【AI论文】CASS:Nvidia到AMD的数据、模型和基准测试的转换
摘要:我们引入了CASS,这是第一个用于跨架构GPU代码转译的大型数据集和模型套件,针对源代码级(CUDAleftrightarrowHIP)和汇编级(NvidiaSASSleftrightarrowAMDRDNA3)的翻译。 该数据集包括主机和设备上的70k个经过验证的代码对,解决了低级GPU代码可移植性的关键差距。 利用这一资源,我们训练了CASS系列领域特定语言模型,实现了95%的源语言翻译准确率和37.5%的汇编翻译准确率,大大超过了GPT-4o、Claude和Hipify等商业基线。 在超过85%的测试用例中,我们生成的代码与原生性能相匹配,保持了运行时和内存行为。 为了支持严格的评估,我们引入了CASS-Bench,这是一个跨越16个GPU领域的基准,具有地面实况执行能力。 所有数据、模型和评估工具均以开源形式发布,以促进GPU编译器工具、二进制兼容性和LLM引导的硬件翻译方面的进展。 数据集和基准测试位于Huggingface。Huggingface链接:Paper page,论文链接:2505.16968
一、研究背景和目的
研究背景:
图形处理器(GPU)作为现代机器学习和科学计算工作负载的基石,因其高吞吐量的并行处理能力而广受欢迎。NVIDIA的Compute Unified Device Architecture(CUDA)已成为GPU加速的主流编程模型,但其与专有硬件的紧密耦合导致了严重的供应商锁定问题。CUDA代码无法在非NVIDIA的GPU上运行,因为它们的指令集架构(ISA)不兼容。这使得拥有大量CUDA代码库的组织在迁移到其他平台时面临高昂的工程成本。与此同时,AMD GPU因其有利的性价比而日益受到数据中心和消费设备的青睐,这促使了对在AMD硬件上执行遗留CUDA程序的需求,而无需进行全面的软件重写。
为了应对这一挑战,AMD引入了Heterogeneous-computing Interface for Portability(HIP),这是一个C++ GPU API,旨在镜像CUDA的功能,同时支持跨平台开发。然而,现有的工具如HIPIFY仅在源代码级别进行转换,无法执行预编译的CUDA二进制文件,且在转换CUDA程序时表现出较高的失败率。此外,由于NVIDIA和AMD的ISA和编译管道存在分歧,跨供应商的GPU汇编翻译面临更大挑战。因此,开发一种能够在源代码和汇编级别进行跨架构GPU代码转译的方法变得至关重要。
研究目的:
本文旨在解决跨架构GPU代码转译的问题,通过构建第一个大规模的数据集CASS,包含CUDA到HIP的源代码对以及NVIDIA SASS到AMD RDNA3的汇编代码对。利用这一资源,本文训练了CASS系列领域特定语言模型,以实现高精度的源代码和汇编代码转译。此外,为了支持严格的评估,本文还引入了CASS-Bench基准测试,该基准测试跨越了16个GPU领域,并提供了真实执行结果的验证。研究的主要目的包括:
- 构建大规模跨架构GPU代码转译数据集:收集、合成并验证70k个CUDA到HIP的源代码对以及NVIDIA SASS到AMD RDNA3的汇编代码对。
- 训练高精度的领域特定语言模型:利用CASS数据集训练模型,以实现高精度的源代码和汇编代码转译,超越现有的商业基线。
- 引入严格的评估基准:构建CASS-Bench基准测试,以评估模型在跨架构GPU代码转译任务上的性能。
- 开源数据、模型和评估工具:将所有数据、模型和评估工具以开源形式发布,以促进GPU编译器工具、二进制兼容性和LLM引导的硬件翻译方面的研究进展。
二、研究方法
1. 数据集构建:
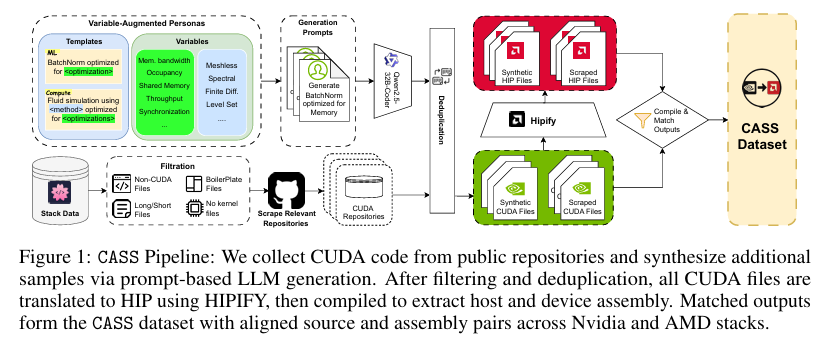
CASS数据集的构建包括三个主要步骤:CUDA代码抓取、合成数据生成以及转译和编译。
- CUDA代码抓取:利用Stackv2数据集提取CUDA源文件,并通过筛选和去重得到24k个可用的CUDA样本。
- 合成数据生成:使用Qwen2.5-Coder32B大型语言模型,通过变量增强角色策略生成CUDA内核代码,最终得到46.3k个有效的CUDA样本。
- 转译和编译:使用HIPIFY工具将CUDA代码转译为HIP代码,并编译得到主机和设备的汇编代码。同时,收集OpenCL代码片段并编译为汇编代码,以增加数据集的多样性。最终得到70k个对齐的汇编样本。
