如何实现高可用评论服务
和内容发布服务类似,评论可以拆分成评论元信息和评论文本两部分,因为评论内容可能是图片、视频等。
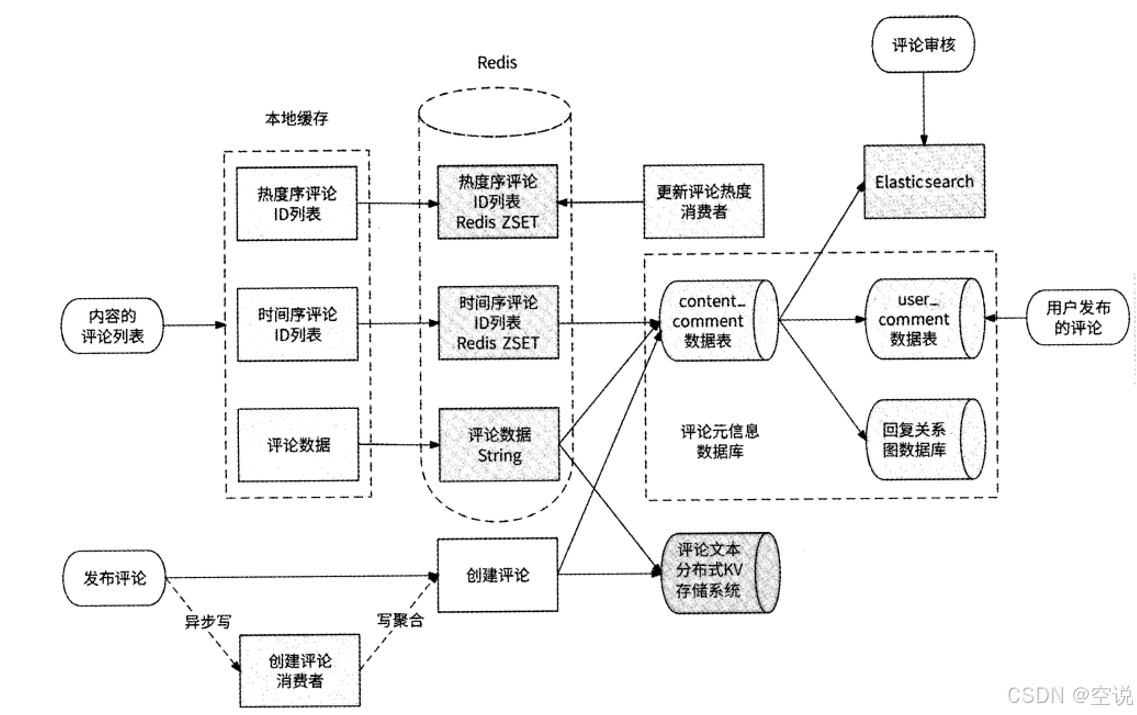
架构图
不同模式
单级模式:所有评论在一个层级下
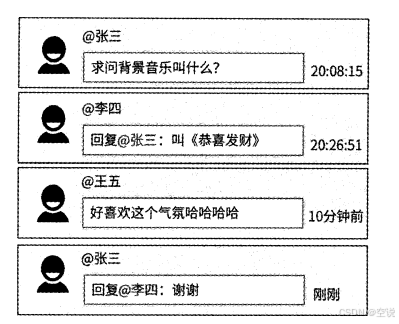
二级模式:所有对内容的评论作为一级评论,对某一级评论的回复视为这条评论的二级评论
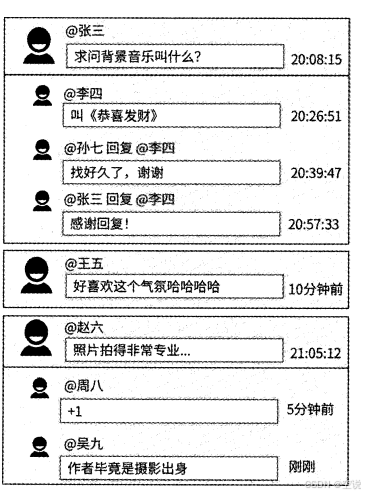
盖楼模式:谁回复了谁一目了然
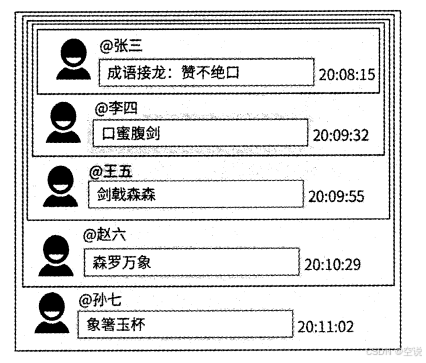
单级模式
表设计如下:
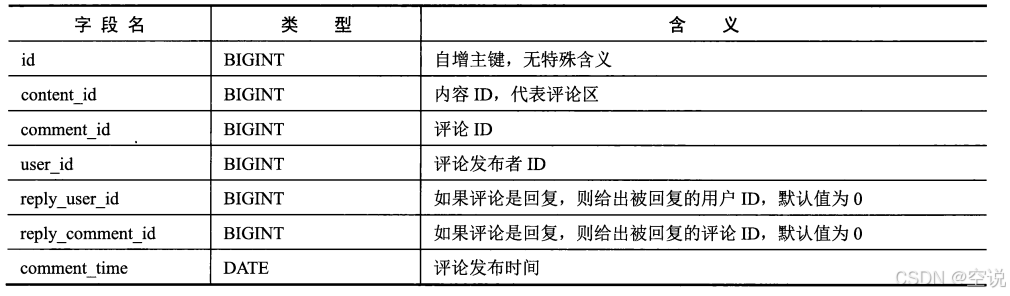
索引设计:
需要查询某内容下所有评论,而且一般按照评论发布时间排序的话,需要有(content_id, comment_time)联合索引,如果要删除某评论的话,客户端可以传入content_id、comment_time、comment_id,也可以命中该索引,所以不需要额外建立comment_id索引
如果要查出用户的历史评论的话,需要(user_id, comment_time)联合索引,而两个索引第一个字段不一样,所以如果要分库分表的话,面临一个分片键的选择。我们可以采用数据表冗余设计,创建两个一模一样的表content_comment和user_comment,通过监听binlog保证二者一致
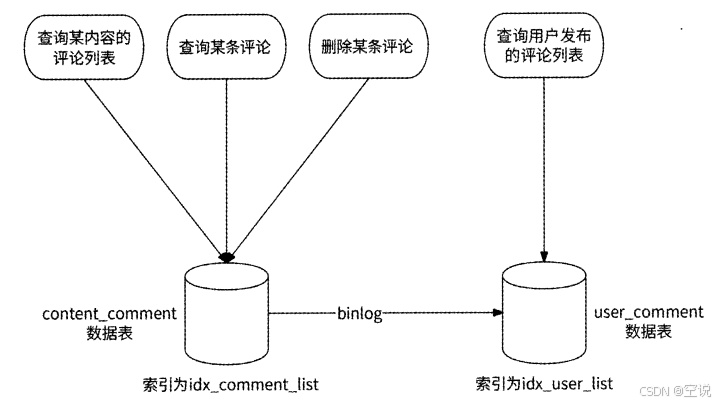
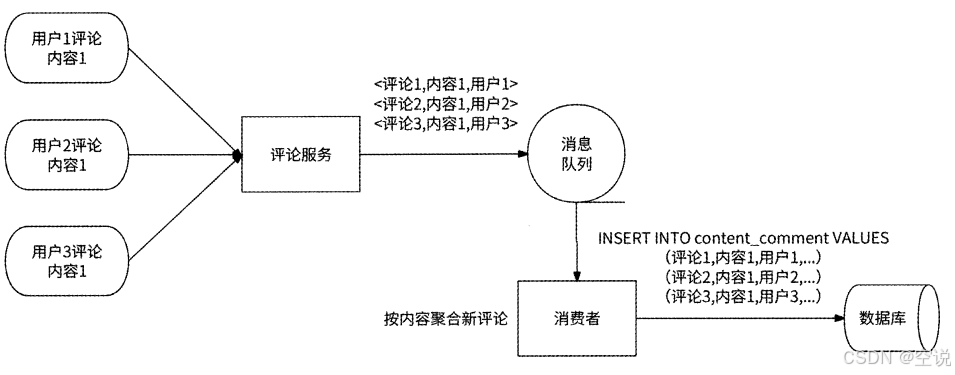
高并发设计:
