突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解到策略的最优解。现有的主流强化学习算法,包括A3C、TRPO、PPO、DSAC、DACER等,均使用这一机制进行求解,即需要对控制策略进行“一阶求导”,然后采用梯度下降原理更新策略的参数[1]。
然而,工业控制领域中,大量控制策略不具备“可导性”,这成为限制强化学习技术广泛应用的瓶颈难题。以两个典型场景为例:(1)当使用“有限状态机”或“决策树”为策略载体时,这类规则型策略导致系统运行状态不断跳转,决策动作呈现阶跃特性,就不具备可导性;(2)以“模型预测控制器”为核心的闭环控制系统中,控制动作是通过在线求解优化问题得到的,期间需经过多轮迭代计算,导致难以显式给出策略输出与策略参数之间的导数关系。对于这类控制策略的参数学习,长期以来都是研究者们亟待解决的难题。
让我们先看看机器学习领域怎么解决这一问题呢?当策略不可导的情形下,现有文献通常应用“零阶优化(Zeroth-Order Optimization)”方法。以典型零阶优化方法进化策略(Evolutionary strategies, ES)为例,在每一轮迭代中,当前策略 π μ \pi_\mu πμ在参数空间添加噪声进行探索。每个加噪策略 π θ i \pi_{\theta_i} πθi在环境中采样,得到单条轨迹的回合回报 R ( π θ i ) R(\pi_{\theta_i}) R(πθi),其中参数 θ i \theta_i θi在整条轨迹中保持不变。通过对噪声样本进行加权平均,就可以估计策略参数的“零阶梯度”:
∇ μ J ^ E S = ∑ i = 1 n R ( π θ i ) Σ − 1 ( θ i − μ ) \nabla_\mu\hat{J}_\mathrm{ES}=\sum_{i=1}^nR(\pi_{\theta_i})\Sigma^{-1}(\theta_i-\mu) ∇μJ^ES=i=1∑nR(πθi)Σ−1(θi−μ) 其中, n n n为单次迭代的样本数。公式(1)的这一想法是比较简单明了的,但是将其直接用于强化学习是否有效呢?
从梯度形式可以看出,梯度估计方差与噪声采样数量密切相关:(1)当 n n n很小时,估计值的方差会变得非常大而使学习过程不稳定;(2)当 n n n较大时,因为准确估计回报 R R R需要采样整条轨迹,导致每一轮交互的步数急剧增加,让训练效率急剧降低。对于强化学习问题而言,每一步的样本数据都是重新采集的,通常数量是比较少的,这使得梯度计算过程更加糟糕,甚至导致训练过程发散,不能收敛至最优解。这就是零阶强化学习方法固有的“样本效率”与“梯度方差”的平衡困境。针对这一难题,清华大学李升波教授课题组提出了完全依赖“零阶梯度”的高性能强化学习算法(Zeroth-Order Actor-Critic, ZOAC),通过实施逐时间步的参数空间加噪探索以及策略参数扰动的优势函数估计,破解了零阶强化学习算法易失稳,难求解的挑战,为有限状态机、决策树、规则化控制律等策略的训练提供了全新的工具[2][3]。
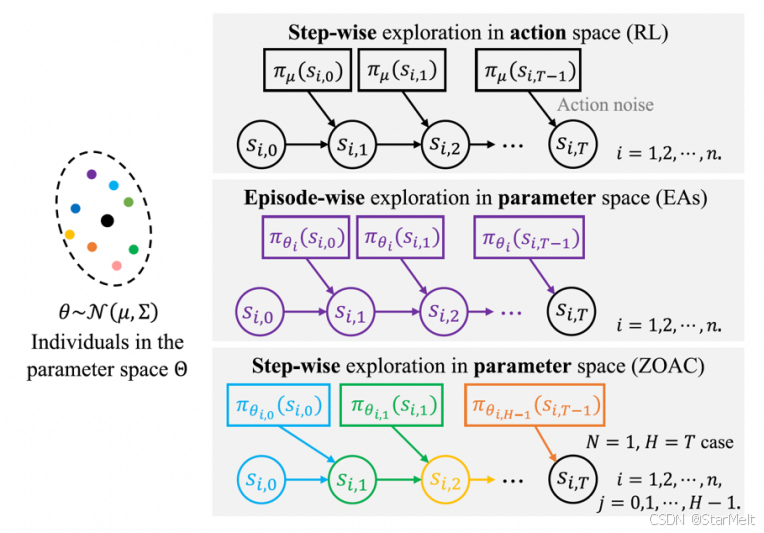
首先,为了解决样本效率和梯度方差的权衡问题,并充分提高学习过程中的探索能力,团队提出采用逐时间步的参数空间加噪探索策略 β μ , Σ \beta_{\mu,\Sigma} βμ,Σ,其中 μ \mu μ和 Σ \Sigma Σ分别为高斯噪声的均值和协方差矩阵,如图1所示。研究进一步推导了以最大化期望累计折扣奖励 J ( μ , Σ ) = E s ∼ d 0 v β μ , Σ ( s ) J(\mu,\Sigma)=\mathbb{E}_{s\sim d_{0}}v^{\beta_{\mu,\Sigma}}(s) J(μ,Σ)=Es∼d0vβμ,Σ(s)为目标的零阶策略梯度。实际算法可以通过采样求均值来近似期望值得到策略梯度的估计值:
