pcie问答--0609
3. retry buffer有多大?
retry number 2bit;最多只能发送4次retry tlp;
Replay Buffer Sizing:
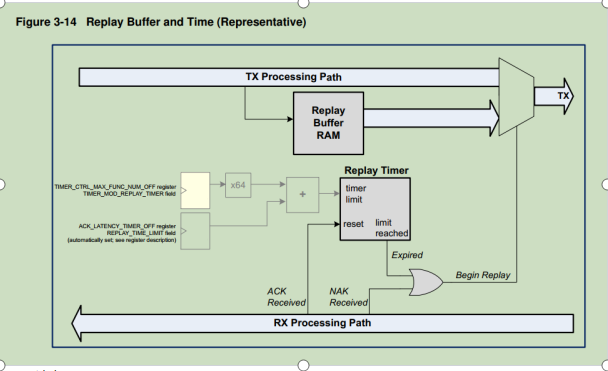
replay buffer 逻辑;大写均为定值;
4. Fcrc,Ecrc,Lcrc ,DCRC占用多少字节?分别是做什么用的?
Fcrc: stp token crc;4 bit
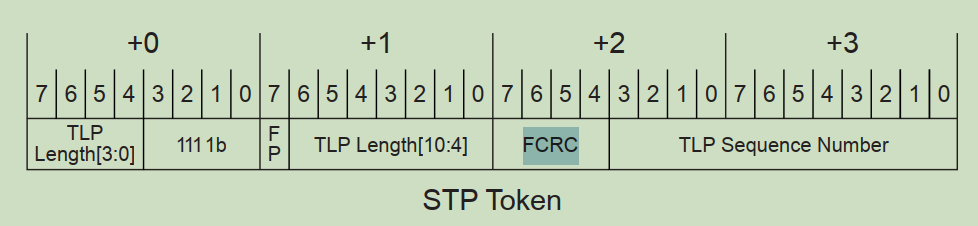
ECRC: tlp diagest,32bit
LCRC: LCRC 会 覆盖整个TLP包的内容,header+payload;DLLP LCRC规则;32bit
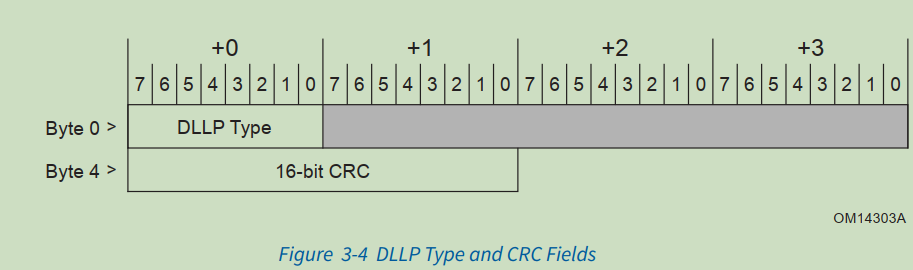
DCRC: dllp 包的crc;16bit;
7. 收到uncorrectable,correctable error之后会在哪里表现出来?并且收到对应的error之后应该怎么做?
pcie RX:
- 丢弃tlp
- 产生一个带CA或者UR的completion (np request)
- pci-compatible status register中标记
- AER en之后在AER status中标注
- 产生err MSG(usp only)
- 对于格式错误的TLP,credit将根据该TLP所占用的缓冲区空间予以返还。(不消耗credit)
9.pcie orderd 规则深层次下的逻辑是什么?该处在rtl是怎么实现?
