6月10日day50打卡
预训练模型+CBAM模块
知识点回顾:
- resnet结构解析
- CBAM放置位置的思考
- 针对预训练模型的训练策略
- 差异化学习率
- 三阶段微调


作业:
- 好好理解下resnet18的模型结构
- 尝试对vgg16+cbam进行微调策略
可以把这个模型想象成一个「图像特征挖掘工厂」,用生活中的场景来类比理解:
1. 工厂大门:初始处理(前几层)
- Conv2d(卷积层):就像工厂入口的「基础筛网」。输入是一张3通道的彩色图片(RGB),这里用64个不同的「小筛子」(卷积核)扫描图片,每个筛子能提取不同的基础特征(比如边缘、颜色块),输出64张「基础特征图」(尺寸112x112)。
- BatchNorm2d(批量归一化):相当于「标准化车间」。把前面提取的特征值调整到统一的「舒适范围」(比如均值0,方差1),避免后续处理时数据波动太大,就像给工人统一工具尺寸,防止操作混乱。
- ReLU(激活函数):是「有用信息过滤器」。只保留特征中的正数部分(有用信息),过滤掉负数(无用信息),相当于把筛出来的杂质扔掉,只留需要加工的材料。
- MaxPool2d(最大池化):是「信息浓缩器」。把每个特征图中最突出的部分(最大值)保留下来,同时缩小图片尺寸(从112x112→56x56),就像把大堆材料压缩成小而精的「核心材料块」,减少后续处理量。
2. 核心车间:残差块(BasicBlock)
这部分是工厂的「核心加工区」,由多个「残差小组」(BasicBlock)组成,每个小组负责「升级特征」。
比如第一个残差小组(2-1)里有两个卷积层:
- 第一层卷积:用64个筛子进一步提取更细的特征(比如从边缘到纹理);
- 第二层卷积:再用64个筛子提炼更复杂的特征(比如从纹理到简单图案);
- 关键操作:最后把原始输入(未加工的材料)和提炼后的特征相加(跳跃连接)。就像工人加工材料时,发现直接扔掉原始材料容易丢信息,于是把原始材料和加工后的材料混合,确保「老信息不丢失」,避免深层加工时「信息断层」(梯度消失)。
随着层数加深(Sequential模块1-5到1-8),工厂的「加工精度」逐步升级:
- 通道数从64→128→256→512(相当于筛子数量变多,能提取更复杂的特征,比如从简单图案到物体局部,再到整体);
- 特征图尺寸从56x56→28x28→14x14→7x7(材料块越缩越小,聚焦核心信息)。
3. 收尾阶段:分类决策
- AdaptiveAvgPool2d(自适应平均池化):是「最终浓缩机」。不管前面的特征图多大(7x7),都压缩成1x1的小方块,把每个通道的信息汇总成一个数值(512个数值),就像把所有加工好的材料块压成512颗「信息颗粒」。
- Linear(全连接层):是「分类裁判」。把512颗信息颗粒通过全连接层,映射到1000个类别(比如狗、猫、飞机),输出每个类别的概率,就像裁判根据所有材料,最终判断「这是什么东西」。
总结
整个模型就像一个多层级的「图像特征挖掘流水线」:从最基础的边缘提取开始,逐步升级到复杂特征(纹理→局部→整体),通过「残差小组」避免信息丢失,最后用「浓缩+裁判」两步完成分类。总共有1100多万个「小工人」(参数)在协作,确保能精准挖掘图片里的细节。
“(7×7, stride=2)” 是深度学习中卷积层(或池化层)的两个关键参数,用生活中的场景打个比方解释:
1. 7×7:「观察窗口的大小」
假设你有一张大照片(比如输入的特征图或原始图片),需要用一个「小窗口」去扫描它,提取局部特征。这里的 7×7 就是这个小窗口的尺寸——它的宽度和高度都是7个像素(像一个7行7列的格子)。
比如,如果你在看一张猫的照片,7×7的窗口能同时“看到”猫的眼睛、鼻子周围的一片区域(比3×3的窗口看得更广),适合捕捉更大范围的局部特征(比如纹理、简单图案)。
2. stride=2:「窗口滑动的步长」
stride(步长) 是每次移动窗口的距离。stride=2 表示:扫描完一个窗口后,窗口向右(或向下)移动2个像素,再扫描下一个位置。
比如擦玻璃时,你用一块7×7的抹布擦窗户,每次移动2厘米(而不是1厘米)。这样做的好处是:
- 减少计算量:窗口移动更快,覆盖的位置更少,处理的数据量更小;
- 缩小输出尺寸:假设输入图片是224×224像素,用7×7窗口+stride=2扫描后,输出的特征图尺寸会变成 (224-7)/2 + 1 ≈ 109×109(约缩小一半),相当于“浓缩”了信息。
总结
“7×7, stride=2” 就像用一个7×7的“观察窗”在图片上扫描,每次跳2个像素。它的作用是:
- 7×7:捕捉更大范围的局部特征;
- stride=2:减少计算量,同时让输出的特征图更小(信息更浓缩)。
这种组合常见于模型的初始层(比如ResNet的第一层卷积),用来快速提取粗粒度特征并降低后续处理的复杂度。
“下采样(Downsampling)”,常见于图像处理或深度学习领域。用生活场景打个比方解释:
简单来说
假设你有一张1000×1000像素的高清照片(比如拍的风景),但手机屏幕只能显示200×200像素的缩略图。这时候需要把大图片“缩小”成小尺寸,同时保留主要内容(比如山、树的轮廓),这个过程就是「下采样」(下采集)。
在技术中的作用
下采样的核心是减少数据规模,同时保留关键信息。常见场景有2种:
-
图像处理:
把大尺寸图片缩小(比如1000×1000→200×200),减少存储或传输的开销(就像发朋友圈时自动压缩图片)。 -
深度学习(如CNN):
模型的卷积层后常跟下采样(比如最大池化Max Pooling),作用是:- 降低计算量:特征图尺寸缩小(比如56×56→28×28),后续处理的数据量减少;
- 聚焦关键特征:通过“取最大值”(最大池化)保留最显著的特征(比如边缘、纹理),过滤掉细节噪声;
- 防止过拟合:减少特征维度,避免模型过度关注无关细节。
常见实现方式
- 最大池化(Max Pooling):用一个小窗口(如2×2)扫描特征图,取窗口内的最大值作为输出(保留最突出的特征);
- 平均池化(Average Pooling):取窗口内的平均值(保留整体强度,弱化局部突出值);
- 步长卷积(Strided Convolution):卷积时让卷积核每次移动更大的步长(如stride=2),直接缩小特征图尺寸。
总结
“下采集(下采样)”就像给数据“拍缩略图”,通过缩小尺寸或降低精度,在保留核心信息的同时减少计算或存储压力,是图像处理和深度学习中常用的“轻量化”操作。
“让网络层学习残差” 是ResNet(残差网络)的核心思想,用生活场景打个比方就能轻松理解:
1. 什么是“残差”?
假设你要从A点到B点,直接走的路线是“全程”(目标函数 ( H(x) ))。但如果已经知道从A到C的路线(当前输出 ( x )),那么剩下的“C到B的路线”就是 残差(( H(x) - x ))。
放到神经网络里:原本网络想直接学习 ( H(x) )(从输入 ( x ) 直接映射到目标输出),但ResNet让网络改学 ( H(x) - x )(残差),然后通过“跳跃连接”把 ( x ) 和残差相加,得到最终 ( H(x) )。
2. 为什么要学“残差”?
传统神经网络的问题:网络层数越深,梯度在反向传播时越容易“消失”(变得极小,无法更新参数),导致模型学不会复杂特征。
而“学残差”相当于给网络“降低难度”:
- 如果 ( H(x) ) 很难直接学(比如深层网络),但 ( H(x) - x ) 可能更简单(因为 ( x ) 已经是当前层的输入,相当于“已知部分”);
- 即使残差学不好(比如输出0),网络也能通过跳跃连接保留原始输入 ( x )(至少“不变差”),避免深层网络的“退化问题”(层数增加但效果下降)。
用学生做题打比方
假设学生要解一道难题 ( H(x) )(比如“1000道综合题”):
- 传统方法:直接让学生学 ( H(x) )(从0开始解1000题),可能因为太难而放弃(梯度消失,学不会);
- ResNet的方法:先让学生做 ( x )(比如“已经会解800题”),然后只学残差 ( H(x)-x )(剩下的200题)。这样学生只需要补差距,更容易掌握(梯度更易传递,学得更好)。
总结
“让网络层学习残差” 就是让网络专注学“目标输出与当前输入的差距”,而不是直接学目标输出。它像“补短板”一样降低学习难度,解决了深层网络梯度消失的问题,让模型能训练得更深、效果更好。
“标准残差”和“下采样残差”是ResNet(残差网络)中两种常见的残差块设计,核心区别在于输入与输出的特征图尺寸/通道数是否一致。用生活场景打个比方解释:
1. 标准残差(Standard Residual Block)
一句话总结:输入和输出的特征图尺寸、通道数完全相同,跳跃连接直接“原路叠加”。
结构比喻
假设你在玩“拼图游戏”:
- 输入是一张56×56像素、64通道的特征图(相当于“64种颜色的56×56拼图”);
- 经过残差块的两个卷积层处理后,输出还是56×56像素、64通道(拼图尺寸和颜色种类没变);
- 此时,输入的原始拼图(x)可以直接和处理后的拼图(F(x))叠加(x + F(x)),就像“在原图上直接贴新图案”。
关键特点
- 没有下采样(特征图尺寸不变,如56×56→56×56);
- 通道数不变(如64→64);
- 跳跃连接是“直连”(Identity Shortcut),无需额外调整。
作用
用于网络的“深化”:在不改变特征图尺寸的前提下,通过叠加多个残差块让网络更深,学习更复杂的特征(比如从纹理→简单图案)。
2. 下采样残差(Downsampling Residual Block)
一句话总结:输入和输出的特征图尺寸或通道数不同,需要调整输入后再叠加(跳跃连接需“投影”)。
结构比喻
还是拼图游戏,但这次要“升级难度”:
- 输入是56×56像素、64通道的拼图;
