实现自己的AI视频监控系统-第二章-AI分析模块3(核心)
文章目录
- 前言
- 实验环境
- 一、TensorRT和cuda-python
- 1.1 简介
- 1.2 TensorRT的安装
- 1.3 安装对应的python-whl和cuda-python
- 1.3.1 trt-python安装
- 1.3.2 cuda-python安装
- 二、TensorRT-python推理测试
- 2.1 onnx模型转换TensorRT
- 2.2 tensorrt推理测试(代码)
- 2.3 TensorRT yolo11n推理测试结果
- 总结
- 下期预告
前言
在上一小节,我们实现了yolo11n模型在onnxruntime GPU版本的推理。onnxruntime提供了丰富的推理后端,可以在多种设备和类型上进行模型的快速部署,但是其核心推理表现并不优秀。本章节我们将基于专业的计算设备和推理工具进一步提高模型分析的帧率和性能。
实验环境
- OS : windows10
- GPU: RTX 3080
- CPU: I5-12490F
- CUDNN: 11.6
一、TensorRT和cuda-python
1.1 简介
ONNX Runtime 作为一个通用的推理引擎,其优势在于兼容性,它能够运行来自不同训练框架(PyTorch, TensorFlow等)转换而来的 ONNX 模型。然而,为了追求极致的性能,我们通常需要针对特定的硬件平台(尤其是 NVIDIA GPU)进行深度优化。NVIDIA 的 TensorRT 正是为此而生的高性能深度学习推理 SDK。
-
为什么选择 TensorRT?
TensorRT 的核心优势在于其优化能力,它通过一系列技术手段来最大限度地提高推理的吞吐量和降低延迟:-
层与张量融合(Layer & Tensor Fusion): TensorRT 会分析计算图,将多个层(如卷积、偏置加法、激活函数)合并成一个更复杂的单一内核(Kernel)。这显著减少了内核启动的次数以及 GPU 内存的读写操作,从而大幅提升效率。
-
精度校准(Precision Calibration): 大多数模型训练时采用 FP32 精度。TensorRT 可以在保证精度损失极小的情况下,将模型量化为 FP16 甚至 INT8 精度。INT8 量化使用量化感知训练(QAT)或训练后量化(PTQ)技术,能将模型大小减至原来的 1/4,并极大提升计算速度,尤其利于 Tensor Core 的计算。
-
内核自动调优(Kernel Auto-Tuning): 对于某一层操作(如卷积),可能存在多种实现算法。TensorRT 会根据目标 GPU 的架构(如 Ampere, Ada Lovelace)、输入大小和批次大小(Batch Size),自动选择最优的内核实现。
-
动态张量内存(Dynamic Tensor Memory): TensorRT 会为每个张量分配所需的最小内存,并重用内存以避免昂贵的分配操作,优化内存占用和提高效率。
-
多流执行(Multi-Stream Execution): 轻松设置多个推理流(Streams)来处理并行输入,充分利用现代 GPU 的并行计算能力。
-
-
TensorRT 的工作流程
使用 TensorRT 部署一个模型通常包含两个阶段:-
构建阶段(Build Phase): 此阶段将模型(如 ONNX)转换为 TensorRT 的优化表示,这个表示称为 TensorRT 引擎(Engine)。构建过程会执行上述的所有优化操作,耗时较长,因此通常只需执行一次。生成的引擎文件可以序列化到磁盘(.plan 或 .engine 后缀)以供后续使用。
-
部署阶段(Deployment Phase): 此阶段加载序列化后的引擎文件,创建推理上下文(Context),并执行实际的推理任务。该阶段非常高效。
-
-
CUDA Python:与 GPU 交互的桥梁
虽然 TensorRT 的 Python API (tensorrt) 隐藏了底层许多复杂的 CUDA 操作,但在高性能推理流水线中,我们仍然需要直接与 GPU 内存打交道,以实现:-
