《Spring Boot 微服务架构下的高并发活动系统设计与实践》
Spring Boot 微服务架构下的高并发活动系统设计与实践
引言
在互联网产品中,会员营销活动是提升用户粘性、促进付费转化的核心手段。无论是“会员日秒杀”“限时拼团”还是“积分兑换”,活动系统都需要在短时间内承接海量用户请求——例如某司会员业务的“年度会员大促”活动,曾出现过**单日活动参与用户超100万、峰值QPS(每秒请求数)达8000+**的场景。
面对高并发挑战,传统单体架构常因“牵一发而动全身”的耦合问题导致系统崩溃;而微服务架构虽能解耦,但如何设计高可用、易扩展的活动系统,仍是技术团队的核心课题。
本文将结合会员营销活动平台的实战经验,从架构演进、缓存设计、异步处理、组件化拆分四大维度,详细拆解高并发活动系统的设计与优化过程,并附真实调优案例。
一、从单体到微服务:活动系统的架构演进
1.1 传统单体架构的痛点
早期会员活动系统采用单体架构(All-in-One),所有功能(活动创建、规则校验、库存扣减、奖励发放)集中在一个Spring Boot工程中。随着业务发展,问题逐渐暴露:
- 扩展性差:活动类型从3种增加到20+种(如秒杀、拼团、裂变),代码量膨胀至10万+行,新增活动需修改同一套逻辑,上线风险高。
- 高并发瓶颈:大促期间所有请求集中冲击单体服务,数据库连接池、线程池易被占满,曾出现“活动未开始,系统先崩溃”的事故。
- 维护成本高:活动规则(如“满299减50”“新用户额外赠100积分”)与业务逻辑强耦合,规则变更需全量回归测试,迭代效率低。
1.2 微服务架构的拆分策略
为解决上述问题,团队将活动系统拆分为**“活动中心”“规则引擎”“库存服务”“奖励服务”**四大微服务,通过Spring Cloud Alibaba实现服务治理,架构演进如图1所示:
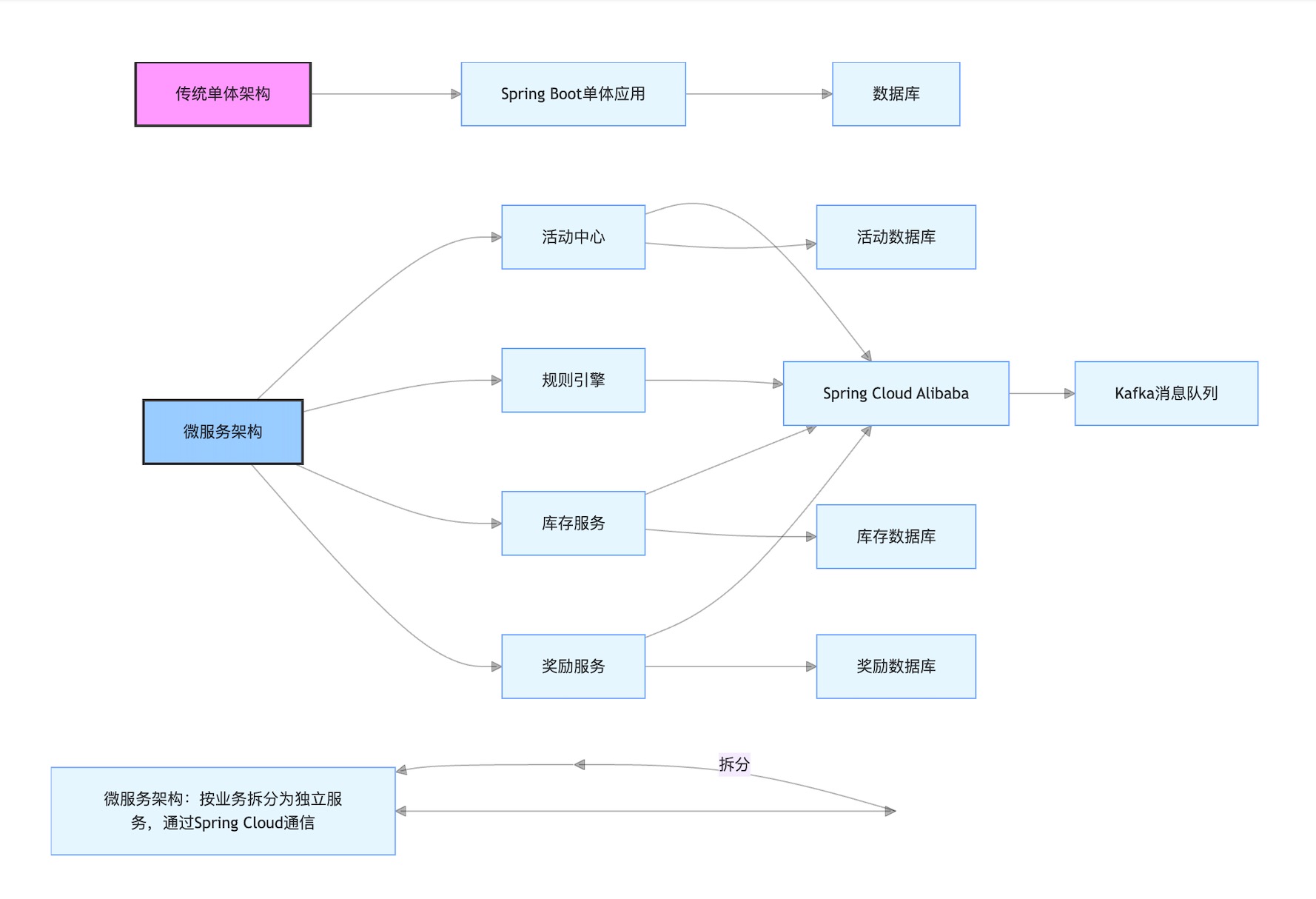
- 活动中心:负责活动的全生命周期管理(创建、上线、暂停、下线),提供活动信息查询接口(如“获取当前有效活动列表”)。
- 规则引擎:独立处理活动规则校验(如“用户是否满足新客条件”“商品是否在活动范围内”),支持规则动态配置(通过Apollo配置中心)。
- 库存服务:管理活动商品库存,提供“扣减库存”“回滚库存”接口,通过Redis分布式锁保证并发安全。
- 奖励服务:处理活动奖励发放(如积分、会员权益),通过Kafka消息队列实现异步发放,避免阻塞主流程。
