1. 网络基础
0.背景
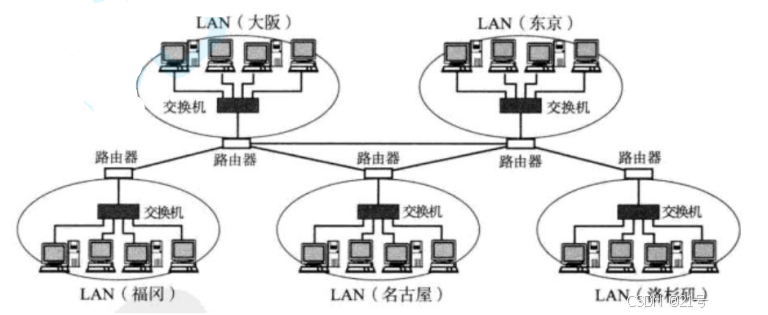
1.协议I
1.1协议分层
1.2 OSI七层模型
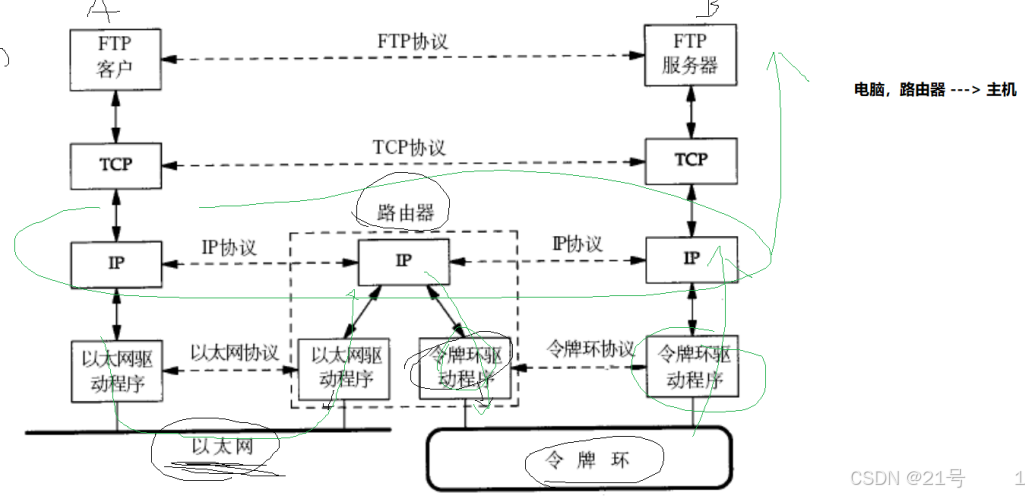
1.3 TCP/IP五层(或四层)协议
1. 物理层: 负责光/电信号的传递方式. 比如现在以太网通用的网线(双绞 线)、早
期以太网采用的的同轴电缆(现在主要用于有线电视)、光纤, 现在的 wifi 无线网使用
电磁波等都属于物理层的概念。物理层的能力决定了最大传输速率、传输距离、抗
干扰性等. 集线器(Hub)工作在物理层. 2. 数据链路层: 负责设备之间的数据帧的传送和识别. 例如网卡设备的驱动、帧同
步(就是说从网线上检测到什么信号算作新帧的开始)、冲突检测(如果检测到冲突就
自动重发)、数据差错校验等工作. 有以太网、令牌环网, 无线 LAN 等标准. 交换机
(Switch)工作在数据链路层. 3. 网络层: 负责地址管理和路由选择. 例如在 IP 协议中, 通过 IP 地址来标识一台
主机, 并通过路由表的方式规划出两台主机之间的数据传输的线路(路由). 路由器
(Router)工作在网路层. 4. 传输层: 负责两台主机之间的数据传输. 如传输控制协议 (TCP), 能够确保数据
可靠的从源主机发送到目标主机. 5. 应用层: 负责应用程序间沟通,如简单电子邮件传输(SMTP)、文件传输协
