日志的具体使用
配置文件配置日志路径等
在 Java 项目中,无论是本地开发环境(Windows)还是生产部署环境(Linux),日志配置都通过 application.yml 或 logback-spring.xml 文件来实现,主要目的是将程序运行中的信息和异常记录到文件中以便调试和追踪。
在本地开发环境中,程序通常运行在 IDE(如 IntelliJ IDEA)中,日志默认会输出到控制台。如果没有额外配置日志路径,Spring Boot 会在项目根目录下生成一个名为 spring.log 的日志文件。为了更清晰地管理日志,建议在 application.yml 中配置日志输出路径,例如设置为 D:/logs/app.log,或在 logback-spring.xml 中指定路径。开发环境可以同时保留控制台输出和文件输出,方便调试。
而在生产环境中,Java 程序一般以 JAR 包或容器方式运行在 Linux 服务器上,不依赖控制台输出,因此日志通常直接写入指定文件。推荐将日志输出路径设置为 /home/app/logs/app.log 或 /var/log/myapp/app.log 等规范位置。同时,为了防止日志文件过大或无限增长,生产环境中应启用按天或按文件大小滚动的日志策略,并设置保留天数(如 7~30 天)。这通常通过 logback-spring.xml 中的 RollingFileAppender 和 TimeBasedRollingPolicy 来实现。
方式1:通过 application.yml
windows本地测试环境:
logging:file:name: D:/logs/myapp.log // windows本地开发指定日志地址这时日志就会写入 Windows 的
D:\logs\myapp.log。
Lunix生产环境
logging:file:name: /home/myapp/logs/app.log // Lunix的文件路径level:root: INFO
这会把日志写到
/home/myapp/logs/app.log,这个路径是 Linux 文件系统路径。
方式2:通过 logback-spring.xml
试用于生产环境当中
<?xml version="1.0" encoding="UTF-8"?>
<configuration><!-- 设置日志文件路径(可根据环境变量替换) --><property name="LOG_PATH" value="/home/myapp/logs"/><!-- 日志格式说明:%d:时间戳[%thread]:线程名%-5level:日志级别,最小宽度5%logger{36}:日志记录器名字,最长36字符%msg:日志内容%n:换行符(必须写!)--><appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"><!-- 当前日志写入的文件 --><file>${LOG_PATH}/app.log</file><!-- 滚动策略:按天生成新文件 --><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><!-- 文件命名规则(每天一个文件) --><fileNamePattern>${LOG_PATH}/app.%d{yyyy-MM-dd}.log</fileNamePattern><!-- 最多保留30天日志 --><maxHistory>30</maxHistory></rollingPolicy><encoder><!-- 日志格式 + 换行 --><pattern>%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger{36} - %msg%n</pattern><charset>UTF-8</charset></encoder></appender><!-- 根日志配置,控制最小输出级别 --><root level="INFO"><appender-ref ref="FILE"/></root></configuration>
| 配置项 | 说明 |
|---|---|
${LOG_PATH} | 可设置为 /var/log/app、/opt/project/logs 等生产标准目录 |
app.log | 当前正在写入的日志 |
app.2025-06-04.log | 滚动后生成的按日期归档日志文件 |
maxHistory=30 | 只保留最近 30 天,自动删除更老的日志 |
%msg%n | 必须包含 %n,确保每条日志后换行 |
无论在哪种环境下,日志记录异常信息都需要通过日志工具手动调用,例如在 try-catch 块中使用 logger.error("错误信息", e) 记录异常及其堆栈。日志框架不会自动捕获所有异常,必须由开发者明确写入日志。
如何明确写入日志呢?
