从碳基羊驼到硅基LLaMA:开源大模型家族的生物隐喻与技术进化全景
在人工智能的广袤版图上,一场从生物学羊驼到数字智能体的奇妙转变正在上演。Meta推出的LLaMA(Large Language Model Meta AI)系列模型,不仅名字源自美洲驼(llama),更以其开源特性和强大性能,引领了开源大模型社区的“驼类大爆发”。本文将全面梳理LLaMA家族的进化谱系,从生物学驼类的分类学基础到硅基LLaMA的技术发展脉络,系统分析各类微调变体的技术特点与应用场景,揭示这场从碳基生物到硅基智能的华丽蜕变如何重塑AI技术生态(扩展阅读:哪些魔法带来了 DeepSeek 的一夜爆火?MTP、MoE还是 GRPO?-CSDN博客)。
引言:驼类命名的AI革命
生物学中的驼科动物(Camelidae)是一个古老而独特的哺乳动物家族,主要分为两个族:骆驼族(Camelini)和美洲驼族(Lamini)。骆驼族包括我们熟悉的双峰驼(Bactrian camel)、野生双峰驼(Wild Bactrian camel)和单峰驼(Dromedary);而美洲驼族则包含大羊驼(Llama)、羊驼(Alpaca)、原驼(Guanaco)和小羊驼(Vicuna)。这些生物驼类在形态、习性和栖息环境上各具特色,却共享着相似的基因基础。
2023年初,当Meta发布LLaMA系列基础模型时,可能未曾预料到它会引发开源AI社区的“驼类命名狂潮”。斯坦福团队迅速基于LLaMA-7B微调出Alpaca(羊驼),随后Guanaco(原驼)、Vicuna(小羊驼)等变体相继问世,甚至出现了Dromedary(单峰骆驼)和“华驼”等创意命名。这场命名狂欢背后,反映的是开源社区对LLaMA系列的高度认可与热情参与。
硅基LLaMA家族的发展轨迹与生物学驼类惊人地相似。2023年2月,Meta发布LLaMA开源大语言模型,如同驼类家族的“始祖物种”,迅速衍生出Alpaca、Vicuna、Guanaco等一系列变体,每种变体都针对特定环境(应用场景)进行了“适应性进化”。这种命名并非偶然——正如生物学驼类适应了从安第斯山脉到戈壁沙漠的多样环境,LLaMA系列模型也通过各类微调技术“进化”出适应不同任务和领域的专用模型。
生物学驼类与硅基LLaMA家族的类比不仅停留在名字层面。正如不同驼类适应了安第斯山脉、蒙古高原等多样环境,LLaMA系列模型也通过各类微调技术“进化”出适应不同领域和任务的“亚种”。从最初的7B参数基础模型,到支持32k上下文的LLaMA 2 Long,再到各类垂直领域专用模型,LLaMA家族展示了惊人的适应性和可塑性。
本部分将从生物学驼类的分类学特征出发,建立与硅基LLaMA家族的对应关系,为后续技术分析提供生动的生物学隐喻基础。
碳基驼类:生物学分类与特性

骆驼族:沙漠生存专家
骆驼族包含现存三种大型驼类动物,均以出色的沙漠适应能力著称:
-
双峰驼(Bactrian camel):分布于中亚地区,最显著特征是背部有两个脂肪储备峰。作为骆驼族中体型最大的成员,双峰驼能负重170-270公斤,在缺水条件下生存数周,堪称“沙漠之舟”的典范。
-
野生双峰驼(Wild Bactrian camel):双峰驼的野生近亲,栖息于中国西北和蒙古的戈壁地区。比家养双峰驼更瘦小敏捷,现存数量不足1000峰,被列为极危物种。
-
单峰驼(Dromedary):背部单一脂肪峰的驼类,主要分布于中东和北非。比双峰驼更高但体重较轻,以耐热性和长途跋涉能力闻名,是撒哈拉沙漠地区重要的运输工具。