议(FTP)、网络远程访问协议(Telnet)等. 我们的网络编程主要就是针对应用层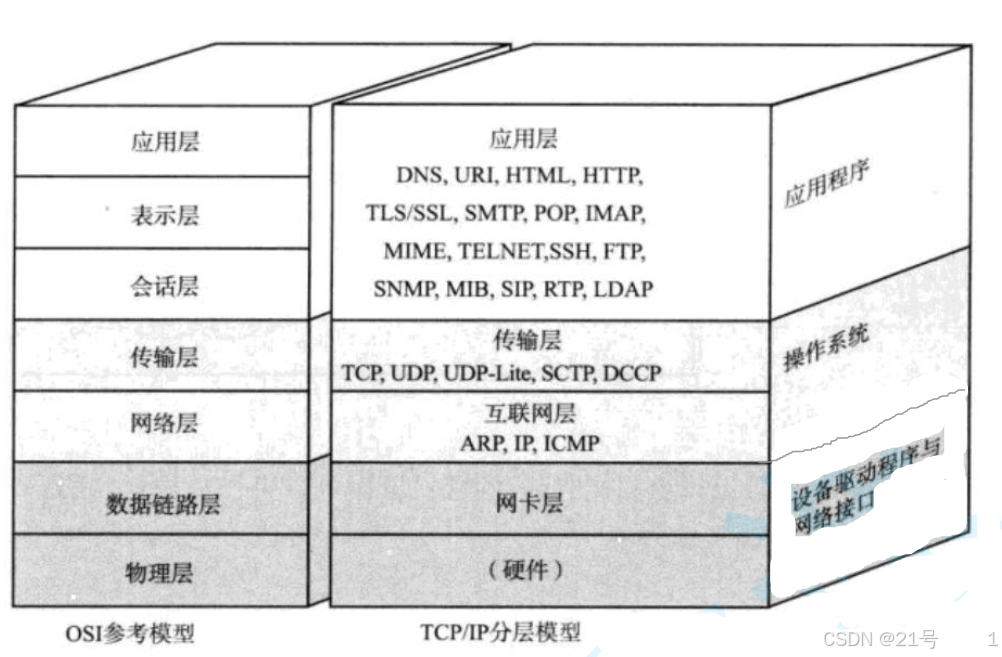
一般而言
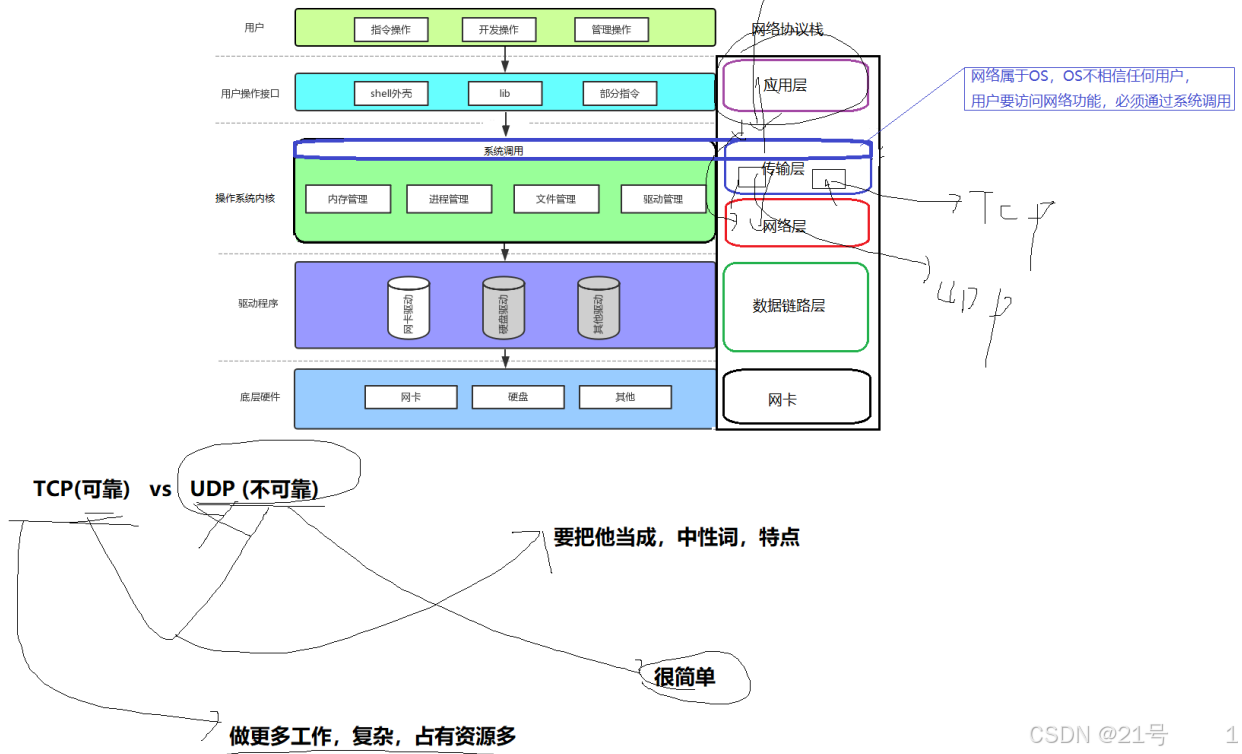
• 对于一台主机, 它的操作系统内核实现了从传输层到物理层的内容;
• 对于一台路由器, 它实现了从网络层到物理层;
• 对于一台交换机, 它实现了从数据链路层到物理层;
• 对于集线器, 它只实现了物理层2.协议II
2.1为什么要有TCP/IP协议
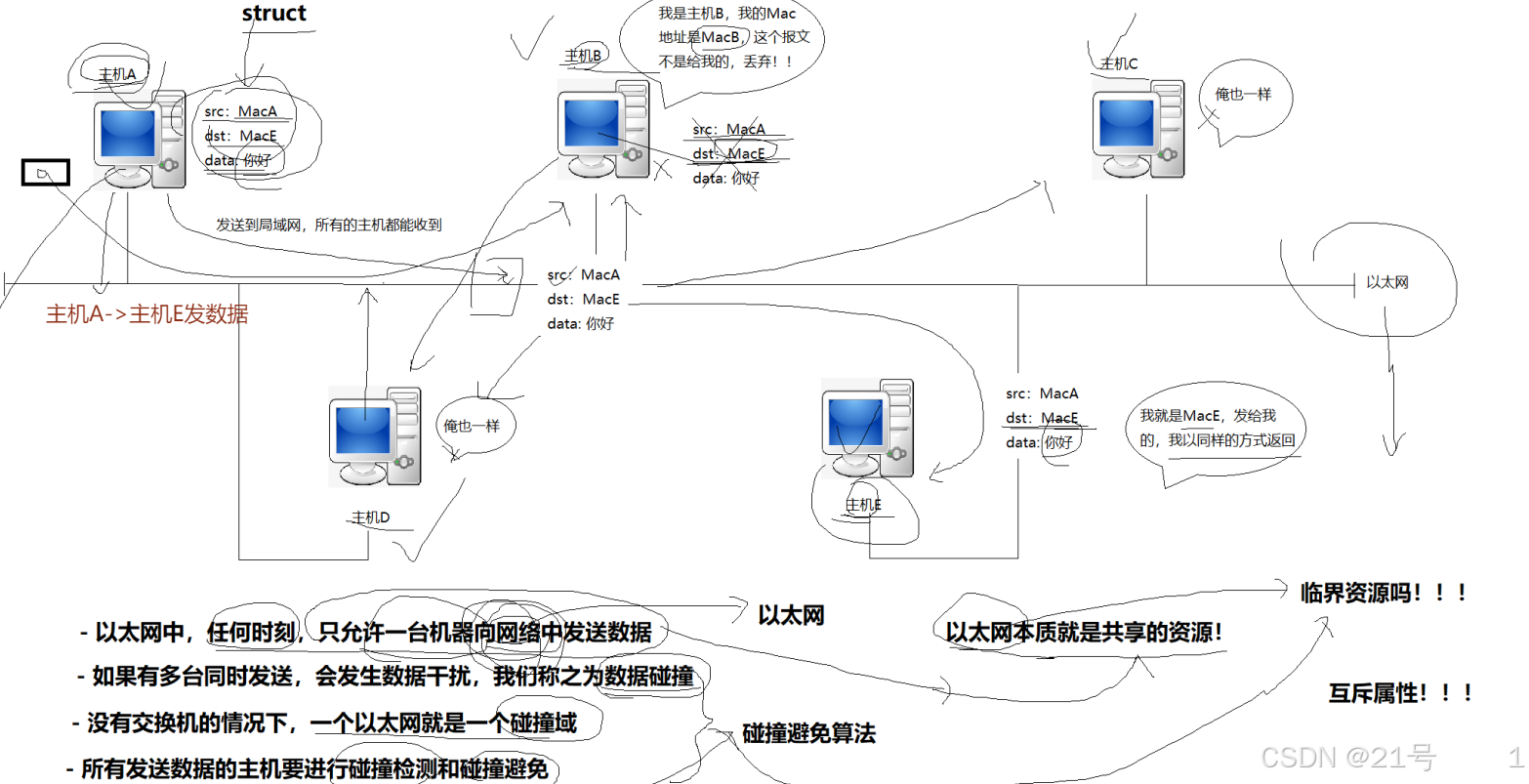
2.2什么是TCP/IP协议
2.3TCP/IP协议与OS的关系(宏观)
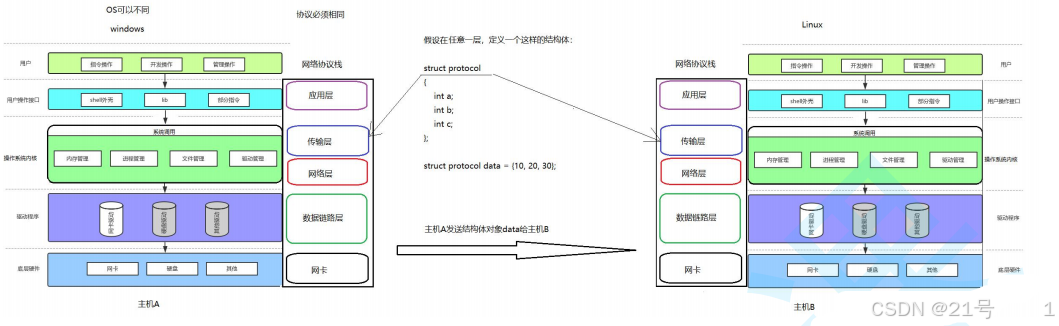
问题:主机 B 能识别 data,并且准确提取 a=10,b=20,c=30 吗?回答:答案是肯定的!因为双方都有同样的结构体类型 struct protocol。也就是说,
用同样的代码实现协议,用同样的自定义数据类型,天然就具有”共识“,能够识别
对方发来的数据,这不就是约定吗?关于协议的朴素理解:所谓协议,就是通信双方都认识的结构化的数据类型
因为协议栈是分层的,所以,每层都有双方都有协议,同层之间,互相可以认识对方的协议。