在 CPU(主机)内存和 GPU(设备)内存之间高效地拷贝输入和输出数据。
-
管理 GPU 上的内存分配和释放。
-
必要时,编写自定义的 CUDA 内核以实现特殊操作。
-
原生的 CUDA C++ API 性能最好,但在 Python 环境中使用不便。cuda-python 包提供了 Python 包装层,它几乎提供了所有 CUDA Runtime API 的功能,使得我们能够在 Python 中直接进行精细的 GPU 内存和执行管理,代码更简洁,集成更顺畅。
1.2 TensorRT的安装
截至目前,最新版本的TRT已经发布到TRT10,点击链接即可跳转下载页面,但是需要先注册登录nvidia账户。
- 下载自己系统对应的版本(本机系统win10、cudnn11.6)
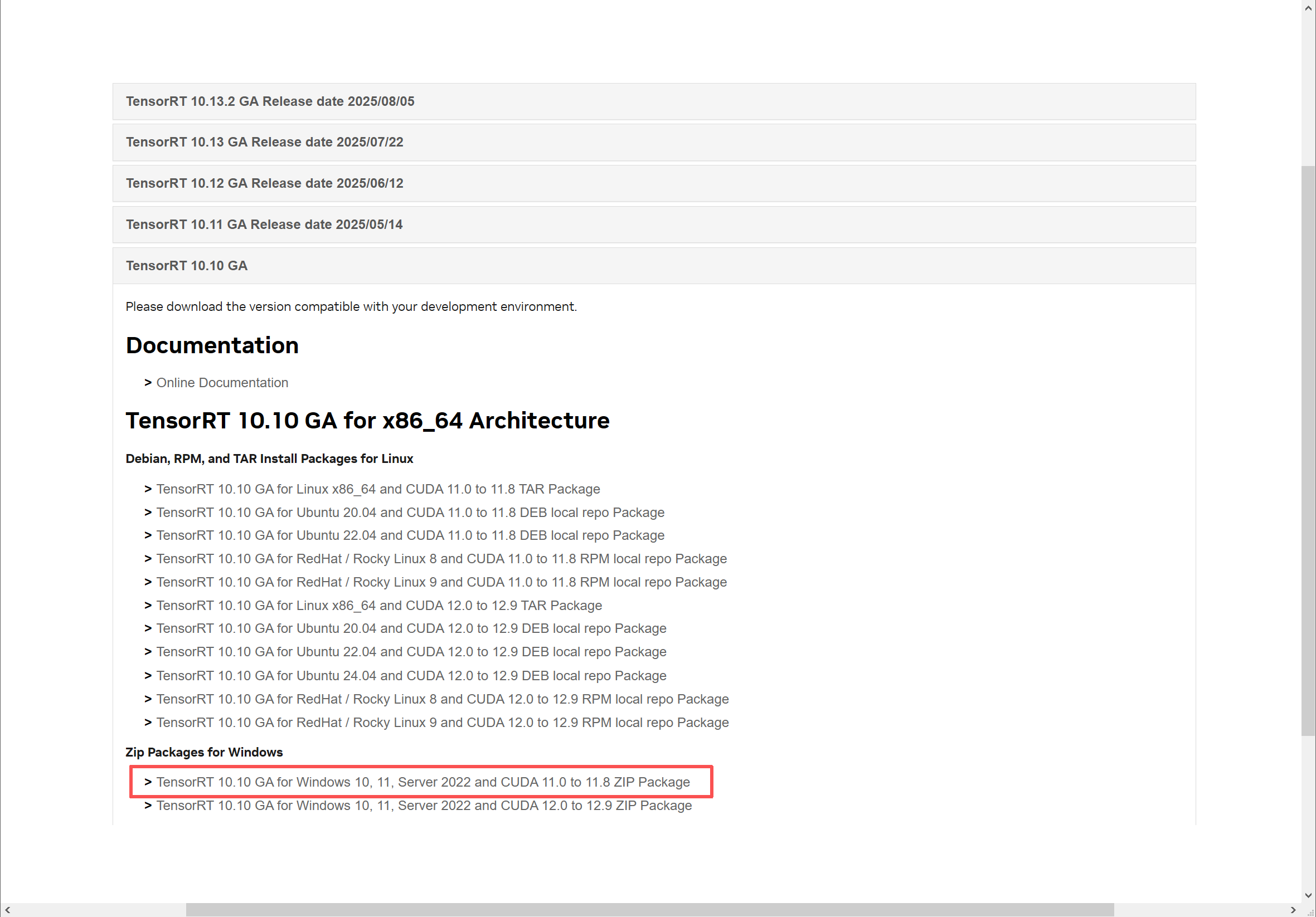
- 解压缩


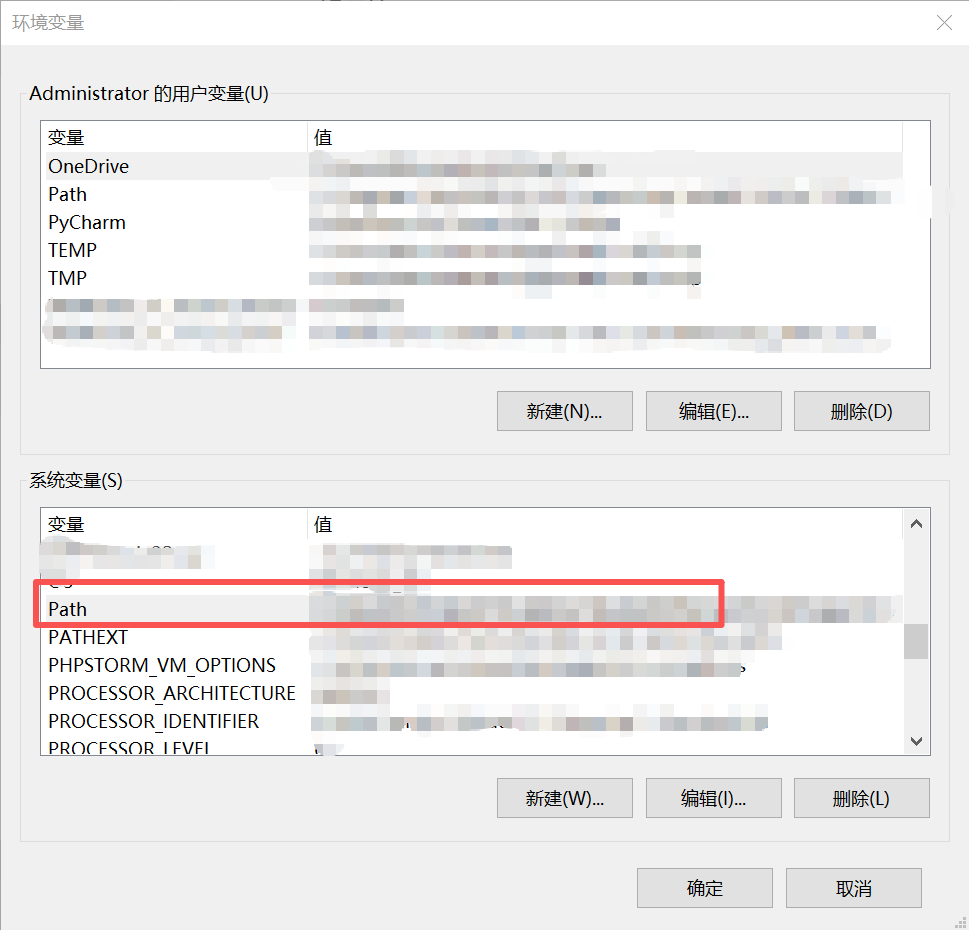
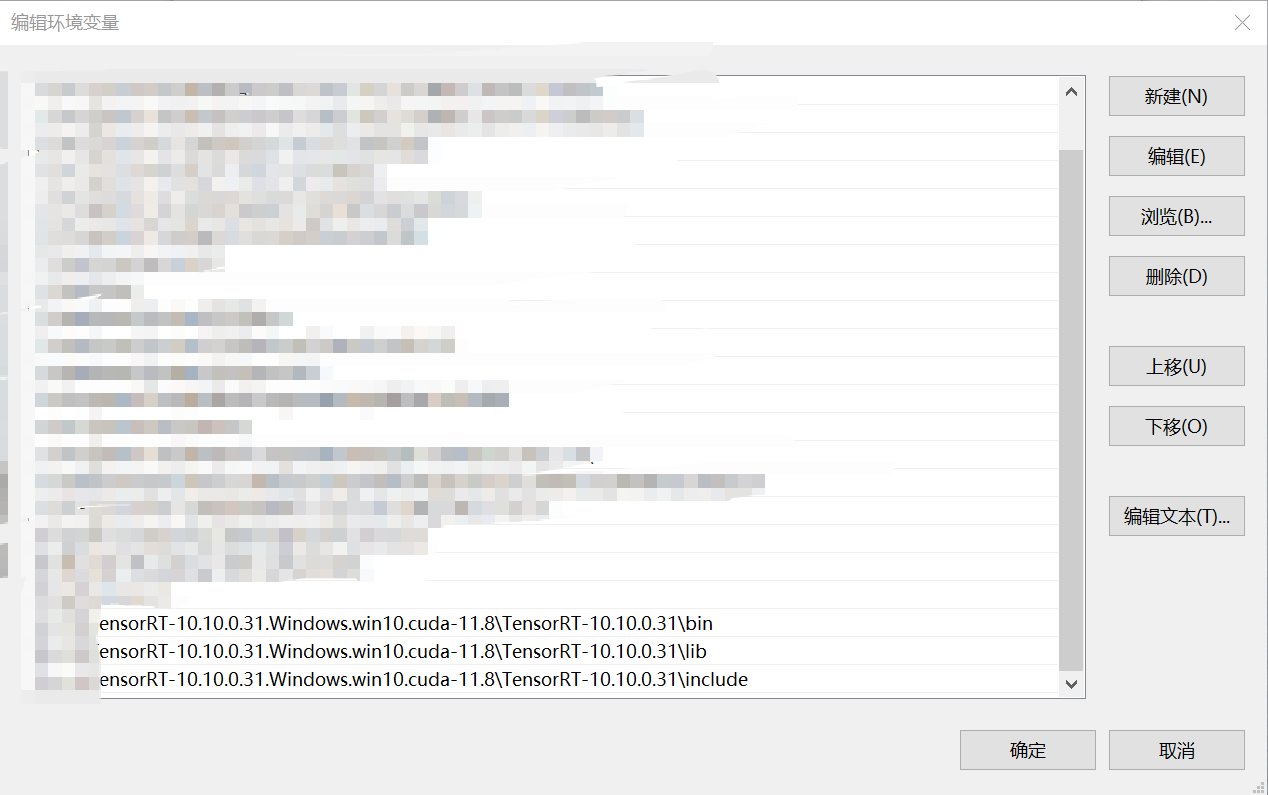
- 添加以下路径到系统变量中并保存
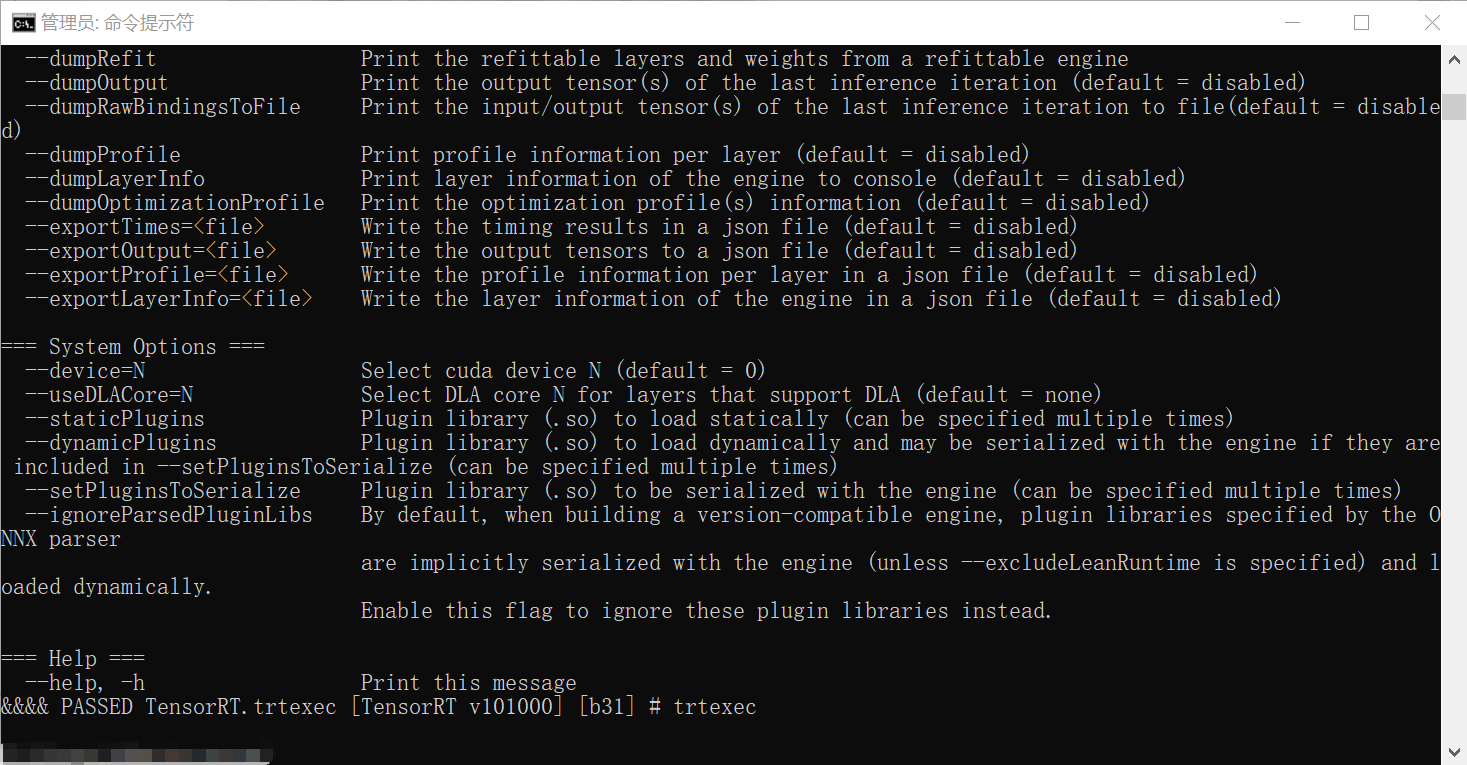
- 终端执行trtexec显示如下表示安装成功
1.3 安装对应的python-whl和cuda-python
1.3.1 trt-python安装
- 进入TRT的目录,因为我提前创建好了python3.12的conda环境,所以执行以下几个命令安装对应的whl包(依据自己的环境版本)
pip install ./tensorrt-10.10.0.31-cp312-none-win_amd64.whl
pip install ./tensorrt_lean-10.10.0.31-cp312-none-win_amd64.whl
pip install ./tensorrt_dispatch-10.10.0.31-cp312-none-win_amd64.whl
- 测试是否可以导入
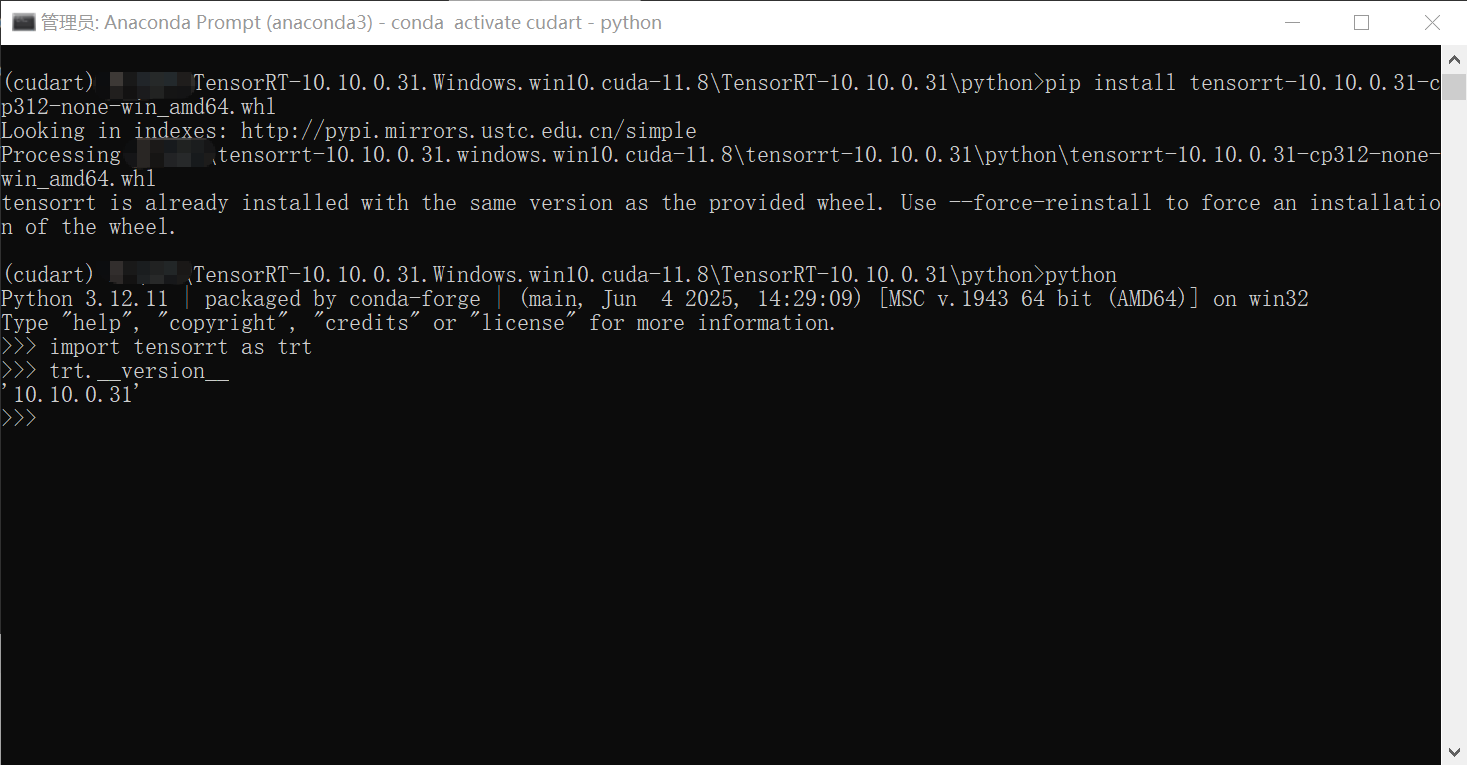
"""
知道你们不想写,这里给出代码
"""
import tensorrt as trt
print(trt.__version__)
- 如果可以正常导入,基本表示trt-python安装成功了
1.3.2 cuda-python安装
- 需要注意的是目前默认安装的cuda-python是13.0以上版本,该版本接口与12.x的接口存在差异,我们先默认安装最新版本,完成推理,然后再适当降低版本完成后续的工作
pip install cuda-python
二、TensorRT-python推理测试
2.1 onnx模型转换TensorRT
- 本小节我们采用trtexec直接将onnx模型转换为tensorrt模型
- 转换指令如下:
trtexec --onnx=path/to/model.onnx --fp16 --saveEngine=model_fp16.engine
--onnx:onnx模型路径
--fp16:指定模型为fp16精度
--saveEngine: 输出模型位置(结尾为.engine)
- 这一过程将持续几分钟,转换成功的示意图如下:
2.2 tensorrt推理测试(代码)
- 这里直接给出依据现有环境可直接运行的代码(如果python提示缺少某些库,则直接依据提示进行pip install package)
- 我将在下一章节深入讲解推理和转换,大家伙可以提前学习该代码
import timeimport tensorrt as trt
import numpy as np
import cv2