1.3 微服务架构的优势
拆分后,活动系统的可维护性、扩展性、稳定性显著提升:
- 新增活动类型仅需在“活动中心”添加配置,规则逻辑通过“规则引擎”动态扩展,无需修改核心代码;
- 大促期间可针对“活动中心”“库存服务”单独扩容,避免资源浪费;
- 服务间通过HTTP/JSON或gRPC通信,故障隔离(如“奖励服务”宕机不影响活动参与主流程)。
二、Redis缓存:解决高并发下的热点数据问题
2.1 活动场景中的缓存需求
在会员活动中,**活动基础信息(如标题、时间、商品列表)和用户参与状态(如是否已领券、剩余次数)**是高频读取的热点数据。若直接查询数据库,会导致:
- 数据库QPS激增,响应时间从10ms延长至200ms+;
- 主从复制延迟加剧,可能出现“用户看到活动已开始,但数据库未同步”的不一致问题。
2.2 缓存设计的三大核心问题与解决方案
(1)缓存穿透:查询不存在的数据
场景:恶意用户伪造活动ID(如activity_id=-1),请求量过大时可能拖垮数据库。
解决方案:
- 布隆过滤器:在活动上线时,将所有有效
activity_id存入布隆过滤器。请求到达时,先检查ID是否存在于布隆过滤器中,不存在则直接返回“活动不存在”。 - 空值缓存:对不存在的ID,缓存一个
null值(设置短过期时间,如5分钟),避免重复查询数据库。
// 布隆过滤器初始化(Spring Boot配置)
@Bean
public BloomFilter<String> activityBloomFilter() {return BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()), 100000, 0.01); // 预计10万活动,误判率1%
}// 缓存查询逻辑
public Activity getActivity(Long activityId) {// 1. 布隆过滤器校验if (!activityBloomFilter.mightContain(activityId.toString())) {return null;}// 2. 查询Redis缓存Activity activity = redisTemplate.opsForValue().get("activity:" + activityId);if (activity == null) {// 3. 查询数据库activity = activityMapper.selectById(activityId);// 4. 