Dify 工作流全解:模块组成、设计思路与DSL实战指南
目录
- 前言
- 1 Dify 工作流概述
- 1.1 什么是工作流?
- 1.2 工作流的运行机制
- 2 工作流模块详解
- 2.1 输入模块(Input Node)
- 2.2 Prompt 模块
- 2.3 函数模块(Function Node)
- 2.4 条件判断模块(If Node)
- 2.5 工具调用模块(Tool Node)
- 2.6 输出模块(Output Node)
- 3 如何设计一个高效的 Dify 工作流
- 3.1 明确目标与用户输入
- 3.2 拆解任务步骤
- 3.3 模块化构建流程
- 3.4 合理使用变量和上下文
- 3.5 设置容错与默认路径
- 4 工作流DSL文件介绍与使用
- 4.1 DSL 文件结构说明
- 4.2 如何导出/导入工作流 DSL
- 4.3 DSL 文件的进阶使用
- 5 实战案例:构建一个产品推荐工作流
- 6 小结与展望
- 结语
前言
在多模态AI应用迅速发展的当下,越来越多开发者与企业开始探索如何通过流程自动化与智能化组合,构建更高效的智能系统。Dify 作为一款开源的大模型应用开发平台,不仅提供了完善的知识库、模型调用与前后端集成能力,更引入了灵活的「工作流(Workflow)」机制。工作流让开发者可以以模块化、可视化的方式串联多个智能组件,构建复杂的AI交互逻辑。
本文将围绕 Dify 的工作流系统展开,详解其核心模块、设计方法及DSL脚本的实际使用,帮助你快速掌握构建高效智能工作流的关键能力。

1 Dify 工作流概述
1.1 什么是工作流?
在 Dify 中,工作流(Workflow)是一个可视化的流程引擎,它允许用户以图形化方式组合多个功能模块,形成一条有逻辑、有依赖的任务路径。每一个工作流节点都是一个功能实体,可以是一个 Prompt 模块,也可以是函数调用、HTTP请求、变量处理等执行单元。
通过工作流,用户可以实现:
- 多轮对话逻辑控制
- 调用多个不同模型或工具完成协作任务
- 条件判断、变量传递、数据加工等复杂行为
1.2 工作流的运行机制