from cuda.bindings import driver, nvrtcdef _cudaGetErrorEnum(error):if isinstance(error, driver.CUresult):err, name = driver.cuGetErrorName(error)return name if err == driver.CUresult.CUDA_SUCCESS else "<unknown>"elif isinstance(error, nvrtc.nvrtcResult):return nvrtc.nvrtcGetErrorString(error)[1]else:raise RuntimeError('Unknown error type: {}'.format(error))def checkCudaErrors(result):if result[0].value:raise RuntimeError("CUDA error code={}({})".format(result[0].value, _cudaGetErrorEnum(result[0])))if len(result) == 1:return Noneelif len(result) == 2:return result[1]else:return result[1:]class TRTEngine:def __init__(self, engine_path):# COCO 类别名称self.class_names = ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light','fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow','elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee','skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard','tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple','sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch','potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard','cell phone','microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear','hair drier', 'toothbrush']# 初始化 CUDAerr, = driver.cuInit(0)if err != driver.CUresult.CUDA_SUCCESS:raise RuntimeError(f"CUDA initialization failed with error: {err}")# 获取设备err, self.device = driver.cuDeviceGet(0)if err != driver.CUresult.CUDA_SUCCESS:raise RuntimeError(f"Failed to get CUDA device with error: {err}")self.ctx_create_params = driver.CUctxCreateParams()self.stream_create_params = driver.cuStreamCreate(0)# 创建上下文err, self.context = driver.cuCtxCreate(self.ctx_create_params, 0, self.device)if err != driver.CUresult.CUDA_SUCCESS:raise RuntimeError(f"Failed to create CUDA context with error: {err}")# 初始化 TensorRTlogger = trt.Logger(trt.Logger.WARNING)runtime = trt.Runtime(logger)# 加载引擎文件with open(engine_path, "rb") as f:engine_data = f.read()self.engine = runtime.deserialize_cuda_engine(engine_data)# 获取输入尺寸self.input_shape = self.engine.get_tensor_shape(self.engine.get_tensor_name(0))[2:]# 创建执行上下文self.context_trt = self.engine.create_execution_context()# 分配输入输出内存self._allocate_buffers()def _allocate_buffers(self):"""分配输入输出内存"""self.inputs = []self.outputs = []self.bindings = []self.allocations = [] # 存储分配的内存指针for i in range(self.engine.num_io_tensors):name = self.engine.get_tensor_name(i)dtype = self.engine.get_tensor_dtype(name)shape = self.engine.get_tensor_shape(name)# print("type : ",dtype)# 计算所需内存大小size = trt.volume(shape) * np.dtype(trt.nptype(dtype)).itemsize# print("size : ",size)# 分配设备内存err, d_ptr = driver.cuMemAlloc(size)if err != driver.CUresult.CUDA_SUCCESS:raise RuntimeError(f"Failed to allocate CUDA memory with error: {err}")self.bindings.append(int(d_ptr))self.allocations.append(d_ptr)# 设置输入输出if self.engine.get_tensor_mode(name) == trt.TensorIOMode.INPUT:self.inputs.append({'name': name,'dtype': dtype,'shape': shape,'allocation': d_ptr,'size': size})else:self.outputs.append({'name': name,'dtype': dtype,'shape': shape,'allocation': d_ptr,'size': size})def preprocess(self, image):"""预处理图像"""# 获取原始图像尺寸h, w = image.shape[:2]# 计算缩放比例scale = min(self.input_shape[0] / h, self.input_shape[1] / w)new_w, new_h = int(w * scale), int(h * scale)# 调整图像大小resized = cv2.resize(image, (new_w, new_h), interpolation=cv2.INTER_LINEAR)# 创建填充后的图像padded = np.full((self.input_shape[0], self.input_shape[1], 3), 114, dtype=np.uint8)padded[:new_h, :new_w] = resized# 转换颜色空间和数据类型padded = cv2.cvtColor(padded, cv2.COLOR_BGR2RGB)padded = padded.transpose(2, 0, 1) # HWC