商家平台AI智能搜索工程实践|RAG|向量检索增强
业务场景
商家在商家平台输入搜索词,需要根据平台内容生态返回合理的检索答案。
价值:提升用户体验
- 解决语义鸿沟痛点:通过Embedding模型理解深层语义,召回相关性提升40%+
- 复杂推理与信息整合:自动综合多个来源生成结论,生成结构化答案
工程架构
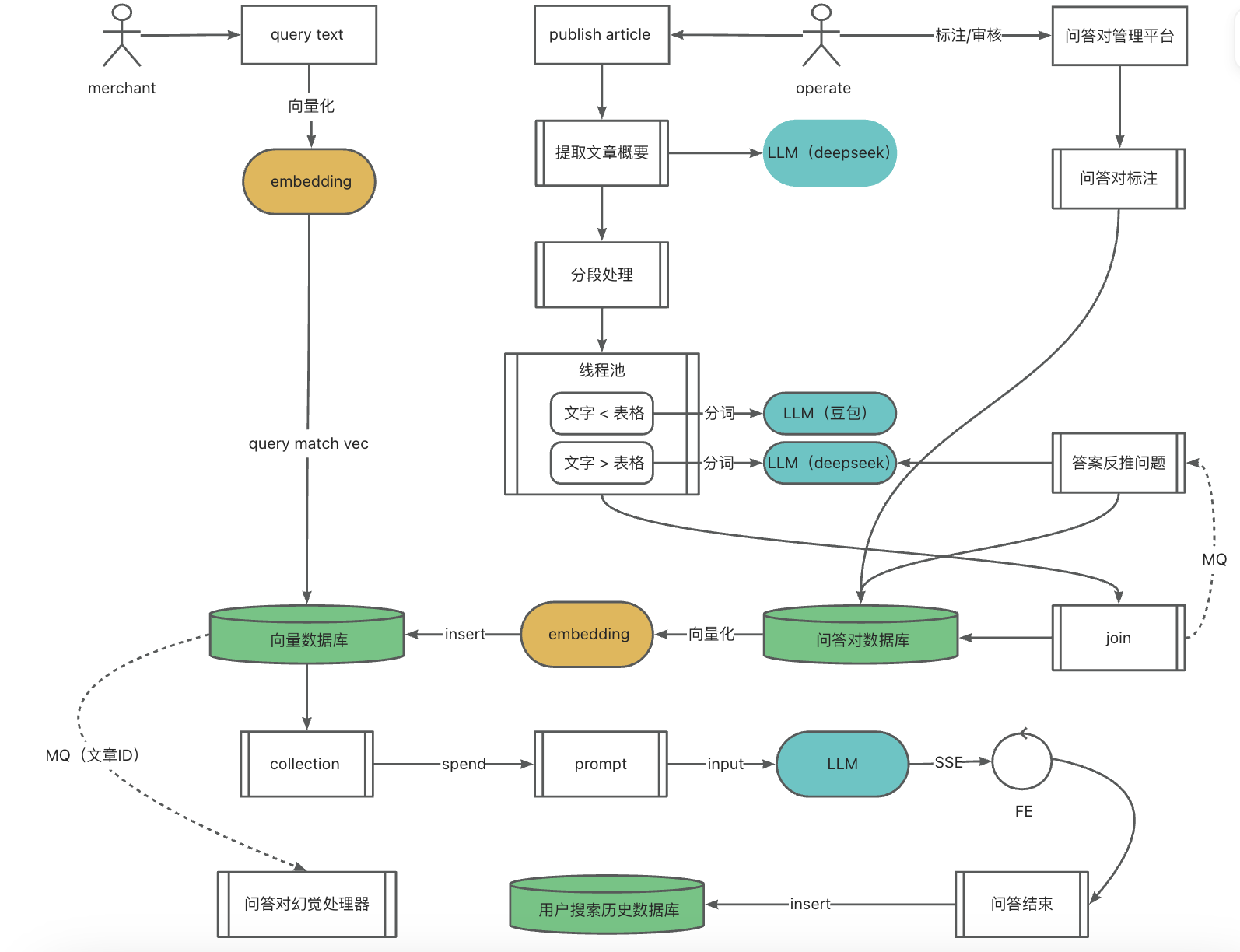
数据模型
问答对语义表:
主键|问题|答案|关联的文章ID|文章版本|预期态(符合、不符合、反馈审核中)|反馈原因|反馈人
问答对向量表:
主键|问答对语义ID|向量集合|权重|逻辑删除
用户搜索历史表: 主键|用户ID|搜索词|会话ID|搜索结果|问答对来源|是否符合预期|用户反馈意见
技术挑战
拆分问答对
运营同学发布电商平台规则或者文章时,需要将文章拆解问答对,然后将问答对mapping成向量,转储至向量数据库中。
难点
- 文章太长,LLM拆解过慢,甚至会超时,导致分词失败。
- 文章内容包括长文本和表格以及图片等,不同的LLM处理的效率和质量也不同。
- 针对文章进行分段处理后,会导致上下文语义终中断,导致分词质量降低,召回率降低。
解决方案
- 将文章进行分段处理,分段之后,通过线程池并发拆解各个文章段的问答对,提高处理效率。
- 分段之后,判断表格和文字的权重占比,表格大,优先使用doubao大模型,长文本优先使用deepseek大模型,做好容错和降级处理。
- 为了避免语义中断,事前可将文章的标题、概要通过LLM提取出来,一并交给大模型进行拆解问答对,降低语义中断的可能。
语义漂移
用户的搜索词可能会和问答对数据库中的数据存在表述差异,导致召回率降低。
事前:拆解问答对之后,通过答案反推可能的问题,一并存入问答对数据库和向量数据库。
事中:可以通过多轮问答,让LLM揣摩用户的语义,逐渐逼近问答对数据库中的数据。
