【论文阅读】YOLOv8在单目下视多车目标检测中的应用
Application of YOLOv8 in monocular downward multiple Car Target detection
原文真离谱,文章都不全还发上来
引言
自动驾驶技术是21世纪最重要的技术发展之一,有望彻底改变交通安全和效率。任何自动驾驶系统的核心都依赖于通过精确物体检测来感知和理解其环境的关键能力。佐治亚理工学院吕诗杰的这篇论文通过提出对YOLOv8物体检测框架的增强,解决了自动驾驶计算机视觉中的基本挑战。
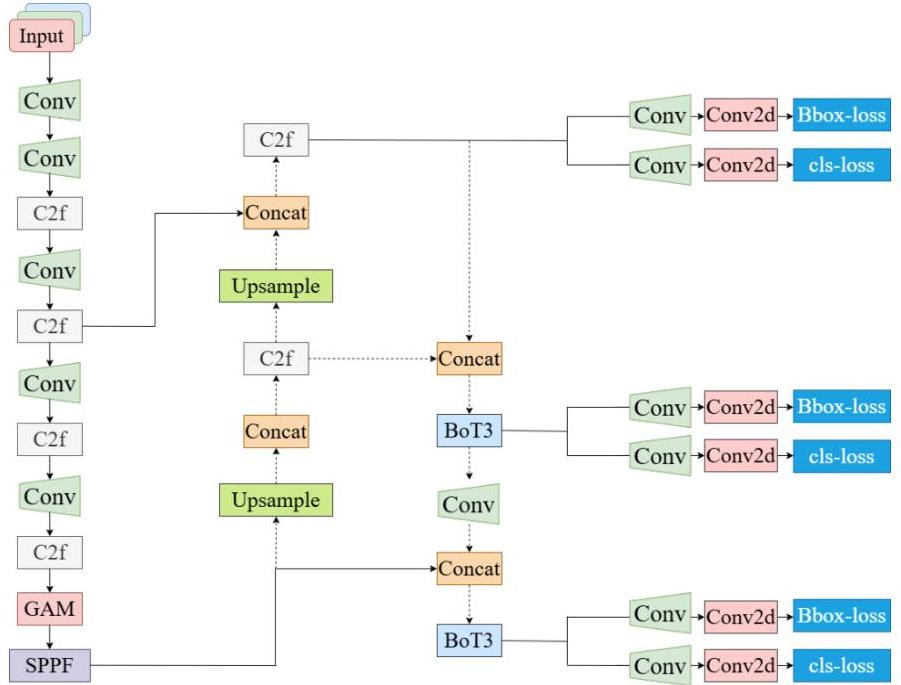
图1:改进后的YOLOv8架构概述,展示了增强的骨干网络、颈部网络和检测头组件
该研究特别针对多尺度、小型和远距离物体的检测——这些挑战对于像中国大学生方程式汽车大赛(FSAC)这样的自动驾驶竞赛尤为重要,因为精确快速的目标识别对于安全导航和竞争表现至关重要。
研究背景与动机
当前的自动驾驶系统依赖于各种传感器技术,包括雷达、摄像头、激光雷达和超声波传感器。然而,每种技术都存在影响实际性能的明显局限性:
- 雷达系统在恶劣天气条件和反光表面上精度下降
- 基于摄像头的系统极易受光照条件和天气变化的影响,尽管它们提供了丰富的视觉信息
- 高性能传感器如激光雷达成本高昂,限制了其广泛应用
- 分辨率限制尤其影响小型或远距离物体的检测
该研究通过专注于改进基于摄像头的物体检测来解决这些挑战,这提供了一种更具成本效益的解决方案,同时保持了高性能。YOLO(You Only Look Once)系列模型特别适合此应用,因为它们在速度和精度之间取得了卓越的平衡,使其成为实时自动驾驶应用的理想选择。
方法论概述
研究方法的核心是通过三项主要的架构改进来增强YOLOv8框架,这些改进旨在解决多尺度物体检测中的特定挑战:
- 骨干网络增强:通过不同分支块(DBB)集成结构重参数化技术
- 颈部结构改进:实现双向金字塔网络模型
- 管道优化:开发新的检测管道结构
这些修改协同作用,在保持计算效率以实现实时应用的同时,提高了网络检测不同尺度物体的能力。
架构改进
C2f-DBB模块集成
第一个主要增强是在骨干网络中引入了不同分支块(DBB)。DBB方法通过集成多个分支来解决多尺度特征提取的挑战,这些分支专注于输入图像的不同尺度和语义方面。
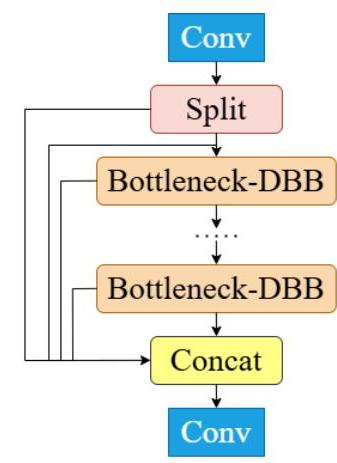
图2:C2f-DBB模块结构,显示了分割、瓶颈-DBB块和拼接操作
DBB模块与结构重参数化技术相结合,使得网络在训练期间能够保持多个分支以增强特征学习,然后在推理时将其融合为更简单的结构以提高效率。这种方法提供了:
- 增强的多尺度特征提取能力
- 改进对小型和远距离目标的检测
- 推理时保持计算效率
双向金字塔网络
第二个改进是用双向金字塔结构取代了原有的单向路径聚合特征金字塔网络(PAFPN)。原有的PAFPN的单向性限制了多尺度特征的有效整合,特别是影响了不同尺度目标的性能。
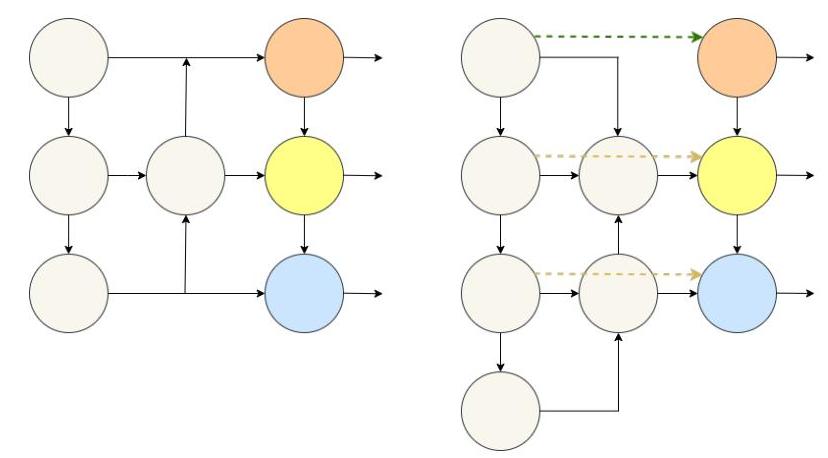
图3:单向(左)与双向(右)金字塔网络结构对比,展示了双向方法中增强的信息流
双向设计实现了:
- 信息在自上而下和自下而上两个方向流动
- 更全面的跨尺度特征融合
- 增强了多尺度目标检测的性能
- 提高了小型和远距离目标识别的准确性
注意力机制集成
本研究还引入了注意力机制,以进一步增强特征表示并聚焦于相关的图像区域。注意力模块帮助网络优先处理重要特征,同时抑制噪声,从而有助于更准确的目标检测。
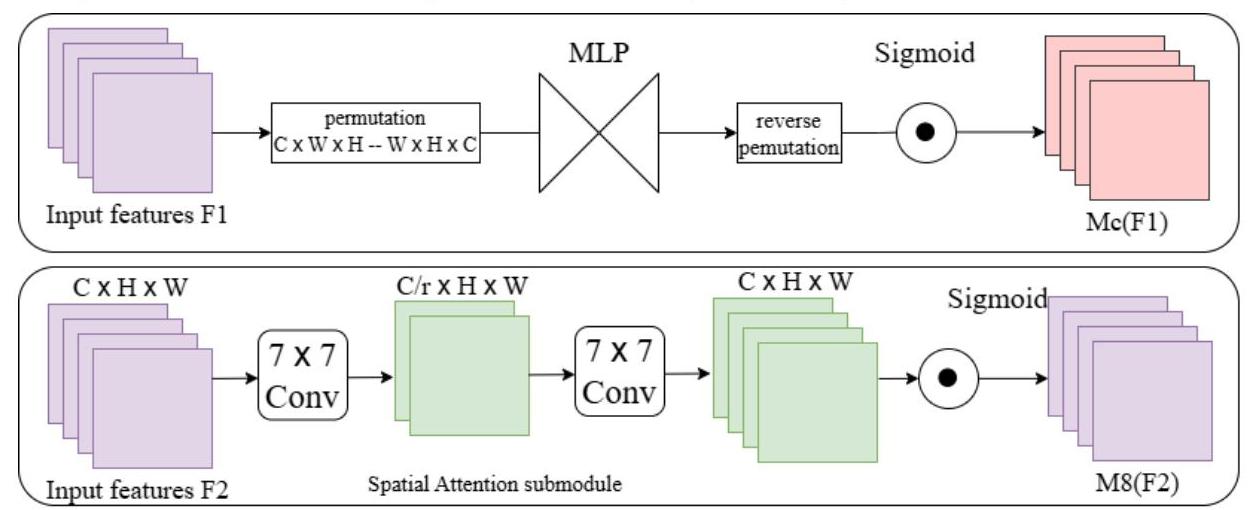
图4:注意力机制的结构,展示了通道和空间注意力组件,以增强特征表示
实验设置与评估
实验评估使用精心选择的数据集和标准化指标进行,以确保对所提出的改进进行全面评估。
数据集
选择了两个专门的数据集进行评估:
- SODA-D (Small Object Detection in Aerial Images - Drone):专门用于无人机航拍图像中的小目标检测,提供了与自动驾驶挑战相关的多种类别
- VisDrone:一个用于无人机视频分析的大规模数据集,包含来自全球不同城市在各种环境条件下的航拍画面,面临的重大挑战包括遮挡和主要为小型目标
训练配置
- 图像分辨率:1280×1280 像素
- 训练周期:100
- 优化器:SGD,批处理大小为 16
- 内存容量:64GB
- 评估指标:精确率 (P)、召回率 (R)、mAP@0.5、mAP@0.5:0.95、GFLOPS、参数和 FPS
结果与性能分析
实验结果表明,在两个数据集上目标检测性能均显著提高,验证了所提出的架构改进的有效性。
定量性能
SODA-D 数据库结果:
- 基线 YOLOv8:mAP@0.5 为 61.8%,mAP@0.5:0.95 为 36.8%
- 改进模型:mAP@0.5 为 65.2%,mAP@0.5:0.95 为 38.3%
- 改进:mAP@0.5 增加了 3.4%,mAP@0.5:0.95 增加了 1.5%
- 精确率从 70.1% 提高到 72.5%
- 召回率从 56.1% 提高到 58.9%
VisDrone 数据库结果:
- 基线 YOLOv8:mAP@0.5 为 30.5%,mAP@0.5:0.95 为 16.7%
- 改进模型:mAP@0.5 为 34.5%,mAP@0.5:0.95 为 16.6%
- 改进:mAP@0.5 增加了 4.0%
- 精确率从 42.0% 提高到 44.5%
- 召回率从 31.7% 提高到 33.9%
定性分析
视觉比较表明,增强模型取得了实际的改进,显示出更准确的目标定位和更高的检测率,特别是对于较小和更远的目标。

图5:检测结果的视觉比较,显示增强型YOLOv8模型相较于基线模型在准确性和精度方面的提升。
视觉证据支持了定量发现,表明:
- 跨各种物体尺寸的更高检测精度
- 更精确的边界框定位
- 在小物体或远距离物体等挑战性场景中性能提升
意义与影响
本研究通过以下几个关键领域,对自动驾驶技术和计算机视觉应用的进步做出了重大贡献:
安全性与可靠性提升
改进的物体检测能力直接转化为自动驾驶车辆更高的安全性,具体表现为:
- 更准确地识别障碍物、行人和其他车辆
- 更好的碰撞避免和风险缓解
- 改进路径规划和导航的决策
实际应用
对中国大学生方程式智能汽车大赛 (FSAC) 比赛要求的具体关注,展示了在快速和准确检测至关重要的高风险场景中的实际适用性。这些改进使系统特别适合竞技性自动驾驶平台。
成本效益
通过增强基于摄像头的物体检测系统,这项工作有助于实现更具成本效益的自动驾驶汽车开发,与激光雷达等昂贵的传感器解决方案相比,这可能使自动驾驶技术更易于大规模生产。
技术进步
本研究通过以下方式推动了实时物体检测的最新技术水平:
- 成功解决了多尺度检测挑战
- 提高了小物体的检测能力
- 保持了实时应用的计算效率
- 为YOLO架构的进一步增强提供了框架
结论
本研究对YOLOv8物体检测框架进行了全面增强,专门解决了自动驾驶应用中的关键挑战。通过集成结构重参数化技术、双向金字塔网络和优化后的管道结构,所提出的系统在检测多尺度、小型和远距离物体方面取得了显著改进。
实验结果表明,在挑战性数据集上,性能持续提升,SODA-D和VisDrone数据集上的mAP@0.5分数分别提升了3.4%和4.0%。这些改进虽然是渐进的,但代表着迈向更可靠、更安全的自动驾驶系统的有意义的进展。
这项工作专注于实际应用,特别是在竞技性自动驾驶场景中,突出了其在实际部署挑战中的相关性。通过在成熟的YOLOv8框架上进行构建,而不是开发全新的架构,本研究为现有自动驾驶车辆开发管道中的实际实施和可扩展性提供了途径。
未来的工作可以探索进一步的架构改进、与其他传感器模式的集成以及在其他真实世界场景中的验证,以继续提升基于视觉的自动驾驶系统的能力。