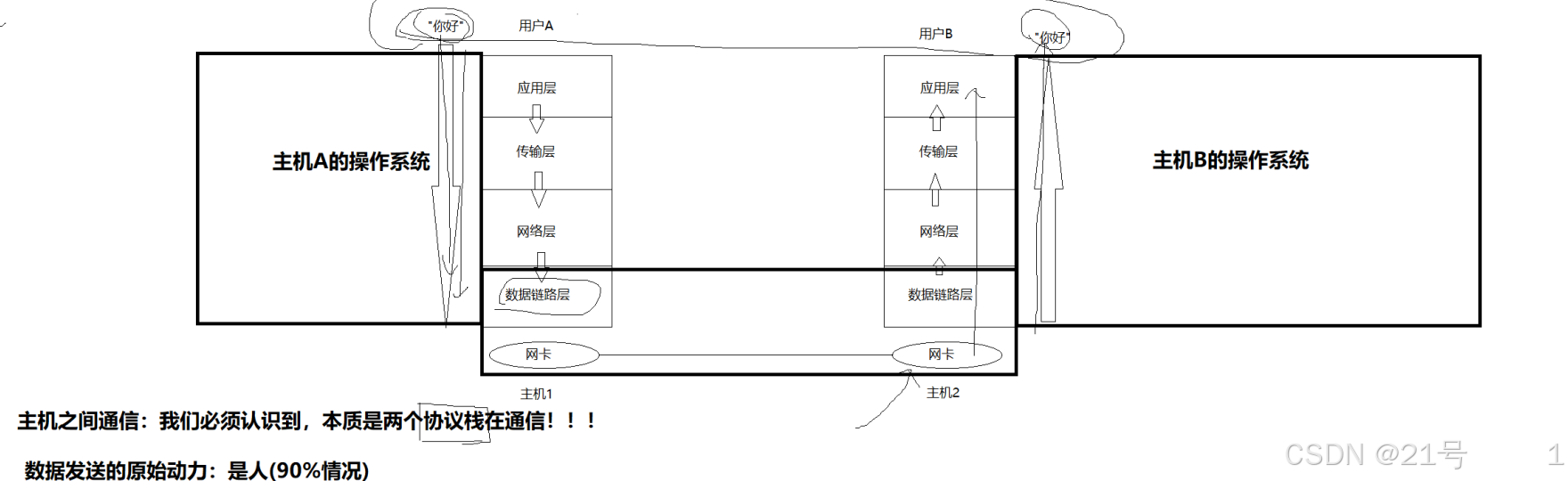
3.网络传输基本流程
3.1局部网网络传输流程图
认识MAC地址
IP地址,用来标识,全球范围内,主机的唯一性(公网IP)
从哪来,到哪去 --- 源IP,目标IP地址(长远)
上一站从哪来,下一站去哪里 --- 源MAC,目标MAC地址(近期)
数据包封装和分用
而其中每层都有协议,所以当我进行进行上述传输流程的时候,要进行封装和解包
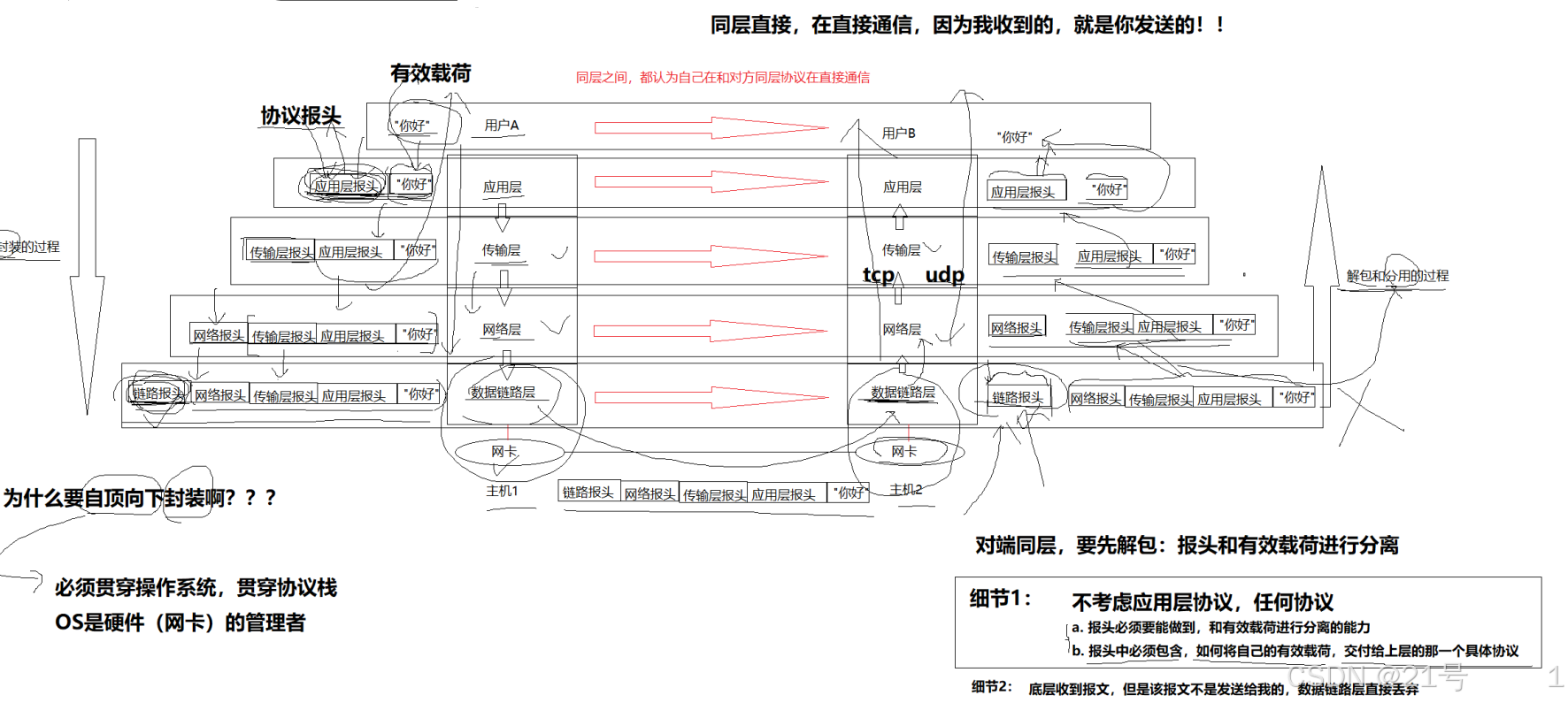 • 报头部分,就是对应协议层的结构体字段,我们一般叫做报头
• 报头部分,就是对应协议层的结构体字段,我们一般叫做报头
• 除了报头,剩下的叫做有效载荷
• 故,报文 = 报头 + 有效载荷
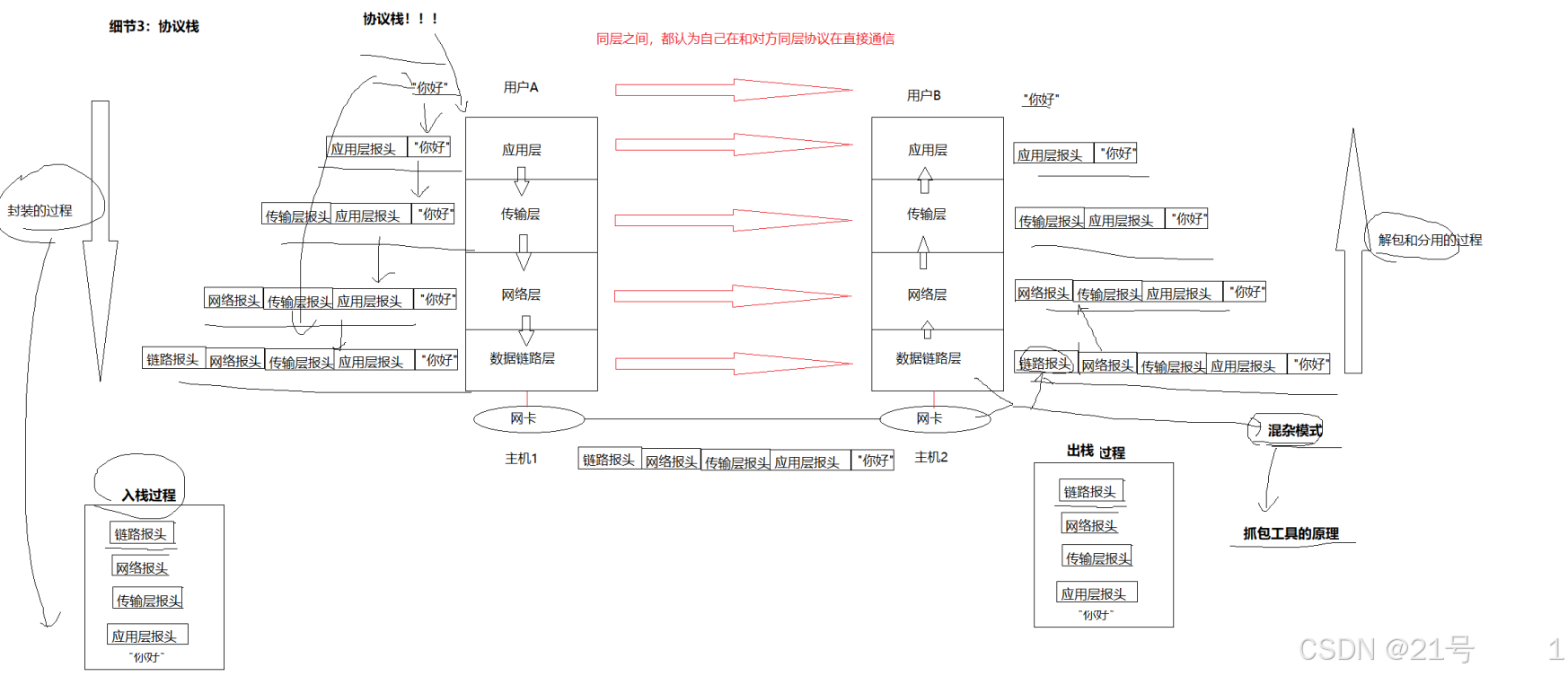
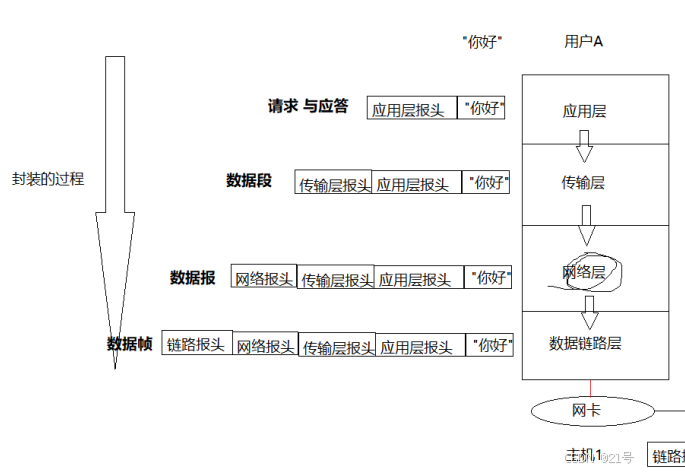
在网络传输的过程中,数据不是直接发送给对方主机的,而是先要自定向下将数据交 付给下层协议,最后由底层发送,然后由对方主机的底层来进行接受,在自底向上进 行向上交付。
3.2跨网络传输流程图
网络中的地址管理 - 认识 IP 地址
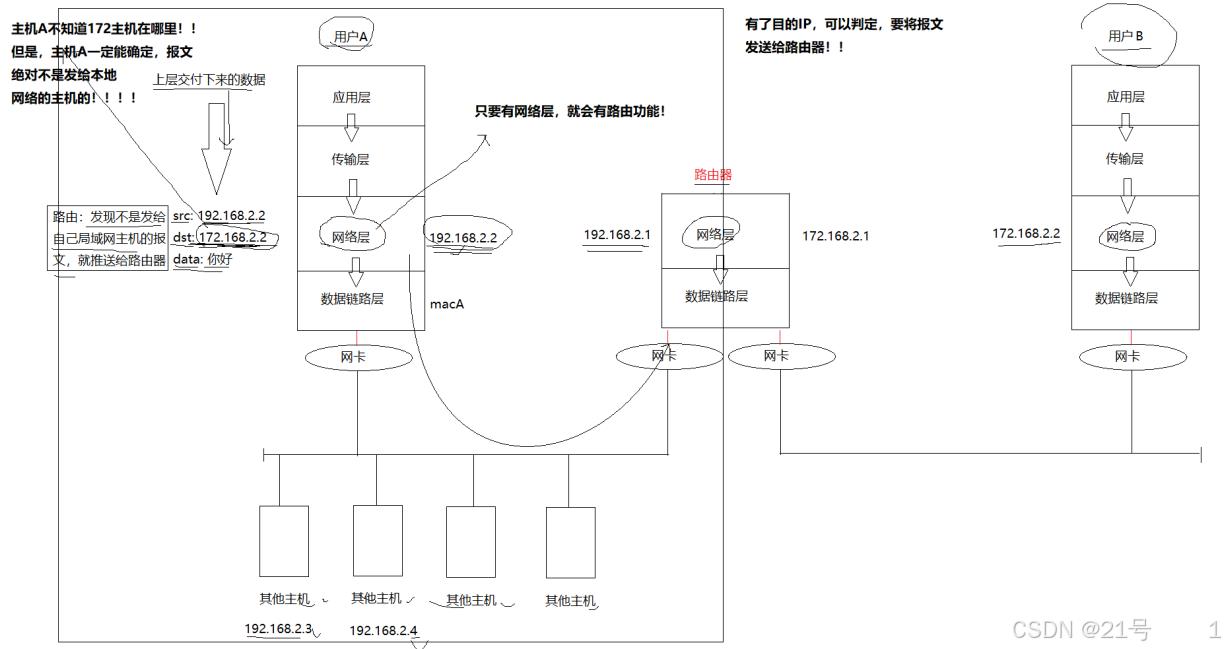 路由过程中,IP地址不变,mac地址一直在变,mac地址只会在本局域网内有效!!