∇ μ J ^ Z O A C = 1 n H ∑ i = 1 n ∑ j = 0 H − 1 ∑ k = 0 N − 1 ( γ λ ) k ( r i , j N + k + γ v i , j N + k + 1 β − v i , j N + k β ) Σ − 1 ( θ i , j − μ ) \nabla_\mu\hat{J}_\mathrm{ZOAC}=\frac1{nH}\sum_{i=1}^n\sum_{j=0}^{H-1}\sum_{k=0}^{N-1}(\gamma\lambda)^k\left(r_{i,jN+k}+\gamma v_{i,jN+k+1}^\beta-v_{i,jN+k}^\beta\right)\Sigma^{-1}(\theta_{i,j}-\mu) ∇μJ^ZOAC=nH1i=1∑nj=0∑H−1k=0∑N−1(γλ)k(ri,jN+k+γvi,jN+k+1β−vi,jN+kβ)Σ−1(θi,j−μ) 其中, n n n同样为每次迭代采样的轨迹数量,在单条轨迹中先后采样 H H H个带参数噪声的策略,每个策略向前执行 N N N步, λ \lambda λ为权衡偏差及方差的超参数。式(2)与式(1)的形式相似,梯度通过噪声向量的加权平均得到,规避了对策略端到端求导的需求,保证了方法的泛用性。然而区别在于,每个受扰策略仅与环境交互 N N N步,远远小于整条轨迹的长度。 对于参数空间中的每个噪声向量 θ i , j \theta_{i,j} θi,j,利用序贯决策问题的Markov属性估计了其优势函数 r i , j N + k + γ v i , j N + k + 1 β − v i , j N + k β r_{i,jN+k}+\gamma v_{i,jN+k+1}^{\beta}-v_{i,jN+k}^{\beta} ri,jN+k+γvi,jN+k+1β−vi,jN+kβ,作为轨迹总体回报值 R ( π θ i , j ) R\left(\pi_{\theta_{i,j}}\right) R(πθi,j)的高效而准确的替代。这与主流强化学习方法中对输出动作的优势函数有所区别,在策略参数空间中进行估计保证了与零阶优化迭代机制的深度融合。对理论分析表明,相同环境交互步数的前提下,ZOAC方法所估计的梯度在保证无偏的同时有着更低的方差,有利于提高策略训练速度和稳定性。
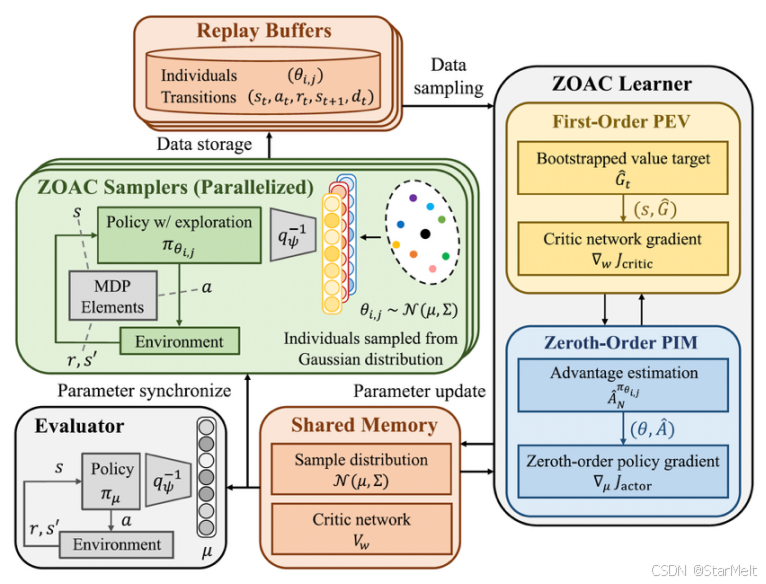
以此为基础,设计了如图2所示的适用于不可导策略的强化学习算法框架。学习器负责对策略进行迭代更新,主要包含两个交替执行的部分:(1)一阶策略评估(First-Order Policy Evaluation, PEV),算法引入值函数网络 V ( s ; w ) V(s; w) V(s;w)以近似状态值函数 v β ( s ) v^\beta(s) vβ(s)。根据经验池的状态经验样本,通过自举法估计状态价值目标,并通过最小化值函数网络输出值与状态价值目标的均方误差(Mean Squared Error, MSE)对网络参数 w w w执行更新;(2)零阶策略改进(Zeroth-Order Policy Improvement, PIM),根据采集到的轨迹片段,依托值函数网络对式(2)中的状态价值 v β v^\beta vβ进行近似估计,然后基于优势函数对策略参数的扰动方向进行加权平均,最终通过梯度上升更新策略参数 μ \mu μ。

综上所述,本研究针对现有静态零阶优化方法探索能力受限、学习效率低下的难题,提出了零阶强化学习方法ZOAC,结合了逐时间步的参数空间加噪探索方法,推导了考虑序贯决策问题Markov属性的零阶策略梯度,引入了策略参数扰动方向的优势函数以降低策略梯度估计方差,并进一步融合二元交替迭代求解架构,通过充分利用问题本身的时序结构加速策略训练过程。以此为基础,依托分布式计算框架搭建了决控策略的强化学习训练系统,并应用于规则型自动驾驶决控策略训练,验证了所提方法的可行性和有效性。
参考文献
[1]Li S E. Reinforcement learning for sequential decision and optimal control[M]. Singapore: Springer Verlag, 2023.
[2]Lei Y, Lyu Y, Zhan G, et al. Zeroth-Order Actor-Critic: An Evolutionary Framework for Sequential Decision Problems[J]. IEEE Transactions on Evolutionary Computation, 2025, 29(2). 555-569.
[3]Lei Y, Chen J, Li S E, et al. Performance-Driven Controller Tuning via Derivative-Free Reinforcement Learning[C]//2022 IEEE 61st Conference on Decision and Control (CDC). IEEE, 2022: 115-122.