工作流的本质是一张有向图,节点之间通过连接线建立执行路径。Dify 后端会根据图的依赖关系自动调度各个节点的执行顺序。系统支持串行、并行、条件分支等执行模式,并能够在流程中使用全局变量,实现跨节点的数据共享与逻辑判断。
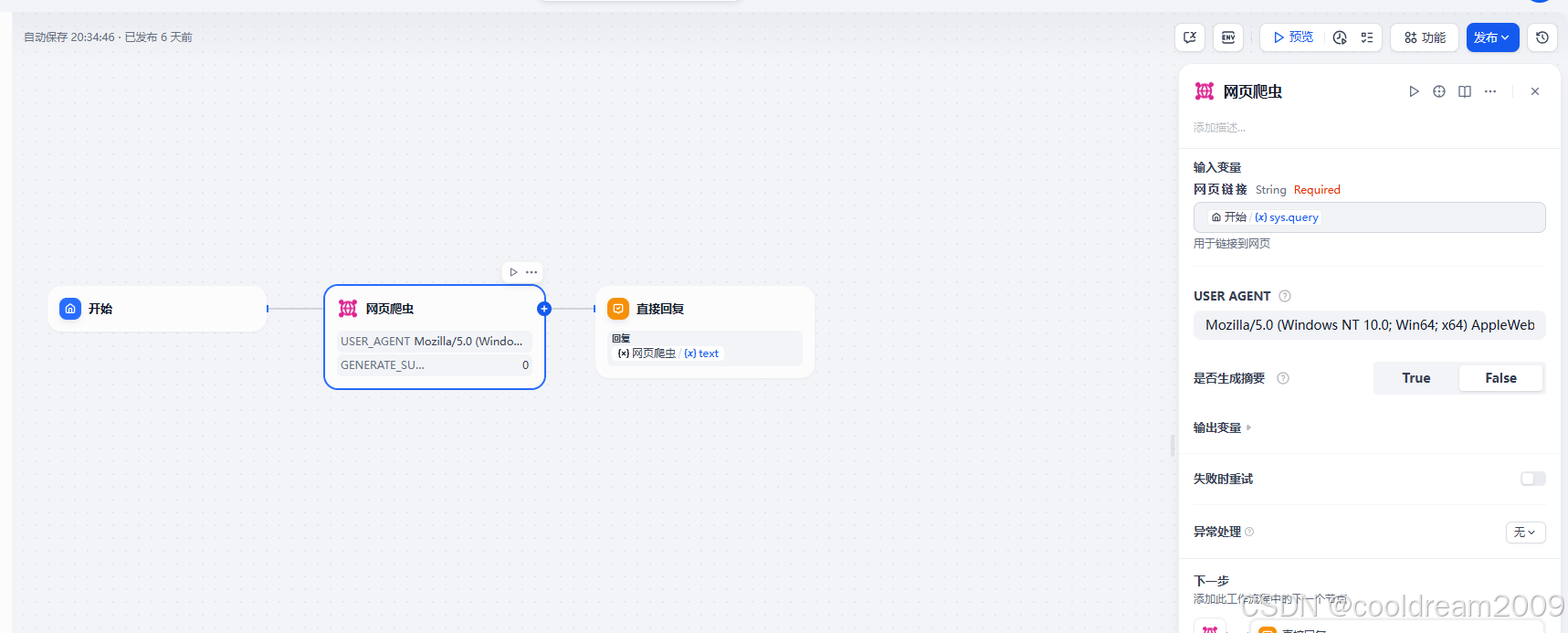
2 工作流模块详解
Dify 的工作流系统由若干模块组成,不同模块承担着不同类型的计算与控制任务。常见的核心模块如下:
2.1 输入模块(Input Node)
输入模块是工作流的起点,用于接收用户输入或外部请求数据。支持多种类型的输入变量设定,包括文本、数值、布尔值、数组等。每次调用时,输入数据会自动绑定到上下文环境中,供后续模块调用。
2.2 Prompt 模块
Prompt 模块是工作流的核心部分,它调用指定的大语言模型,基于用户输入及上下文变量生成回答或执行任务。开发者可以使用模板语法自定义 Prompt 内容,还可以设置温度、Top P、最大长度等参数以控制模型输出行为。
2.3 函数模块(Function Node)
函数模块允许用户执行自定义逻辑,比如对模型结果进行加工、格式转换或做数学运算等。目前支持 Python 风格的内联脚本编写,并能访问流程上下文中的所有变量。
2.4 条件判断模块(If Node)
条件模块实现分支控制。它根据某个布尔表达式结果决定流程走向,从而实现类似 if-else 的逻辑跳转。条件表达式支持使用上下文变量和逻辑运算符。
2.5 工具调用模块(Tool Node)
Dify 支持集成外部工具或插件(如 Web Search、计算器、数据库查询等)。工具模块可以配置参数并调用外部服务,处理后的结果也会自动写入流程上下文。
2.6 输出模块(Output Node)
输出模块是工作流的终点。它将结果展示给用户或返回给调用方,支持自定义返回内容与格式,是最终交互的呈现口。
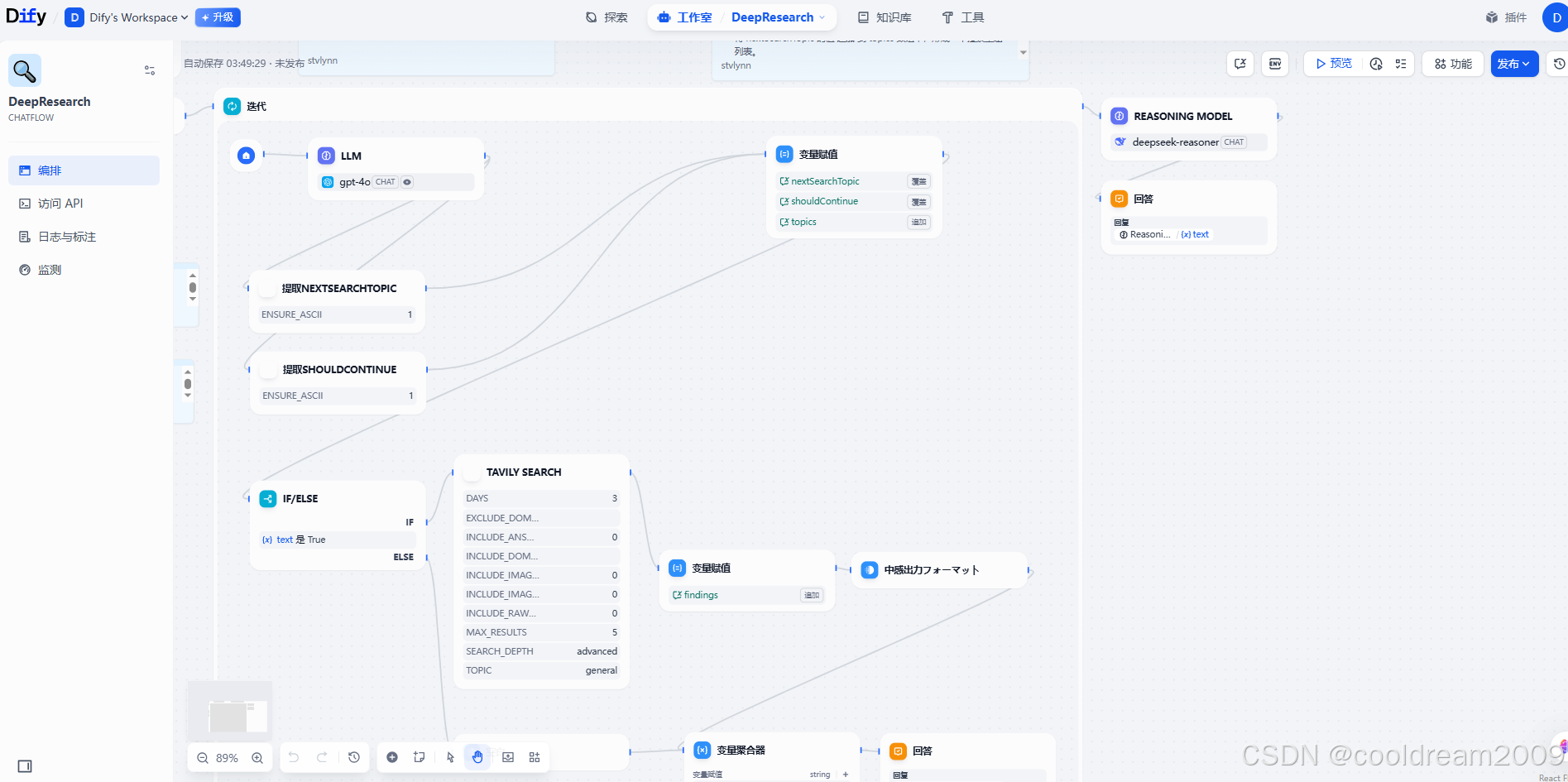
3 如何设计一个高效的 Dify 工作流