- 残差块需要输出28×28像素、128通道的拼图(尺寸缩小一半,颜色种类翻倍);
- 此时原始输入(56×56、64通道)无法直接和输出(28×28、128通道)叠加,必须先对原始输入做“调整”:
- 用1×1卷积(相当于“缩小拼图尺寸+增加颜色种类”),把原始输入变成28×28、128通道;
- 再和处理后的输出叠加(调整后的x + F(x)),就像“把旧拼图缩小、加颜色后,再和新拼图叠加”。
关键特点
- 包含下采样(特征图尺寸缩小,如56×56→28×28);
- 通道数增加(如64→128);
- 跳跃连接是“投影”(Projection Shortcut),需用1×1卷积调整输入的尺寸或通道数。
作用
用于网络的“层级升级”:通过缩小特征图尺寸(减少计算量)、增加通道数(学习更复杂特征),让模型从“局部特征”过渡到“整体抽象特征”(比如从简单图案→物体局部→物体整体)。
总结
- 标准残差:输入输出“尺寸/通道一致”,直接叠加,用于深化网络;
- 下采样残差:输入输出“尺寸/通道不同”,需调整输入后叠加,用于升级网络层级(缩小尺寸、增加通道)。
两者配合,让ResNet既能训练得很深(标准残差防梯度消失),又能适应不同层级的特征提取需求(下采样残差调尺寸/通道)。
要理解“CBAM放在全连接层前导致空间注意力消失”的问题,需要先明确CBAM(卷积注意力模块)的核心机制和全连接层(FC层)的作用:
1. CBAM的空间注意力依赖二维空间信息
CBAM的空间注意力模块(Spatial Attention)需要**二维的空间维度(H×W)**来计算注意力权重。具体来说:
- 输入是特征图 ( F \in \mathbb{R}^{C \times H \times W} )(C通道,H高,W宽);
- 空间注意力会对通道维度做全局池化(最大池化+平均池化),得到两个 ( 1 \times H \times W ) 的特征图;
- 拼接后通过卷积生成空间注意力图 ( M_s \in \mathbb{R}^{1 \times H \times W} ),用于加权原始特征图 ( F )(即 ( F' = F \odot M_s ))。
关键:空间注意力的计算完全依赖二维的 ( H \times W ) 空间结构,需要保留每个像素的空间位置信息。
2. 全连接层前的特征已失去空间维度
全连接层(FC层)的作用是将高维特征展平为一维向量(( \mathbb{R}^{C \times H \times W} \to \mathbb{R}^{N} ),其中 ( N = C \times H \times W )),用于最终的分类或回归。
如果CBAM放在FC层前,此时的特征已经历了两种可能的处理:
-
情况1:特征图被展平(如 ( 512 \times 7 \times 7 \to 25088 ) 维向量):
二维的 ( H \times W ) 空间位置信息被压缩成一维的顺序,无法区分每个元素对应的原始空间位置(比如第100个元素是原7×7特征图中的哪个坐标?无法确定)。此时空间注意力模块无法生成有效的 ( H \times W ) 注意力图。 -
情况2:特征图被全局池化(如 ( 512 \times 7 \times 7 \to 512 \times 1 \times 1 )):
空间维度被压缩为 ( 1 \times 1 ),空间注意力计算出的 ( M_s ) 也是 ( 1 \times 1 )(相当于一个标量)。此时注意力无法区分原始特征图中不同空间位置的重要性(所有位置被统一加权),空间注意力失去意义。
总结
CBAM的空间注意力依赖二维的 ( H \times W ) 空间信息,而全连接层前的特征已失去这种空间结构(展平为一维或压缩为1×1)。因此,空间注意力模块无法生成有效的二维注意力图,导致其“完全消失”(无法对特定空间区域加权)。
正确做法:CBAM应放在卷积层之后(保留 ( H \times W ) 空间维度),例如在ResNet的每个Stage末尾,这样才能有效利用空间注意力增强关键区域的特征。
CBAM(Convolutional Block Attention Module,卷积注意力模块)的核心是同时关注“哪些通道重要”和“哪些空间位置重要”,由两个子模块串行组成:通道注意力模块(Channel Attention)和空间注意力模块(Spatial Attention)。下面用通俗的步骤+比喻解释其实现:
一、通道注意力模块(关注“哪些通道重要”)
目标:筛选出对任务更关键的特征通道(比如识别猫时,更关注“胡须”“耳朵”对应的通道)。
实现步骤(以输入特征图 ( F \in \mathbb{R}^{C \times H \times W} ) 为例):
-
提取通道统计信息:
对输入特征图的空间维度(H×W)分别做两种池化:- 全局平均池化(GAP):计算每个通道的平均值,得到 ( \mathbf{F}_{avg} \in \mathbb{R}^{C \times 1 \times 1} )(反映通道的“整体分布”);
- 全局最大池化(GMP):提取每个通道的最大值,得到 ( \mathbf{F}_{max} \in \mathbb{R}^{C \times 1 \times 1} )(反映通道的“显著特征”)。
-
融合通道信息:
将 ( \mathbf{F}{avg} ) 和 ( \mathbf{F}{max} ) 输入同一个多层感知机(MLP),先通过一个全连接层降维(如C→C/r,r是压缩比),再通过另一个全连接层升维回C,得到两个通道权重向量 ( \mathbf{W}{avg} ) 和 ( \mathbf{W}{max} )。 -
生成通道注意力权重:
将 ( \mathbf{W}{avg} ) 和 ( \mathbf{W}{max} ) 相加后,通过Sigmoid激活函数(输出0-1),得到通道注意力图 ( M_c \in \mathbb{R}^{C \times 1 \times 1} )(每个值表示对应通道的重要性)。 -
加权特征图:
将原始特征图 ( F ) 与 ( M_c ) 按通道相乘(( F' = F \odot M_c )),增强重要通道的特征。
比喻:
假设你有一叠彩色透明胶片(C个通道,每个通道是H×W的胶片),通道注意力像“给每张胶片打光”——先统计每张胶片的整体亮度(GAP)和最亮的点(GMP),然后通过“调光器”(MLP)决定哪张胶片需要更亮(权重高),最后给对应胶片打光(加权)。
二、空间注意力模块(关注“哪些空间位置重要”)
目标:定位特征图中对任务更关键的空间区域(比如识别猫时,更关注脸部区域)。
实现步骤(输入是通道注意力后的特征图 ( F' \in \mathbb{R}^{C \times H \times W} )):
-
提取空间统计信息:
对输入特征图的通道维度(C)分别做两种池化:- 平均池化(AvgPool):计算每个空间位置的通道平均值,得到 ( \mathbf{F}'_{avg} \in \mathbb{R}^{1 \times H \times W} )(反映空间区域的“整体强度”);
- 最大池化(MaxPool):提取每个空间位置的通道最大值,得到 ( \mathbf{F}'_{max} \in \mathbb{R}^{1 \times H \times W} )(反映空间区域的“显著特征”)。
-
融合空间信息:
将 ( \mathbf{F}'{avg} ) 和 ( \mathbf{F}'{max} ) 沿通道维度拼接(得到 ( \mathbb{R}^{2 \times H \times W} )),通过一个7×7的卷积层(或3×3,视具体实现)降维到1个通道,生成空间注意力图 ( M_s \in \mathbb{R}^{1 \times H \times W} )(每个值表示对应空间位置的重要性)。 -
加权特征图:
将通道注意力后的特征图 ( F' ) 与 ( M_s ) 按空间位置相乘(( F'' = F' \odot M_s )),增强重要区域的特征。
比喻:
现在你有一张已经“打光”的胶片(通道注意力后的特征图),空间注意力像“给胶片的局部区域加滤镜”——先统计每个位置的整体亮度(AvgPool)和最亮点(MaxPool),然后通过“滤镜模板”(卷积层)决定哪些位置需要更清晰(权重高),最后给对应位置加滤镜(加权)。
总结
CBAM的注意力机制是“先通道后空间”的两步筛选:
- 通道注意力:筛选“重要的特征类型”(哪些通道更关键);
- 空间注意力:定位“重要的特征位置”(哪些区域更关键)。
通过两次加权,模型能更聚焦于对任务最有用的特征,提升性能。
“CBAM模块初始状态接近‘直通’” 可以理解为:CBAM在刚开始训练时,对输入特征的修改很小,几乎让特征“原样通过”,就像模块暂时“不起作用”一样。
用生活场景打个比方:
假设你有一个“智能滤镜”(CBAM模块),它的任务是自动增强照片中“重要的部分”(比如花朵)。但刚拿到这个滤镜时,它还没学会识别花朵,所以默认设置是“不调色、不模糊”——照片经过滤镜后和原图几乎一样(直通)。等用它处理了很多照片(训练后),它才会逐渐学会“花朵区域要更鲜艳,背景要模糊”(注意力生效)。
技术上的原因
CBAM的注意力权重(通道注意力 ( M_c ) 和空间注意力 ( M_s ))是通过神经网络(如MLP、卷积层)生成的,这些网络的参数在训练初期是随机初始化的。此时:
- 通道注意力 ( M_c ) 的权重接近1(比如Sigmoid激活后输出≈1),对输入特征的通道“不增强也不抑制”;
- 空间注意力 ( M_s ) 的权重也接近1,对输入特征的空间位置“不聚焦也不忽略”。
因此,输入特征 ( F ) 经过CBAM后得到 ( F'' = F \odot M_c \odot M_s \approx F \times 1 \times 1 = F ),相当于“直通”。
为什么要这样设计?
