kafka:【1】概念关系梳理
核心数据流关系:生产者 -> 主题 -> 消费者
这是 Kafka 最核心、最顶层的关系,描述了数据的基本流向:
- 生产者 (Producer) 是数据的来源,它负责创建消息并将其发送到 Kafka。
- 主题 (Topic) 是消息的目的地。生产者总是将消息发布到特定的主题。它是一个逻辑上的分类,比如“订单主题”或“日志主题”。
- 消费者 (Consumer) 是数据的最终使用者,它订阅一个或多个主题,并从 Kafka 中拉取(Pull)消息进行处理。
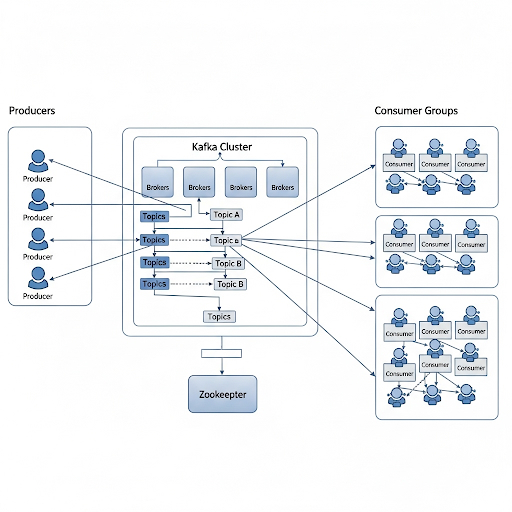
图解说明:
- 生产者 (Producers): 位于最左侧,是数据的起点。它们将消息发布到 Kafka 集群。
- Kafka 集群 (Kafka Cluster): 位于中间,由多个 代理 (Brokers) 组成。这是 Kafka 的核心,负责接收、存储和管理消息。图中展示了集群内的逻辑概念——主题 (Topics)。
- 消费者组 (Consumer Groups):- 位于最右侧,是数据的终点。组内的 消费者 (Consumers) 订阅并处理来自主题的消息。
- Zookeeper: (图中未 explicit 显示, 但在实际架构中非常重要) 负责管理和协调整个 Kafka 集群,比如选举 Leader、存储集群元数据等。
逻辑与物理的映射关系:主题、分区与代理
一个逻辑上的“主题”是如何在物理上存储和管理的呢?这就涉及到了分区和代理:
- 主题 (Topic) 与 分区 (Partition):
- 一个主题可以被分成一个或多个分区。分区是物理上的概念,是数据存储的基本单元。
- 一个主题的所有消息数据被分散存储在它的所有分区中。比如一个有3个分区的主题,它的数据就被分成了3份。
- 关键点:分区是 Kafka 实现高并发和水平扩展的核心。多个消费者可以同时消费不同分区的消息,从而极大地提高了处理能力。
- 分区 (Partition) 与 代理 (Broker):
- 代理是一台 Kafka 服务器。一个 Kafka 集群由多个代理组成。
- 每个分区都存储在某一个代理上。通过将一个主题的多个分区分布到不同的代理上,Kafka 实现了负载均衡和分布式存储。
分区内部的结构:分区、文件段与偏移量
我们再深入到单个分区的内部来看数据是如何组织的:
- 分区 (Partition) 与 文件段 (Segment File):
- 一个分区并不是一个单一的大文件,而是由多个文件段 (Segment File) 组成的。
- 当一个文件段写满后(达到一定大小或时间),Kafka 会创建一个新的文件段来写入后续消息。这种设计便于日志的清理和管理。
- 消息与偏移量 (Offset):
- 分区内的每条消息都有一个唯一的、递增的序号,称为偏移量 (Offset)。
- 偏移量保证了单个分区内的消息是严格有序的。消费者通过记录自己消费到的偏移量来跟踪消费进度。
高可用性关系:分区、副本与 ISR
为了防止代理宕机导致数据丢失,Kafka 设计了副本机制:
-
分区 (Partition) 与 副本 (Replica):
- 每个分区都可以配置多个副本,这些副本存储着完全相同的数据。
- 副本分为两种角色:
- Leader 副本:每个分区有且仅有一个 Leader。所有生产者和消费者的读写请求都由 Leader 处理。
- Follower 副本:被动地从 Leader 处同步数据。当 Leader 宕机时,会从 Follower 中选举一个新的 Leader。
- 副本被分布在不同的代理上,这样即使某台代理挂了,其他代理上的副本依然可用,保证了数据不丢失和服务的高可用性。
-
副本与 ISR (In-Sync Replicas):
