【大模型】【推荐系统】LLM在推荐系统中的应用价值
文章目录
- A 论文出处
- B 背景
- B.1 背景介绍
- B.2 问题提出
- B.3 创新点
- B.4 两大推荐方法
- C 模型结构
- C.1 知识蒸馏(训练过程)
- C.2 轻量推理(部署过程)
- D 实验设计
- E 个人总结
A 论文出处
- 论文题目:SLMRec:Distilling Large Language Models into Small for Sequential Recommendation
- 发表情况:2025-ICLR
- 作者单位:蚂蚁集团、国外大学及研究院
B 背景
B.1 背景介绍
序列推荐任务旨在通过用户过往的交互数据,来预测用户可能与之互动的下一个行为,因此这类模型通过建模分析用户的行动序列,揭示更复杂的行为模式和时间动态。近期研究表明,将大语言模型引入推荐系统逐渐成为研究热门,无论是将序列推荐视为语言模型的语义建模,还是作为用户表征的一种方法,都使大语言模型对序列推荐任务产生了深远影响。但是,由于大模型的庞大,在现实生活中大部分平台上应用大模型显得低效且不切实际,如何平衡好大模型的规模和推荐系统的海量数据,成为了能否用大模型进行序列推荐的关键问题。
B.2 问题提出
(1)尽管大模型在预训练阶段并没有显式地对商品ID的语义进行学习,现阶段大模型的杰出表现来源于预训练知识的迁移能力?还是注意力机制的固有建模优势?
(2)现有大模型的参数量较大,如此巨大的模型是否适配海量数据场景的推荐任务?模型是否有进一步裁剪的可能性?
B.3 创新点
(1)论文重新评估大语言模型(LLM)在序列推荐中的必要性,并在大规模行业数据集上进行了一系列实验,研究了减少训练和推理阶段参数数量对整体性能的影响。通过实证结果,论文发现模型参数的增加并不总是带来一致的改进。
(2)基于论文实证研究的结果,论文提出了一种名为SLMREC的小语言模型,用于序列推荐,并通过采用了标准的知识蒸馏方法来对齐表示知识。此外,论文还设计了多种监督信号,以引导学生模型在其隐藏表示中获取任务感知的知识。
B.4 两大推荐方法
下面简要介绍一下传统的序列推荐方法和基于大模型的推荐方法的主要步骤
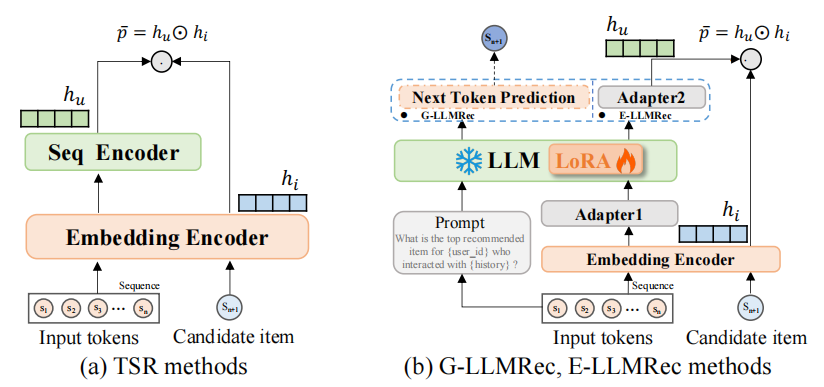
(1)传统序列推荐(TSR)