事后:如果没有匹配到向量,或者生成的答案不符合预期,可人工或系统异步生成同义词或相近词。
大模型幻觉
通过RAG架构,很大程度解决掉了LLM幻觉问题,为了严格避免幻觉问题,在生成问答对的时候,可异步实时校验问答对和原文章的匹配程度,也可每天巡检,降低脏数据。
向量数据库如何优化
关于向量数据库索引的选择:HNSW(分层导航地图世界)。
调优技巧:优先固定M(如32),逐步增加efConstruction直到召回率达标
-
M(最大连接数) 控制节点邻居数,决定图的连通性 默认16-48 高召回需求(如医疗问答)选32+高维数据(>768维)需增至40+ ↑M → 精度↑、内存占用↑、构建时间↑
-
efConstruction(构建候选集) 控制索引质量,影响节点选择范围 范围200-2000: 百万级数据:ef=400,十亿级数据:ef=2000 ↑efC → 召回率↑、构建耗时指数级↑
-
m_L(层分配概率) 控制节点出现在高层的概率 经验值:1/ln(M),通常取0.62-0.75 ↓m_L → 搜索路径变长但内存↓
关于向量维度的选择:128维,通过维度设定和召回率来衡量。
存储数据结构:字符串(“0.1234,0.6543,0.7543…”),底层存储可mapping成int或者二进制,节省内存开销。
match:针对标量和向量的检索,为了避免向量范围太大而过滤掉标量条件,在语法树阶段,可调整标量和向量的处理顺序,提升召回率。
如何提升召回率
RAG全链路各个阶段提升召回率的措施
- 拆解问答对阶段:通过文章分段、上下文语义关联、答案反推问题、实时/定时巡检问答对是否符合语义
- 用户搜索阶段:多轮问答、数据集整合、用户反馈
- 数据标注阶段:通过用户反馈、运营巡检,标注错误问答对,进行分析
- 提示词阶段:通过业务演进进行提示词调优
提示词
事前:设定角色
事中:规划任务思维链、任务细节
事后:风控、校验、输出