初始状态“直通”是为了让模型训练更稳定。如果CBAM一开始就强行修改特征(比如随机增强某些通道或区域),可能会破坏原始特征的分布,导致模型难以收敛。等训练一段时间后,CBAM逐渐学会“哪些特征重要”,才会调整权重,真正发挥注意力的作用。
Sigmoid函数是机器学习中常用的“数值转换器”,核心作用是把任意大的输入值“压缩”到 0到1之间,像一个“概率开关”或“软化的二值门”。用大白话+生活例子解释它的用途:
1. 二分类任务中的“概率转换器”
在逻辑回归(二分类模型)中,Sigmoid是“灵魂组件”。假设模型通过线性计算得到一个值 ( z )(可能是很大的正数或负数),Sigmoid能把 ( z ) 转成概率:
[ \sigma(z) = \frac{1}{1 + e^{-z}} ]
例子:判断邮件是否是垃圾邮件:
- 如果 ( z = 5 )(模型认为“很可能是垃圾”),( \sigma(5) \approx 0.993 )(99.3%的概率是垃圾邮件);
- 如果 ( z = -3 )(模型认为“很可能不是垃圾”),( \sigma(-3) \approx 0.048 )(4.8%的概率是垃圾邮件)。
Sigmoid的输出直接对应“是正类(如垃圾邮件)的概率”,方便设定阈值(比如≥0.5判为正类)。
2. 神经网络中的“非线性开关”
神经网络的隐藏层需要激活函数引入非线性(否则多层网络等价于单层)。Sigmoid的S型曲线能把线性变换(( Wx + b ))的输出“掰弯”,让网络能拟合复杂的非线性关系(比如图像中的边缘、纹理)。
例子:识别手写数字“8”:
- 输入像素值经过线性变换后可能是一个很大的数(如10)或很小的数(如-5);
- Sigmoid把它们转成0.999或0.007,相当于告诉下一层:“这个特征很重要(接近1)”或“可以忽略(接近0)”。
如果没有Sigmoid(只用线性变换),无论多少层网络都只能拟合直线关系,无法处理复杂任务。
3. 注意力机制中的“权重生成器”
在注意力模块(如CBAM)中,Sigmoid用来生成0-1的注意力权重,控制特征的“增强”或“抑制”。
例子:CBAM的通道注意力模块中,Sigmoid输出一个通道权重(如0.8),表示“这个通道的特征重要性是80%”。原始特征乘以这个权重后,重要通道被保留(0.8×原特征),不重要的通道被削弱(如0.2×原特征)。
总结
Sigmoid的核心是“压缩数值+输出概率”:
- 分类任务中:把模型的线性输出转成概率(0-1),方便判断类别;
- 神经网络中:引入非线性,让网络能学习复杂模式;
- 注意力机制中:生成0-1的权重,控制特征的重要性。
它就像一个“智能阀门”,把任意大的输入“调节”成有意义的概率或权重,是机器学习中最经典的“数值翻译官”。
CBAM的有效性取决于任务需求和数据特点,用大白话总结它“有用”和“无用”的场景:
一、CBAM有用的情况
当任务需要模型聚焦关键特征,且数据中存在显著的局部/通道重要性差异时,CBAM能明显提升效果:
1. 特征冗余高的复杂任务
- 例子:图像分类(如ImageNet)、目标检测(如COCO)、医学影像分析(如肿瘤识别)。
- 原因:这些任务的输入(如图像)包含大量冗余信息(背景、噪声),CBAM的通道注意力能筛选关键特征类型(如“肿瘤边缘”对应的通道),空间注意力能定位关键区域(如肿瘤位置),帮助模型忽略无关信息。
2. 关键特征局部性强的场景
- 例子:细粒度分类(如区分不同品种的狗)、遥感图像分析(如识别特定地物)。
- 原因:这些任务的关键特征(如狗的耳朵形状、地物的纹理)集中在局部区域,CBAM的空间注意力能“放大”这些区域,避免模型被背景干扰。
3. 深层网络的特征增强
- 例子:ResNet-50/101等深层模型。
- 原因:深层网络的特征图可能因层数加深而“模糊”,CBAM能通过注意力重新激活关键特征,缓解“特征退化”问题。
二、CBAM无用(甚至有害)的情况
当任务无需额外聚焦或计算资源受限时,CBAM可能效果有限,甚至拖慢模型:
1. 简单任务或小数据集
- 例子:MNIST手写数字分类、简单的二分类(如判断图片是否为猫)。
- 原因:这些任务的特征本身很简单(如数字的轮廓、猫的大致形状),模型无需额外注意力即可轻松学习。CBAM的注意力计算反而可能引入冗余,增加训练时间。
2. 轻量级模型或实时任务
- 例子:MobileNet、实时目标检测(如自动驾驶中的实时障碍物识别)。
- 原因:轻量级模型追求“速度+精度”的平衡,CBAM会增加计算量(额外的卷积和池化操作),可能导致推理时间变长,性价比低。
3. 关键特征均匀分布的场景
- 例子:纹理均匀的图像(如纯色背景的产品图)、全局特征主导的任务(如场景分类中的“天空”占比判断)。
- 原因:这些任务的关键特征(如产品的整体形状、天空的大面积区域)分布均匀,CBAM的空间注意力无法找到“局部重点”,通道注意力也难以筛选出“更重要的通道”,注意力权重接近1(相当于无效操作)。
总结
CBAM是“特征聚焦工具”,在需要突出局部/关键特征的复杂任务中有用,但在简单任务、轻量级模型或特征均匀的场景中可能无用。使用时需根据具体任务权衡“注意力带来的精度提升”和“计算开销”。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 定义通道注意力
class ChannelAttention(nn.Module):def __init__(self, in_channels, ratio=16):"""通道注意力机制初始化参数:in_channels: 输入特征图的通道数ratio: 降维比例,用于减少参数量,默认为16"""super().__init__()# 全局平均池化,将每个通道的特征图压缩为1x1,保留通道间的平均值信息self.avg_pool = nn.AdaptiveAvgPool2d(1)# 全局最大池化,将每个通道的特征图压缩为1x1,保留通道间的最显著特征self.max_pool = nn.AdaptiveMaxPool2d(1)# 共享全连接层,用于学习通道间的关系# 先降维(除以ratio),再通过ReLU激活,最后升维回原始通道数self.fc = nn.Sequential(nn.Linear(in_channels, in_channels // ratio, bias=False), # 降维层nn.ReLU(), # 非线性激活函数nn.Linear(in_channels // ratio, in_channels, bias=False) # 升维层)# Sigmoid函数将输出映射到0-1之间,作为各通道的权重self.sigmoid = nn.Sigmoid()def forward(self, x):"""前向传播函数参数:x: 输入特征图,形状为 [batch_size, channels, height, width]返回:调整后的特征图,通道权重已应用"""# 获取输入特征图的维度信息,这是一种元组的解包写法b, c, h, w = x.shape# 对平均池化结果进行处理:展平后通过全连接网络avg_out = self.fc(self.avg_pool(x).view(b, c))# 对最大池化结果进行处理:展平后通过全连接网络max_out = self.fc(self.max_pool(x).view(b, c))# 将平均池化和最大池化的结果相加并通过sigmoid函数得到通道权重attention = self.sigmoid(avg_out + max_out).view(b, c, 1, 1)# 将注意力权重与原始特征相乘,增强重要通道,抑制不重要通道return x * attention #这个运算是pytorch的广播机制## 空间注意力模块
class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super().__init__()self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):# 通道维度池化avg_out = torch.mean(x, dim=1, keepdim=True) # 平均池化:(B,1,H,W)max_out, _ = torch.max(x, dim=1, keepdim=True) # 最大池化:(B,1,H,W)pool_out = torch.cat([avg_out, max_out], dim=1) # 拼接:(B,2,H,W)attention = self.conv(pool_out) # 卷积提取空间特征return x * self.sigmoid(attention) # 特征与空间权重相乘## CBAM模块
class CBAM(nn.Module):def __init__(self, in_channels, ratio=16, kernel_size=7):super().__init__()self.channel_attn = ChannelAttention(in_channels, ratio)self.spatial_attn = SpatialAttention(kernel_size)def forward(self, x):x = self.channel_attn(x)x = self.spatial_attn(x)return ximport torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 数据预处理(与原代码一致)
train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 加载数据集(与原代码一致)
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=train_transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, transform=test_transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)import torch
import torch.nn as nn
from torchvision import models# 自定义ResNet18模型,插入CBAM模块
class ResNet18_CBAM(nn.Module):def __init__(self, num_classes=10, pretrained=True, cbam_ratio=16, cbam_kernel=7):super().__init__()# 加载预训练ResNet18self.backbone = models.resnet18(pretrained=pretrained) # 修改首层卷积以适应32x32输入(CIFAR10)self.backbone.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False)self.backbone.maxpool = nn.Identity() # 移除原始MaxPool层(因输入尺寸小)# 在每个残差块组后添加CBAM模块self.cbam_layer1 = CBAM(in_channels=64, ratio=cbam_ratio, kernel_size=cbam_kernel)self.cbam_layer2 = CBAM(in_channels=128, ratio=cbam_ratio, kernel_size=cbam_kernel)self.cbam_layer3 = CBAM(in_channels=256, ratio=cbam_ratio, kernel_size=cbam_kernel)self.cbam_layer4 = CBAM(in_channels=512, ratio=cbam_ratio, kernel_size=cbam_kernel)# 修改分类头self.backbone.fc = nn.Linear(in_features=512, out_features=num_classes)def forward(self, x):# 主干特征提取x = self.backbone.conv1(x)x = self.backbone.bn1(x)x = self.backbone.relu(x) # [B, 64, 32, 32]# 第一层残差块 + CBAMx = self.backbone.layer1(x) # [B, 64, 32, 32]x = self.cbam_layer1(x)# 第二层残差块 + CBAMx = self.backbone.layer2(x) # [B, 128, 16, 16]x = self.cbam_layer2(x)# 第三层残差块 + CBAMx = self.backbone.layer3(x) # [B, 256, 8, 8]x = self.cbam_layer3(x)# 第四层残差块 + CBAMx = self.backbone.layer4(x) # [B, 512, 4, 4]x = self.cbam_layer4(x)# 全局平均池化 + 分类x = self.backbone.avgpool(x) # [B, 512, 1, 1]x = torch.flatten(x, 1) # [B, 512]x = self.backbone.fc(x) # [B, 10]return x# 初始化模型并移至设备
model = ResNet18_CBAM().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', patience=3, factor=0.5)import time# ======================================================================
# 4. 结合了分阶段策略和详细打印的训练函数
# ======================================================================
def set_trainable_layers(model, trainable_parts):print(f"\n---> 解冻以下部分并设为可训练: {trainable_parts}")for name, param in model.named_parameters():param.requires_grad = Falsefor part in trainable_parts:if part in name:param.requires_grad = Truebreakdef train_staged_finetuning(model, criterion, train_loader, test_loader, device, epochs):optimizer = None# 初始化历史记录列表,与你的要求一致all_iter_losses, iter_indices = [], []train_acc_history, test_acc_history = [], []train_loss_history, test_loss_history = [], []for epoch in range(1, epochs + 1):epoch_start_time = time.time()# --- 动态调整学习率和冻结层 ---if epoch == 1:print("\n" + "="*50 + "\n🚀 **阶段 1:训练注意力模块和分类头**\n" + "="*50)set_trainable_layers(model, ["cbam", "backbone.fc"])optimizer = optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=1e-3)elif epoch == 6:print("\n" + "="*50 + "\n✈️ **阶段 2:解冻高层卷积层 (layer3, layer4)**\n" + "="*50)set_trainable_layers(model, ["cbam", "backbone.fc", "backbone.layer3", "backbone.layer4"])optimizer = optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=1e-4)elif epoch == 21:print("\n" + "="*50 + "\n🛰️ **阶段 3:解冻所有层,进行全局微调**\n" + "="*50)for param in model.parameters(): param.requires_grad = Trueoptimizer = optim.Adam(model.parameters(), lr=1e-5)# --- 训练循环 ---model.train()running_loss, correct, total = 0.0, 0, 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 记录每个iteration的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append((epoch - 1) * len(train_loader) + batch_idx + 1)running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 按你的要求,每100个batch打印一次if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totaltrain_loss_history.append(epoch_train_loss)train_acc_history.append(epoch_train_acc)# --- 测试循环 ---model.eval()test_loss, correct_test, total_test = 0, 0, 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testtest_loss_history.append(epoch_test_loss)test_acc_history.append(epoch_test_acc)# 打印每个epoch的最终结果print(f'Epoch {epoch}/{epochs} 完成 | 耗时: {time.time() - epoch_start_time:.2f}s | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 训练结束后调用绘图函数print("\n训练完成! 开始绘制结果图表...")plot_iter_losses(all_iter_losses, iter_indices)plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)# 返回最终的测试准确率return epoch_test_acc# ======================================================================
# 5. 绘图函数定义
# ======================================================================
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 4))plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('训练和测试准确率')plt.legend(); plt.grid(True)plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('训练和测试损失')plt.legend(); plt.grid(True)plt.tight_layout()plt.show()# ======================================================================
# 6. 执行训练
# ======================================================================
model = ResNet18_CBAM().to(device)
criterion = nn.CrossEntropyLoss()
epochs = 50print("开始使用带分阶段微调策略的ResNet18+CBAM模型进行训练...")