设计 Dify 工作流的关键是模块划分与数据流设计。一个好的工作流设计应当满足高内聚、低耦合、易扩展的原则。以下是设计过程的几个关键步骤:
3.1 明确目标与用户输入
首先需要明确用户通过工作流希望完成什么任务,以及有哪些输入变量。例如一个“智能问答机器人”的工作流,用户的输入通常是一句话提问。
3.2 拆解任务步骤
将整体任务拆解成多个原子操作,比如:
- 接收用户输入
- 查询知识库
- 调用 LLM 推理
- 判断是否需要外部数据
- 整合结果输出
这一步类似传统编程中的“函数划分”,有助于提升复用性与逻辑清晰度。
3.3 模块化构建流程
根据任务拆分结果,选择合适的模块类型,并将它们按照逻辑顺序连接起来。例如:
[Input] → [Prompt 1:理解意图] → [条件判断:是否调用工具] → [Prompt 2 or Tool调用] → [输出]
3.4 合理使用变量和上下文
Dify 在每一步执行中都会更新上下文,用户可以使用 DSL 表达式访问任意历史节点的结果或变量,典型格式为:
{{ node_id.outputs.result }}
设计时应尽量避免重复计算,优先复用上下文中的已有信息。
3.5 设置容错与默认路径
为防止工作流中某些节点执行失败或模型返回空值,建议设计默认分支或 fallback 逻辑,保障流程稳健。
4 工作流DSL文件介绍与使用
Dify 支持使用 JSON 格式的 DSL 文件描述工作流结构,这一机制使得工作流可以通过代码方式导入、导出、复用与版本控制。
4.1 DSL 文件结构说明
工作流 DSL 文件的基本结构如下(部分字段):
{"nodes": [{"id": "input_1","type": "input","data": { "variable": "user_query" }},{"id": "prompt_1","type": "prompt","data": {"prompt_template": "请回答以下问题:{{ input_1.outputs.user_query }}","model": "gpt-4"}}],"connections": [{ "source": "input_1", "target": "prompt_1" }]