路由过程中,IP地址不变,mac地址一直在变,mac地址只会在本局域网内有效!!
网络层+IP的本质意义:给网络提供了一层虚拟化层,让世界上所有的网络,都叫做IP网络!!
对比 IP 地址和 Mac 地址的区别• IP 地址在整个路由过程中,一直不变(目前,我们只能这样说明,后面在修正)
• Mac 地址一直在变
• 目的 IP 是一种长远目标,Mac 是下一阶段目标,目的 IP 是路径选择的重要依
据,mac 地址是局域网转发的重要依据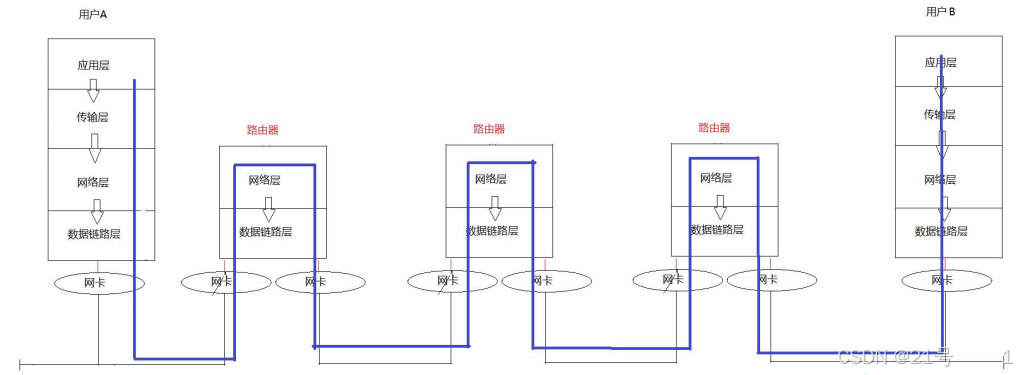
4.Socket编程预备
4.1理解源 IP 地址和目的 IP 地址
进程是人在系统中的代表,只要把数据给进程,人就相当于拿到了数据
数据传输到主机不是目的,而是手段。到达主机内部,再交给主机内的进程,才是目的。
但是系统中,同时会存在非常多的进程,当数据到达目标主机之后,怎么转发给目标进程?这就要在网络的背景下,在系统中,标识主机的唯一性
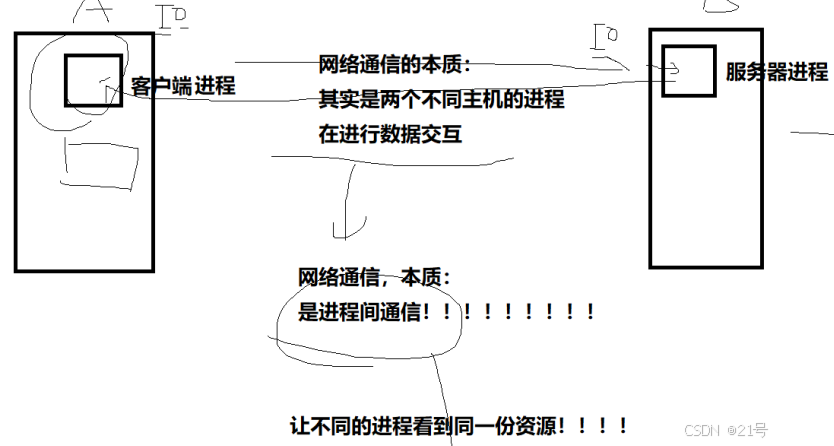
上网只有两种行为
1.从远端服务器,获取数据
2.本地数据,上传到远端服务器
4.2认识端口号(port)
端口号,可以用来标识系统中唯一的一个网络进程
端口号(port)是传输层协议的内容
• 端口号是一个 2 字节 16 位的整数;
• 端口号用来标识一个进程, 告诉操作系统, 当前的这个数据要交给哪一个进程来
处理;
• IP 地址 + 端口号能够标识网络上的某一台主机的某一个进程;
• 一个端口号只能被一个进程占用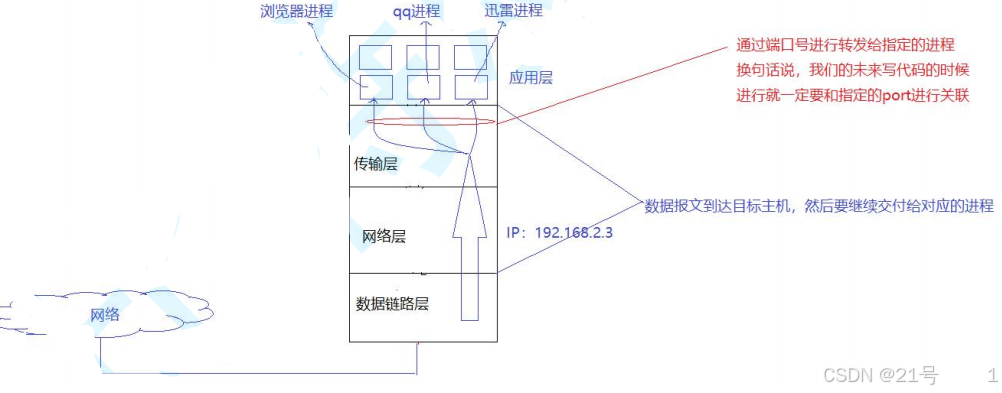 端口号范围划分
端口号范围划分
• 0 - 1023: 知名端口号, HTTP, FTP, SSH 等这些广为使用的应用层协议, 他们的
端口号都是固定的.
• 1024 - 65535: 操作系统动态分配的端口号. 客户端程序的端口号, 就是由操作
系统从这个范围分配的.理解 "端口号" 和 "进程 ID"
理解 socket
• 综上,IP 地址用来标识互联网中唯一的一台主机,port 用来标识该主机上唯一的
一个网络进程
IP + Port = 全网内唯一的一个进程• IP+Port 就能表示互联网中唯一的一个进程
• 所以,通信的时候,本质是两个互联网进程代表人来进行通信,{srcIp,
srcPort,dstIp,dstPort}这样的 4 元组就能标识互联网中唯二的两个进程
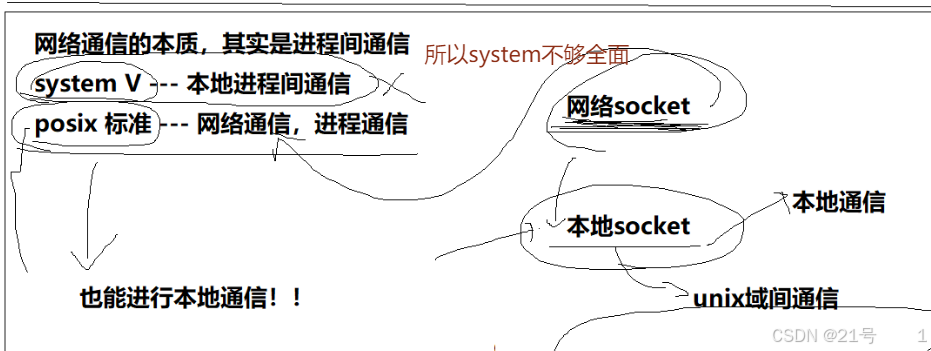
• 所以,网络通信的本质,也是进程间通信
• 我们把 ip+port 叫做套接字 socket4.3传输层的典型代表
认识 TCP 协议
• 传输层协议
• 有连接
• 可靠传输
• 面向字节流认识 UDP 协议
• 传输层协议
• 无连接
• 不可靠传输
• 面向数据报4.4网络字节序
• 发送主机通常将发送缓冲区中的数据按内存地址从低到高的顺序发出;
• 接收主机把从网络上接到的字节依次保存在接收缓冲区中,也是按内存地址从
低到高的顺序保存;
• 因此,网络数据流的地址应这样规定:先发出的数据是低地址,后发出的数据是高
地址.