to CHWpadded = np.ascontiguousarray(padded, dtype=np.float32) / 255.0return padded, scale, (w, h)def postprocess(self, output, scale, orig_shape, conf_threshold=0.5, nms_threshold=0.4):"""后处理输出"""# 重塑输出为 (8400, 84)output = output[0].transpose(1, 0)# 提取边界框和类别分数boxes = output[:, :4] # x_center, y_center, width, heightprint("box", boxes)scores = output[:, 4:] # 类别分数print("score", scores)# 找到每个框的最高分数和对应的类别class_ids = np.argmax(scores, axis=1)confidences = np.max(scores, axis=1)# 应用置信度阈值mask = confidences > conf_thresholdboxes = boxes[mask]confidences = confidences[mask]class_ids = class_ids[mask]if len(boxes) == 0:return []# 将中心坐标转换为角坐标x_center, y_center, width, height = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]x1 = (x_center - width / 2) / scaley1 = (y_center - height / 2) / scalex2 = (x_center + width / 2) / scaley2 = (y_center + height / 2) / scaleboxes = np.column_stack([x1, y1, x2, y2])# 应用非极大值抑制indices = cv2.dnn.NMSBoxes(boxes.tolist(),confidences.tolist(),conf_threshold,nms_threshold)# 准备最终检测结果detections = []if len(indices) > 0:if isinstance(indices, np.ndarray):indices = indices.flatten()for idx in indices:x1, y1, x2, y2 = boxes[idx]# 确保边界框在图像范围内x1 = max(0, min(x1, orig_shape[0]))y1 = max(0, min(y1, orig_shape[1]))x2 = max(0, min(x2, orig_shape[0]))y2 = max(0, min(y2, orig_shape[1]))detections.append({'bbox': [x1, y1, x2, y2],'confidence': confidences[idx],'class_id': class_ids[idx],'class_name': self.class_names[class_ids[idx]]})return detectionsdef infer(self, image):"""执行推理"""# 预处理图像input_data, scale, orig_shape = self.preprocess(image)# 将数据复制到GPUinput_array = np.ascontiguousarray(input_data)err, = driver.cuMemcpyHtoD(self.inputs[0]['allocation'],input_array.ctypes.data,input_array.nbytes,)if