【YOLO11改进 - C3k2融合】C3k2融合EBlock(Encoder Block):低光增强编码器块,利用傅里叶信息增强图像的低光条件
YOLOv11目标检测创新改进与实战案例专栏
文章目录: YOLOv11创新改进系列及项目实战目录 包含卷积,主干 注意力,检测头等创新机制 以及 各种目标检测分割项目实战案例
专栏链接: YOLOv11目标检测创新改进与实战案例

文章目录
- YOLOv11目标检测创新改进与实战案例专栏
- 介绍
- 摘要
- 文章链接
- 基本原理
- **EBlock的核心功能**
- **EBlock的结构组成**
- 1. **空间注意力模块(SpAM)**
- 2. **频域前馈网络(Fre-MLP)**
- **EBlock的工作流程**
- **EBlock的设计优势**
- 核心代码
- YOLO11引入代码
- 注册
- 步骤1:
- 步骤2
- 配置yolov11-C3k2_EBlock.yaml
- 实验
- 脚本
- 结果
介绍

摘要
在夜间或昏暗环境下拍摄照片时,由于光线暗淡且常使用长曝光,照片通常会存在噪点、亮度低和模糊等问题。尽管在这些情况下,去模糊和低光图像增强(LLIE)这两项任务存在关联,但大多数图像恢复方法都是将它们分开处理的。 在本文中,我们提出了一种高效且稳健的神经网络,用于多任务低光图像恢复。不同于当前流行的基于Transformer的模型,我们设计了新的注意力机制,以增强高效卷积神经网络(CNNs)的感受野。与以往的方法相比,我们的方法在参数和乘加运算(MAC)方面降低了计算成本。我们的模型DarkIR在常用的LOLBlur、LOLv2和Real-LOLBlur数据集上取得了新的最先进结果,并且能够很好地适配真实世界中的夜间和昏暗环境图像。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
-
在文章提出的DarkIR模型中,EBlock(Encoder Block,编码器块) 是实现低光图像增强的核心组件,主要作用是利用傅里叶域信息改善图像的光照条件,同时为后续的解码器提供光照增强后的特征。其设计遵循Metaformer和NAFBlock的结构,具体细节如下:
EBlock的核心功能
EBlock专为低光增强任务设计,通过处理图像的傅里叶域信息来提升亮度,同时提取有效的空间特征。它的核心目标是:
- 增强图像在傅里叶域的幅度信息(与光照条件高度相关);
- 生成低分辨率的光照校正图像,为解码器提供基础;
- 减少计算成本,同时保证增强效果。
EBlock的结构组成
EBlock由两个关键模块组成,协同完成低光增强任务:
1. 空间注意力模块(SpAM)
-
作用:提取图像的空间特征,辅助后续频域增强。
-
结构:
- 基于NAFBlock的反向残差块(Inverted Residual Block),减少参数数量的同时保留重要特征;
- 简化的通道注意力(SCA),通过对通道维度的权重分配,突出关键区域(如高光或暗光区域);
- 采用门控机制(而非传统激活函数),更灵活地控制特征流动,避免过度激活导致的信息丢失。
-
功能:聚焦图像中对光照敏感的空间区域,为频域处理提供针对性的空间信息。
2. 频域前馈网络(Fre-MLP)
-
作用:直接在傅里叶域操作,增强与光照相关的幅度信息。
-
原理:
- 图像的光照条件主要与傅里叶域的幅度相关(相位信息更多影响结构),因此仅需增强幅度即可改善亮度;
- 通过快速傅里叶变换(FFT) 将图像从空间域转换到频域,分离出幅度和相位;
- 对幅度进行增强处理(如调整对比度、抑制噪声),再通过逆快速傅里叶变换(IFFT) 转换回空间域。
-
优势:相比空间域操作(如通道MLP),频域处理能更高效地全局优化光照,且对低分辨率图像同样有效。
EBlock的工作流程
- 输入处理:接收低光图像的特征图(来自前一层或原始输入);
- 空间特征提取:通过SpAM提取空间注意力特征,突出光照敏感区域;
- 频域增强:将特征图转换到傅里叶域,通过Fre-MLP增强幅度信息,再转换回空间域;
- 下采样与特征传递:通过步长卷积(Strided Convolution)对特征图下采样(分辨率减半),减少深层网络的计算量;
- 生成低分辨率图像:将编码后的深层特征通过卷积层线性组合,生成分辨率为原始图像1/8的低光增强图像(x^↓8\hat{x}_{↓8}x^↓8),用于模型正则化(确保光照增强效果)。
EBlock的设计优势
- 高效性:通过下采样减少深层网络的运算量,同时频域操作避免了空间域的冗余计算;
- 针对性:专注于傅里叶域幅度增强,直击低光图像的核心问题(光照不足);
- 轻量性:相比Transformer模型,EBlock基于CNN结构,参数更少,适合移动端部署。
核心代码
class EBlock(nn.Module):'''Change this block using Branch'''def __init__(self, c, DW_Expand=2, dilations = [1], extra_depth_wise = False):super().__init__()#we define the 2 branchesself.dw_channel = DW_Expand * c self.extra_conv = nn.Conv2d(c, c, kernel_size=3, padding=1, stride=1, groups=c, bias=True, dilation=1) if extra_depth_wise else nn.Identity() #optional extra dwself.conv1 = nn.Conv2d(in_channels=c, out_channels=self.dw_channel, kernel_size=1, padding=0, stride=1, groups=1, bias=True, dilation = 1)self.branches = nn.ModuleList()for dilation in dilations:self.branches.append(Branch(c, DW_Expand, dilation = dilation))assert len(dilations) == len(self.branches)self.dw_channel = DW_Expand * c self.sca = nn.Sequential(nn.AdaptiveAvgPool2d(1),nn.Conv2d(in_channels=self.dw_channel // 2, out_channels=self.dw_channel // 2, kernel_size=1, padding=0, stride=1,groups=1, bias=True, dilation = 1), )self.sg1 = SimpleGate()self.conv3 = nn.Conv2d(in_channels=self.dw_channel // 2, out_channels=c, kernel_size=1, padding=0, stride=1, groups=1, bias=True, dilation = 1)# second stepself.norm1 = LayerNorm2d(c)self.norm2 = LayerNorm2d(c)self.freq = FreMLP(nc = c, expand=2)self.gamma = nn.Parameter(torch.zeros((1, c, 1, 1)), requires_grad=True)self.beta = nn.Parameter(torch.zeros((1, c, 1, 1)), requires_grad=True)# self.adapter = Adapter(c, ffn_channel=None)# self.use_adapters = False# def set_use_adapters(self, use_adapters):
# self.use_adapters = use_adaptersdef forward(self, inp):y = inpx = self.norm1(inp)x = self.conv1(self.extra_conv(x))z = 0for branch in self.branches:z += branch(x)z = self.sg1(z)x = self.sca(z) * zx = self.conv3(x)y = inp + self.beta * x#second stepx_step2 = self.norm2(y) # size [B, 2*C, H, W]x_freq = self.freq(x_step2) # size [B, C, H, W]x = y * x_freq x = y + x * self.gamma# if self.use_adapters:
# return self.adapter(x)
# else:return x YOLO11引入代码
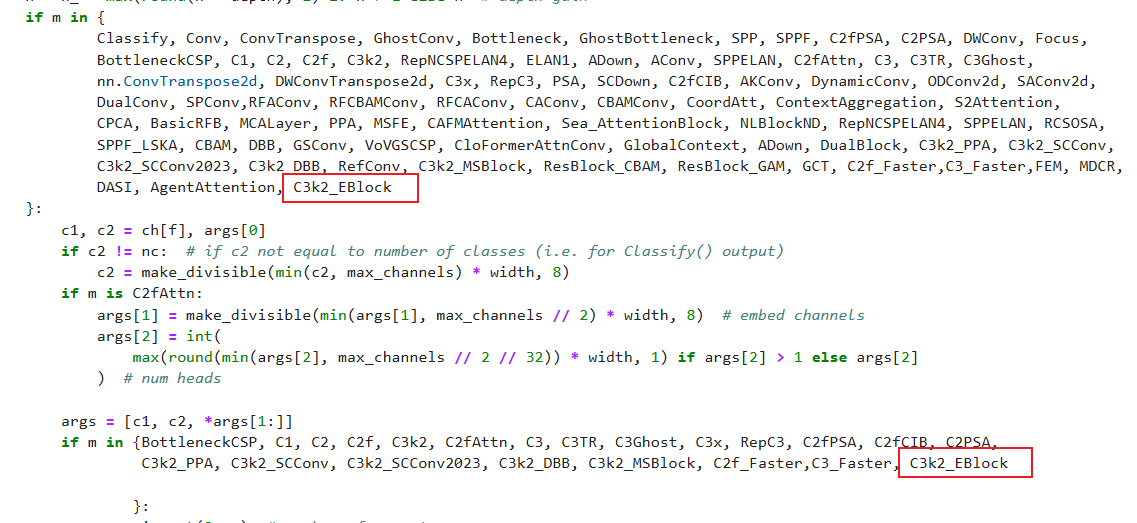
在根目录下的ultralytics/nn/目录,新建一个C3k2目录,然后新建一个以 C3k2_EBlock为文件名的py文件, 把代码拷贝进去。
import torch
import torch.nn as nnclass LayerNormFunction(torch.autograd.Function):@staticmethoddef forward(ctx, x, weight, bias, eps):ctx.eps = epsN, C, H, W = x.size()mu = x.mean(1, keepdim=True)var = (x - mu).pow(2).mean(1, keepdim=True)y = (x - mu) / (var + eps).sqrt()ctx.save_for_backward(y, var, weight)y = weight.view(1, C, 1, 1) * y + bias.view(1, C, 1, 1)return y@staticmethoddef backward(ctx, grad_output):eps = ctx.epsN, C, H, W = grad_output.size()y, var, weight = ctx.saved_variablesg = grad_output * weight.view(1, C, 1, 1)mean_g = g.mean(dim=1, keepdim=True)mean_gy = (g * y).mean(dim=1, keepdim=True)gx = 1. / torch.sqrt(var + eps) * (g - y * mean_gy - mean_g)return gx, (grad_output * y).sum(dim=3).sum(dim=2).sum(dim=0), grad_output.sum(dim=3).sum(dim=2).sum(dim=0), Noneclass LayerNorm2d(nn.Module):def __init__(self, channels, eps=1e-6):super(LayerNorm2d, self).__init__()self.register_parameter('weight', nn.Parameter(torch.ones(channels)))self.register_parameter('bias', nn.Parameter(torch.zeros(channels)))self.eps = epsdef forward(self, x):return LayerNormFunction.apply(x, self.weight, self.bias, self.eps)class SimpleGate(nn.Module):def forward(self, x):x1, x2 = x.chunk(2, dim=1)return x1 * x2class Adapter(nn.Module):def __init__(self, c, ffn_channel = None):super().