空值缓存(防止穿透)if (activity == null) {redisTemplate.opsForValue().set("activity:" + activityId, "null", 5, TimeUnit.MINUTES);} else {redisTemplate.opsForValue().set("activity:" + activityId, activity, 1, TimeUnit.HOURS); // 正常缓存1小时}}return activity == "null" ? null : activity;
}
(2)缓存击穿:热点key过期
场景:某活动(如“年度会员秒杀”)的缓存过期后,海量请求同时涌入数据库,导致数据库压力骤增。
解决方案:
- 互斥锁(Redis Lock):缓存过期时,仅允许一个线程查询数据库并更新缓存,其他线程等待缓存更新后重新查询。
- 热点预加载:大促前手动将热点活动的缓存过期时间延长至活动结束后(如活动持续24小时,缓存设置为25小时)。
// 互斥锁实现缓存击穿防护
public Activity getHotActivity(Long activityId) {Activity activity = redisTemplate.opsForValue().get("activity:" + activityId);if (activity == null) {// 获取分布式锁(Redisson实现)RLock lock = redissonClient.getLock("lock:activity:" + activityId);try {if (lock.tryLock(10, 30, TimeUnit.SECONDS)) { // 最多等待10秒,锁30秒自动释放// 再次检查缓存(避免锁竞争时重复查询)activity = redisTemplate.opsForValue().get("activity:" + activityId);if (activity == null) {activity = activityMapper.selectById(activityId);redisTemplate.opsForValue().set("activity:" + activityId, activity, 1, TimeUnit.HOURS);}}} catch (InterruptedException e) {Thread.currentThread().interrupt();} finally {lock.unlock();}}return activity;