以下内容只针对单个VC,每个vc都有自己的credit。
RO规则:举个例子
场景:
-
一个 CPU 向 EP 发出一个 Memory Write(写数据);
-
接着又发出一个 Memory Read(轮询状态寄存器);
-
如果这两个事务无依赖关系,可以设置 RO = 1;
-
这样 Read 请求可能被优先传输,提高响应速度。
但如果 Read 是用来判断 Write 是否完成,就必须 RO=0,以强排序确保写入完成后再读取
3.4.3 Receive Routing(S IP)
当使用axi bridge时,TRGT1 代替axi bridge;
TRGT0 端口 用来接受access或ELBI in an USP。
EP 模式路由规则
- CFG 路由TRGT0 端口之后通过LBC端口访问CDM
- BAR-match mem& IO request 路由到TRGT1
- MSG request内部解码,相关信号送到SII端口,
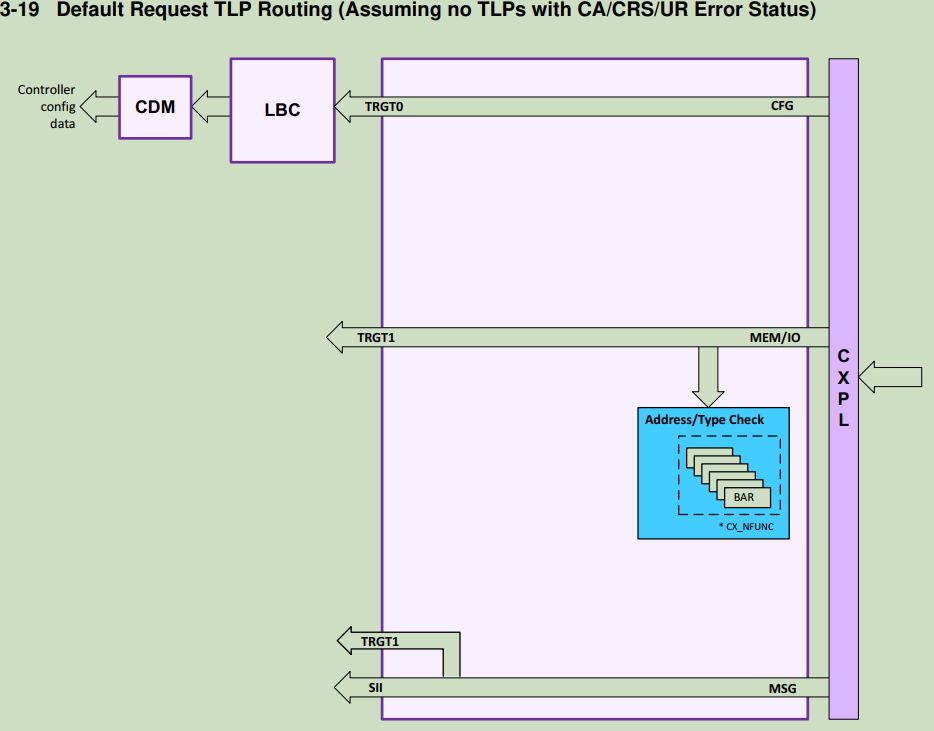
cpl包可能会路由到TRGT1或直接被discard;
Error Detection for Received TLPs
当controller 接收到错误之后,通常有以下流程:
- 丢弃该tlp包
- 设置一个completion(针对non-posted request),cs状态设置为CA或UR
- 在PCI-compatible status中设置
- 在AER中设置相关的register
- 产生一个error MSG(USP only)
- 对于错误的TLP包 credit被返还
advanced ordering information
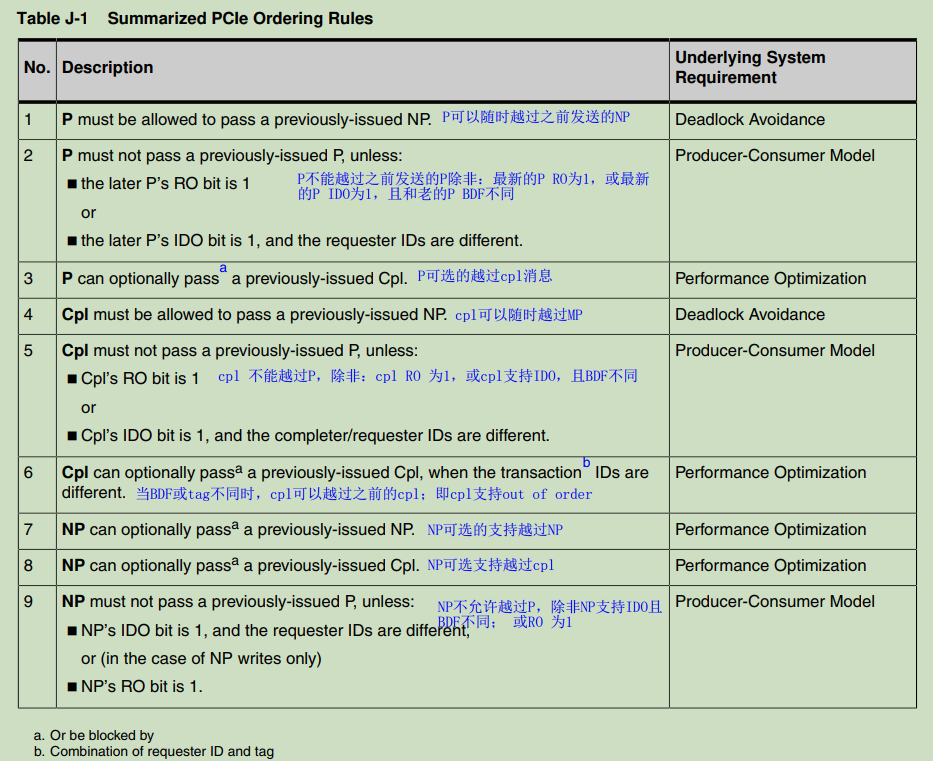
遵循以下三个规则:
1. 生产消费模型
2. 避免死锁
3. 性能优化;
生产消费模型
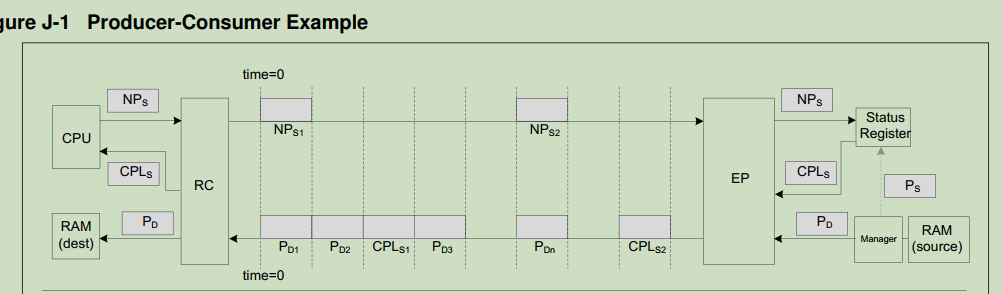
生产者:EP,把本端的RAM内容发送到对端,设为为Pd,最后一个Pd发送完成之后往本地status register中设置status。
消费者:CPU(RC)polling(轮询)EP侧的status register,检查 manager(ep)是否完成。Polling 请求当作NPs,以cpls返回。
生产-消费模型:cpl不能超过Pd,且cpu不能提前消费。对于不在该轮内部的P和cpl 包,可以设置RO(relax order)为1,来加快传输性能。
如果设定了“cpl must not pass P”,可以用其他的方式来实现status 的判断。推荐使用中端方式。
必须先要producer 完成写之后,consumer 才允许读操作。为了确保这个规则,必须确保已经发出的Post 操作不能被其他操作越过。表2,5,9规则满足该条件。以下提升性能的方式:
1. Producer-Consumer Relaxed Ordering (RO) Optimization
cpl可以越过P
2.Producer-Consumer ID-Based Ordering (IDO) Optimization
cpl或request不是来源于同一个ID(bdf号或者tag id),cpl或request可以pass P。
bypass,cut-through,store-and-forward
bypass:该tlp类型可以越过任何类型的tlp包,不受规则约束;
-
它可以绕过其他类型的 TLP;
-
控制器对它不施加严格的顺序约束;
-
常用于消息型 TLP,如中断、PME、错误通知等。
📌 举例:
-
一个 INTx 中断消息(Message TLP)可以绕过先前排队的 Memory Write TLP 被优先处理;
-
但一个 Memory Write TLP 不能绕过另一个排在它前面的 Memory Write TLP(FIFO)。
cut-through:
cut-through是一个转发策略,收到一个tlp之后,在接受完整的header(3DW,4DW)后,就可以立刻开始转发数据,不用等待整个tlp接受完。
✅ 特点:
-
延迟更低(特别是数据较大的 TLP);
-
需要有能力检查前缀即可决策目标端口;
-
常用于交换芯片、PCIe switch、DMA controller。
📌 举例:
一个 512B 的 Memory Read Completion 数据包:
-
在 cut-through 模式下,可能只需接收前 16~24 字节就可以开始向目标端口转发;
-
提高了链路利用率和响应速度。
store-and-forward:
与 cut-through 相反,store-and-forward 是:
-
控制器或交换器在完全接收完整个 TLP 之后,
-
再将其转发到目的端口。
✅ 特点:
-
延迟更高;
-
可以先进行完整性校验(如 LCRC 校验),确保无误后再转发;
-
更安全、稳健,适合需要完整检查 TLP 正确性的应用。
Inbound (Receive) Order Enforcement
只针对trgt1/rbyp 端口;不对 trgt0,elbi,sii端口进行排序。所有TLP类型被认为是cut-through,或store-and-forward;
PCIe Ordering (CX_RADM_ORDERING_RULES =1):
Strict Priority Delivery (CX_RADM_ORDERING_RULES =0):
1. The Posted queue is delivered until it is empty, or halted by your application.
2. The Completion queue is delivered until it is empty, or halted by your application.