2. 模型训练:
本文训练了CASS系列领域特定语言模型,包括用于源代码转译和汇编代码转译的模型。模型基于Qwen2.5-Coder进行微调,并在不同参数规模(1.5B、3B和7B)下进行训练。训练过程中采用了DeepSpeed和Liger Kernel等优化技术,以提高训练效率和硬件利用率。
3. 评估基准构建:
为了评估模型的性能,本文构建了CASS-Bench基准测试,该基准测试跨越了16个GPU领域,并提供了真实执行结果的验证。每个领域包含1到5个精心策划的提示,用于生成CUDA实现,并在NVIDIA硬件上编译和执行以获得参考输出。然后,使用模型生成相应的AMD代码,并编译执行以验证功能正确性。
三、研究结果
1. 数据集分析:
CASS数据集显示了CUDA和HIP在源代码和汇编级别上的显著结构差异。汇编文件的长度、语法相似性和操作码多样性等方面均存在显著差异。例如,AMD设备汇编的平均长度是NVIDIA的两倍,且汇编代码的准确性在不同领域间存在显著差异。尽管如此,转译后的代码在执行时与原生代码在内存使用和运行时间上高度匹配,超过85%的样本在两者上的差异均在±5.6%以内。
2. 模型性能:
CASS系列模型在源代码转译任务上取得了95%的准确率,在汇编代码转译任务上取得了37.5%的准确率,显著优于GPT-4o、Claude和HIPIFY等商业基线。特别是在CASS-Bench基准测试上,CASS模型的表现远超其他模型,证明了其在跨架构GPU代码转译任务上的有效性。
3. 基准测试结果:
CASS-Bench基准测试的结果显示,CASS模型在大多数领域上均能生成功能正确的代码,且生成的代码在运行时和内存行为上与原生代码高度匹配。这进一步验证了CASS模型在跨架构GPU代码转译任务上的实用性和有效性。
四、研究局限
尽管CASS数据集和模型在跨架构GPU代码转译任务上取得了显著成果,但仍存在一些局限性:
-
数据集多样性:尽管CASS数据集包含了70k个对齐的代码对,但在某些复杂或代表性不足的领域上,数据集的多样性可能仍然有限。这可能导致模型在这些领域上的性能不佳。
-
模型规模:本文训练的CASS模型最大规模为7B参数,这可能限制了模型在更复杂任务上的性能。更大规模的模型可能能够捕获更多的模式和细节,从而提高转译的准确性。
-
汇编代码转译的复杂性:汇编代码转译是一个高度复杂的任务,涉及对底层硬件架构的深入理解。尽管CASS模型在汇编代码转译上取得了一定成果,但在某些复杂或特定于硬件的优化上,模型可能仍然存在不足。
-
评估基准的局限性:CASS-Bench基准测试虽然涵盖了16个GPU领域,但可能仍然无法完全代表所有实际的GPU应用场景。因此,模型在实际应用中的性能可能需要进一步验证。
五、未来研究方向
针对上述研究局限,未来研究可以从以下几个方面展开:
-
扩展数据集多样性:通过收集更多来自不同领域和应用的CUDA和HIP代码,以及合成更多样化的汇编代码,来扩展CASS数据集的多样性。这将有助于提高模型在复杂或代表性不足的领域上的性能。
-
探索更大规模的模型:研究更大规模的领域特定语言模型在跨架构GPU代码转译任务上的性能表现。通过增加模型参数数量,可以进一步提高模型的表达能力和转译准确性。
-
优化汇编代码转译方法:针对汇编代码转译的复杂性,探索更有效的转译方法和优化策略。例如,可以研究如何结合静态分析和动态执行信息来提高转译的准确性;或者开发针对特定硬件架构的优化器,以生成更高效的汇编代码。
-
完善评估基准:构建更全面、更具代表性的评估基准,以更准确地评估模型在跨架构GPU代码转译任务上的性能。这可以包括收集更多实际应用场景中的代码对,以及设计更严格的评估指标和测试用例。
-
结合其他技术:探索将跨架构GPU代码转译与其他技术(如自动化代码优化、编译器优化等)相结合的可能性。通过结合这些技术,可以进一步提高转译后代码的性能和效率。
-
关注实际应用:将研究成果应用于实际的GPU编程和迁移项目中,以验证其在真实场景中的有效性和实用性。通过与行业伙伴合作,可以收集更多实际应用中的反馈和数据,以指导后续的研究和改进工作。
总之,本文提出的CASS数据集和模型为跨架构GPU代码转译领域的研究提供了新的方向和思路。未来研究可以进一步扩展数据集多样性、探索更大规模的模型、优化汇编代码转译方法、完善评估基准、结合其他技术以及关注实际应用等方面展开工作,以推动该领域的持续发展和进步。