}
(3)缓存雪崩:大量key同时过期
场景:若所有活动缓存的过期时间设置为同一时刻(如凌晨0点),过期后请求会集中冲击数据库,导致系统崩溃。
解决方案:
- 随机过期时间:在基础过期时间(如1小时)上增加随机偏移(如0-30分钟),避免批量过期。
- 缓存集群高可用:使用Redis Cluster代替单实例,避免因节点宕机导致的缓存大面积失效。
三、Kafka消息队列:异步处理实现削峰填谷
3.1 活动场景中的异步需求
在活动参与主流程中,用户点击“参与活动”后,需完成:
- 校验活动状态(是否已开始);
- 校验用户资格(是否为会员);
- 扣减库存;
- 发放奖励(如积分、优惠券);
- 记录日志(用于数据统计)。
其中,扣减库存是核心操作(需实时响应),但发放奖励、记录日志可异步处理(用户无需等待)。若同步执行所有操作,请求耗时会从200ms延长至800ms+,严重影响用户体验。
3.2 Kafka的削峰填谷实践
团队引入Kafka作为消息中间件,将非核心操作通过消息队列异步处理,架构如图2所示:
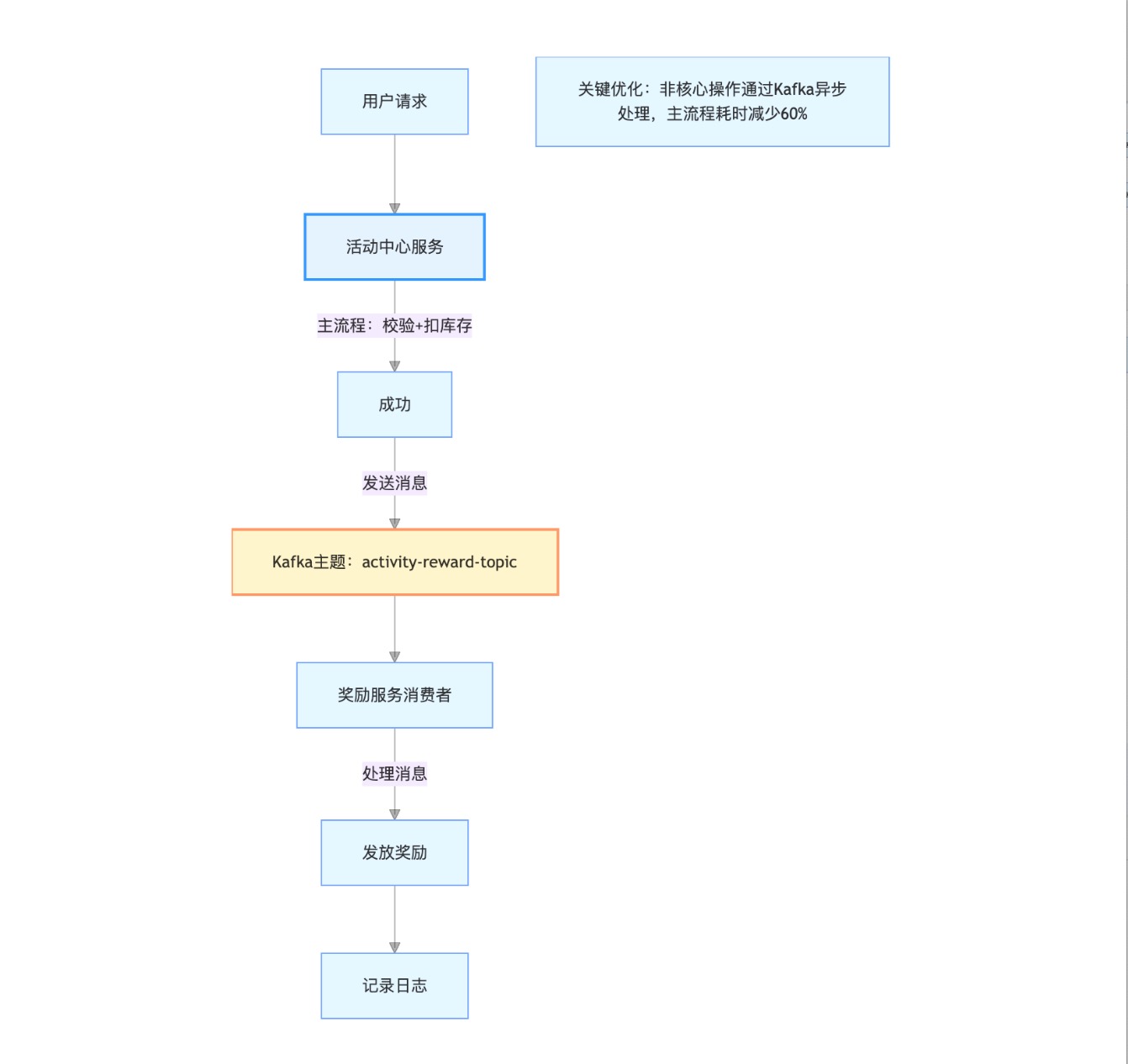
- 生产者(活动中心):用户参与活动后,主流程完成“校验+扣库存”,然后向Kafka发送一条“奖励发放”消息(包含用户ID、活动ID、奖励类型)。
- 消费者(奖励服务):监听Kafka主题
activity-reward-topic,按消费能力(如每秒处理2000条)逐条处理消息,完成奖励发放。
3.3 关键实现细节
(1)消息可靠性保障
- 生产者确认:设置
acks=all,确保消息写入Kafka集群所有副本后再返回成功; - 消费者幂等:通过数据库唯一索引(如
user_id+activity_id)避免重复发放奖励; - 死信队列:消费失败的消息自动转发至
dead-letter-topic,人工排查后重新处理。
(2)性能优化
- 批量消费:消费者配置
max.poll.records=500,每次拉取500条消息批量处理,减少网络IO; - 异步处理:消费者内部使用线程池(如
ThreadPoolExecutor)并行处理消息,提升吞吐量。
四、组件化拆分:活动引擎与规则引擎的解耦
4.1 为什么需要组件化?