• TCP/IP 协议规定,网络数据流应采用大端字节序,即低地址高字节.
• 不管这台主机是大端机还是小端机, 都会按照这个 TCP/IP 规定的网络字节序来
发送/接收数据;
• 如果当前发送主机是小端, 就需要先将数据转成大端; 否则就忽略, 直接发送即
可;大端 --- 高存低,低存高
小端 --- 高存高,低存低
• 这些函数名很好记,h 表示 host,n 表示 network,l 表示 32 位长整数,s 表示 16 位
短整数。
• 例如 htonl 表示将 32 位的长整数从主机字节序转换为网络字节序,例如将 IP 地
址转换后准备发送。
• 如果主机是小端字节序,这些函数将参数做相应的大小端转换然后返回;
• 如果主机是大端字节序,这些函数不做转换,将参数原封不动地返回。
4.5 socket编程接口
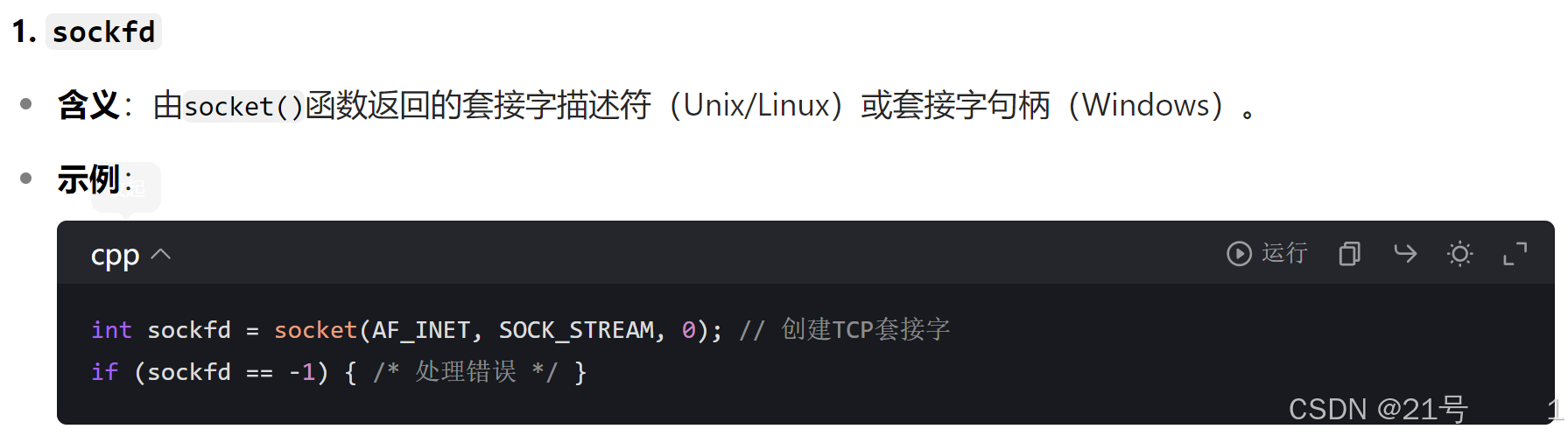
1. 创建 socket 文件描述符 (TCP/UDP, 客户端 + 服务器)
int socket(int domain, int type, int protocol);



2. 绑定端口号 (TCP/UDP, 服务器)
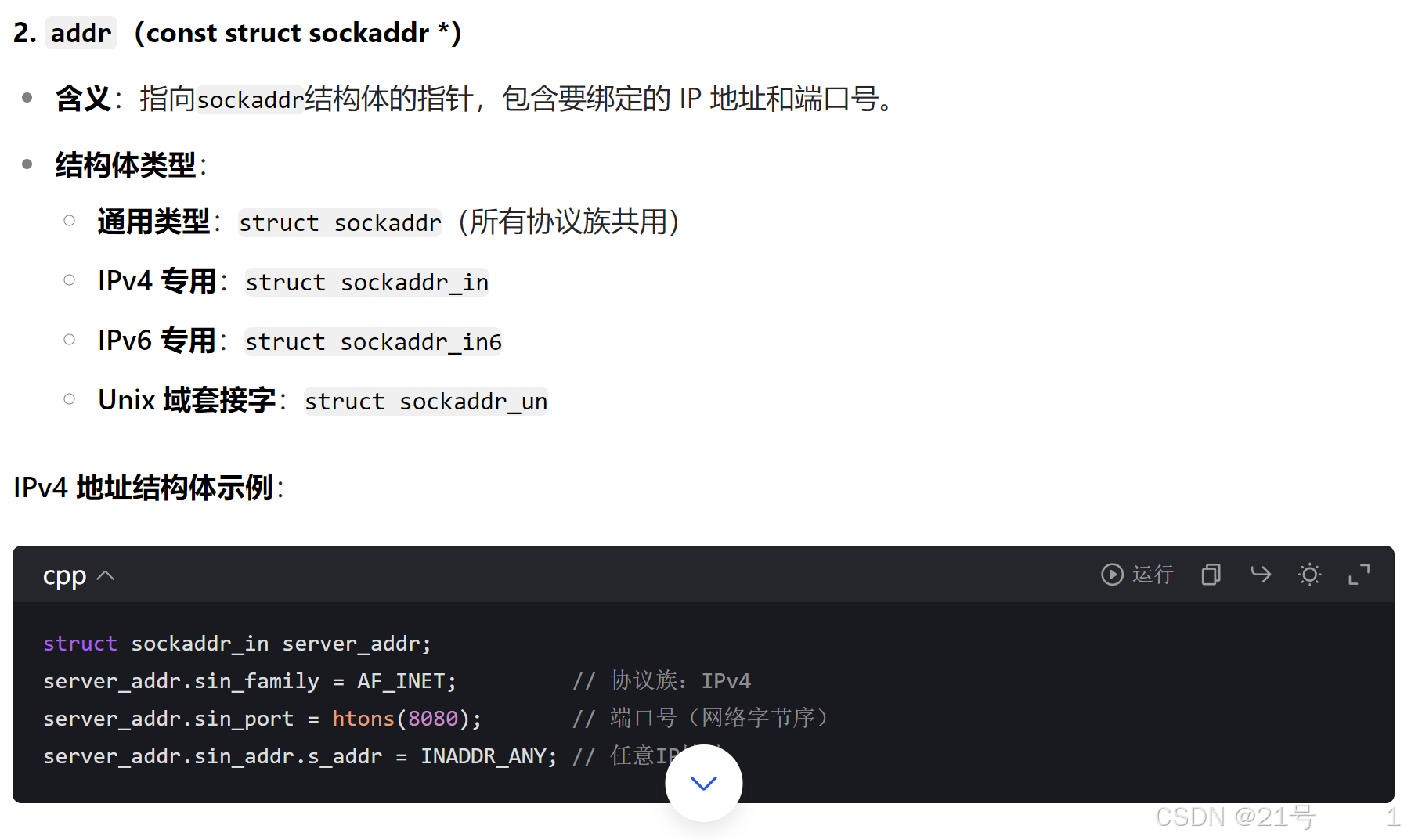