err != driver.CUresult.CUDA_SUCCESS:raise RuntimeError(f"Failed to copy data to device with error: {err}")# 执行推理self.context_trt.execute_v2(self.bindings)# 分配输出内存output_shape = self.outputs[0]['shape']output_dtype = trt.nptype(self.outputs[0]['dtype'])output = np.zeros(output_shape, dtype=output_dtype)# print(output)# 将结果从GPU复制回CPUerr, = driver.cuMemcpyDtoH(output.ctypes.data,self.outputs[0]['allocation'],output.nbytes,)if err != driver.CUresult.CUDA_SUCCESS:raise RuntimeError(f"Failed to copy data from device with error: {err}")# 后处理detections = self.postprocess(output, scale, orig_shape)return detectionsdef draw_detections(self, image, detections, conf_threshold=0.5):"""在图像上绘制检测结果"""for det in detections:if det['confidence'] < conf_threshold:continuebbox = det['bbox']x1, y1, x2, y2 = map(int, bbox)# 绘制边界框color = (0, 255, 0) # 绿色cv2.rectangle(image, (x1, y1), (x2, y2), color, 2)# 准备标签文本label = f"{det['class_name']}: {det['confidence']:.2f}"# 获取文本尺寸(text_width, text_height), baseline = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)# 绘制文本背景cv2.rectangle(image,(x1, y1 - text_height - baseline),(x1 + text_width, y1),color,-1)# 绘制文本cv2.putText(image,label,(x1, y1 - baseline),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0, 0, 0),1)return imagedef __del__(self):if hasattr(self, 'context_trt'):del self.context_trtself.context_trt = Noneif hasattr(self, 'engine'):del self.engineself.engine = None# 释放CUDA内存if hasattr(self, 'allocations'):for allocation in self.allocations:try:driver.cuMemFree(allocation)except:pass # 忽略释放错误self.allocations = []# 最后释放CUDA上下文if hasattr(self, 'context'):driver.cuCtxDestroy(self.context)self.context = None# 使用示例# 初始化引擎