final_accuracy = train_staged_finetuning(model, criterion, train_loader, test_loader, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# torch.save(model.state_dict(), 'resnet18_cbam_finetuned.pth')
# print("模型已保存为: resnet18_cbam_finetuned.pth")开始使用带分阶段微调策略的ResNet18+CBAM模型进行训练...==================================================
🚀 **阶段 1:训练注意力模块和分类头**
==================================================---> 解冻以下部分并设为可训练: ['cbam', 'backbone.fc']
Epoch: 1/50 | Batch: 100/782 | 单Batch损失: 1.8761 | 累计平均损失: 2.0936
Epoch: 1/50 | Batch: 200/782 | 单Batch损失: 1.5795 | 累计平均损失: 1.9700
Epoch: 1/50 | Batch: 300/782 | 单Batch损失: 1.9934 | 累计平均损失: 1.9023
Epoch: 1/50 | Batch: 400/782 | 单Batch损失: 1.6816 | 累计平均损失: 1.8486
Epoch: 1/50 | Batch: 500/782 | 单Batch损失: 1.5018 | 累计平均损失: 1.8095
Epoch: 1/50 | Batch: 600/782 | 单Batch损失: 1.7538 | 累计平均损失: 1.7862
Epoch: 1/50 | Batch: 700/782 | 单Batch损失: 1.4402 | 累计平均损失: 1.7618
Epoch 1/50 完成 | 耗时: 76.99s | 训练准确率: 37.14% | 测试准确率: 47.93%
Epoch: 2/50 | Batch: 100/782 | 单Batch损失: 1.5562 | 累计平均损失: 1.5582
Epoch: 2/50 | Batch: 200/782 | 单Batch损失: 1.6893 | 累计平均损失: 1.5446
Epoch: 2/50 | Batch: 300/782 | 单Batch损失: 1.6789 | 累计平均损失: 1.5400
Epoch: 2/50 | Batch: 400/782 | 单Batch损失: 1.5620 | 累计平均损失: 1.5348
Epoch: 2/50 | Batch: 500/782 | 单Batch损失: 1.2866 | 累计平均损失: 1.5292
Epoch: 2/50 | Batch: 600/782 | 单Batch损失: 1.5602 | 累计平均损失: 1.5246
Epoch: 2/50 | Batch: 700/782 | 单Batch损失: 1.5485 | 累计平均损失: 1.5178
Epoch 2/50 完成 | 耗时: 76.06s | 训练准确率: 45.86% | 测试准确率: 52.25%
Epoch: 3/50 | Batch: 100/782 | 单Batch损失: 1.4667 | 累计平均损失: 1.4613
Epoch: 3/50 | Batch: 200/782 | 单Batch损失: 1.5852 | 累计平均损失: 1.4588
Epoch: 3/50 | Batch: 300/782 | 单Batch损失: 1.5992 | 累计平均损失: 1.4554
Epoch: 3/50 | Batch: 400/782 | 单Batch损失: 1.5013 | 累计平均损失: 1.4499
Epoch: 3/50 | Batch: 500/782 | 单Batch损失: 1.4690 | 累计平均损失: 1.4450
Epoch: 3/50 | Batch: 600/782 | 单Batch损失: 1.5330 | 累计平均损失: 1.4405
Epoch: 3/50 | Batch: 700/782 | 单Batch损失: 1.4175 | 累计平均损失: 1.4439
Epoch 3/50 完成 | 耗时: 76.44s | 训练准确率: 48.57% | 测试准确率: 53.09%
Epoch: 4/50 | Batch: 100/782 | 单Batch损失: 1.8851 | 累计平均损失: 1.4088
Epoch: 4/50 | Batch: 200/782 | 单Batch损失: 1.3620 | 累计平均损失: 1.4010
Epoch: 4/50 | Batch: 300/782 | 单Batch损失: 1.2933 | 累计平均损失: 1.4012
Epoch: 4/50 | Batch: 400/782 | 单Batch损失: 1.4718 | 累计平均损失: 1.4001
Epoch: 4/50 | Batch: 500/782 | 单Batch损失: 1.4203 | 累计平均损失: 1.4002
Epoch: 4/50 | Batch: 600/782 | 单Batch损失: 1.2771 | 累计平均损失: 1.3977
Epoch: 4/50 | Batch: 700/782 | 单Batch损失: 1.1290 | 累计平均损失: 1.3990
Epoch 4/50 完成 | 耗时: 76.16s | 训练准确率: 50.08% | 测试准确率: 53.22%
Epoch: 5/50 | Batch: 100/782 | 单Batch损失: 1.1834 | 累计平均损失: 1.3582
Epoch: 5/50 | Batch: 200/782 | 单Batch损失: 1.3496 | 累计平均损失: 1.3638
Epoch: 5/50 | Batch: 300/782 | 单Batch损失: 1.2025 | 累计平均损失: 1.3554
Epoch: 5/50 | Batch: 400/782 | 单Batch损失: 1.3070 | 累计平均损失: 1.3621
Epoch: 5/50 | Batch: 500/782 | 单Batch损失: 1.4832 | 累计平均损失: 1.3618
Epoch: 5/50 | Batch: 600/782 | 单Batch损失: 1.1339 | 累计平均损失: 1.3637
Epoch: 5/50 | Batch: 700/782 | 单Batch损失: 1.3601 | 累计平均损失: 1.3640
Epoch 5/50 完成 | 耗时: 76.16s | 训练准确率: 51.49% | 测试准确率: 56.94%==================================================
✈️ **阶段 2:解冻高层卷积层 (layer3, layer4)**
==================================================---> 解冻以下部分并设为可训练: ['cbam', 'backbone.fc', 'backbone.layer3', 'backbone.layer4']
Epoch: 6/50 | Batch: 100/782 | 单Batch损失: 1.3789 | 累计平均损失: 1.3115
Epoch: 6/50 | Batch: 200/782 | 单Batch损失: 1.1504 | 累计平均损失: 1.2371
Epoch: 6/50 | Batch: 300/782 | 单Batch损失: 0.9576 | 累计平均损失: 1.1879
Epoch: 6/50 | Batch: 400/782 | 单Batch损失: 0.9399 | 累计平均损失: 1.1532
Epoch: 6/50 | Batch: 500/782 | 单Batch损失: 0.9393 | 累计平均损失: 1.1281
Epoch: 6/50 | Batch: 600/782 | 单Batch损失: 1.1172 | 累计平均损失: 1.1034
Epoch: 6/50 | Batch: 700/782 | 单Batch损失: 0.8407 | 累计平均损失: 1.0849
Epoch 6/50 完成 | 耗时: 82.91s | 训练准确率: 62.59% | 测试准确率: 74.09%
Epoch: 7/50 | Batch: 100/782 | 单Batch损失: 1.0288 | 累计平均损失: 0.9088
Epoch: 7/50 | Batch: 200/782 | 单Batch损失: 0.9535 | 累计平均损失: 0.8958
Epoch: 7/50 | Batch: 300/782 | 单Batch损失: 0.7839 | 累计平均损失: 0.8853
Epoch: 7/50 | Batch: 400/782 | 单Batch损失: 0.9926 | 累计平均损失: 0.8737
Epoch: 7/50 | Batch: 500/782 | 单Batch损失: 1.1164 | 累计平均损失: 0.8658
Epoch: 7/50 | Batch: 600/782 | 单Batch损失: 0.8296 | 累计平均损失: 0.8584
Epoch: 7/50 | Batch: 700/782 | 单Batch损失: 0.6773 | 累计平均损失: 0.8516
Epoch 7/50 完成 | 耗时: 86.22s | 训练准确率: 70.47% | 测试准确率: 77.36%
Epoch: 8/50 | Batch: 100/782 | 单Batch损失: 0.7221 | 累计平均损失: 0.7658
Epoch: 8/50 | Batch: 200/782 | 单Batch损失: 0.6348 | 累计平均损失: 0.7703
Epoch: 8/50 | Batch: 300/782 | 单Batch损失: 0.7070 | 累计平均损失: 0.7613
Epoch: 8/50 | Batch: 400/782 | 单Batch损失: 0.9136 | 累计平均损失: 0.7593
Epoch: 8/50 | Batch: 500/782 | 单Batch损失: 0.7165 | 累计平均损失: 0.7550
Epoch: 8/50 | Batch: 600/782 | 单Batch损失: 0.5091 | 累计平均损失: 0.7500
Epoch: 8/50 | Batch: 700/782 | 单Batch损失: 0.8951 | 累计平均损失: 0.7481
Epoch 8/50 完成 | 耗时: 86.69s | 训练准确率: 74.17% | 测试准确率: 79.83%
Epoch: 9/50 | Batch: 100/782 | 单Batch损失: 0.9336 | 累计平均损失: 0.7063
Epoch: 9/50 | Batch: 200/782 | 单Batch损失: 0.6615 | 累计平均损失: 0.6932
Epoch: 9/50 | Batch: 300/782 | 单Batch损失: 0.7089 | 累计平均损失: 0.6886
Epoch: 9/50 | Batch: 400/782 | 单Batch损失: 0.6640 | 累计平均损失: 0.6848
Epoch: 9/50 | Batch: 500/782 | 单Batch损失: 0.6583 | 累计平均损失: 0.6848
Epoch: 9/50 | Batch: 600/782 | 单Batch损失: 0.6543 | 累计平均损失: 0.6838
Epoch: 9/50 | Batch: 700/782 | 单Batch损失: 0.4608 | 累计平均损失: 0.6805
Epoch 9/50 完成 | 耗时: 83.22s | 训练准确率: 76.52% | 测试准确率: 81.59%
Epoch: 10/50 | Batch: 100/782 | 单Batch损失: 0.4796 | 累计平均损失: 0.6166
Epoch: 10/50 | Batch: 200/782 | 单Batch损失: 0.4604 | 累计平均损失: 0.6158