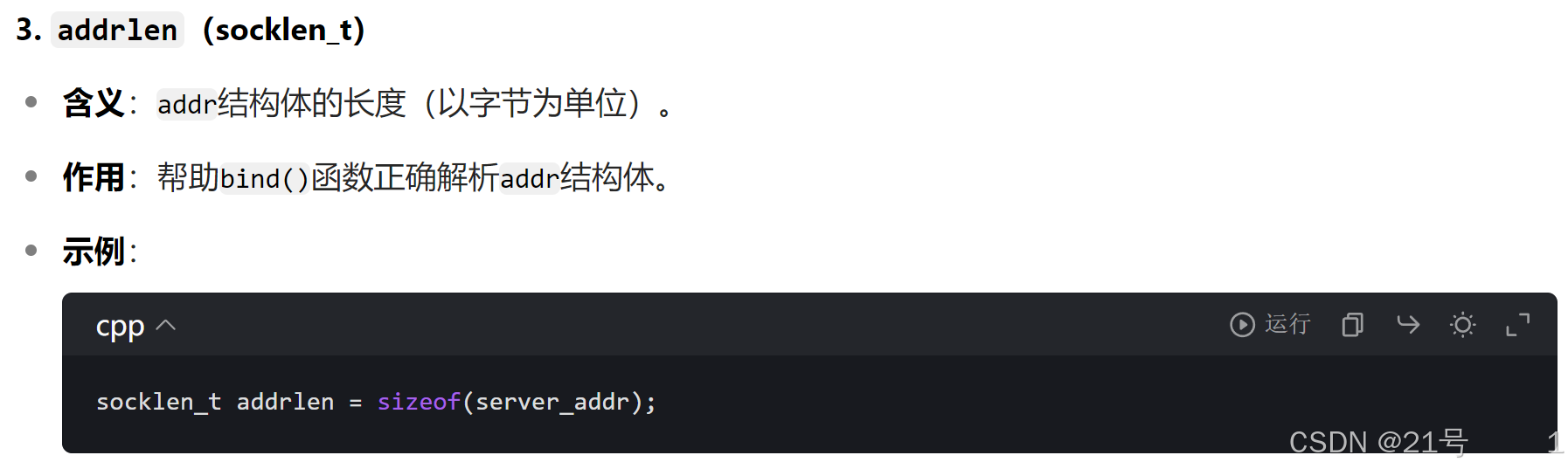
3. 开始监听 socket (TCP, 服务器)
listen() 函数用于将主动套接字(由 socket() 创建)转换为被动套接字,使其能够接受客户端的连接请求


4. 接收请求 (TCP, 服务器)
accept()函数用于从监听队列中提取一个已建立的连接,并返回一个新的套接字描述符用于与客户端通信
5. 建立连接 (TCP, 客户端)
connect()函数用于客户端向服务器发起连接请求。它将主动套接字(由socket()创建)与服务器的地址和端口绑定,建立 TCP 连接或指定 UDP 通信的默认目标地址
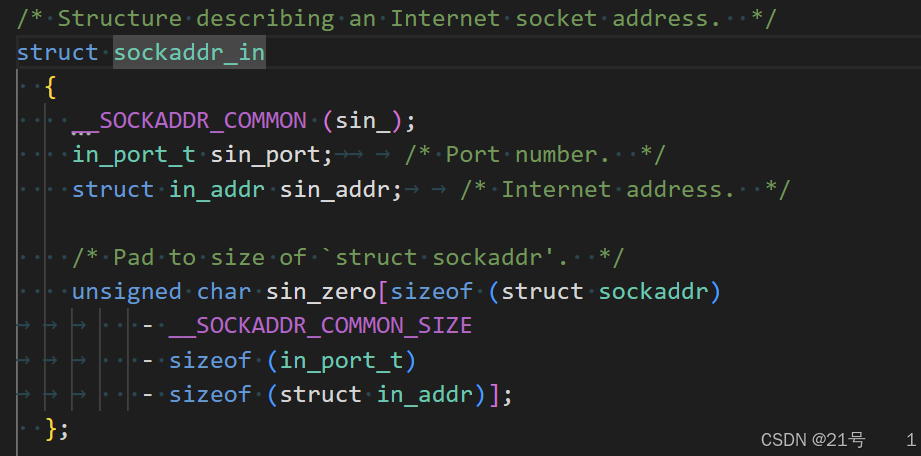
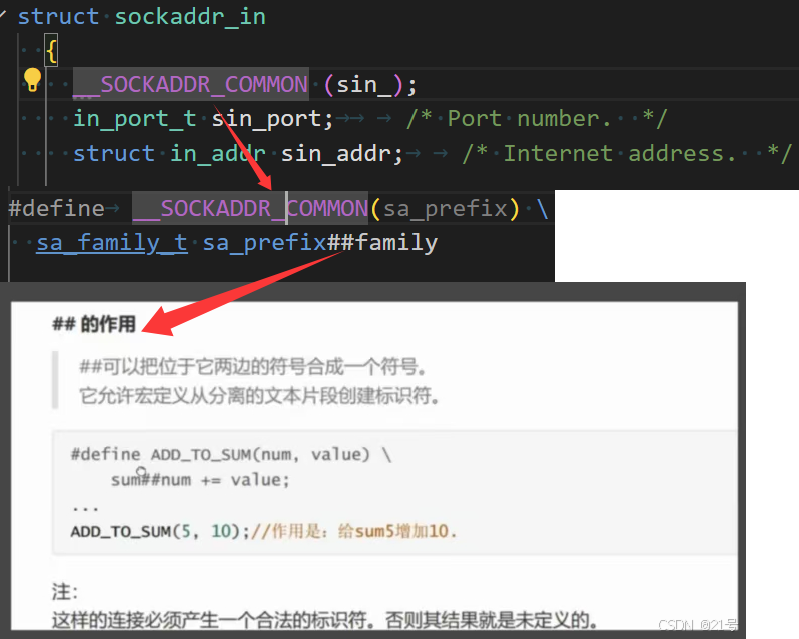
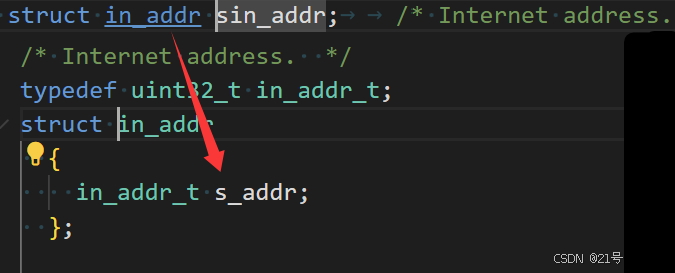
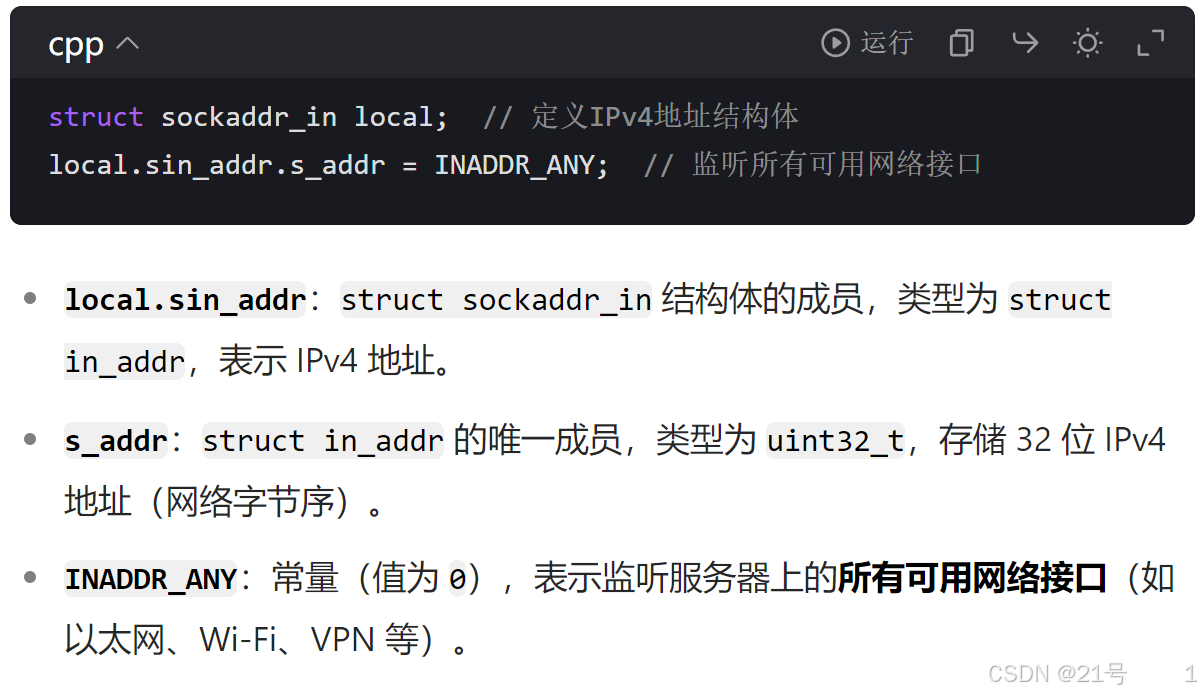
sockaddr 结构
socket API 是一层抽象的网络编程接口,适用于各种底层网络协议,如 IPv4、IPv6,以及 后面要讲的 UNIX Domain Socket. 然而, 各种网络协议的地址格式并不相同.