不使用 @Slf4j 时,要自己创建 Logger 对象
如果你不想用 Lombok(或不能用),那你就得自己这样写:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;public class MyService {private static final Logger logger = LoggerFactory.getLogger(MyService.class);public void test() {logger.info("日志输出测试");}
}
使用 @Slf4j 可以简化 Logger 创建(推荐)
加上这个注解后:
@Slf4j
public class MyService {public void test() {log.info("日志输出测试"); // log 对象自动注入了}
}
日志级别决定了这条日志是否会真正被“输出”到控制台或文件。
你可以通过配置文件(如 application.yml 或 logback-spring.xml)设置当前系统允许“最小级别”的日志输出。
如果你不分级别、乱打日志:
-
要么生产环境日志过多,查不到重点信息;
-
要么 debug 日志没开,调试时候什么都看不到;
-
要么大量 info 日志白白写入磁盘浪费空间。
日志级别怎么使用?(从高到低)
| 日志级别 | 说明 | 适用场景 |
|---|---|---|
ERROR | 错误级别,程序执行失败 | 异常捕获、严重失败 |
WARN | 警告级别,潜在问题 | 数据不一致、配置问题 |
INFO | 正常流程信息 | 用户登录成功、订单创建成功等 |
DEBUG | 调试信息 | 参数打印、中间变量、流程细节 |
TRACE | 详细追踪信息 | 函数调用细节(极少用) |
logging:level:root: INFO
表示:低于 INFO 的日志不会打印(比如 DEBUG、TRACE)
推荐做法:
logging:level:com.example: DEBUG # 某个包开启 DEBUGroot: INFO # 其他默认 INFO
在异常中写日志的标准写法
记录消息 + 异常堆栈
try {// 异常代码
} catch (Exception e) {log.error("订单创建失败,订单号:{}", orderId, e);
}
不推荐写法 ❌(只记录 e.getMessage())
log.error("出错了:" + e.getMessage()); // 没有堆栈,调试困难
“没有堆栈”指的是日志里只显示了异常的文字描述,没有显示异常是在哪个类、哪一行代码、经过哪些调用链发生的,这样就不利于定位问题。
所以:
写日志时,一定记得带上异常对象(e)本身,才能输出堆栈信息!
若依AI的操作日志部分是如何实现的?
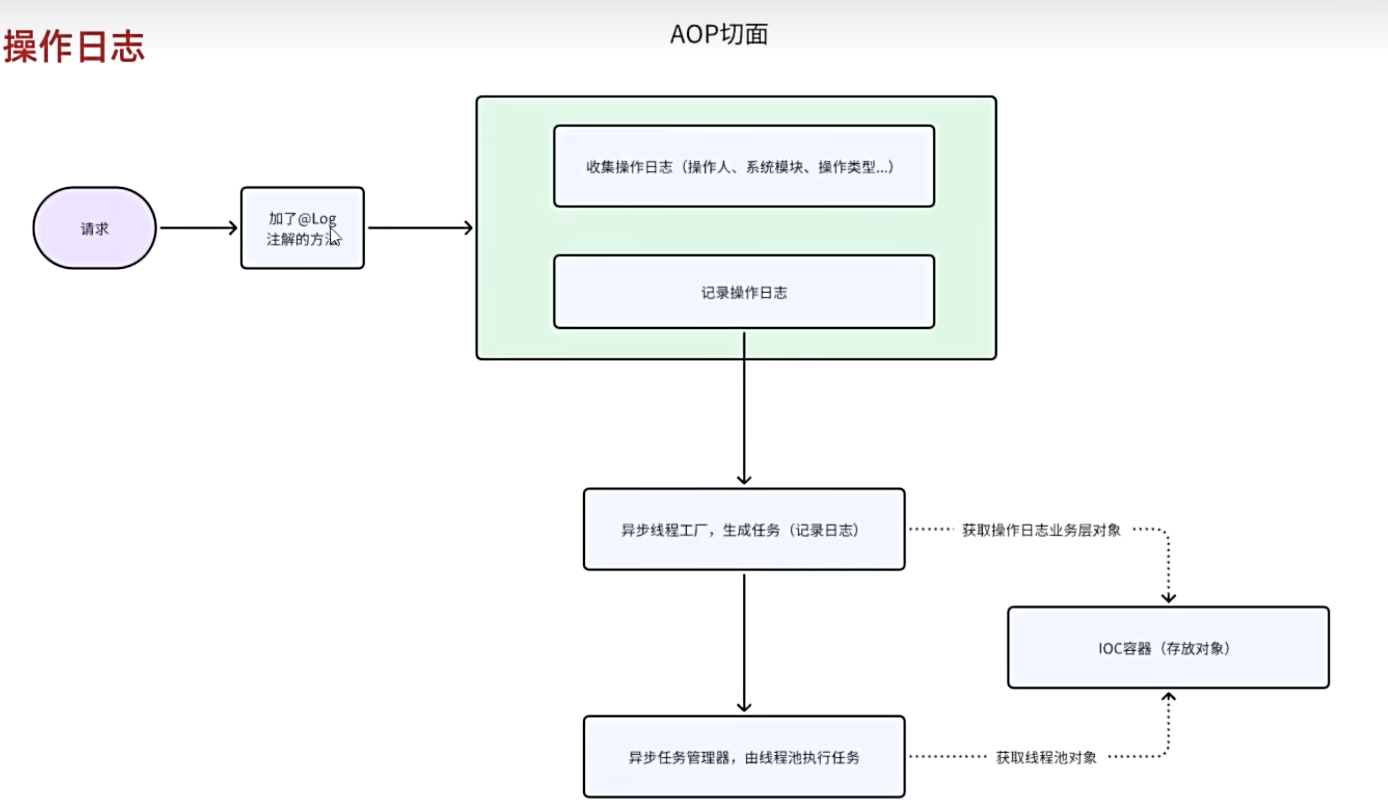
通过自定义注解+AOP实现只要请求进入了一个被 Spring 管理、且带有 @Log 注解的方法,AOP 就会在方法执行前、执行后或异常时执行相应的拦截逻辑,从而触发日志记录流程。
使用方法
/*** 新增售货机货道*/@PreAuthorize("@ss.hasPermi('manage:channel:add')")@Log(title = "售货机货道", businessType = BusinessType.INSERT)@PostMappingpublic AjaxResult add(@RequestBody Channel channel){return toAjax(channelService.insertChannel(channel));}自定义注解
 LogAspect.java
LogAspect.java
@Before(方法执行前)
/*** 处理请求前执行*/@Before(value = "@annotation(controllerLog)")public void boBefore(JoinPoint joinPoint, Log controllerLog){TIME_THREADLOCAL.set(System.currentTimeMillis());}记录当前时间,用于计算操作耗时。
@AfterReturning(方法正常执行结束后)