评论是一个读多写多的场景,并且一个内容的所有评论会被路由到同一张表中,我们可以采用异步写+写聚合的方案来处理高并发写的场景:
对于读取,我们可以把前N条评论用缓存存储,同样使用ZSet,并且可以使用本地缓存
盖楼模式
盖楼模式的最大特点是可以展示每条评论的完整楼层,楼层由初始评论和回复组成。假设在一条内容下,用户1发布了评论,用户2回复了用户1,用户3回复了用户2……用户100回复了用户99,那么对于用户100的回复来说,用户1〜用户100的评论组成了 一个层数为100的楼层——不仅展示了用户100的评论,而且展示了用户1〜用户99的完整回复链路。所以,在盖楼模式下,通过每条评论都能回溯到完整的回复链路,以组成楼层。
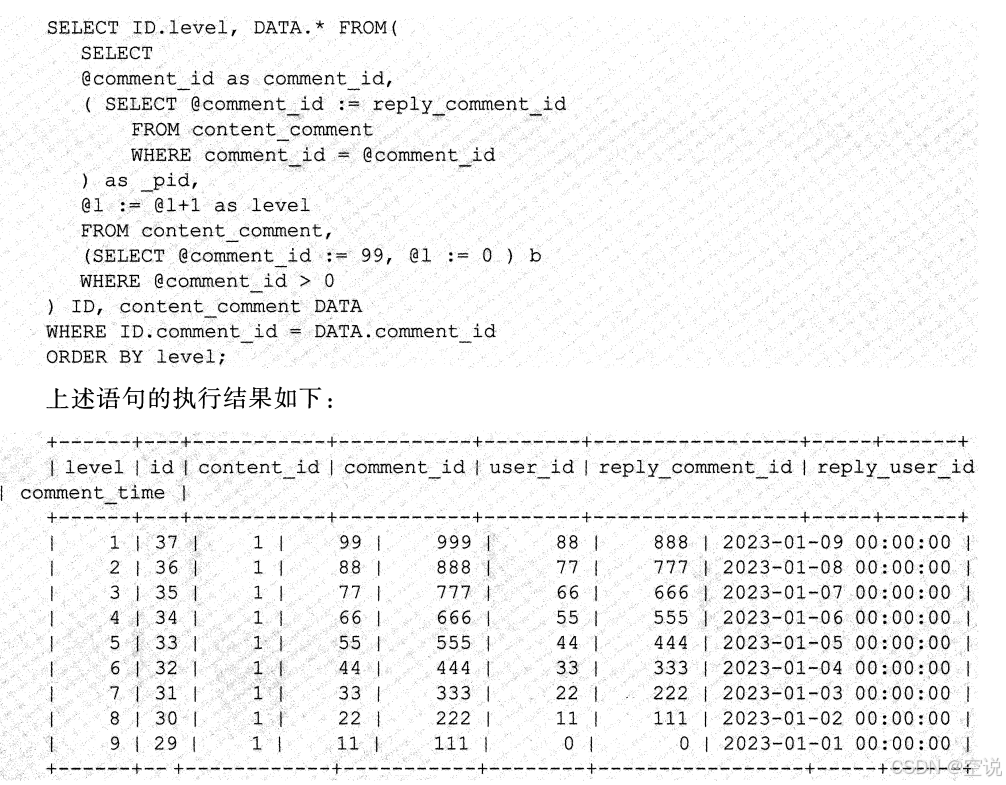
回顾单级模式的content_comment数据表设计,comment id字段和reply_comment_id字段记录了一条评论与另一条评论的回复关系。如果要展示一条评论的盖楼情况,则需要从此评论的记录开始,根据reply_comment_id字段不断递归查询上一层的评论记录,直到遍历到此字段为0的评论记录才停止,此时表示已查询到顶层评论。在递归过程中,查询到的每条评论自底向上组成楼层
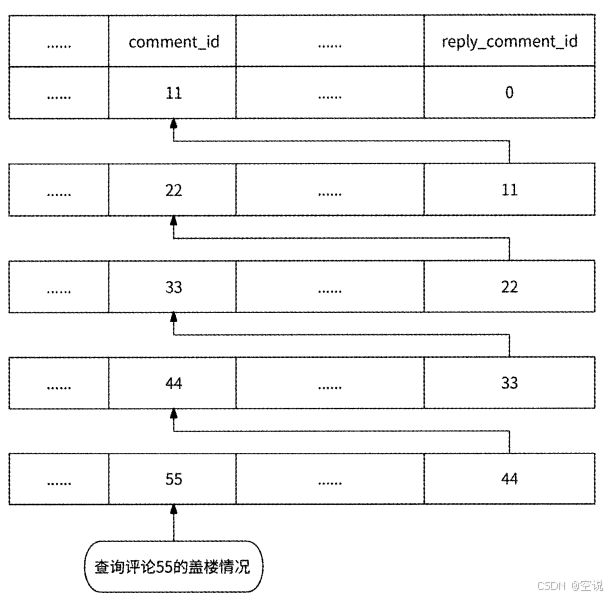
可以写SQL查询:
二级模式
在二级评论区中,对一级评论的回复和对回复的回复一般按照评论发布时间由远及近排序。而一级评论由于相互之间没有互动关系,所以既可以使用传统的按照评论发布时间对其进行排序,也可以使用更为个性化的排序方式来展示一些精彩的评论,比如微博评论区支持按照热度排序和按照时间排序两种规则,默认按照热度排序。所谓热度是一个比较笼统的概念,不同产品一般采用不同的热度定义,比如点赞数、回复数、发布时间等属性都会影响评论的热度