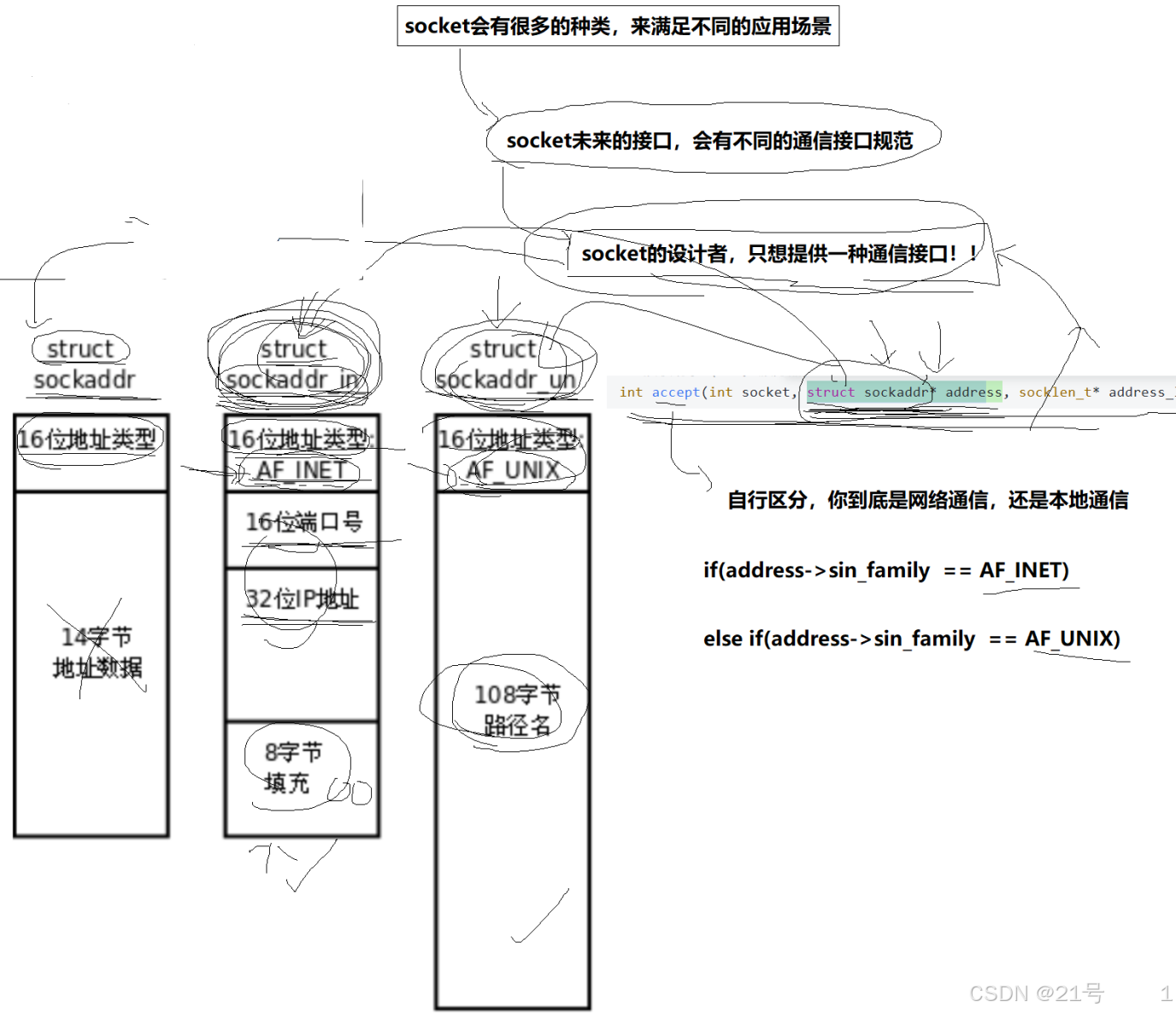
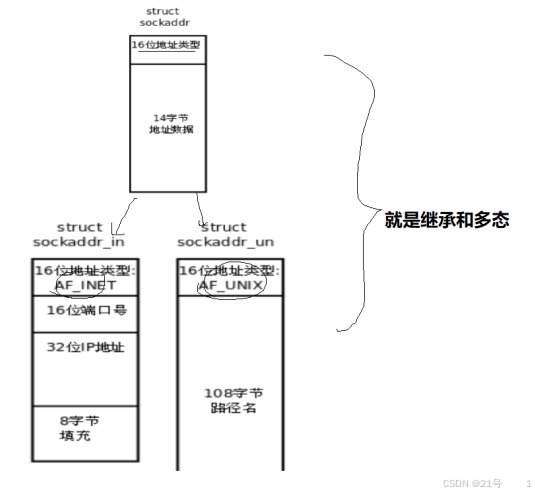
代码实现
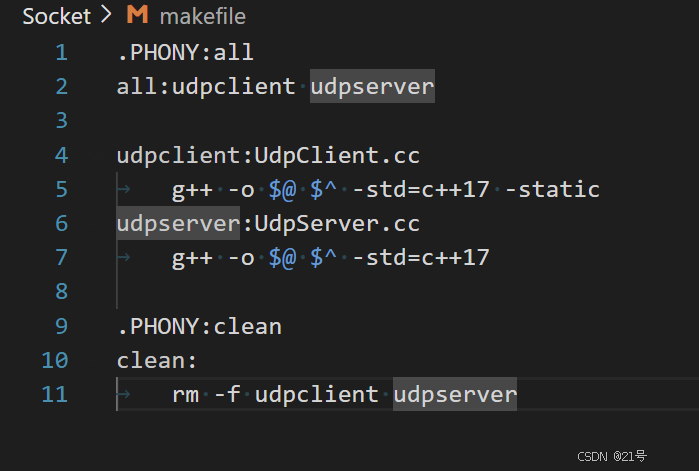
makefile:
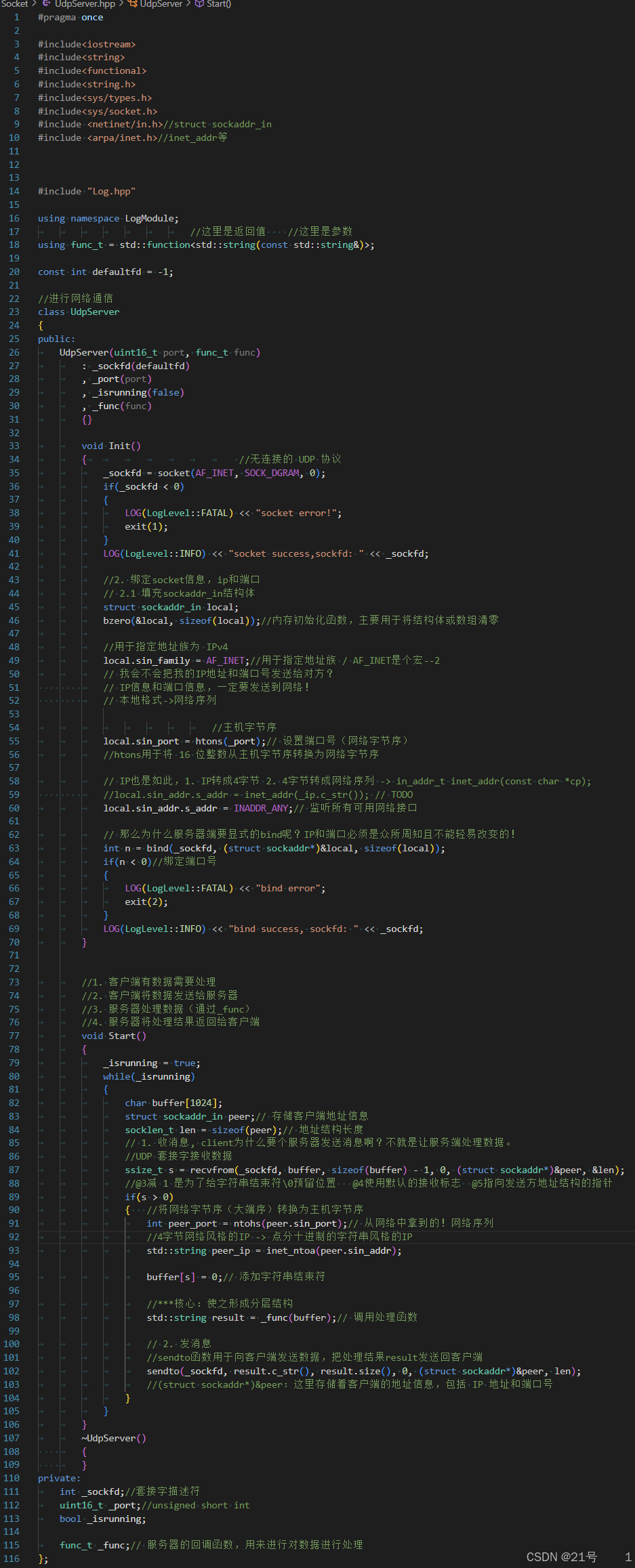
UdpServer.hpp:
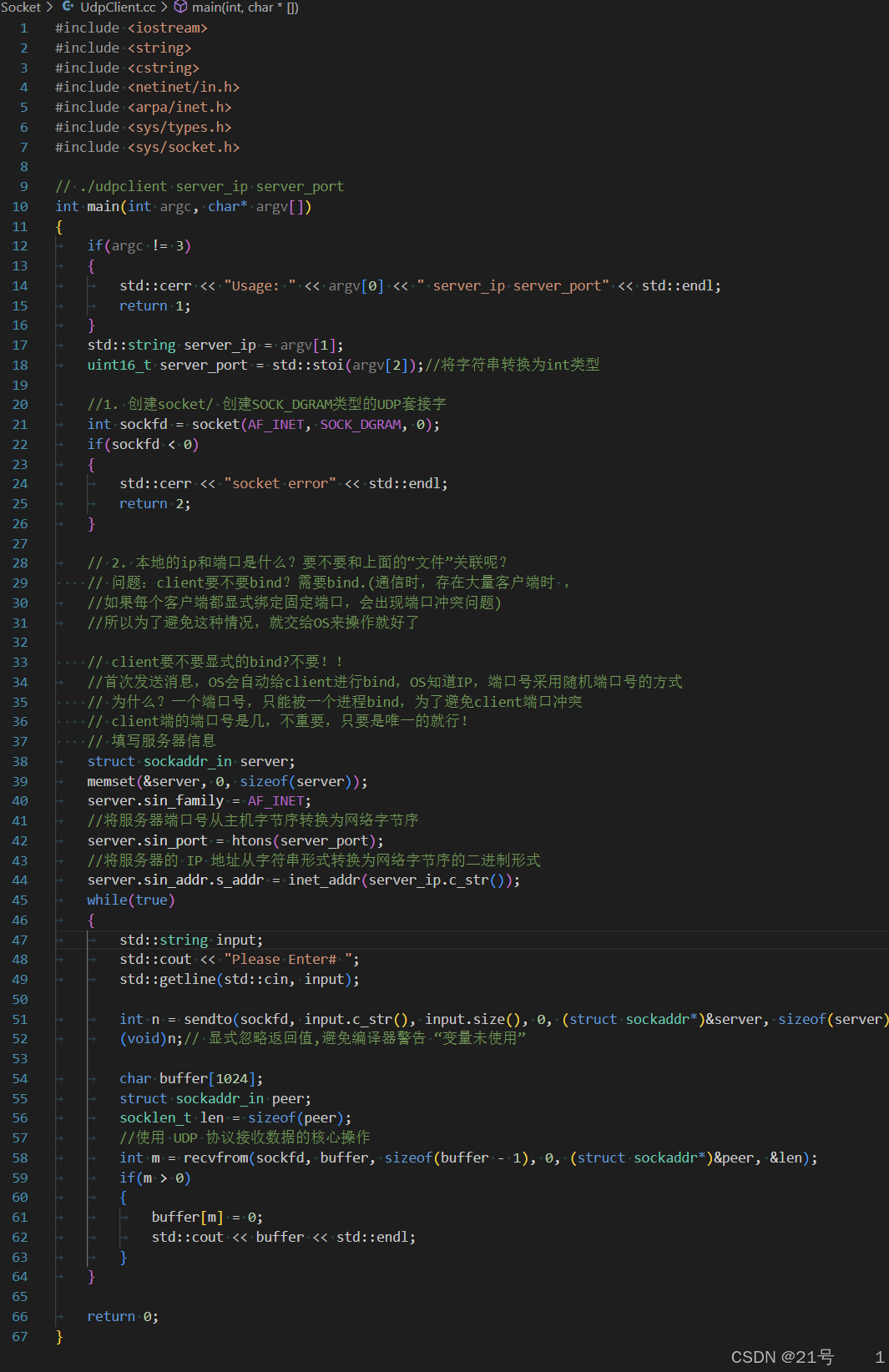
UdpClient.cc:
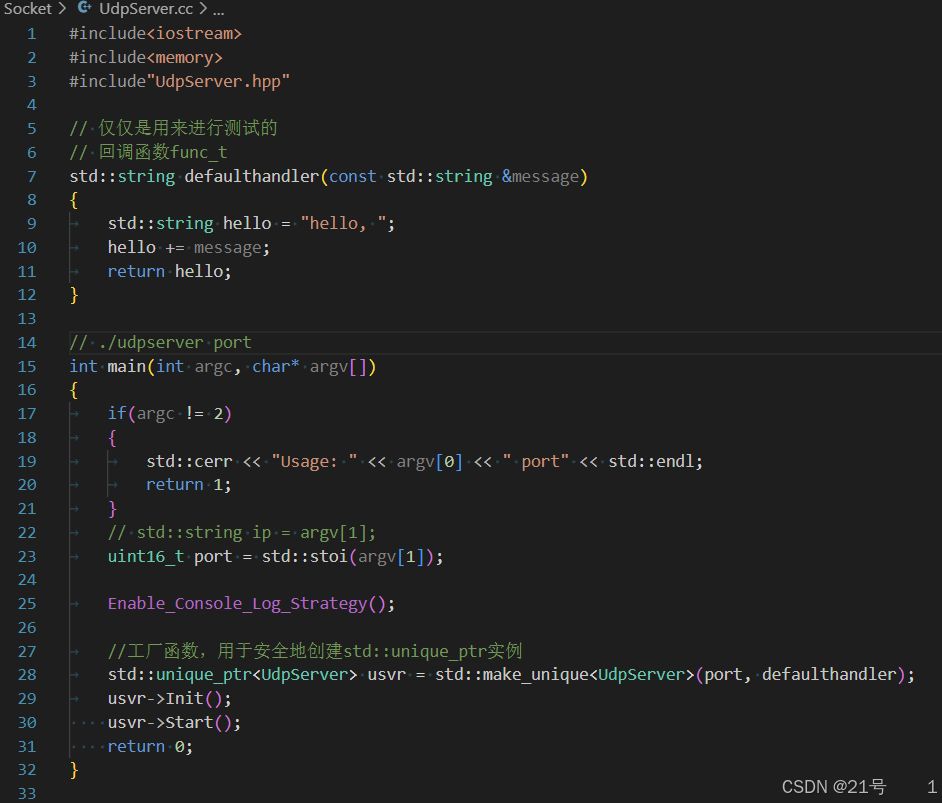
UdpServer.cc:
Mutex.hpp:
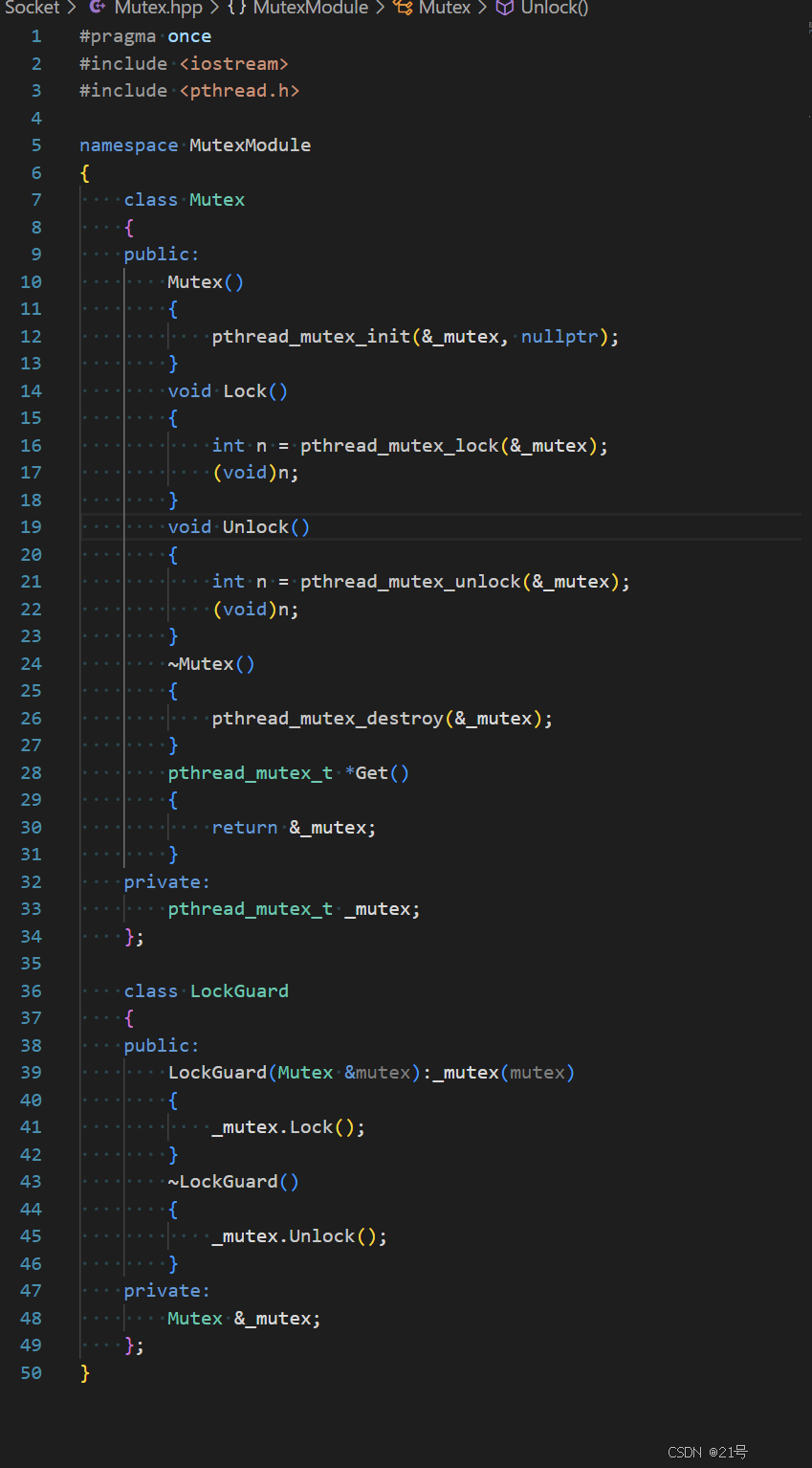 Log.hpp:
Log.hpp:

附录:
p45

p60

p79