/*** 处理完请求后执行** @param joinPoint 切点* 你拦截的“目标方法”,它的类名、方法名、参数、返回值,全部都可以通过 JoinPoint 拿到。* controllerLog:controllerLog 就是你写在 @Log(...) 注解中那些参数的载体,是注解对象本身。*/@AfterReturning(pointcut = "@annotation(controllerLog)", returning = "jsonResult")public void doAfterReturning(JoinPoint joinPoint, Log controllerLog, Object jsonResult){handleLog(joinPoint, controllerLog, null, jsonResult);}protected void handleLog(final JoinPoint joinPoint, Log controllerLog, final Exception e, Object jsonResult){try{// 获取当前的用户LoginUser loginUser = SecurityUtils.getLoginUser();// *========数据库日志=========*//SysOperLog operLog = new SysOperLog();operLog.setStatus(BusinessStatus.SUCCESS.ordinal());// 请求的地址String ip = IpUtils.getIpAddr();operLog.setOperIp(ip);operLog.setOperUrl(StringUtils.substring(ServletUtils.getRequest().getRequestURI(), 0, 255));if (loginUser != null){operLog.setOperName(loginUser.getUsername());SysUser currentUser = loginUser.getUser();if (StringUtils.isNotNull(currentUser) && StringUtils.isNotNull(currentUser.getDept())){operLog.setDeptName(currentUser.getDept().getDeptName());}}// 存在异常if (e != null){operLog.setStatus(BusinessStatus.FAIL.ordinal());// 更新状态为异常operLog.setErrorMsg(StringUtils.substring(e.getMessage(), 0, 2000));}// 设置方法名称String className = joinPoint.getTarget().getClass().getName();String methodName = joinPoint.getSignature().getName();operLog.setMethod(className + "." + methodName + "()");// 设置请求方式operLog.setRequestMethod(ServletUtils.getRequest().getMethod());// 处理设置注解上的参数getControllerMethodDescription(joinPoint, controllerLog, operLog, jsonResult);// 设置消耗时间operLog.setCostTime(System.currentTimeMillis() - TIME_THREADLOCAL.get());// 保存数据库AsyncManager.me().execute(AsyncFactory.recordOper(operLog));}catch (Exception exp){// 记录本地异常日志log.error("异常信息:{}", exp.getMessage());exp.printStackTrace();}finally{TIME_THREADLOCAL.remove();}}handleLog 方法的作用总结
| 阶段 | 具体操作 |