Epoch: 10/50 | Batch: 300/782 | 单Batch损失: 0.3858 | 累计平均损失: 0.6094
Epoch: 10/50 | Batch: 400/782 | 单Batch损失: 0.6743 | 累计平均损失: 0.6203
Epoch: 10/50 | Batch: 500/782 | 单Batch损失: 0.7695 | 累计平均损失: 0.6223
Epoch: 10/50 | Batch: 600/782 | 单Batch损失: 0.3935 | 累计平均损失: 0.6214
Epoch: 10/50 | Batch: 700/782 | 单Batch损失: 0.4813 | 累计平均损失: 0.6235
Epoch 10/50 完成 | 耗时: 83.58s | 训练准确率: 78.08% | 测试准确率: 81.28%
Epoch: 11/50 | Batch: 100/782 | 单Batch损失: 0.6589 | 累计平均损失: 0.5848
Epoch: 11/50 | Batch: 200/782 | 单Batch损失: 0.6819 | 累计平均损失: 0.5855
Epoch: 11/50 | Batch: 300/782 | 单Batch损失: 0.6547 | 累计平均损失: 0.5891
Epoch: 11/50 | Batch: 400/782 | 单Batch损失: 0.8317 | 累计平均损失: 0.5862
Epoch: 11/50 | Batch: 500/782 | 单Batch损失: 0.7952 | 累计平均损失: 0.5852
Epoch: 11/50 | Batch: 600/782 | 单Batch损失: 0.5688 | 累计平均损失: 0.5865
Epoch: 11/50 | Batch: 700/782 | 单Batch损失: 0.9742 | 累计平均损失: 0.5852
Epoch 11/50 完成 | 耗时: 84.87s | 训练准确率: 79.57% | 测试准确率: 83.28%
Epoch: 12/50 | Batch: 100/782 | 单Batch损失: 0.7744 | 累计平均损失: 0.5365
Epoch: 12/50 | Batch: 200/782 | 单Batch损失: 0.4654 | 累计平均损失: 0.5396
Epoch: 12/50 | Batch: 300/782 | 单Batch损失: 0.7344 | 累计平均损失: 0.5396
Epoch: 12/50 | Batch: 400/782 | 单Batch损失: 0.5466 | 累计平均损失: 0.5406
Epoch: 12/50 | Batch: 500/782 | 单Batch损失: 0.6569 | 累计平均损失: 0.5436
Epoch: 12/50 | Batch: 600/782 | 单Batch损失: 0.5201 | 累计平均损失: 0.5449
Epoch: 12/50 | Batch: 700/782 | 单Batch损失: 0.4543 | 累计平均损失: 0.5451
Epoch 12/50 完成 | 耗时: 87.69s | 训练准确率: 80.97% | 测试准确率: 83.42%
Epoch: 13/50 | Batch: 100/782 | 单Batch损失: 0.6510 | 累计平均损失: 0.5226
Epoch: 13/50 | Batch: 200/782 | 单Batch损失: 0.5177 | 累计平均损失: 0.5239
Epoch: 13/50 | Batch: 300/782 | 单Batch损失: 0.4906 | 累计平均损失: 0.5181
Epoch: 13/50 | Batch: 400/782 | 单Batch损失: 0.4491 | 累计平均损失: 0.5189
Epoch: 13/50 | Batch: 500/782 | 单Batch损失: 0.4104 | 累计平均损失: 0.5228
Epoch: 13/50 | Batch: 600/782 | 单Batch损失: 0.7475 | 累计平均损失: 0.5212
Epoch: 13/50 | Batch: 700/782 | 单Batch损失: 0.4665 | 累计平均损失: 0.5212
Epoch 13/50 完成 | 耗时: 87.18s | 训练准确率: 81.64% | 测试准确率: 84.44%
Epoch: 14/50 | Batch: 100/782 | 单Batch损失: 0.5500 | 累计平均损失: 0.4651
Epoch: 14/50 | Batch: 200/782 | 单Batch损失: 0.5167 | 累计平均损失: 0.4798
Epoch: 14/50 | Batch: 300/782 | 单Batch损失: 0.4733 | 累计平均损失: 0.4795
Epoch: 14/50 | Batch: 400/782 | 单Batch损失: 0.4339 | 累计平均损失: 0.4853
Epoch: 14/50 | Batch: 500/782 | 单Batch损失: 0.5792 | 累计平均损失: 0.4881
Epoch: 14/50 | Batch: 600/782 | 单Batch损失: 0.5573 | 累计平均损失: 0.4877
Epoch: 14/50 | Batch: 700/782 | 单Batch损失: 0.4727 | 累计平均损失: 0.4873
Epoch 14/50 完成 | 耗时: 87.24s | 训练准确率: 82.88% | 测试准确率: 84.97%
Epoch: 15/50 | Batch: 100/782 | 单Batch损失: 0.3884 | 累计平均损失: 0.4545
Epoch: 15/50 | Batch: 200/782 | 单Batch损失: 0.3876 | 累计平均损失: 0.4648
Epoch: 15/50 | Batch: 300/782 | 单Batch损失: 0.4986 | 累计平均损失: 0.4593
Epoch: 15/50 | Batch: 400/782 | 单Batch损失: 0.5642 | 累计平均损失: 0.4612
Epoch: 15/50 | Batch: 500/782 | 单Batch损失: 0.5553 | 累计平均损失: 0.4678
Epoch: 15/50 | Batch: 600/782 | 单Batch损失: 0.3092 | 累计平均损失: 0.4681
Epoch: 15/50 | Batch: 700/782 | 单Batch损失: 0.3330 | 累计平均损失: 0.4678
Epoch 15/50 完成 | 耗时: 87.12s | 训练准确率: 83.64% | 测试准确率: 84.88%
Epoch: 16/50 | Batch: 100/782 | 单Batch损失: 0.4565 | 累计平均损失: 0.4374
Epoch: 16/50 | Batch: 200/782 | 单Batch损失: 0.3855 | 累计平均损失: 0.4329
Epoch: 16/50 | Batch: 300/782 | 单Batch损失: 0.7052 | 累计平均损失: 0.4431
Epoch: 16/50 | Batch: 400/782 | 单Batch损失: 0.5092 | 累计平均损失: 0.4410
Epoch: 16/50 | Batch: 500/782 | 单Batch损失: 0.5863 | 累计平均损失: 0.4427
Epoch: 16/50 | Batch: 600/782 | 单Batch损失: 0.5284 | 累计平均损失: 0.4447
Epoch: 16/50 | Batch: 700/782 | 单Batch损失: 0.3693 | 累计平均损失: 0.4462
Epoch 16/50 完成 | 耗时: 85.93s | 训练准确率: 84.26% | 测试准确率: 85.73%
Epoch: 17/50 | Batch: 100/782 | 单Batch损失: 0.4525 | 累计平均损失: 0.4212
Epoch: 17/50 | Batch: 200/782 | 单Batch损失: 0.4279 | 累计平均损失: 0.4252
Epoch: 17/50 | Batch: 300/782 | 单Batch损失: 0.3124 | 累计平均损失: 0.4244
Epoch: 17/50 | Batch: 400/782 | 单Batch损失: 0.4619 | 累计平均损失: 0.4208
Epoch: 17/50 | Batch: 500/782 | 单Batch损失: 0.4711 | 累计平均损失: 0.4245
Epoch: 17/50 | Batch: 600/782 | 单Batch损失: 0.2753 | 累计平均损失: 0.4253
Epoch: 17/50 | Batch: 700/782 | 单Batch损失: 0.4614 | 累计平均损失: 0.4292
Epoch 17/50 完成 | 耗时: 85.13s | 训练准确率: 84.85% | 测试准确率: 85.72%
Epoch: 18/50 | Batch: 100/782 | 单Batch损失: 0.5472 | 累计平均损失: 0.4028
Epoch: 18/50 | Batch: 200/782 | 单Batch损失: 0.2413 | 累计平均损失: 0.4077
Epoch: 18/50 | Batch: 300/782 | 单Batch损失: 0.4395 | 累计平均损失: 0.4054
Epoch: 18/50 | Batch: 400/782 | 单Batch损失: 0.3432 | 累计平均损失: 0.4010
Epoch: 18/50 | Batch: 500/782 | 单Batch损失: 0.3620 | 累计平均损失: 0.4037
Epoch: 18/50 | Batch: 600/782 | 单Batch损失: 0.2353 | 累计平均损失: 0.4052
Epoch: 18/50 | Batch: 700/782 | 单Batch损失: 0.1533 | 累计平均损失: 0.4052
Epoch 18/50 完成 | 耗时: 85.68s | 训练准确率: 85.56% | 测试准确率: 85.75%
Epoch: 19/50 | Batch: 100/782 | 单Batch损失: 0.3158 | 累计平均损失: 0.3777
Epoch: 19/50 | Batch: 200/782 | 单Batch损失: 0.3645 | 累计平均损失: 0.3824
Epoch: 19/50 | Batch: 300/782 | 单Batch损失: 0.4678 | 累计平均损失: 0.3913
Epoch: 19/50 | Batch: 400/782 | 单Batch损失: 0.2455 | 累计平均损失: 0.3917
Epoch: 19/50 | Batch: 500/782 | 单Batch损失: 0.3822 | 累计平均损失: 0.3949
Epoch: 19/50 | Batch: 600/782 | 单Batch损失: 0.5209 | 累计平均损失: 0.3957
Epoch: 19/50 | Batch: 700/782 | 单Batch损失: 0.3431 | 累计平均损失: 0.3954
Epoch 19/50 完成 | 耗时: 83.83s | 训练准确率: 86.25% | 测试准确率: 86.50%
Epoch: 20/50 | Batch: 100/782 | 单Batch损失: 0.2932 | 累计平均损失: 0.3766
Epoch: 20/50 | Batch: 200/782 | 单Batch损失: 0.3212 | 累计平均损失: 0.3744
Epoch: 20/50 | Batch: 300/782 | 单Batch损失: 0.4868 | 累计平均损失: 0.3750
Epoch: 20/50 | Batch: 400/782 | 单Batch损失: 0.1922 | 累计平均损失: 0.3779
Epoch: 20/50 | Batch: 500/782 | 单Batch损失: 0.2483 | 累计平均损失: 0.3769