总之,在二级模式的评论功能中包括两种评论列表。
点击打开内容评论区,展示由一级评论组成的评论列表。
点击打开一级评论的评论区,展示由二级评论组成的评论列表。
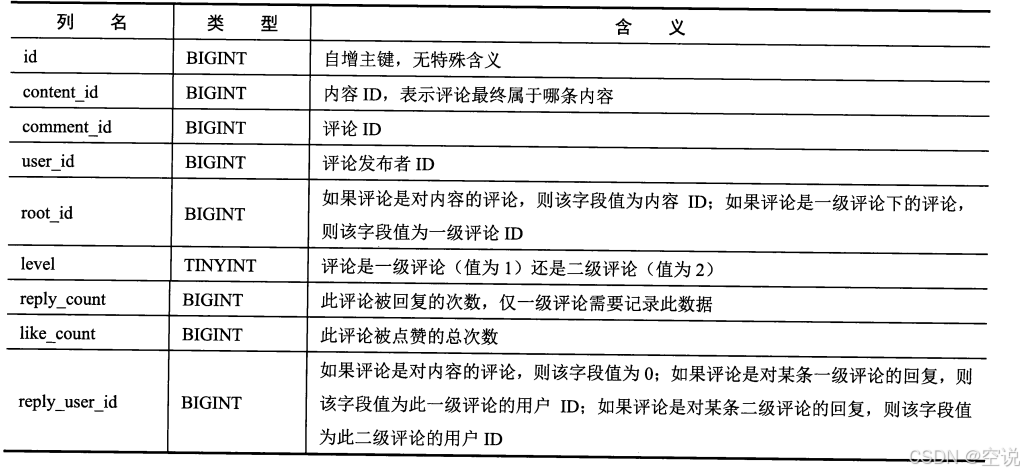
二级模式评论功能的数据模型需要区分一条评论是一级评论还是二级评论,还需要区分一条二级评论回复的是一级评论还是二级评论,这是设计二级模式评论元信息数据的核心所在
表设计:

索引设计:
查询所有一级评论:where root_id = 1 and level = 1 order by comment_time
查询一级评论下面的二级评论:where root_id = 2 and level = 2 order by comment_time
查询用户历史评论:where user_id = 1 order by comment_time desc
所以需要索引(root_id, level, comment_time)和(user_id, comment_time),考虑到分库分表的情况,我们仍然需要做冗余表设计,content_comment和user_comment
评论状态:可以给评论划分一些状态
- 全员可见:所有人都能看到此评论。
- 仅好友可见:仅相互关注的好友能看到此评论。
- 自见:只有评论发布者可以看到此评论,评论发布者会认为自己已经发布了评论。
- 审核中:已被审核召回的评论处于审核中状态,此时评论的可见性与自见相同。
- 删除:审核没通过的评论会被标记为此状态,任何人都看不到此评论。
- 神评论:评论审核不只是对不合规的评论进行删除,还会把最热门的评论标记为 “神评论”,以便对可提高用户活跃度的评论进行正向鼓励
热度排序:
可以把前N条评论按照热度展示,后N条仍然按照时间顺序排序,这意味着同一条评论可能同时出现在热度和时间里面,当进行分页查询时,需要判断上次读取是热度还是时间,所以入参需要有标识,如果是热度,本次继续是热度(可能不够,那就夹杂时间),如果是时间,本次继续是时间:
- 客户端读取第 1 页的评论,请求参数为(content_id=1, offset=0, from_where='hot')。评论服务在收到请求后,按照from_where参数的要求访问Redis ZSET对象获取前10条热门评论,执行语句:ZREVRANGE hot_comment_1 0 9,返回10条评论的评论ID,并告知客户端 from_where 为 hot, offset 为 10。
- 客户端读取第 2 页的评论,请求参数为(content_id=1, offset=10, from_where='hot')。评论服务在收到请求后,按照from where参数的要求访问Redis ZSET对象获取第11〜20 条热门评论,执行语句:ZREVRANGE hot_comment_1 10 19。由于热门评论一共只有16条,所以此次只得到6条热门评论。此时评论服务转而从时间序评论列表中获取前4条评论,即在SQL语句中设置LIMIT 0, 4。在组合这10条评论后,告知客户端from_where time, offset 为 4
- 客户端读取第 3 页的评论,请求参数为(content_id=1, offset=4, from_where='time')。 评论服务在收到请求后,按照from_where参数的要求访问时间序评论列表,获取第5 ~ 14 条评论,即在SQL语句中设置LIMIT 4,10。在得到若干评论后,告知客户端from_where 为 time, offset 为 14。