早期活动逻辑高度耦合,新增“拼团活动”需修改“秒杀活动”的代码,测试成本极高。通过组件化拆分,可将通用逻辑抽象为引擎,具体活动类型通过“配置+扩展”实现。
4.2 活动引擎:流程控制的“骨架”
活动引擎负责定义活动执行的标准流程(如“初始化→校验→执行→收尾”),并通过模板方法模式预留扩展点。代码示例如下:
// 活动引擎接口
public interface ActivityEngine {/*** 执行活动主流程* @param context 活动上下文(包含用户、活动、商品等信息)*/ActivityResult execute(ActivityContext context);
}// 抽象活动引擎(模板方法模式)
public abstract class AbstractActivityEngine implements ActivityEngine {@Overridepublic ActivityResult execute(ActivityContext context) {// 1. 初始化:加载活动配置ActivityConfig config = loadConfig(context.getActivityId());// 2. 校验:用户资格、活动状态if (!validate(context, config)) {return ActivityResult.fail("校验失败");}// 3. 执行核心逻辑(由子类实现)boolean success = doExecute(context, config);// 4. 收尾:记录日志、发送通知afterExecute(context, success);return success ? ActivityResult.success() : ActivityResult.fail("执行失败");}protected abstract boolean doExecute(ActivityContext context, ActivityConfig config);
}// 秒杀活动引擎(继承抽象引擎)
@Component
public class SeckillActivityEngine extends AbstractActivityEngine {@Overrideprotected boolean doExecute(ActivityContext context, ActivityConfig config) {// 秒杀特有的扣库存逻辑return stockService.deductStock(context.getUserId(), context.getGoodsId(), config.getLimit());}
}
4.3 规则引擎:动态扩展的“大脑”