}
其中 nodes 表示节点列表,每个节点具有唯一 id 与 type 类型;connections 则表示流程图中的连接路径。
4.2 如何导出/导入工作流 DSL
用户可以在 Dify Web 控制台设计好流程图后,通过“导出DSL”按钮生成 JSON 文件;同样可以将已有 JSON 文件导入以还原流程结构。这使得团队协作、版本管理与代码自动化部署成为可能。
4.3 DSL 文件的进阶使用
在复杂应用场景中,用户可以手动编辑 DSL 文件,实现更灵活的流程控制,例如:
- 使用循环结构(未来版本支持)
- 动态绑定参数模板
- 嵌套子工作流(Subflow)
- 多语言支持(prompt_template 国际化)
5 实战案例:构建一个产品推荐工作流
假设我们需要构建一个基于用户描述进行产品推荐的工作流,其核心逻辑如下:
- 用户输入产品偏好描述
- 通过大模型理解用户需求
- 查询知识库中商品信息
- 匹配推荐结果
- 生成推荐理由并输出
对应模块设计:
Input:接收用户偏好描述Prompt 1:调用 GPT 模型分析需求Function:抽取关键词Tool:调用数据库插件检索商品Prompt 2:生成推荐理由Output:输出推荐内容
最终输出格式可为:
{"product": "智能手表","reason": "根据您的运动与健康管理偏好,推荐该产品。"
}
6 小结与展望
Dify 的工作流系统为 AI 应用开发者提供了一种模块化、低代码的任务编排方式,大大降低了构建复杂智能流程的门槛。无论是通用问答、知识库检索、RAG 增强还是外部工具调用,工作流都能通过灵活的组件组合高效实现。
未来,Dify 工作流还将支持更多高级能力,如流程模板、子流程调用、变量作用域控制、调试回放等功能,进一步提升开发体验与系统稳定性。
结语
在 AI 驱动的新时代,掌握 Dify 工作流的设计与实现,将为你的智能产品赋予前所未有的灵活性与智能化水平。希望本文能够为你揭示 Dify 工作流的核心机制与最佳实践,助力打造真正有价值的AI解决方案。