这些骆驼族成员的共同特点是极强的环境适应力,能够在资源稀缺的恶劣条件下生存并发挥作用——这一特性与基础LLaMA模型的定位不谋而合,后者同样被设计为在各种计算环境下都能高效运行的“基础工作驼”。
美洲驼族:安第斯山的多样化适应
美洲驼族包含四个主要物种,体型较小但分化更为多样:
-
大羊驼(Llama):美洲驼族中体型最大的成员,肩高可达1.8米,体重130-200公斤。早在印加帝国时期就被驯化为驮畜,性格相对独立,适合高海拔运输工作。其学名Llama直接启发了Meta的LLaMA模型命名。
-
羊驼(Alpaca):比大羊驼小一号,以优质绒毛著称。高度驯化,性情温顺,群体性强。斯坦福大学的研究团队将首个LLaMA微调模型命名为Alpaca,正是看中其“精致实用”的特性。
-
原驼(Guanaco):野生美洲驼,分布广泛但数量稀少。体型介于大羊驼和羊驼之间,适应力强。在LLaMA生态中,Guanaco代表了早期尝试多语言支持的微调模型。
-
小羊驼(Vicuna):美洲驼族中最精致稀有的成员,绒毛极为细腻。对应到AI领域,Vicuna-13B以其高效性能和对话质量成为“硅基驼类”中的明星。
| 生物学驼类 | 主要特征 | 对应LLaMA模型 | 模型特点 |
|---|---|---|---|
| 双峰驼 | 大型、耐力强、双峰 | LLaMA 65B | 基础大模型,计算负重能力强 |
| 单峰驼 | 速度快、适应炎热 | LLaMA 2 Long | 长上下文处理能力强 |
| 大羊驼(Llama) | 基础驮畜、多功能 | 原始LLaMA | 基础开源模型 |
| 羊驼(Alpaca) | 绒毛优质、驯化程度高 | Alpaca | 早期指令微调模型 |
| 小羊驼(Vicuna) | 体型小、绒毛珍贵 | Vicuna-13B | 高效对话模型 |
| 原驼(Guanaco) | 野生、适应力强 | Guanaco | 多语言支持模型 |
值得注意的是,生物学驼类的分类历史上曾有过混淆——羊驼(Alpaca)最初被归类于羊驼属(Lama),2001年的基因研究才确认其更接近小羊驼属(Vicugna)。类似地,硅基LLaMA家族的许多模型在初期也经历了快速迭代和重新定位,反映了技术进化过程中的试错与调整。
硅基LLaMA家族的崛起与分化
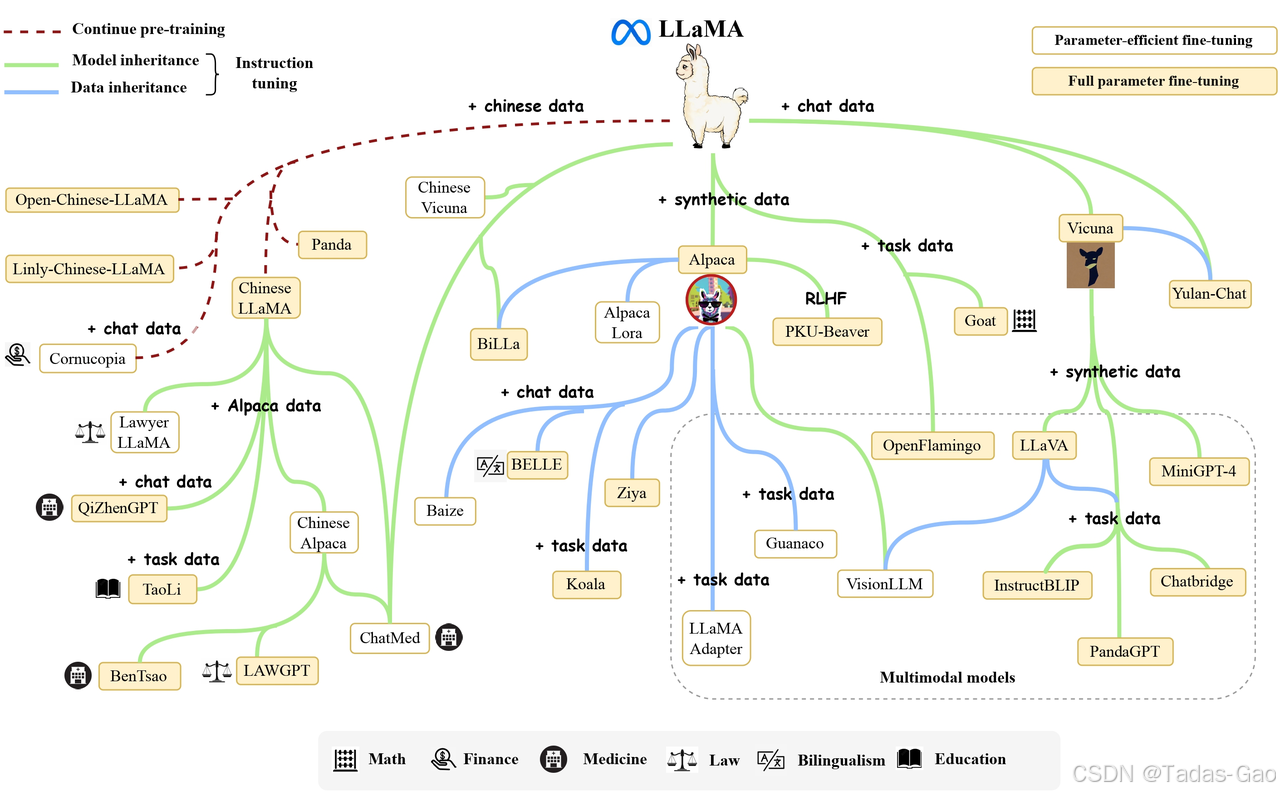
基础物种:LLaMA的发布与特性
2023年2月24日,Meta发布了LLaMA(Large Language Model Meta AI)系列基础模型,参数规模包括7B、13B、33B和65B四个版本。虽然LLaMA最大的65B参数版本仍小于OpenAI的GPT-3(175B),但其通过三项关键技术创新实现了更高效的性能:
-
Pre-normalization:在Transformer模块的残差连接前进行层归一化,提升训练稳定性;
-
SwiGLU激活函数:替代传统ReLU,增强非线性表达能力;
-
旋转位置编码(RoPE):通过旋转矩阵实现位置信息的高效编码。
这些设计使LLaMA如同驼类祖先一样,具备了在“资源稀缺环境”(有限计算资源)下高效运作的先天优势。特别值得一提的是RoPE技术,它后来成为扩展模型上下文窗口的关键——只需调整"基频"超参数,就能使LLaMA 2 Long支持高达32k的上下文长度,性能超越ChatGPT和Claude 2。
第一波分化:从Alpaca到Vicuna

LLaMA开源后,研究社区迅速展开了微调实验,形成了硅基驼类家族的第一次大规模分化:
Alpaca(羊驼):2023年3月13日,斯坦福大学CRFM团队发布了Alpaca-7B,这是首个基于LLaMA微调的重要变体。仅用52K指令数据微调,成本不到600美元,性能却接近GPT-3.5。Alpaca如同其生物学对应物——被高度驯化的羊驼,展示了LLaMA模型经过“驯化”(微调)后的实用价值。
Vicuna(小羊驼):2023年3月底,由加州大学伯克利分校、卡耐基梅隆大学等多校团队联合推出的Vicuna-13B成为开源社区的焦点。通过在ShareGPT收集的70K用户对话数据上微调,仅花费300美元训练成本,却达到了ChatGPT 90%的性能。GPT-4评估显示,Vicuna生成的回答比Alpaca更详细、结构更合理,在45%的情况下甚至被认为优于ChatGPT。Vicuna得名于美洲驼族中最精致的小羊驼,反映了其在硅基驼类家族中的高效与优质特性。
Guanaco(原驼):紧随Alpaca之后,Guanaco模型于2023年3月16日发布,重点增强了多语言支持能力。如同野生原驼比驯化驼类更具适应力,Guanaco模型也展现了在多样化语言环境中的灵活性。
| 模型 | 发布时间 | 基础模型 | 微调数据 | 主要特点 | 生物对应物 |
|---|---|---|---|---|---|
| LLaMA | 2023.02 | - | - | 开源基础模型 | 大羊驼 |
| Alpaca | 2023.03 | LLaMA-7B | 52K指令数据 | 低成本指令微调 | 羊驼 |
| Vicuna | 2023.03 | LLaMA-13B | 70K对话数据 | 高质量对话 | 小羊驼 |
| Guanaco | 2023.03 | LLaMA | 多语言数据 | 多语言支持 | 原驼 |
这一阶段的发展印证了“驼类命名法”的核心理念:不同微调方法产生的模型变体,如同驼类物种适应不同生态环境一样,各自擅长特定的任务场景。值得注意的是,这些早期变体主要采用全参数微调方法,即调整模型的所有参数以适应新任务,相当于对模型进行“全面进化”。
技术分水岭:PEFT方法的兴起
随着模型规模扩大,全参数微调的高计算成本促使参数高效微调技术(Parameter-Efficient Fine-Tuning,PEFT)快速发展,形成了硅基驼类进化的新机制:
LoRA(Low-Rank Adaptation):在原始权重旁添加低秩矩阵进行微调,大幅降低训练成本。Alpaca-LoRA项目仅用单张RTX 4090即可微调LLaMA-7B。
QLoRA:结合4-bit量化的LoRA变体,使LLaMA微调可在消费级显卡完成。如RedPajama-3B甚至能在手机端进行轻量微调。
Adapter:在Transformer模块中插入小型瓶颈结构,适合多任务学习。Chinese-LLaMA等模型采用了这类技术增强中文能力。
PEFT技术如同“定向进化”,仅调整模型关键部分而非整体重构,使LLaMA家族能够快速适应各种细分领域,催生了后续爆发式的模型分化。
领域专用LLaMA变体的爆发式增长
随着PEFT技术的成熟,LLaMA家族开始在各个垂直领域快速分化,形成了丰富的“适应性辐射”现象。这些领域专用模型如同驼类物种适应不同地理环境,针对特定任务场景进行了深度优化。
语言与区域适应变体
Chinese-LLaMA & Chinese-Vicuna:针对LLaMA原生中文支持薄弱的问题(训练数据中仅占0.13%),中文社区迅速推出了多个本地化版本。Chinese-LLaMA通过扩充中文词表和加入中文数据预训练显著提升中文能力;Chinese-Vicuna则基于LoRA方案支持个性化指令微调。这些模型如同驼类适应新大陆,解决了“语言迁移”挑战。