- 输入:用户历史交互的物品序列(如 [ i t e m 1 , i t e m 2 , . . . , i t e m t ] [item₁, item₂, ..., itemₜ] [item1,item2,...,itemt])。
- 流程:
- 嵌入编码(Embedding Encoder):
将每个物品ID转换为低维向量表示(Embedding)。 - 序列编码(Seq Encoder):
使用RNN/Transformer等模型,将物品序列编码为用户表征向量 h u h_u hu。 - 候选物品编码:
目标物品 i i i 通过独立Embedding层生成物品表征向量 h i h_i hi。 - 预测交互概率:
计算用户与物品的匹配度: p = h u ⊙ h i p = h_u ⊙ h_i p=hu⊙hi( ⊙ ⊙ ⊙ 表示内积或神经网络交互函数)。
- 嵌入编码(Embedding Encoder):
- 目标:直接预测用户对候选物品的偏好概率。
(2)基于大模型的推荐:G-LLMRec(生成式推荐)
- 输入:
自然语言提示(Prompt),例如:
“What is the top recommended item for user_123 who interacted with [itemA, itemB, …]?” - 流程:
- 文本化序列编码:
用户历史序列被转换为文本描述(如物品标题)。 - 大语言模型(LLM)推理:
将提示输入LLM(如GPT),直接生成推荐物品的文本标识(如物品名称或ID)。 - 适配器(Adapter1):
可选模块,用于对齐LLM表征与推荐任务(微调时引入)。
- 文本化序列编码:
- 特点:端到端生成式推荐,依赖LLM的推理能力直接输出结果。
(3)基于大模型的推荐:E-LLMRec(表征增强推荐)
- 输入:用户历史物品序列(ID或文本)。
- 流程:
- 文本嵌入编码:
物品ID/文本通过LLM的Embedding Encoder生成向量(如LLM的词嵌入层)。 - 序列编码(LLM适配):
使用Adapter2调整LLM输出,生成用户表征 h u h_u hu(保留序列结构信息)。 - 候选物品编码:
目标物品通过相同LLM Embedding层生成 h i h_i hi。 - 预测交互概率:
传统交互函数计算匹配度: p = h u ⊙ h i p = h_u ⊙ h_i p=hu⊙hi。
- 文本嵌入编码:
- 特点:利用LLM增强表征,但保留传统推荐器的交互预测层。
C 模型结构