❑ When the Posted queue is halted, the Completion queue becomes blocked unless RO of the
Completion is 1.
3. The Non-Posted queue is delivered until it is empty, halted by your application, or blocked as
follows:
❑ When the Posted queue is halted, the Non-Posted queue becomes blocked.
❑ When the Completion queue is halted, the Non-Posted queue becomes blocked.
❑ When the Completion queue is blocked (by a halted Posted queue), the Non-Posted queue
becomes blocked
Outbound (Transmit) Order Enforcement
控制器不会在以下接口之间自动维持事务的顺序:
-
DBI、VMI、SII、XALI0、XALI1、XALI2 等;
-
也不维持这些接口的事务与控制器自己生成的 Completion 或 Message 的顺序。
发送优先级(TLP arbitration priority,高优先级先发):
-
消息 TLP(包括控制器内部自动发的消息,或 VMI 请求发出的 message)
-
控制器为 Config 读/写内部寄存器生成的 Completion
-
来自 XALI0/1/2 的 TLP(使用 round-robin 算法轮询选择)
Outbound Order Enforcement on XALI0/1/2
-
XALI0/1/2 使用**轮询调度(round robin)**来决定谁先发;
-
控制器判断是否有 credit,如果有就选中当前轮询到的接口发送 TLP;
-
不管事务类型,调度过程本身不区分 MWr、MRd、Cpl 等类型。
即使 Completion 可越过被blocked的 Posted,
-
XALI1 自身后续的 Cpl 或 Nposted 是不能越过 XALI1 当前被阻塞的 MWr 的。
即:一个接口内,前面的 TLP 阻塞住了,后面的 TLP 也发不出去。
AXI Bridge 特例:
如果配置中启用了 AXI Bridge:
-
XALI0/1/2 接口就被隐藏;
-
你的系统会通过 AXI 接口发出请求;
-
控制器内部做 AXI → PCIe 转换;
-
AXI ordering 规则另有说明(在该文档第 480 页)。
10.啥叫个生产消费模型,生产了什么?被谁消费了?
生产:数据从哪里来;
消费:数据被谁用了。见上一个问题