false">1</disk></resources></cache></config>
application.yml
spring:cache:type: jcachejcache:config: classpath:ehcache.xmlprovider: org.ehcache.jsr107.EhcacheCachingProvider
PDFController.java
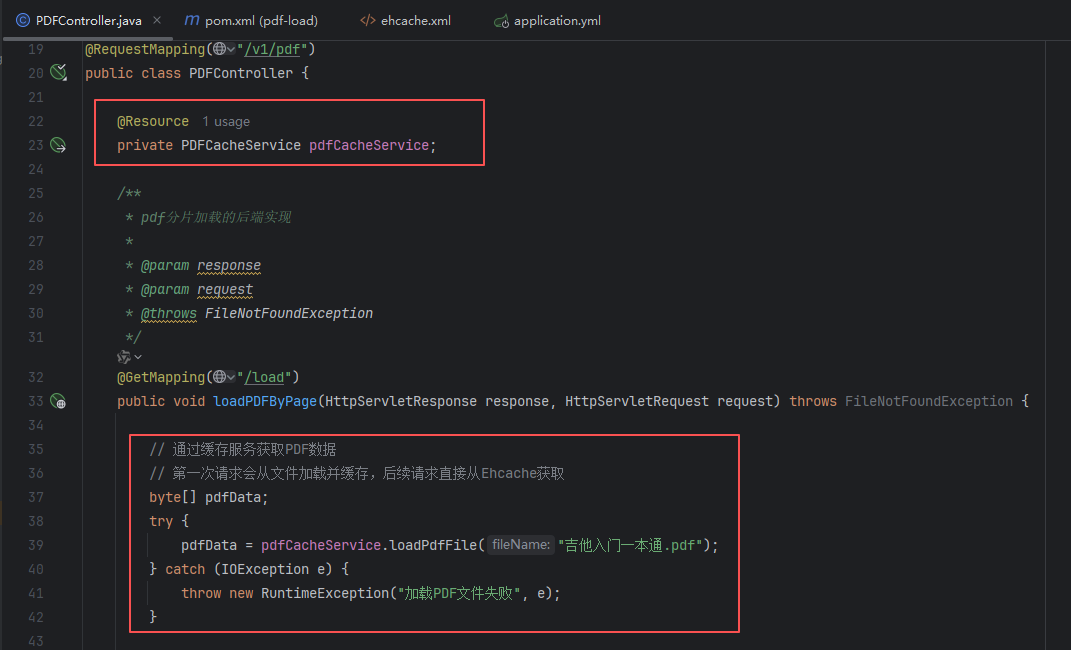
PDFCacheService.java
package com.example.pdfload.service;import org.apache.commons.io.FileUtils;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.stereotype.Service;
import org.springframework.util.ResourceUtils;import java.io.File;
import java.io.IOException;/*** PDF缓存服务* 使用Ehcache实现PDF文件的智能缓存管理*/
@Service
public class PDFCacheService {/*** 使用Spring Cache注解实现缓存* 缓存名称对应ehcache.xml中配置的"pdfCache"* * @param fileName PDF文件名* @return PDF文件字节数组* @throws IOException 文件读取异常*/@Cacheable(value = "pdfCache", key = "#fileName")public byte[] loadPdfFile(String fileName) throws IOException {// 这行日志只有在真正从文件系统加载时才会输出// 如果从缓存获取,不会执行这个方法体System.out.println("从文件系统加载PDF: " + fileName);File pdf = ResourceUtils.getFile("classpath:" + fileName);byte[] pdfData = FileUtils.readFileToByteArray(pdf);System.out.println("PDF文件大小: " + (pdfData.length / 1024 / 1024) + " MB");return pdfData;}
}
启动类:PdfLoadApplication.java
加载速度对比
六、可能会遇到的问题
1. app.js:2174 Uncaught (in promise) Error: file origin does not match viewer’s
解压后的文件引入到vue项目中,同时在viewer.mjs文件中找到下图中跨域判断位置,注释后即表明允许跨域。否则可能会有报错:
app.js:2174 Uncaught (in promise) Error: file origin does not match viewer'sat validateFileURL (app.js:2174:15)at Object.run (app.js:642:7)
2. Expected a JavaScript module script but the server responded with a MIME type of "application/octet-stream
解决 Nginx 无法识别 mjs 文件的问题
网页部署到服务器后,访问前端页面时在控制台报如下错误:
Failed to load module script: The server responded with a non-JavaScript MIME type of "application/octet-stream". Strict MIME type checking is enforced for module scripts per HTML spec.
