详解什么是One-Hot Encoding (独热编码)
什么是独热编码 (One-Hot Encoding)?
独热编码是一种在数据预处理中常用的技术,用于将分类变量 (Categorical Variables) 转换为适合机器学习算法处理的数值格式。它的核心思想是:将每个类别表示成一个二进制向量,在这个向量中,只有代表该类别的那一位是 “热”的 (值为 1),其余所有位都是 “冷”的 (值为 0)。
为什么需要独热编码?
大多数机器学习算法(如线性回归、逻辑回归、支持向量机、神经网络等)需要数值输入。如果只是简单地将类别标签编码成整数(例如:红=0, 绿=1, 蓝=2),算法可能会错误地认为这些类别之间存在数值上的顺序或大小关系(例如:认为 红(0) < 绿(1) < 蓝(2)),但实际这些类别通常是无序且相互独立的(如颜色、国家、品牌)。独热编码通过为每个类别创建独立的二元特征,彻底消除了这种潜在的误导性排序关系。
工作原理:
-
识别唯一类别: 找出该分类特征中所有不同的类别。
-
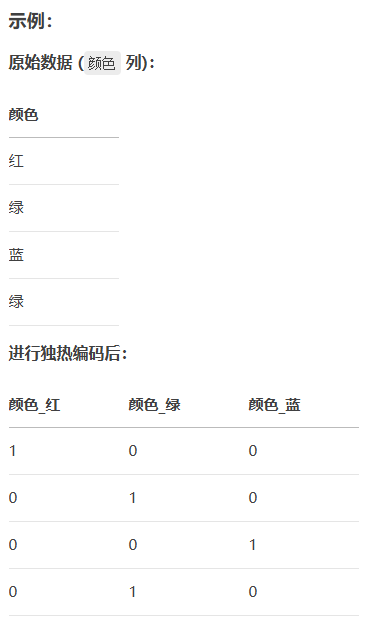
示例:特征
颜色包含["红", "绿", "蓝"]→ 唯一类别:["红", "绿", "蓝"]。
-
-
创建新的二进制列: 为每一个唯一类别创建一个新的二元特征(列)。
-
示例:新列命名为
颜色_红,颜色_绿,颜色_蓝。
-
-
赋值 1 和 0: 对于数据中的每一行:
-
在其所属类别对应的新列上标记为 1。
-
在其他所有新列上标记为 0。
-
关键要点:
-
虚拟变量陷阱 (Dummy Variable Trap): 如果一个分类特征有
k个不同类别,独热编码会创建k个新列。这可能导致多重共线性 (Multicollinearity) 问题(即新列之间存在完美的线性关系,例如颜色_红 + 颜色_绿 + 颜色_蓝 = 1)。为了避免这个问题并减少冗余,通常会删除其中一列(例如,只保留k-1列)。被删除的那个类别可以通过所有新列都是0来表示(称为参照类别)。 -
高基数问题 (High Cardinality): 如果一个分类特征包含非常多的类别(例如:邮政编码、用户ID、产品SKU,可能有成百上千个),独热编码会创建大量新列,导致数据维度急剧膨胀(维度灾难),增加计算负担和过拟合风险。这种情况下,应考虑其他编码方式(如目标编码、特征哈希、嵌入)。
-
稀疏矩阵 (Sparse Matrix): 独热编码的结果矩阵中大部分元素是
0。像scikit-learn这样的库在内部会使用稀疏矩阵格式来高效存储这种数据,节省内存空间。
何时使用独热编码?
-
名义数据 (Nominal Data): 类别之间没有内在顺序的数据(如:颜色、国家、品牌、产品类型)。
-
低到中度基数 (Low-to-Moderate Cardinality): 类别数量相对较少(通常少于 15-20 个)。
-
适用的算法: 对数值关系敏感的模型,如:
-
线性模型(线性回归、逻辑回归)
-
支持向量机 (SVM)
-
基于距离的算法(KNN)
-
神经网络 (Neural Networks)
-
朴素贝叶斯 (Naive Bayes)
-
替代方案:
-
标签编码 (Label Encoding): 直接将类别映射为整数 (
0, 1, 2...)。仅适用于有序分类变量 (Ordinal Data)(如:"低"=0,"中"=1,"高"=2)。 -
目标编码/均值编码 (Target Encoding / Mean Encoding): 用该类别下目标变量的平均值来替换类别标签。对高基数特征有效,但需小心过拟合。
-
特征哈希 (Feature Hashing / Hashing Trick): 将类别映射到固定数量的桶(特征)中,通过哈希函数实现。用于处理极高基数特征,但可能发生哈希冲突。
-
嵌入 (Embeddings): 深度学习中使用的方法,通过训练学习一个低维、稠密的向量来表示每个类别(如:词嵌入)。特别适合高基数特征和自然语言处理。