规则引擎用于处理活动中的复杂规则(如“新用户专享”“满3件打8折”),支持通过配置动态修改规则,无需重启服务。团队采用Drools规则引擎(也可自研简易版),核心流程如下:
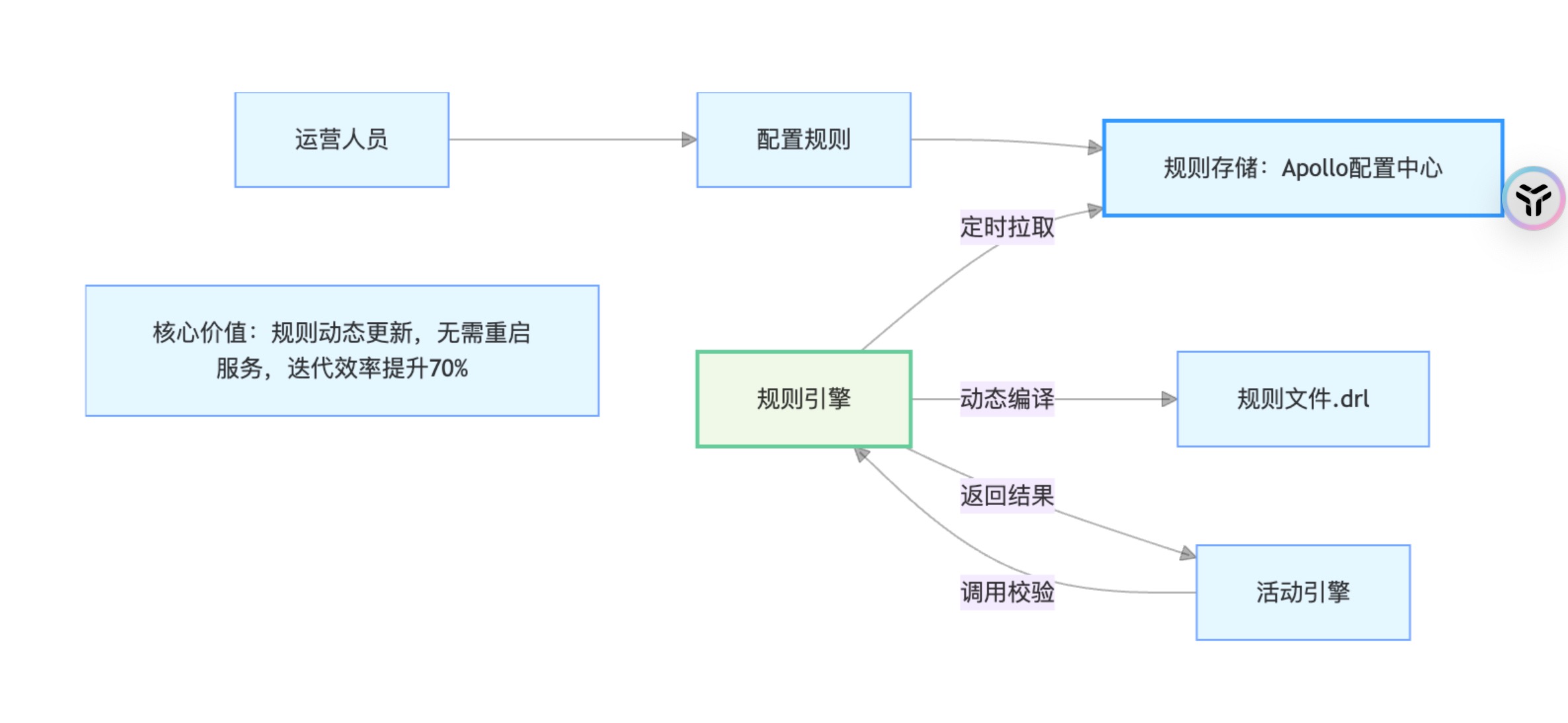
- 规则配置:运营人员通过后台界面配置规则(如“用户注册时间<30天”),保存为Drools规则文件(
.drl); - 规则加载:规则引擎定时从Apollo配置中心拉取最新规则文件,动态编译并加载;
- 规则执行:活动引擎调用规则引擎,传入用户信息(如注册时间、历史订单数),规则引擎返回校验结果(是否通过)。
五、实战案例:QPS从2000到8000的性能调优
5.1 问题定位(初始压测结果)
在活动系统上线前的压测中,发现QPS仅2000,且存在以下问题:
- 数据库CPU利用率达90%(慢查询多,如
SELECT * FROM activity WHERE status=1无索引); - Redis缓存命中率仅60%(部分热点活动未缓存);
- 活动引擎同步调用奖励发放接口(耗时300ms/次)。
5.2 优化措施与效果
(1)数据库优化
- 为
activity.status字段添加索引,查询时间从200ms降至10ms; - 将“活动参与记录”表按时间分库分表(如按月分表),单表数据量从1000万降至100万,查询性能提升50%。
(2)缓存优化
- 对大促活动提前预加载缓存(活动上线时自动写入Redis),缓存命中率提升至95%;
- 引入本地缓存Caffeine(存储高频活动的基础信息),减少Redis网络调用,响应时间从50ms降至10ms。
(3)异步化改造
- 将奖励发放、日志记录通过Kafka异步处理,主流程耗时从800ms降至200ms;
- 消费者线程池从
core=10扩展至core=50,Kafka消费吞吐量从1000条/秒提升至5000条/秒。
(4)服务扩容
- 活动中心从2台实例扩容至5台(4核8G→8核16G),Nginx负载均衡策略从“轮询”改为“加权轮询”(按机器性能分配流量);
- Redis集群从3节点扩展至6节点,主节点内存从8G升级至16G,避免缓存淘汰。
5.3 最终效果
优化后,活动系统在大促期间QPS稳定在8000+,响应时间<300ms,故障发生率从0.5%降至0.01%,支撑了百万级用户的活动参与需求。
总结
高并发活动系统的设计是“技术+业务”的双重挑战。通过微服务架构解耦、Redis缓存优化、Kafka异步处理、组件化引擎拆分,可有效提升系统的稳定性和扩展性。
在实际落地中,需注意:
- 数据一致性:缓存与数据库的更新需通过“先更新数据库,再删除缓存”或“消息队列异步同步”保证;
- 监控告警:对QPS、缓存命中率、Kafka堆积量等指标实时监控,提前发现瓶颈;
- 灰度发布:新活动类型上线时,先放量10%用户测试,避免全量故障。
希望本文的实践经验能为你的高并发系统设计提供参考,欢迎在评论区交流讨论!