__init__()if ffn_channel:ffn_channel = 2else:ffn_channel = cself.conv1 = nn.Conv2d(in_channels=c, out_channels=ffn_channel, kernel_size=1, padding=0, stride=1, groups=1, bias=True)self.conv2 = nn.Conv2d(in_channels=ffn_channel, out_channels=c, kernel_size=1, padding=0, stride=1, groups=1, bias=True)self.depthwise = nn.Conv2d(in_channels=c, out_channels=ffn_channel, kernel_size=3, padding=1, stride=1, groups=c, bias=True, dilation=1)def forward(self, input):x = self.conv1(input) + self.depthwise(input)x = self.conv2(x)return xclass FreMLP(nn.Module):def __init__(self, nc, expand = 2):super(FreMLP, self).__init__()self.process1 = nn.Sequential(nn.Conv2d(nc, expand * nc, 1, 1, 0),nn.LeakyReLU(0.1, inplace=True),nn.Conv2d(expand * nc, nc, 1, 1, 0))def forward(self, x):_, _, H, W = x.shapex_dtype = x.dtypex_freq = torch.fft.rfft2(x.float(), norm='backward')mag = torch.abs(x_freq)pha = torch.angle(x_freq)mag = self.process1(mag.to(x_dtype))real = mag * torch.cos(pha)imag = mag * torch.sin(pha)x_out = torch.complex(real, imag)x_out = torch.fft.irfft2(x_out.float(), s=(H, W), norm='backward')return x_out.to(x_dtype)class Branch(nn.Module):'''Branch that lasts lonly the dilated convolutions'''def __init__(self, c, DW_Expand, dilation = 1):super().__init__()self.dw_channel = DW_Expand * c self.branch = nn.Sequential(nn.Conv2d(in_channels=self.dw_channel, out_channels=self.dw_channel, kernel_size=3, padding=dilation, stride=1, groups=self.dw_channel,bias=True, dilation = dilation) # the dconv)def forward(self, input):return self.branch(input)class EBlock(nn.Module):'''Change this block using Branch'''def __init__(self, c, DW_Expand=2, dilations = [1], extra_depth_wise = False):super().__init__()#we define the 2 branchesself.dw_channel = DW_Expand * c self.extra_conv = nn.Conv2d(c, c, kernel_size=3, padding=1, stride=1, groups=c, bias=True, dilation=1) if extra_depth_wise else nn.Identity() #optional extra dwself.conv1 = nn.Conv2d(in_channels=c, out_channels=self.dw_channel, kernel_size=1, padding=0, stride=1, groups=1, bias=True, dilation = 1)self.branches = nn.ModuleList()for dilation in dilations:self.branches.append(Branch(c, DW_Expand, dilation = dilation))assert len(dilations) == len(self.branches)self.dw_channel = DW_Expand * c self.sca = nn.Sequential(nn.AdaptiveAvgPool2d(1),nn.Conv2d(in_channels=self.dw_channel // 2, out_channels=self.dw_channel // 2, kernel_size=1, padding=0, stride=1,groups=1, bias=True, dilation = 1), )self.sg1 = SimpleGate()self.conv3 = nn.Conv2d(in_channels=self.dw_channel // 2, out_channels=c, kernel_size=1, padding=0, stride=1, groups=1, bias=True, dilation = 1)# second stepself.norm1 = LayerNorm2d(c)self.norm2 = LayerNorm2d(c)self.freq = FreMLP(nc = c, expand=2)self.gamma = nn.Parameter(torch.zeros((1, c, 1, 1)), requires_grad=True)self.beta = nn.Parameter(torch.zeros((1, c, 1, 1)), requires_grad=True)def forward(self, inp):y = inpx = self.norm1(inp)x = self.conv1(self.extra_conv(x))z = 0for branch in self.branches:z += branch(x)z = self.sg1(z)x = self.sca(z) * zx = self.conv3(x)y = inp + self.beta * x#second stepx_step2 = self.norm2(y) # size [B, 2*C, H, W]x_freq = self.freq(x_step2) # size [B, C, H, W]x = y * x_freq x = y + x * self.gammareturn x def autopad(k, p=None, d=1): # kernel, padding, dilation"""Pad to 'same' shape outputs."""if d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-sizeif p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):"""Initialize Conv layer with given arguments including activation."""super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):"""Apply convolution, batch normalization and activation to input tensor."""return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):"""Perform transposed convolution of 2D data."""return self.act(self.conv(x))class C2f(nn.Module):"""Faster Implementation of CSP Bottleneck with 2 convolutions."""def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):"""Initializes a CSP bottleneck with 2 convolutions and n Bottleneck blocks for faster processing."""super().__init__()self.c = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, 2 * self.c, 1, 1)self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))def forward(self, x):"""Forward pass through C2f layer."""y = list(self.cv1(x).chunk(2, 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))def forward_split(self, x):"""Forward pass using split() instead of chunk()."""y = list(self.cv1(x).split((self.c, self.c), 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))class Bottleneck(nn.Module):"""Standard bottleneck."""def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):"""Initializes a standard bottleneck module with optional shortcut connection and configurable parameters."""super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, k[0], 1)self.cv2 = Conv(c_, c2, k[1], 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):"""Applies the YOLO FPN to input data."""return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class C3(nn.Module):"""CSP Bottleneck with 3 convolutions."""def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):"""Initialize the CSP Bottleneck with given channels, number, shortcut, groups, and expansion values."""super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=((1, 1), (3, 3)), e=1.0) for _ in range(n)))def forward(self, x):"""Forward pass through the CSP bottleneck with 2 convolutions."""return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
