GraphRAG优化新思路-开源的ROGRAG框架
目前的如微软开源的GraphRAG的工作流程都较为复杂,难以孤立地评估各个组件的贡献,传统的检索方法在处理复杂推理任务时可能不够有效,特别是在需要理解实体间关系或多跳知识的情况下。先说结论,看完后感觉这个框架性能上不会比GraphRAG高,仅在单一数据集上进行了评测,不过优化思路可以借鉴下,比如:双层次检索提高图检索准确性等。供参考。
方法

图构建及索引
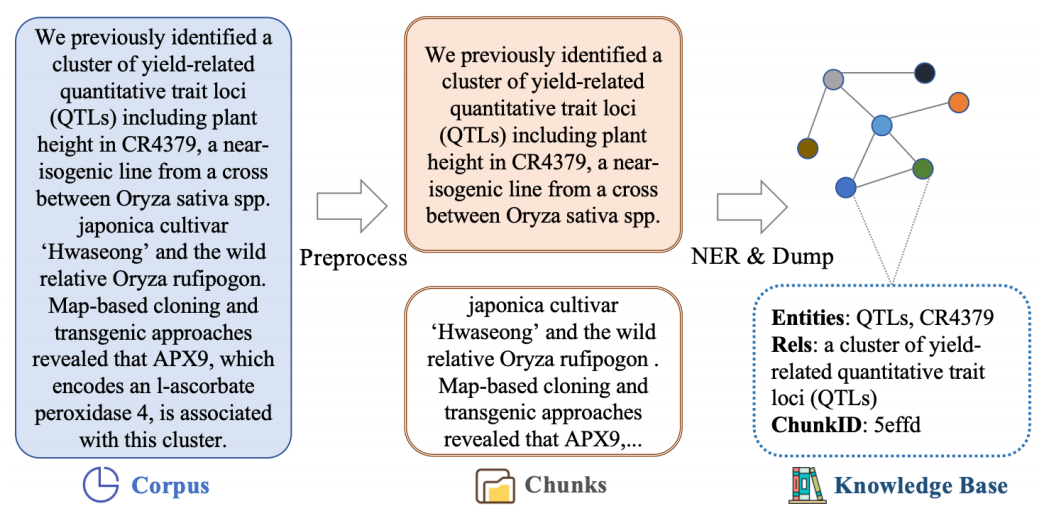
这一步主要是使用LLM构建知识图谱(KG),涉及预处理(多源异构内容转text)、文本chunk分割、KG构建(命名实体识别(NER)、分割的文本中提取<实体, 关系, 实体>三元组,以及相关的关键词、描述和权重。这些三元组用于构建图,捕捉语料中的复杂多跳依赖关系)、图存储。
图引导检索
这一步是ROGRAG的核心,分为两种主要方法:双层次方法和逻辑形式方法。
1、双层次方法
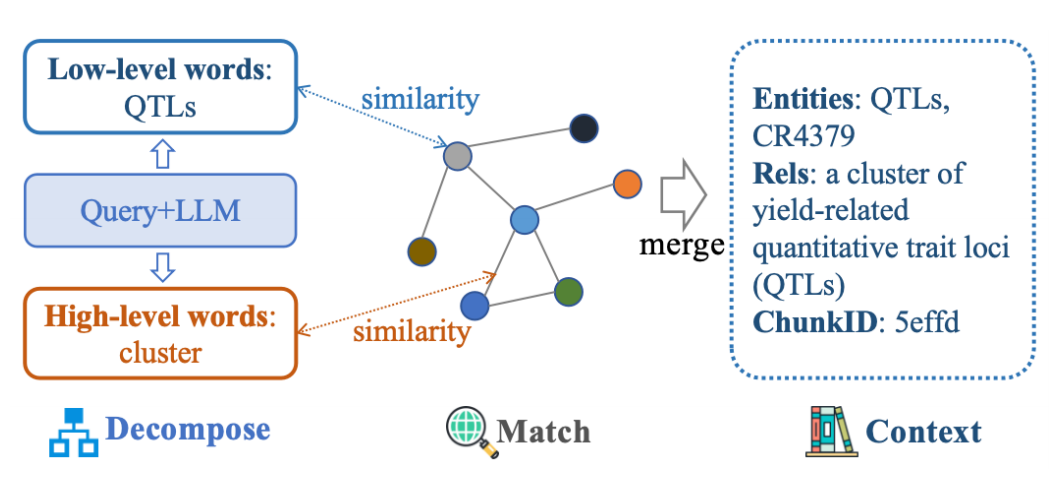
