NLP——TF-IDF算法
一·TF-IDF 分析
TF:
指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化 (一般是词频除以文章总词数), 以防止它偏向长的文件。

功能是用于找到核心关键词、关键词
jieba可以把文章分成一个又一个词
TF-IDF 分析
举例:
假设一篇文章为《中国的蜜蜂养殖》,分词后有 1000 个词,"中国"、"蜜蜂"、"养殖" 各出现 20 次,则这三个词的 "词频"(TF)都为 0.02。
IDF:
逆向文档频率。IDF 的主要思想是:如果包含词条 t 的文档越少,IDF 越大,则说明词条具有很好的类别区分能力。

TF-IDF 分析
TF-IDF:
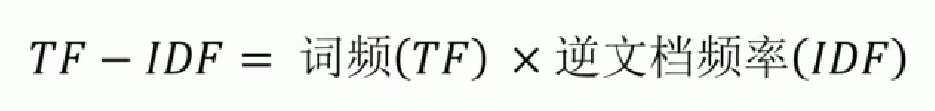
因此,TF-IDF 倾向于过滤掉常见的词语,保留重要的词语。
对 TF - IDF 的总结,说明 TF - IDF 相当于加权
二·代码
语料库
This is the first document
This document is the second document
And this is the third one
Is this the first document
This line has several words
This is the final document代码
# 导入需要的库:TfidfVectorizer用于TF-IDF特征提取,pandas用于数据处理
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd# 读取文本文件内容作为语料库
# 打开当前目录下的task2_1.txt文件,只读模式
inFile = open(r".\task2_1.txt", 'r')
# 按行读取文件内容,存储到corpus列表中
corpus = inFile.readlines()# 初始化TF-IDF向量器
vectorizer = TfidfVectorizer()
# 对语料库进行拟合并转换,得到TF-IDF矩阵
tfidf = vectorizer.fit_transform(corpus)# 打印TF-IDF矩阵(稀疏矩阵形式)
print(tfidf)# 获取所有特征词(词汇表)
wordlist = vectorizer.get_feature_names()
# 打印词汇表
print(wordlist)# 将TF-IDF矩阵转换为DataFrame格式,方便查看和处理
# 转置矩阵并转换为稠密矩阵,以词汇表为索引
df = pd.DataFrame(tfidf.T.todense(), index=wordlist)
# 打印转换后的DataFrame
print(df)# 提取第6列(索引为5)的TF-IDF值,转换为列表
featurelist = df.iloc[:, 5].to_list()# 创建字典存储词语及其对应的TF-IDF值
resdict = {}
for i in range(0, len(wordlist)):resdict[wordlist[i]] = featurelist[i]
# 按TF-IDF值降序排序
resdict = sorted(resdict.items(), key=lambda x: x[1], reverse=True)# 打印排序后第3个元素(索引为2)的词语及其TF-IDF值
print(resdict[2])步骤 1:导入所需库
python
运行
# 导入TF-IDF特征提取工具
from sklearn.feature_extraction.text import TfidfVectorizer
# 导入数据处理工具(用于将结果转换为表格形式)
import pandas as pd
- TfidfVectorizer:来自
sklearn.feature_extraction.text模块,用于将文本语料转换为 TF-IDF 特征矩阵(TF-IDF 是一种衡量词语在文本中重要性的指标)。 - pandas:常用的数据处理库,这里用于将稀疏的 TF-IDF 矩阵转换为易读的表格(DataFrame)。
步骤 2:读取文本语料
python
运行
# 打开文本文件(路径为当前目录下的task2_1.txt,只读模式)
inFile = open(r".\task2_1.txt", 'r')
# 按行读取文件内容,存储到corpus列表中(corpus即"语料库")
corpus = inFile.readlines()
- 代码通过
open()函数读取指定路径的文本文件,r表示只读模式。 readlines()会将文件内容按行分割,存入corpus列表,例如corpus可能是:["This is the first document", "This document is the second document", ...]。
步骤 3:初始化 TF-IDF 向量器并转换语料
python
运行
# 初始化TF-IDF向量器(默认会对文本进行分词、去除停用词等预处理)
vectorizer = TfidfVectorizer()
# 对语料库进行拟合并转换,得到TF-IDF矩阵(稀疏矩阵形式)
tfidf = vectorizer.fit_transform(corpus)
- TfidfVectorizer():初始化向量器,默认参数包括:
- 自动将文本转换为小写
- 按空格分词
- 去除标点符号
- 过滤掉出现频率过高(如在 95% 以上文档中出现)或过低的词语(停用词)。
- fit_transform(corpus):
fit:分析语料库,构建词汇表(记录所有出现的词语)。transform:将每句文本转换为 TF-IDF 向量,最终形成一个矩阵(行 = 文本序号,列 = 词语序号,值 = TF-IDF 值)。
步骤 4:查看 TF-IDF 矩阵及词汇表
python
运行
# 打印TF-IDF矩阵(稀疏矩阵形式,只显示非零值的位置和数值)
print(tfidf)# 获取词汇表(所有词语的列表,按字母顺序排列)
wordlist = vectorizer.get_feature_names()
# 打印词汇表
print(wordlist)
- tfidf:是一个稀疏矩阵(大多数值为 0),输出格式类似
(行索引, 列索引) TF-IDF值,例如(0, 1) 0.5表示第 1 个文本中第 2 个词语的 TF-IDF 值为 0.5。 - wordlist:通过
get_feature_names()获取词汇表,例如可能为['and', 'document', 'final', 'first', 'has', 'is', 'line', 'one', 'several', 'the', 'third', 'this', 'words']。
步骤 5:将 TF-IDF 矩阵转换为 DataFrame
python
运行
# 将TF-IDF矩阵转置(行=词语,列=文本),并转换为稠密矩阵,用词汇表作为索引
df = pd.DataFrame(tfidf.T.todense(), index=wordlist)
# 打印转换后的表格(每行是一个词语,每列是一个文本的TF-IDF值)
print(df)
- tfidf.T.todense():
T:转置矩阵(行和列互换),让词语作为行,文本作为列。todense():将稀疏矩阵转换为稠密矩阵(显示所有值,包括 0)。
- DataFrame:表格形式更直观,例如行索引为词语
'document',列索引为文本序号,单元格值为该词语在对应文本中的 TF-IDF 值。
步骤 6:提取特定文本的词语并排序
python
运行
# 提取第6个文本(索引为5,因为Python从0开始计数)的所有词语的TF-IDF值,转换为列表
featurelist = df.iloc[:, 5].to_list()# 创建字典,存储"词语: TF-IDF值"键值对
resdict = {}
for i in range(0, len(wordlist)):resdict[wordlist[i]] = featurelist[i]# 按TF-IDF值降序排序(值越大,词语在该文本中越重要)
resdict = sorted(resdict.items(), key=lambda x: x[1], reverse=True)# 打印排序后第3个词语(索引为2)及其TF-IDF值
print(resdict[2])
- df.iloc[:, 5]:提取表格中第 6 列(对应第 6 个文本)的数据。
- 排序逻辑:通过
sorted()函数按 TF-IDF 值从大到小排序,key=lambda x: x[1]表示按字典的值排序,reverse=True表示降序。 - 最终
print(resdict[2])会输出第 6 个文本中,TF-IDF 值排第 3 的词语及其数值。