Epoch: 20/50 | Batch: 600/782 | 单Batch损失: 0.4557 | 累计平均损失: 0.3790
Epoch: 20/50 | Batch: 700/782 | 单Batch损失: 0.4184 | 累计平均损失: 0.3772
Epoch 20/50 完成 | 耗时: 83.58s | 训练准确率: 86.52% | 测试准确率: 86.26%==================================================
🛰️ **阶段 3:解冻所有层,进行全局微调**
==================================================
Epoch: 21/50 | Batch: 100/782 | 单Batch损失: 0.1845 | 累计平均损失: 0.3334
Epoch: 21/50 | Batch: 200/782 | 单Batch损失: 0.2104 | 累计平均损失: 0.3280
Epoch: 21/50 | Batch: 300/782 | 单Batch损失: 0.3827 | 累计平均损失: 0.3273
Epoch: 21/50 | Batch: 400/782 | 单Batch损失: 0.2357 | 累计平均损失: 0.3226
Epoch: 21/50 | Batch: 500/782 | 单Batch损失: 0.4506 | 累计平均损失: 0.3201
Epoch: 21/50 | Batch: 600/782 | 单Batch损失: 0.3157 | 累计平均损失: 0.3179
Epoch: 21/50 | Batch: 700/782 | 单Batch损失: 0.3888 | 累计平均损失: 0.3164
Epoch 21/50 完成 | 耗时: 97.13s | 训练准确率: 89.14% | 测试准确率: 87.75%
Epoch: 22/50 | Batch: 100/782 | 单Batch损失: 0.3001 | 累计平均损失: 0.2792
Epoch: 22/50 | Batch: 200/782 | 单Batch损失: 0.2804 | 累计平均损失: 0.2765
Epoch: 22/50 | Batch: 300/782 | 单Batch损失: 0.3303 | 累计平均损失: 0.2804
Epoch: 22/50 | Batch: 400/782 | 单Batch损失: 0.2860 | 累计平均损失: 0.2814
Epoch: 22/50 | Batch: 500/782 | 单Batch损失: 0.2582 | 累计平均损失: 0.2829
Epoch: 22/50 | Batch: 600/782 | 单Batch损失: 0.2190 | 累计平均损失: 0.2796
Epoch: 22/50 | Batch: 700/782 | 单Batch损失: 0.2337 | 累计平均损失: 0.2789
Epoch 22/50 完成 | 耗时: 96.65s | 训练准确率: 90.30% | 测试准确率: 88.09%
Epoch: 23/50 | Batch: 100/782 | 单Batch损失: 0.2752 | 累计平均损失: 0.2739
Epoch: 23/50 | Batch: 200/782 | 单Batch损失: 0.2014 | 累计平均损失: 0.2706
Epoch: 23/50 | Batch: 300/782 | 单Batch损失: 0.2869 | 累计平均损失: 0.2698
Epoch: 23/50 | Batch: 400/782 | 单Batch损失: 0.5428 | 累计平均损失: 0.2689
Epoch: 23/50 | Batch: 500/782 | 单Batch损失: 0.2420 | 累计平均损失: 0.2683
Epoch: 23/50 | Batch: 600/782 | 单Batch损失: 0.2083 | 累计平均损失: 0.2679
Epoch: 23/50 | Batch: 700/782 | 单Batch损失: 0.2737 | 累计平均损失: 0.2662
Epoch 23/50 完成 | 耗时: 96.65s | 训练准确率: 90.67% | 测试准确率: 88.70%
Epoch: 24/50 | Batch: 100/782 | 单Batch损失: 0.1806 | 累计平均损失: 0.2552
Epoch: 24/50 | Batch: 200/782 | 单Batch损失: 0.3049 | 累计平均损失: 0.2589
Epoch: 24/50 | Batch: 300/782 | 单Batch损失: 0.3578 | 累计平均损失: 0.2576
Epoch: 24/50 | Batch: 400/782 | 单Batch损失: 0.2715 | 累计平均损失: 0.2586
Epoch: 24/50 | Batch: 500/782 | 单Batch损失: 0.2813 | 累计平均损失: 0.2571
Epoch: 24/50 | Batch: 600/782 | 单Batch损失: 0.2442 | 累计平均损失: 0.2566
Epoch: 24/50 | Batch: 700/782 | 单Batch损失: 0.2035 | 累计平均损失: 0.2569
Epoch 24/50 完成 | 耗时: 96.88s | 训练准确率: 91.07% | 测试准确率: 88.77%
Epoch: 25/50 | Batch: 100/782 | 单Batch损失: 0.3843 | 累计平均损失: 0.2441
Epoch: 25/50 | Batch: 200/782 | 单Batch损失: 0.2398 | 累计平均损失: 0.2450
Epoch: 25/50 | Batch: 300/782 | 单Batch损失: 0.1551 | 累计平均损失: 0.2484
Epoch: 25/50 | Batch: 400/782 | 单Batch损失: 0.1477 | 累计平均损失: 0.2470
Epoch: 25/50 | Batch: 500/782 | 单Batch损失: 0.1403 | 累计平均损失: 0.2455
Epoch: 25/50 | Batch: 600/782 | 单Batch损失: 0.1751 | 累计平均损失: 0.2427
Epoch: 25/50 | Batch: 700/782 | 单Batch损失: 0.1857 | 累计平均损失: 0.2437
Epoch 25/50 完成 | 耗时: 101.00s | 训练准确率: 91.55% | 测试准确率: 88.90%
Epoch: 26/50 | Batch: 100/782 | 单Batch损失: 0.2366 | 累计平均损失: 0.2547
Epoch: 26/50 | Batch: 200/782 | 单Batch损失: 0.2450 | 累计平均损失: 0.2490
Epoch: 26/50 | Batch: 300/782 | 单Batch损失: 0.2003 | 累计平均损失: 0.2442
Epoch: 26/50 | Batch: 400/782 | 单Batch损失: 0.1868 | 累计平均损失: 0.2416
Epoch: 26/50 | Batch: 500/782 | 单Batch损失: 0.1777 | 累计平均损失: 0.2377
Epoch: 26/50 | Batch: 600/782 | 单Batch损失: 0.2840 | 累计平均损失: 0.2378
Epoch: 26/50 | Batch: 700/782 | 单Batch损失: 0.2924 | 累计平均损失: 0.2367
Epoch 26/50 完成 | 耗时: 97.04s | 训练准确率: 91.83% | 测试准确率: 88.86%
Epoch: 27/50 | Batch: 100/782 | 单Batch损失: 0.1440 | 累计平均损失: 0.2219
Epoch: 27/50 | Batch: 200/782 | 单Batch损失: 0.1886 | 累计平均损失: 0.2261
Epoch: 27/50 | Batch: 300/782 | 单Batch损失: 0.2393 | 累计平均损失: 0.2270
Epoch: 27/50 | Batch: 400/782 | 单Batch损失: 0.1593 | 累计平均损失: 0.2265
Epoch: 27/50 | Batch: 500/782 | 单Batch损失: 0.3379 | 累计平均损失: 0.2258
Epoch: 27/50 | Batch: 600/782 | 单Batch损失: 0.1907 | 累计平均损失: 0.2263
Epoch: 27/50 | Batch: 700/782 | 单Batch损失: 0.1929 | 累计平均损失: 0.2273
Epoch 27/50 完成 | 耗时: 97.36s | 训练准确率: 92.08% | 测试准确率: 89.31%
Epoch: 28/50 | Batch: 100/782 | 单Batch损失: 0.1359 | 累计平均损失: 0.2147
Epoch: 28/50 | Batch: 200/782 | 单Batch损失: 0.3457 | 累计平均损失: 0.2239
Epoch: 28/50 | Batch: 300/782 | 单Batch损失: 0.2090 | 累计平均损失: 0.2227
Epoch: 28/50 | Batch: 400/782 | 单Batch损失: 0.1215 | 累计平均损失: 0.2214
Epoch: 28/50 | Batch: 500/782 | 单Batch损失: 0.1499 | 累计平均损失: 0.2201
Epoch: 28/50 | Batch: 600/782 | 单Batch损失: 0.2108 | 累计平均损失: 0.2203
Epoch: 28/50 | Batch: 700/782 | 单Batch损失: 0.1363 | 累计平均损失: 0.2219
Epoch 28/50 完成 | 耗时: 96.81s | 训练准确率: 92.33% | 测试准确率: 89.29%
Epoch: 29/50 | Batch: 100/782 | 单Batch损失: 0.1500 | 累计平均损失: 0.2063
Epoch: 29/50 | Batch: 200/782 | 单Batch损失: 0.2529 | 累计平均损失: 0.2120
Epoch: 29/50 | Batch: 300/782 | 单Batch损失: 0.1855 | 累计平均损失: 0.2135
Epoch: 29/50 | Batch: 400/782 | 单Batch损失: 0.2702 | 累计平均损失: 0.2102
Epoch: 29/50 | Batch: 500/782 | 单Batch损失: 0.2964 | 累计平均损失: 0.2092
Epoch: 29/50 | Batch: 600/782 | 单Batch损失: 0.2251 | 累计平均损失: 0.2090
Epoch: 29/50 | Batch: 700/782 | 单Batch损失: 0.2595 | 累计平均损失: 0.2108
Epoch 29/50 完成 | 耗时: 96.78s | 训练准确率: 92.44% | 测试准确率: 89.33%
Epoch: 30/50 | Batch: 100/782 | 单Batch损失: 0.2251 | 累计平均损失: 0.2058
Epoch: 30/50 | Batch: 200/782 | 单Batch损失: 0.2688 | 累计平均损失: 0.2070
Epoch: 30/50 | Batch: 300/782 | 单Batch损失: 0.2091 | 累计平均损失: 0.2098
Epoch: 30/50 | Batch: 400/782 | 单Batch损失: 0.2273 | 累计平均损失: 0.2112
Epoch: 30/50 | Batch: 500/782 | 单Batch损失: 0.3604 | 累计平均损失: 0.2121
Epoch: 30/50 | Batch: 600/782 | 单Batch损失: 0.2866 | 累计平均损失: 0.2106