def main(index: int):engine = TRTEngine("./yolo11n_int8.engine")img = cv2.imread(r"path/to/image")# 执行推理res = []while True:start = time.time()detections = engine.infer(img)res.append(time.time()-start)if len(res)==1000:print(f"index : {index} ,infer : {sum(res)/1000*1000} ms")res.clear()result = engine.draw_detections(image, detections, conf_threshold=0.1)# 显示结果cv2.imshow("Detection Results", result)cv2.waitKey(20)# cv2.destroyAllWindows()# 打印检测结果for det in detections:bbox = det['bbox']print(f"{det['class_name']}: {det['confidence']:.2f}, "f"Box: [{bbox[0]:.1f}, {bbox[1]:.1f}, {bbox[2]:.1f}, {bbox[3]:.1f}]")if __name__ == "__main__":from multiprocessing import Processp1 = Process(target=main, args=(1,), daemon=True).start()# p2 = Process(target=main, args=(2,), daemon=True).start()# p3 = Process(target=main, args=(3,), daemon=True).start()# p4 = Process(target=main, args=(4,), daemon=True).start()# p5 = Process(target=main, args=(5,), daemon=True).start()# p6 = Process(target=main, args=(6,),daemon=True).start()# p7 = Process(target=main, args=(7,), daemon=True).start()# p8 = Process(target=main, args=(8,), daemon=True).start()# p9 = Process(target=main, args=(9,), daemon=True).start()# p10 = Process(target=main, args=(10,), daemon=True).start()# p11 = Process(target=main, args=(11,),daemon=True).start()# p12 = Process(target=main, args=(12,), daemon=True).start()# p13 = Process(target=main, args=(13,), daemon=True).start()# p14 = Process(target=main, args=(14,), daemon=True).start()# p15 = Process(target=main, args=(15,), daemon=True).start()# p16 = Process(target=main, args=(16,), daemon=True).start()# p17 = Process(target=main, args=(17,), daemon=True).start()# p18 = Process(target=main, args=(18,), daemon=True).start()# p19 = Process(target=main, args=(19,), daemon=True).start()# p20 = Process(target=main, args=(20,), daemon=True).start()while True:time.sleep(1)2.3 TensorRT yolo11n推理测试结果