class C3k2(C2f):"""Faster Implementation of CSP Bottleneck with 2 convolutions."""def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):"""Initializes the C3k2 module, a faster CSP Bottleneck with 2 convolutions and optional C3k blocks."""super().__init__(c1, c2, n, shortcut, g, e)self.m = nn.ModuleList(C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck(self.c, self.c, shortcut, g) for _ in range(n))class C3k(C3):"""C3k is a CSP bottleneck module with customizable kernel sizes for feature extraction in neural networks."""def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, k=3):"""Initializes the C3k module with specified channels, number of layers, and configurations."""super().__init__(c1, c2, n, shortcut, g, e)c_ = int(c2 * e) # hidden channels# self.m = nn.Sequential(*(RepBottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))class C3k_EBlock(C3k):def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=3):super().__init__(c1, c2, n, shortcut, g, e, k)c_ = int(c2 * e) # hidden channelsself.m = nn.Sequential(*(EBlock(c_) for _ in range(n)))class C3k2_EBlock(C3k2):def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):super().__init__(c1, c2, n, c3k, e, g, shortcut)self.m = nn.ModuleList(C3k_EBlock(self.c, self.c, n, shortcut, g) if c3k else EBlock(self.c) for _ in range(n))
注册
在ultralytics/nn/tasks.py中进行如下操作:
步骤1:
from ultralytics.nn.C3k2.C3k2_EBlock import C3k2_EBlock
步骤2
修改def parse_model(d, ch, verbose=True):
C3k2_EBlock
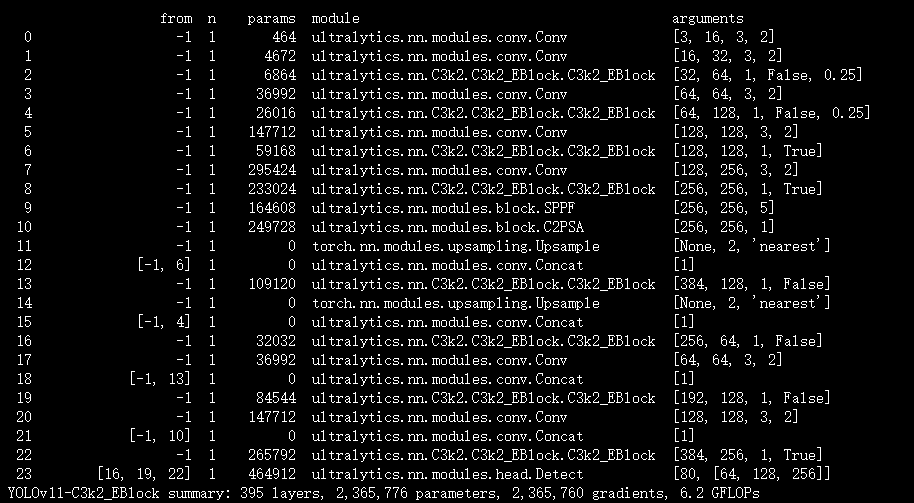
配置yolov11-C3k2_EBlock.yaml
ultralytics/cfg/models/11/yolov11-C3k2_EBlock.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPss: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPsm: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPsl: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPsx: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs# YOLO11n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 2, C3k2_EBlock, [256, False, 0.25]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 2, C3k2_EBlock, [512, False, 0.25]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 2, C3k2_EBlock, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 2, C3k2_EBlock, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 2, C2PSA, [1024]] # 10# YOLO11n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 2, C3k2_EBlock, [512, False]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 2, C3k2_EBlock, [256, False]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 2, C3k2_EBlock, [512, False]] # 19 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 2, C3k2_EBlock, [1024, True]] # 22 (P5/32-large)- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':
# 修改为自己的配置文件地址model = YOLO('/root/ultralytics-main/ultralytics/cfg/models/11/yolov11-C3k2_EBlock.yaml')
# 修改为自己的数据集地址model.train(data='/root/ultralytics-main/ultralytics/cfg/datasets/coco8.yaml',cache=False,imgsz=640,epochs=10,single_cls=False, # 是否是单类别检测batch=8,close_mosaic=10,workers=0,optimizer='SGD',amp=True,project='runs/train',name='C3k2_EBlock',)结果