Epoch: 30/50 | Batch: 700/782 | 单Batch损失: 0.2378 | 累计平均损失: 0.2092
Epoch 30/50 完成 | 耗时: 96.96s | 训练准确率: 92.68% | 测试准确率: 89.42%
Epoch: 31/50 | Batch: 100/782 | 单Batch损失: 0.1396 | 累计平均损失: 0.1995
Epoch: 31/50 | Batch: 200/782 | 单Batch损失: 0.2132 | 累计平均损失: 0.2033
Epoch: 31/50 | Batch: 300/782 | 单Batch损失: 0.1478 | 累计平均损失: 0.2055
Epoch: 31/50 | Batch: 400/782 | 单Batch损失: 0.1910 | 累计平均损失: 0.2047
Epoch: 31/50 | Batch: 500/782 | 单Batch损失: 0.2278 | 累计平均损失: 0.2049
Epoch: 31/50 | Batch: 600/782 | 单Batch损失: 0.1690 | 累计平均损失: 0.2042
Epoch: 31/50 | Batch: 700/782 | 单Batch损失: 0.2135 | 累计平均损失: 0.2052
Epoch 31/50 完成 | 耗时: 97.04s | 训练准确率: 92.92% | 测试准确率: 89.55%
Epoch: 32/50 | Batch: 100/782 | 单Batch损失: 0.2819 | 累计平均损失: 0.1926
Epoch: 32/50 | Batch: 200/782 | 单Batch损失: 0.3059 | 累计平均损失: 0.1947
Epoch: 32/50 | Batch: 300/782 | 单Batch损失: 0.1821 | 累计平均损失: 0.1930
Epoch: 32/50 | Batch: 400/782 | 单Batch损失: 0.2432 | 累计平均损失: 0.1942
Epoch: 32/50 | Batch: 500/782 | 单Batch损失: 0.2580 | 累计平均损失: 0.1947
Epoch: 32/50 | Batch: 600/782 | 单Batch损失: 0.2462 | 累计平均损失: 0.1941
Epoch: 32/50 | Batch: 700/782 | 单Batch损失: 0.0966 | 累计平均损失: 0.1948
Epoch 32/50 完成 | 耗时: 99.56s | 训练准确率: 93.13% | 测试准确率: 89.73%
Epoch: 33/50 | Batch: 100/782 | 单Batch损失: 0.2216 | 累计平均损失: 0.1726
Epoch: 33/50 | Batch: 200/782 | 单Batch损失: 0.0762 | 累计平均损失: 0.1865
Epoch: 33/50 | Batch: 300/782 | 单Batch损失: 0.1702 | 累计平均损失: 0.1829
Epoch: 33/50 | Batch: 400/782 | 单Batch损失: 0.1527 | 累计平均损失: 0.1853
Epoch: 33/50 | Batch: 500/782 | 单Batch损失: 0.1880 | 累计平均损失: 0.1873
Epoch: 33/50 | Batch: 600/782 | 单Batch损失: 0.0904 | 累计平均损失: 0.1865
Epoch: 33/50 | Batch: 700/782 | 单Batch损失: 0.2168 | 累计平均损失: 0.1881
Epoch 33/50 完成 | 耗时: 102.81s | 训练准确率: 93.41% | 测试准确率: 89.76%
Epoch: 34/50 | Batch: 100/782 | 单Batch损失: 0.1367 | 累计平均损失: 0.1934
Epoch: 34/50 | Batch: 200/782 | 单Batch损失: 0.1041 | 累计平均损失: 0.1938
Epoch: 34/50 | Batch: 300/782 | 单Batch损失: 0.2571 | 累计平均损失: 0.1915
Epoch: 34/50 | Batch: 400/782 | 单Batch损失: 0.1586 | 累计平均损失: 0.1906
Epoch: 34/50 | Batch: 500/782 | 单Batch损失: 0.1310 | 累计平均损失: 0.1901
Epoch: 34/50 | Batch: 600/782 | 单Batch损失: 0.1365 | 累计平均损失: 0.1879
Epoch: 34/50 | Batch: 700/782 | 单Batch损失: 0.1419 | 累计平均损失: 0.1880
Epoch 34/50 完成 | 耗时: 98.15s | 训练准确率: 93.41% | 测试准确率: 89.53%
Epoch: 35/50 | Batch: 100/782 | 单Batch损失: 0.2313 | 累计平均损失: 0.1835
Epoch: 35/50 | Batch: 200/782 | 单Batch损失: 0.1496 | 累计平均损失: 0.1801
Epoch: 35/50 | Batch: 300/782 | 单Batch损失: 0.3077 | 累计平均损失: 0.1816
Epoch: 35/50 | Batch: 400/782 | 单Batch损失: 0.0879 | 累计平均损失: 0.1843
Epoch: 35/50 | Batch: 500/782 | 单Batch损失: 0.2600 | 累计平均损失: 0.1840
Epoch: 35/50 | Batch: 600/782 | 单Batch损失: 0.2123 | 累计平均损失: 0.1831
Epoch: 35/50 | Batch: 700/782 | 单Batch损失: 0.2475 | 累计平均损失: 0.1822
Epoch 35/50 完成 | 耗时: 97.44s | 训练准确率: 93.63% | 测试准确率: 89.71%
Epoch: 36/50 | Batch: 100/782 | 单Batch损失: 0.2663 | 累计平均损失: 0.1700
Epoch: 36/50 | Batch: 200/782 | 单Batch损失: 0.1003 | 累计平均损失: 0.1742
Epoch: 36/50 | Batch: 300/782 | 单Batch损失: 0.2323 | 累计平均损失: 0.1713
Epoch: 36/50 | Batch: 400/782 | 单Batch损失: 0.2459 | 累计平均损失: 0.1703
Epoch: 36/50 | Batch: 500/782 | 单Batch损失: 0.1265 | 累计平均损失: 0.1713
Epoch: 36/50 | Batch: 600/782 | 单Batch损失: 0.2301 | 累计平均损失: 0.1745
Epoch: 36/50 | Batch: 700/782 | 单Batch损失: 0.1070 | 累计平均损失: 0.1748
Epoch 36/50 完成 | 耗时: 96.83s | 训练准确率: 93.84% | 测试准确率: 89.60%
Epoch: 37/50 | Batch: 100/782 | 单Batch损失: 0.1996 | 累计平均损失: 0.1786
Epoch: 37/50 | Batch: 200/782 | 单Batch损失: 0.1948 | 累计平均损失: 0.1775
Epoch: 37/50 | Batch: 300/782 | 单Batch损失: 0.2338 | 累计平均损失: 0.1777
Epoch: 37/50 | Batch: 400/782 | 单Batch损失: 0.2381 | 累计平均损失: 0.1747
Epoch: 37/50 | Batch: 500/782 | 单Batch损失: 0.2947 | 累计平均损失: 0.1762
Epoch: 37/50 | Batch: 600/782 | 单Batch损失: 0.1333 | 累计平均损失: 0.1762
Epoch: 37/50 | Batch: 700/782 | 单Batch损失: 0.1409 | 累计平均损失: 0.1766
Epoch 37/50 完成 | 耗时: 96.95s | 训练准确率: 93.86% | 测试准确率: 89.82%
Epoch: 38/50 | Batch: 100/782 | 单Batch损失: 0.1598 | 累计平均损失: 0.1774
Epoch: 38/50 | Batch: 200/782 | 单Batch损失: 0.1250 | 累计平均损失: 0.1702
Epoch: 38/50 | Batch: 300/782 | 单Batch损失: 0.2638 | 累计平均损失: 0.1705
Epoch: 38/50 | Batch: 400/782 | 单Batch损失: 0.3401 | 累计平均损失: 0.1740
Epoch: 38/50 | Batch: 500/782 | 单Batch损失: 0.2255 | 累计平均损失: 0.1734
Epoch: 38/50 | Batch: 600/782 | 单Batch损失: 0.1888 | 累计平均损失: 0.1733
Epoch: 38/50 | Batch: 700/782 | 单Batch损失: 0.1518 | 累计平均损失: 0.1715
Epoch 38/50 完成 | 耗时: 97.08s | 训练准确率: 94.00% | 测试准确率: 89.97%
Epoch: 39/50 | Batch: 100/782 | 单Batch损失: 0.1654 | 累计平均损失: 0.1606
Epoch: 39/50 | Batch: 200/782 | 单Batch损失: 0.1182 | 累计平均损失: 0.1647
Epoch: 39/50 | Batch: 300/782 | 单Batch损失: 0.0901 | 累计平均损失: 0.1658
Epoch: 39/50 | Batch: 400/782 | 单Batch损失: 0.0780 | 累计平均损失: 0.1644
Epoch: 39/50 | Batch: 500/782 | 单Batch损失: 0.2793 | 累计平均损失: 0.1660
Epoch: 39/50 | Batch: 600/782 | 单Batch损失: 0.2445 | 累计平均损失: 0.1659
Epoch: 39/50 | Batch: 700/782 | 单Batch损失: 0.1024 | 累计平均损失: 0.1652
Epoch 39/50 完成 | 耗时: 97.42s | 训练准确率: 94.25% | 测试准确率: 89.76%
Epoch: 40/50 | Batch: 100/782 | 单Batch损失: 0.1358 | 累计平均损失: 0.1634
Epoch: 40/50 | Batch: 200/782 | 单Batch损失: 0.1515 | 累计平均损失: 0.1643
Epoch: 40/50 | Batch: 300/782 | 单Batch损失: 0.1691 | 累计平均损失: 0.1617
Epoch: 40/50 | Batch: 400/782 | 单Batch损失: 0.1575 | 累计平均损失: 0.1658
Epoch: 40/50 | Batch: 500/782 | 单Batch损失: 0.0952 | 累计平均损失: 0.1644
Epoch: 40/50 | Batch: 600/782 | 单Batch损失: 0.0776 | 累计平均损失: 0.1632
Epoch: 40/50 | Batch: 700/782 | 单Batch损失: 0.1103 | 累计平均损失: 0.1637
Epoch 40/50 完成 | 耗时: 97.32s | 训练准确率: 94.23% | 测试准确率: 90.14%
Epoch: 41/50 | Batch: 100/782 | 单Batch损失: 0.1583 | 累计平均损失: 0.1562