- 大家伙可以依据提供的代码动态启动线程进行测试
- 以下是我的测试结果(仅供参考,其中×表示无法推理):
| 测试实例 | 测试路数 | 总帧率 |
|---|---|---|
| TensorRT10 | 路数1 | 125 FPS |
| TensorRT10 | 路数4 | 320 FPS |
| TensorRT10 | 路数10 | 390 FPS |
| OnnxRuntime-GPU | 路数1 | 90 FPS |
| OnnxRuntime-GPU | 路数3 | 140 FPS |
| OnnxRuntime-GPU | 路数6 | 150 FPS |
| OnnxRuntime-GPU | 路数7 | × |
| ultralytics | 路数1 | 111 FPS |
| ultralytics | 路数3 | 200 FPS |
| ultralytics | 路数4 | × |
结果分析与总结
基于以上测试数据,我们可以得出以下结论:
-
性能优势明显:TensorRT 大幅领先
-
在单路推理时,TensorRT (125 FPS) 相比 OnnxRuntime-GPU (90 FPS) 和 ultralytics 原版 (111 FPS) 已有显著性能优势,展现了其深度优化 kernel 和算子融合的强大能力。
-
随着路数(并发数)增加,TensorRT 的性能增长曲线更为平滑,吞吐量优势持续扩大。在10路并发时达到 390 FPS 的总吞吐量,展现了其卓越的并行处理能力和计算效率,非常适合于高并发视频流分析场景。
-
-
并发能力对比:TensorRT > ultralytics > OnnxRuntime-GPU
-
OnnxRuntime-GPU 的并发能力相对较弱,在路数增加到7路时即出现无法推理(可能由于内存溢出或CUDA context 资源耗尽)。其总帧率在达到约150 FPS后便不再增长,表明其并行扩展性存在瓶颈。
-
ultralytics 框架(PyTorch 直接推理)的单路性能尚可,但在4路并发时也出现失败,其扩展性优于 OnnxRuntime但远不如 TensorRT。这通常是由于 Python GIL、模型副本的显存占用以及框架自身的开销所致。
-
TensorRT 成功处理了10路并发请求,显示出其运行时极低的开销和出色的资源管理能力。
-
-
优化建议与场景选择
-
追求极致性能与高并发: 对于需要部署多路摄像头的生产环境,TensorRT 是毋庸置疑的最佳选择。建议通过增加批处理大小(Batch Size)和进一步优化 TensorRT 引擎配置(精度、profile等)来挖掘更大的潜力。
-
快速原型开发与验证: 在项目初期,可以使用 ultralytics 框架进行快速算法验证和模型测试,得益于其简洁的API和完整的生态。
-
跨平台兼容性: 如果部署环境对引擎有严格限制(如某些不支持 TensorRT 的边缘设备),OnnxRuntime 提供了一个不错的平衡点,但需要注意其并发性能限制,需严格测试以确定单机最佳路数。
-
综合来看,TensorRT 通过其深入的模型优化和高效的运行时,在 YOLOv11n 的部署中实现了最高的吞吐量和最佳的并发性能,是多路视频分析业务的首选推理方案。
总结
本小节介绍了tensorrt和cuda-python在windows电脑上的安装过程,并详细介绍了onnx模型转为trt模型的基本流程,从最后的对比数据上来看,在专业设备上借助专业的推理工具,我们可以获得极大的推理性能提升,是AI视频监控平台最优的模型部署方式之一。
下期预告
- 模型量化基本原理和简介
- TensorRT模型量化方法
- yolo11n-end2end转换