- ISR 是一个动态的、与 Leader 副本保持同步的副本集合(包括 Leader 自己)。
- 只有 ISR 列表中的 Follower 才有资格被选举为新的 Leader,这确保了新选出的 Leader 拥有最完整的数据。
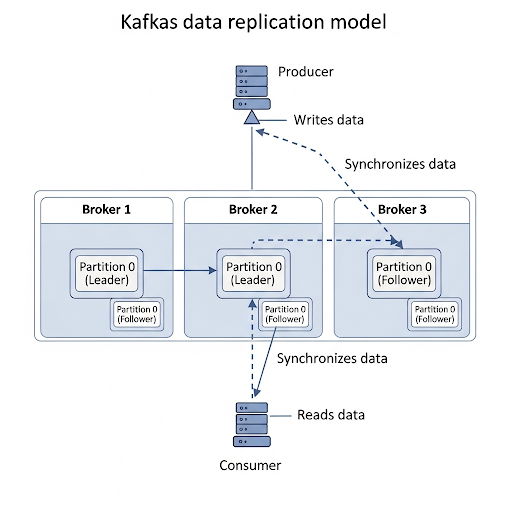
图解说明:
- 唯一写入点: 生产者和消费者的所有请求(读和写)都只发送到 Leader 副本 (位于 Broker 1)。这是 Kafka 高效读写的保证。
- 数据同步: Leader 副本负责将数据变更同步给所有的 Follower 副本 (位于 Broker 2 和 Broker 3)。图中用虚线表示了数据的复制流向。
- 故障转移 (Failover): 如果 Broker 1 宕机,Kafka 控制器 (由 Zookeeper 协调) 会从 Broker 2 或 Broker 3 的 Follower 副本中选举出一个新的 Leader,从而保证服务的持续可用性
消费模型关系:消费者、消费者组与分区
Kafka 如何让多个消费者协同工作呢?这就需要消费者组:
-
消费者 (Consumer) 与 消费者组 (Consumer Group):
- 多个消费者可以组成一个消费者组,它们共同消费一个或多个主题。
- 核心规则:一个主题的同一个分区,在任意时刻只能被同一个消费者组内的一个消费者消费。
- 这个机制保证了组内的每个消费者都能处理一部分独立的数据,从而实现了消费端的负载均衡。
-
消费者组 (Consumer Group) 与 分区 (Partition):
消费者组中消费者的数量通常不应多于它所订阅主题的分区总数。如果消费者比分区多,那么就会有消费者闲置,因为没有分区可供它消费。
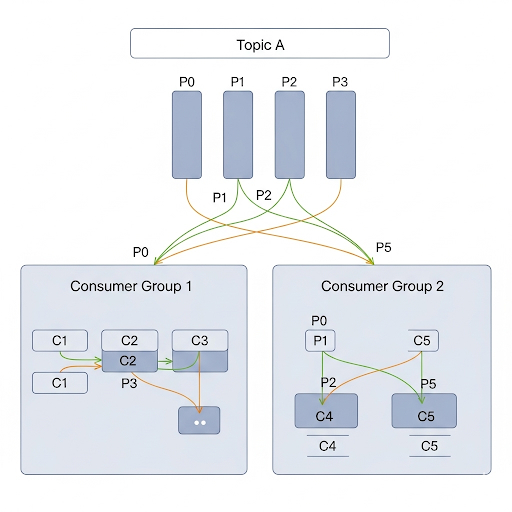
图解说明:
-
组内负载均衡 (Consumer Group 1):
- 这个消费者组有 3 个消费者来消费一个有 4 个分区的主题。
- Kafka 将分区分配给了组内的消费者。在这个例子中,消费者 C1 负责消费分区 P0 和 P1,C2 负责消费 P2,C3 负责消费 P3。
- 关键规则: 组内的每个分区只能被一个消费者处理。这保证了消息不会被重复消费,并实现了负载均衡。
-
广播消费 (Consumer Group 2): 广播消费 (消费者组 2):
- 这是一个全新的消费者组,它也订阅了同一个 “Topic A”。
- Kafka 会为这个新组独立地进行分区分配。C4 消费 P0 和 P1,C5 消费 P2 和 P3。
- 关键特性: 不同的消费者组之间互不影响,它们会各自收到主题中的全量数据。这就实现了发布-订阅 (Publish-Subscribe) 模型,一条消息可以被多个不同的应用(由不同的消费者组代表)处理。
总结关系图
我们可以用一个层次关系来总结:
- 集群 (Cluster) 由多个 代理 (Broker) 组成。
- 数据被组织成逻辑上的 主题 (Topic)。
- 一个 主题 (Topic) 被分成多个物理上的 分区 (Partition),这些分区分布在不同的 代理 (Broker) 上。
- 为了高可用,每个 分区 (Partition) 都有多个 副本 (Replica) (一个 Leader, 多个 Follower),它们也分布在不同的 代理 (Broker) 上。
- 生产者 (Producer) 将消息写入特定 主题 的 Leader 分区 中。
- 消费者 (Consumer) 组成 消费者组 (Consumer Group),从 Leader 分区 中拉取消息。一个分区只能被组内的一个消费者消费。
- 分区内的消息通过 偏移量 (Offset) 标识,并存储在 文件段 (Segment File) 中。