Epoch: 41/50 | Batch: 200/782 | 单Batch损失: 0.1907 | 累计平均损失: 0.1566
Epoch: 41/50 | Batch: 300/782 | 单Batch损失: 0.0756 | 累计平均损失: 0.1589
Epoch: 41/50 | Batch: 400/782 | 单Batch损失: 0.1698 | 累计平均损失: 0.1611
Epoch: 41/50 | Batch: 500/782 | 单Batch损失: 0.1929 | 累计平均损失: 0.1601
Epoch: 41/50 | Batch: 600/782 | 单Batch损失: 0.0987 | 累计平均损失: 0.1593
Epoch: 41/50 | Batch: 700/782 | 单Batch损失: 0.1293 | 累计平均损失: 0.1578
Epoch 41/50 完成 | 耗时: 97.46s | 训练准确率: 94.37% | 测试准确率: 90.08%
Epoch: 42/50 | Batch: 100/782 | 单Batch损失: 0.1681 | 累计平均损失: 0.1450
Epoch: 42/50 | Batch: 200/782 | 单Batch损失: 0.1323 | 累计平均损失: 0.1477
Epoch: 42/50 | Batch: 300/782 | 单Batch损失: 0.1507 | 累计平均损失: 0.1489
Epoch: 42/50 | Batch: 400/782 | 单Batch损失: 0.2658 | 累计平均损失: 0.1491
Epoch: 42/50 | Batch: 500/782 | 单Batch损失: 0.1057 | 累计平均损失: 0.1515
Epoch: 42/50 | Batch: 600/782 | 单Batch损失: 0.1221 | 累计平均损失: 0.1536
Epoch: 42/50 | Batch: 700/782 | 单Batch损失: 0.1181 | 累计平均损失: 0.1547
Epoch 42/50 完成 | 耗时: 97.74s | 训练准确率: 94.59% | 测试准确率: 90.23%
Epoch: 43/50 | Batch: 100/782 | 单Batch损失: 0.1296 | 累计平均损失: 0.1531
Epoch: 43/50 | Batch: 200/782 | 单Batch损失: 0.1386 | 累计平均损失: 0.1522
Epoch: 43/50 | Batch: 300/782 | 单Batch损失: 0.1560 | 累计平均损失: 0.1477
Epoch: 43/50 | Batch: 400/782 | 单Batch损失: 0.2840 | 累计平均损失: 0.1485
Epoch: 43/50 | Batch: 500/782 | 单Batch损失: 0.0569 | 累计平均损失: 0.1485
Epoch: 43/50 | Batch: 600/782 | 单Batch损失: 0.1076 | 累计平均损失: 0.1502
Epoch: 43/50 | Batch: 700/782 | 单Batch损失: 0.1625 | 累计平均损失: 0.1497
Epoch 43/50 完成 | 耗时: 98.88s | 训练准确率: 94.69% | 测试准确率: 90.22%
Epoch: 44/50 | Batch: 100/782 | 单Batch损失: 0.1408 | 累计平均损失: 0.1405
Epoch: 44/50 | Batch: 200/782 | 单Batch损失: 0.1131 | 累计平均损失: 0.1439
Epoch: 44/50 | Batch: 300/782 | 单Batch损失: 0.2458 | 累计平均损失: 0.1469
Epoch: 44/50 | Batch: 400/782 | 单Batch损失: 0.2351 | 累计平均损失: 0.1490
Epoch: 44/50 | Batch: 500/782 | 单Batch损失: 0.2362 | 累计平均损失: 0.1498
Epoch: 44/50 | Batch: 600/782 | 单Batch损失: 0.0939 | 累计平均损失: 0.1485
Epoch: 44/50 | Batch: 700/782 | 单Batch损失: 0.1675 | 累计平均损失: 0.1459
Epoch 44/50 完成 | 耗时: 98.71s | 训练准确率: 94.83% | 测试准确率: 90.14%
Epoch: 45/50 | Batch: 100/782 | 单Batch损失: 0.0928 | 累计平均损失: 0.1347
Epoch: 45/50 | Batch: 200/782 | 单Batch损失: 0.2300 | 累计平均损失: 0.1387
Epoch: 45/50 | Batch: 300/782 | 单Batch损失: 0.0884 | 累计平均损失: 0.1418
Epoch: 45/50 | Batch: 400/782 | 单Batch损失: 0.0626 | 累计平均损失: 0.1430
Epoch: 45/50 | Batch: 500/782 | 单Batch损失: 0.1842 | 累计平均损失: 0.1430
Epoch: 45/50 | Batch: 600/782 | 单Batch损失: 0.1218 | 累计平均损失: 0.1426
Epoch: 45/50 | Batch: 700/782 | 单Batch损失: 0.2282 | 累计平均损失: 0.1425
Epoch 45/50 完成 | 耗时: 98.43s | 训练准确率: 94.91% | 测试准确率: 90.06%
Epoch: 46/50 | Batch: 100/782 | 单Batch损失: 0.1451 | 累计平均损失: 0.1402
Epoch: 46/50 | Batch: 200/782 | 单Batch损失: 0.0374 | 累计平均损失: 0.1370
Epoch: 46/50 | Batch: 300/782 | 单Batch损失: 0.1575 | 累计平均损失: 0.1395
Epoch: 46/50 | Batch: 400/782 | 单Batch损失: 0.0973 | 累计平均损失: 0.1421
Epoch: 46/50 | Batch: 500/782 | 单Batch损失: 0.0838 | 累计平均损失: 0.1408
Epoch: 46/50 | Batch: 600/782 | 单Batch损失: 0.1018 | 累计平均损失: 0.1411
Epoch: 46/50 | Batch: 700/782 | 单Batch损失: 0.1501 | 累计平均损失: 0.1415
Epoch 46/50 完成 | 耗时: 98.36s | 训练准确率: 95.03% | 测试准确率: 90.42%
Epoch: 47/50 | Batch: 100/782 | 单Batch损失: 0.0696 | 累计平均损失: 0.1277
Epoch: 47/50 | Batch: 200/782 | 单Batch损失: 0.1721 | 累计平均损失: 0.1317
Epoch: 47/50 | Batch: 300/782 | 单Batch损失: 0.1047 | 累计平均损失: 0.1326
Epoch: 47/50 | Batch: 400/782 | 单Batch损失: 0.2047 | 累计平均损失: 0.1349
Epoch: 47/50 | Batch: 500/782 | 单Batch损失: 0.1099 | 累计平均损失: 0.1357
Epoch: 47/50 | Batch: 600/782 | 单Batch损失: 0.1169 | 累计平均损失: 0.1364
Epoch: 47/50 | Batch: 700/782 | 单Batch损失: 0.1245 | 累计平均损失: 0.1380
Epoch 47/50 完成 | 耗时: 98.49s | 训练准确率: 95.21% | 测试准确率: 90.22%
Epoch: 48/50 | Batch: 100/782 | 单Batch损失: 0.2113 | 累计平均损失: 0.1308
Epoch: 48/50 | Batch: 200/782 | 单Batch损失: 0.0906 | 累计平均损失: 0.1302
Epoch: 48/50 | Batch: 300/782 | 单Batch损失: 0.2864 | 累计平均损失: 0.1272
Epoch: 48/50 | Batch: 400/782 | 单Batch损失: 0.1393 | 累计平均损失: 0.1275
Epoch: 48/50 | Batch: 500/782 | 单Batch损失: 0.2123 | 累计平均损失: 0.1293
Epoch: 48/50 | Batch: 600/782 | 单Batch损失: 0.1768 | 累计平均损失: 0.1305
Epoch: 48/50 | Batch: 700/782 | 单Batch损失: 0.1327 | 累计平均损失: 0.1308
Epoch 48/50 完成 | 耗时: 98.37s | 训练准确率: 95.42% | 测试准确率: 90.21%
Epoch: 49/50 | Batch: 100/782 | 单Batch损失: 0.1130 | 累计平均损失: 0.1307
Epoch: 49/50 | Batch: 200/782 | 单Batch损失: 0.1521 | 累计平均损失: 0.1350
Epoch: 49/50 | Batch: 300/782 | 单Batch损失: 0.0868 | 累计平均损失: 0.1346
Epoch: 49/50 | Batch: 400/782 | 单Batch损失: 0.1548 | 累计平均损失: 0.1356
Epoch: 49/50 | Batch: 500/782 | 单Batch损失: 0.0865 | 累计平均损失: 0.1361
Epoch: 49/50 | Batch: 600/782 | 单Batch损失: 0.0882 | 累计平均损失: 0.1348
Epoch: 49/50 | Batch: 700/782 | 单Batch损失: 0.1218 | 累计平均损失: 0.1342
Epoch 49/50 完成 | 耗时: 98.23s | 训练准确率: 95.25% | 测试准确率: 90.16%
Epoch: 50/50 | Batch: 100/782 | 单Batch损失: 0.1220 | 累计平均损失: 0.1216
Epoch: 50/50 | Batch: 200/782 | 单Batch损失: 0.0555 | 累计平均损失: 0.1203
Epoch: 50/50 | Batch: 300/782 | 单Batch损失: 0.1986 | 累计平均损失: 0.1241
Epoch: 50/50 | Batch: 400/782 | 单Batch损失: 0.0847 | 累计平均损失: 0.1244
Epoch: 50/50 | Batch: 500/782 | 单Batch损失: 0.0798 | 累计平均损失: 0.1237
Epoch: 50/50 | Batch: 600/782 | 单Batch损失: 0.0511 | 累计平均损失: 0.1247
Epoch: 50/50 | Batch: 700/782 | 单Batch损失: 0.1219 | 累计平均损失: 0.1261
Epoch 50/50 完成 | 耗时: 97.92s | 训练准确率: 95.57% | 测试准确率: 90.20%训练完成! 开始绘制结果图表...
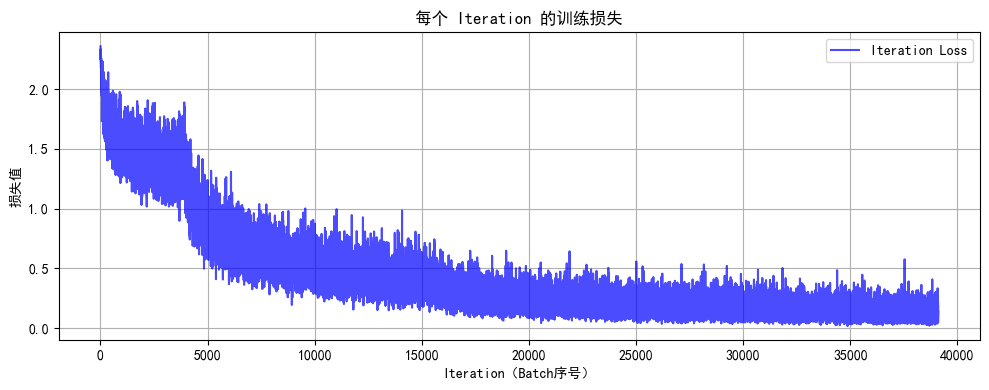
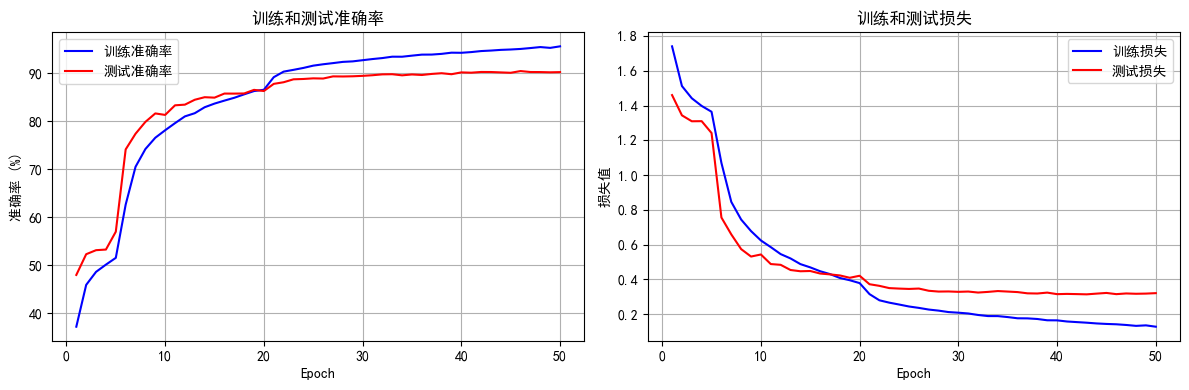
torch.save(model.state_dict(), 'resnet18_cbam_finetuned.pth')
print("模型已保存为: resnet18_cbam_finetuned.pth")模型已保存为: resnet18_cbam_finetuned.pth@浙大疏锦行