问题分析
经过研究发现,这是由于 Nginx 无法识别 .mjs 文件,导致在 HTTP 头中错误地使用 Content-Type: application/octet-stream 来传输 .mjs 文件,从而导致浏览器认为它不是一个合法的 JavaScript 脚本
解决方案
编辑 Nginx 的 MIME types 文件,增加对 .mjs 文件的识别,解决了前端页面无法加载 .mjs 文件的问题,确保了前端页面在部署到服务器后能够正常运行
操作如下:
-
找到 Nginx 配置文件中的 MIME types 文件路径
首先,找到 Nginx 配置文件中 MIME types 文件的路径。通常为
/etc/nginx/mime.types。 -
编辑 MIME types 文件
使用以下命令编辑 MIME types 文件:
sudo vim /etc/nginx/mime.types -
修改 MIME types
在文件中找到以下行:
application/javascript js;修改为:
application/javascript js mjs; -
重新加载 Nginx 配置
保存文件并退出后,重新加载 Nginx 配置:
sudo nginx -s reload
4. Uncaught TypeError: Promise.withResolvers is not a function
uni-app预览pdf(适配多端)_promise.withresolvers is not a function-CSDN博客
降低版本:推荐选择类似以下稳定版本:
v3.11.174(当前广泛兼容版本)v3.10.111
5.TypeError: pattern.at is not a function
问题描述
PDF.js v3.11.174 在360极速浏览器等旧版浏览器中会出现以下错误:
pattern.at is not a function
Setting up fake worker failed: "Cannot read property 'WorkerMessageHandler' of undefined"
这是因为PDF.js使用了ES2022的新特性(如Array.prototype.at、Promise.withResolvers等),而旧版浏览器不支持这些特性。
解决方案:
-
降低版本,使用2.4.456版本 (推荐)
-
替换pattern.at写法为兼容写法,例如
state[pattern.at(-1)] = {checkFn,iterateFn,processFn};# 改写为state[pattern[pattern.length - 1]] = {checkFn,iterateFn,processFn };
6.火狐在pdf.js阅读时报错:An error occurred while loading the PDF.
火狐在pdf.js阅读时报错:An error occurred while loading the PDF.PDF.js v3.11.174 (build: ce8716743)
Message: NetworkError when attempting to fetch resource. app.js:1249:13
Uncaught (in promise)
Object { message: "NetworkError when attempting to fetch resource.", name: "UnknownErrorException", details: "TypeError: NetworkError when attempting to fetch resource.", stack: "BaseExceptionClosure@https://delivery.cxstar.cn/static/pdf/build/pdf.js:446:29\n__webpack_modules__<@https://delivery.cxstar.cn/static/pdf/build/pdf.js:449:2\n__w_pdfjs_require__@https://delivery.cxstar.cn/static/pdf/build/pdf.js:17849:41\n@https://delivery.cxstar.cn/static/pdf/build/pdf.js:18129:32\n@https://delivery.cxstar.cn/static/pdf/build/pdf.js:18140:3\n@https://delivery.cxstar.cn/static/pdf/build/pdf.js:18143:12\nwebpackUniversalModuleDefinition@https://delivery.cxstar.cn/static/pdf/build/pdf.js:31:50\n@https://delivery.cxstar.cn/static/pdf/build/pdf.js:32:3\n" }
https://github.com/mozilla/pdf.js/wiki/Frequently-Asked-Questions#can-i-load-a-pdf-from-another-server-cross-domain-request
解决方案:降低版本,使用2.4.456版本
六、可运行项目源码
gitee项目地址:https://gitee.com/zhouquanstudy/pdfjs
七、参考链接
- 【PDF.js】2023 最新 PDF.js 在 Vue3 中的使用-CSDN博客
- 详细|vue中使用PDF.js预览文件实践 - 掘金 (juejin.cn)
- 前端项目中使用 pdf.js 开发指南 - 掘金 (juejin.cn)
- pdf.js 常见问题
- 前端 - 移动端使用pdfjs-dist来预览pdf文件的一些坑 - 个人文章 - SegmentFault 思否
八、兼容性问题
PDFJS研究 兼容IE 360极速_pdf.js 360浏览器-CSDN博客
解决 Vue3 项目中使用 pdfjs-dist 在旧版浏览器中的兼容性问题
目前对于主流浏览器,谷歌、edge、火狐、360安全浏览器、360极速浏览器,全部兼容版本2.4.456