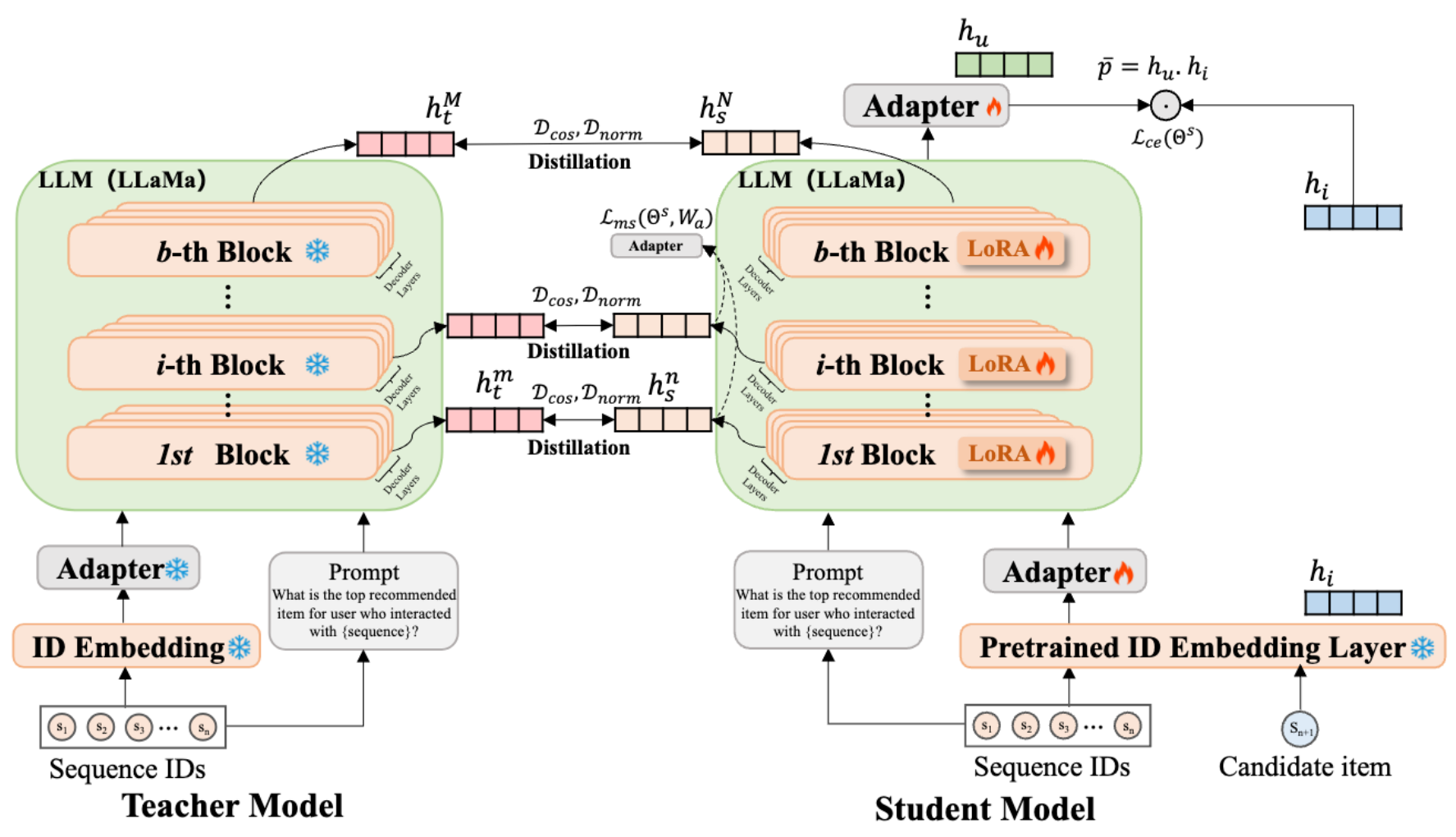
C.1 知识蒸馏(训练过程)
(1)教师模型生成软标签:
- 输入用户历史序列的物品ID,以及自定义的prompt模板。
- LLaMA输出推荐物品的概率分布(软标签),蕴含LLM的语义推理知识。
(2)学生模型学习语义对齐:
- 输入同一用户的物品ID序列,经ID嵌入层和Adapter编码为向量。
- 输出学生预测概率分布。
(3)多层次+多监督信号的知识蒸馏:
- 预测层蒸馏:为了调节教师模型与学生模型之间特征方向的对齐,采用基于余弦相似度的损失项,具体描述公式如下:
D cos ( Θ t , Θ s ) = 1 B ∑ k = 1 B h t ( k m ) ⋅ h s ( k n ) ∥ h t ( k m ) ∥ 2 ⋅ ∥ h s ( k n ) ∥ 2 \mathcal{D}_{\cos}(\Theta_t,\Theta_s)=\frac{1}{B}\sum_{k=1}^B\frac{\mathbf{h}_t^{(km)}\cdot\mathbf{h}_s^{(kn)}}{\|\mathbf{h}_t^{(km)}\|_2\cdot\|\mathbf{h}_s^{(kn)}\|_2} Dcos(Θt,Θs)=B1k=1∑B∥ht(km)∥2⋅∥hs(kn)∥2ht(km)⋅hs(kn)
同时也引入了一个简单的正则化项,旨在最小化教师模型与学生模型的隐藏表示之间的L2距离,该正则化项在数学上表述如下:
D norm ( Θ t , Θ s ) = 1 B ∑ k = 1 B ∥ h t ( k m ) − h s ( k n ) ∥ 2 2 \mathcal{D}_{\text{norm}}(\Theta_t,\Theta_s)=\frac{1}{B}\sum_{k=1}^B\|\mathbf{h}_t^{(km)}-\mathbf{h}_s^{(kn)}\|_2^2 Dnorm(Θt,Θs)=B1k=1∑B∥ht(km)−hs(kn)∥22
- 中间层蒸馏:采用了多种监督策略来引导学生模型吸收推荐相关知识的特定方面,具体描述公式如下:
L m s ( Θ s , W a ) = 1 B − 1 ∑ k = 1 B − 1 L c e ( y , p ^ t ( k m ) ) \mathcal{L}_{ms}(\Theta_{s}, W_{a}) = \frac{1}{B-1} \sum_{k=1}^{B-1} \mathcal{L}_{ce}(y, \hat{p}^{(km)}_{t}) Lms(Θs,Wa)=B−11k=1∑B−1Lce(y,p^t(km)) - 联合训练:综合上述蒸馏损失,用于训练学生模型的复合目标函数可表示为:
L t o t a l = L c e ( Θ s ) + λ 1 D cos ( Θ t , Θ s ) + λ 2 D n o r m ( Θ t , Θ s ) + λ 3 L m s ( Θ s , W a ) \mathcal{L}_{total} = \mathcal{L}_{ce}(\Theta_s) + \lambda_1 \mathcal{D}_{\cos}(\Theta_t, \Theta_s) + \lambda_2 \mathcal{D}_{norm}(\Theta_t, \Theta_s) + \lambda_3 \mathcal{L}_{ms}(\Theta_s, W_a) Ltotal=Lce(Θs)+λ1Dcos(Θt,Θs)+λ2Dnorm(Θt,Θs)+λ3Lms(Θs,Wa)
C.2 轻量推理(部署过程)
(1)学生模型独立接收物品ID序列,经Adapter增强的编码器生成用户表征。
(2)计算用户表征与候选物品向量的内积( p = h u ⊙ h i p = h_u ⊙ h_i p=hu⊙hi),输出推荐得分。
(3)部署优势:学生模型仅保留轻量Adapter和ID嵌入层,参数量显著低于LLM。
D 实验设计
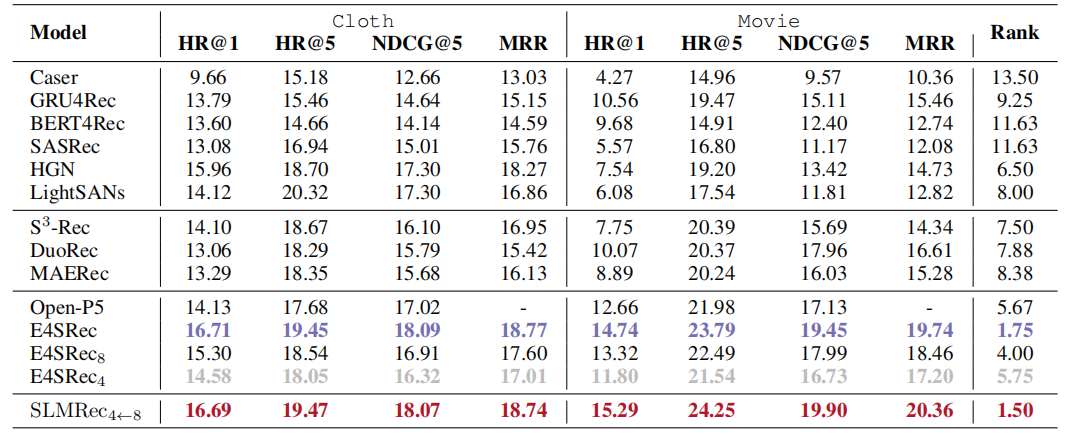
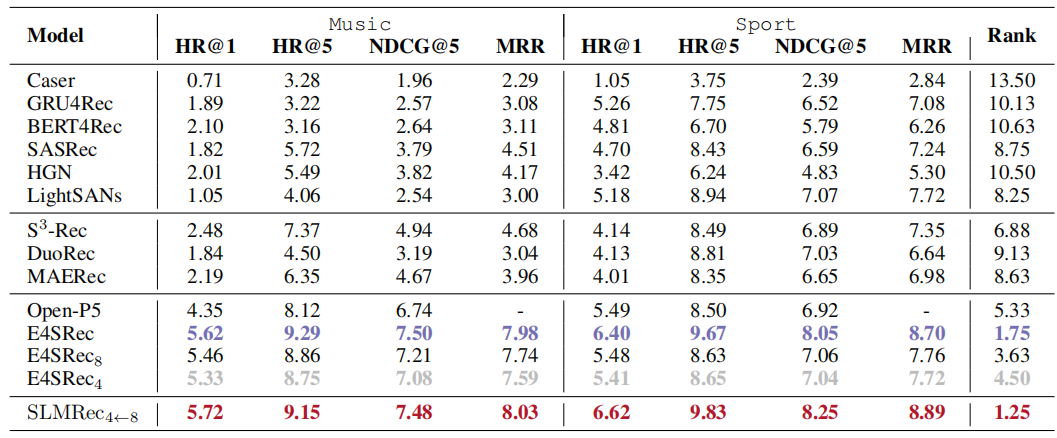
论文提出的SLMRec框架在多个基准数据集上实现突破:在训练效率上,相比原始LLMRec,训练速度提升6.6倍(NVIDIA A100);在推理性能上,服务响应速度提升8.0倍;在模型压缩上,参数量减少87%的同时,在Amazon数据集上略有提升。具体实验结果如下所示:

E 个人总结
(1)本文证明了大模型在推荐系统中的应用价值,同时通过知识蒸馏的方式找到了用大模型进行推荐的新角度,这种对大模型进行多监督信号的蒸馏学习值得学习。
(2)学生模型目前无法通过少量样本学习来适应新场景,当面对新的数据集或平台上的新流量日志时,模型需要从整个数据集中重新训练。未来可以将增量学习技术整合到基于LLM的推荐系统中,以增强模型的迁移能力。