query被分解为两个组成部分:(1)表示实体的低层关键词和(2)高层关系描述。通过模糊匹配将实体与图中的节点匹配,关系关键词与边匹配。检索结果合并后,去除冗余的边、节点和块引用,精炼最终的检索上下文。优势是这种方法利用多粒度特征进行分层模糊匹配,提高了对不规范或复杂查询的检索覆盖率。
2、逻辑形式方法
使用预定义的操作符(如过滤、聚合)将自然语言查询转化为结构化的检索操作序列。利用LLM将自然语言查询转化为结构化的检索操作序列,并通过迭代优化来增强检索上下文。这种方法提供了更精确的检索结果,特别适用于需要结构化推理的任务。

图增强生成
这里和其他rag方法一致,主要优化输出。
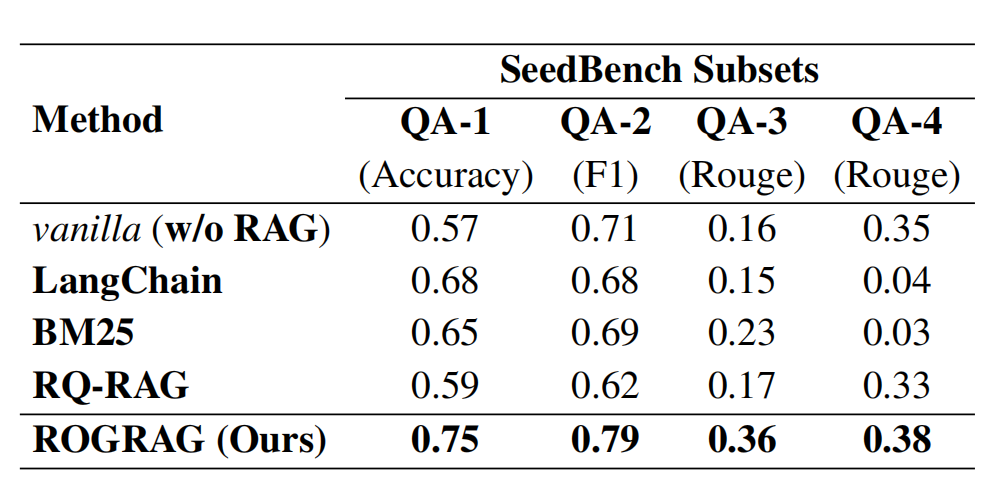
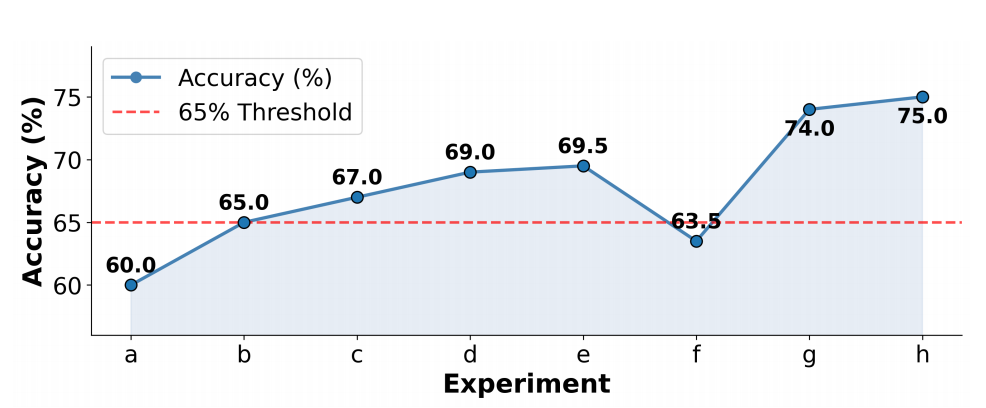
实验性能
整体结果
参考文献:
-
paper:ROGRAG: A Robustly Optimized GraphRAG Framework,https://arxiv.org/abs/2503.06474
-
code:https://github.com/tpoisonooo/ROGRAG