|---|---|
| 1️⃣ 前置准备 | 获取当前用户、请求 IP、URL、请求方法等 |
| 2️⃣ 构建日志对象 | 构造 SysOperLog 日志实体,并设置各种字段 |
| 3️⃣ 判断异常 | 判断是否抛出异常,设置状态为失败并记录错误信息 |
| 4️⃣ 解析注解信息 | 读取 @Log 注解上的业务信息,如操作标题、模块、是否记录参数 |
| 5️⃣ 记录参数与响应 | 根据配置记录请求参数和响应数据(排除敏感字段) |
| 6️⃣ 记录耗时 | 计算方法执行耗时(通过 ThreadLocal 暂存开始时间实现) |
| 7️⃣ 异步入库 | 调用 AsyncManager.me().execute(...) 异步写入数据库 |
LogAspect 是如何“找到”哪些方法有这个注解,并对它们执行日志记录的?
通过 Spring AOP 的“切点表达式” @annotation(...) 实现自动筛选并拦截所有加了 @Log 注解的方法。
Spring AOP 能将注解对象 @Log 自动注入为切面方法的参数,是因为你在切点中使用了 @annotation(...),而参数的类型又刚好就是这个注解的类型。Spring 会通过反射自动解析当前执行的方法注解,并把它注入给你。
| 内容 | 说明 |
|---|---|
@Before("@annotation(controllerLog)") | 表示:拦截所有加了 @Log 注解的方法 |
Log controllerLog | 表示:接收这个方法上的注解对象 |
这个 Log controllerLog 会由 Spring AOP 自动注入当前方法上的 @Log 注解;
你可以像访问普通 Java 对象那样访问它的字段:
controllerLog.title(); // 获取 title = "用户管理"
controllerLog.businessType(); // 获取操作类型,如 INSERT、UPDATE
controllerLog.operatorType(); // 获取操作人类型(后台管理员、前台用户等)
JoinPoint 就是“当前切面切入的那个点”的上下文容器,通过它你可以拿到被拦截方法的各种信息(目标对象、签名、入参等),从而在切面中完成日志、权限、事务、性能监控等横切逻辑。
spring AOP 在底层大量依赖反射来完成 JoinPoint 的相关功能
// 设置方法名称
//拿到的是目标对象的运行时类型的全限定类名,比如:com.yourcompany.service.OrderService
String className = joinPoint.getTarget().getClass().getName(); //拿到的是被调用的方法名,不带参数列表、返回值之类的信息,比如:createOrder
String methodName = joinPoint.getSignature().getName();// 拼接之后com.yourcompany.service.OrderService.createOrder()
operLog.setMethod(className + "." + methodName + "()");总结:
操作日志记录是通过 自定义注解配合 Spring AOP 切面来实现的。主要步骤如下:
-
定义注解
@Log
注解可以加在类或方法上,注解中包含多个字段(如:模块、功能类型、是否保存请求参数等),一般我们只需要填写 模块名(title) 和 操作类型(businessType)。 -
创建切面类
LogAspect
使用@Aspect注解定义一个切面类,用于拦截所有加了@Log注解的方法。通常会实现三个通知:-
@Before:前置通知,记录方法开始执行的时间(用ThreadLocal存储当前时间) -
@AfterReturning:后置通知,方法成功返回后记录操作内容 -
@AfterThrowing:异常通知,方法抛出异常时记录失败日志
-
-
日志处理逻辑(handleLog)
在通知中调用一个统一的处理方法handleLog(),这个方法会:-
解析注解内容(如功能类型、模块名)
-
获取方法签名、执行耗时、请求参数、返回结果等信息
-
封装为操作日志对象
SysOperLog -
使用异步线程(
AsyncManager)写入数据库,避免阻塞主线程
-