Ziya(紫鸭):深度优化中文处理的LLaMA变体,在通用中文任务上表现优异。名称取自“紫气东来”,寓意中文AI的发展前景。
Yulan-Chat(玉兰):专注于中文对话生成的LLaMA微调模型,如同温顺的驯化驼类,擅长与人进行流畅交流。
专业领域变体
Lawyer LLaMA & LAWGPT:法律领域专用模型,能够处理法律条文分析、合同审查等专业任务。如同驼类在特定文化中的专业角色(如运输或绒毛生产),这些模型在法律垂直领域表现出色。
ChatMed & BenTsao(本草):医学领域模型,其中BenTsao名称源自经典医书《本草纲目》,专门针对中医药知识进行优化。如同驼奶在传统医学中的应用,这些模型将古老智慧与现代AI结合。
聚宝盆(Cornucopia):金融领域专用LLaMA,效果媲美专业金融模型“度小满轩辕”。通过12M金融指令数据微调,在投资建议、理财问答等任务上超越通用模型。
QiZhenGPT(启真):学术研究辅助模型,名称取自浙江大学“求是创新”精神,擅长文献分析、论文写作支持等学术任务。
| 模型名称 | 领域 | 基础模型 | 微调方法 | 生物类比 |
|---|---|---|---|---|
| Chinese-LLaMA | 中文处理 | LLaMA | 全参数+词表扩展 | 亚洲适应驼 |
| Ziya | 中文增强 | LLaMA | 持续预训练 | 改良品种驼 |
| Lawyer LLA MA | 法律 | LLaMA | LoRA | 法律“工作驼” |
| ChatMed | 医疗 | LLaMA | Adapter | 医疗“辅助驼” |
| Cornucopia | 金融 | LLaMA-7B | LoRA | 金融“产绒驼” |
| QiZhenGPT | 学术 | LLaMA | 指令微调 | 研究“驮运驼” |
多模态与特殊能力变体
LLaMA家族的进化不仅限于文本领域,还扩展到了多模态交互,如同驼类发展出适应不同环境的感官能力:
LLaVA & Chinese-LLaVA:视觉-语言多模态模型,能够理解和生成与图像相关的内容。Chinese-LLaVA额外支持中英文双语视觉对话。
LLaSM:首个支持中英文语音-文本多模态对话的开源模型,通过Whisper编码语音输入,极大改善了传统文本交互体验。
VisionLLM:通用视觉-语言模型,将LLaMA的文本理解能力与视觉感知结合,支持复杂的跨模态推理。
PandaGPT:结合视觉、听觉和语言理解的多模态模型,如同驼类发达的感官系统,能同时处理多种输入形式。
这些多模态变体代表了LLaMA家族最前沿的进化方向,使大模型能够像生物学驼类感知多样环境一样,理解和生成多种模态的内容。
技术进化树:LLaMA家族的系统分类
基于上述发展脉络,我们可以构建LLaMA家族的“技术进化树”,清晰展示各类变体的亲缘关系和分化路径:
基础模型层
-
LLaMA:原始“始祖物种”,包含7B/13B/33B/65B多个体型变种
-
LLaMA 2:第二代基础模型,训练数据增加40%
-
LLaMA 2 Long:通过RoPE ABF调整支持32k上下文
-
-
通用微调分支
-
Alpaca系:早期指令微调方向
-
Alpaca-LoRA:参数高效微调变体
-
Guanaco:多语言支持分支
-
Luotuo(骆驼):中文社区早期尝试
-
-
Vicuna系:高质量对话方向
-
Chinese-Vicuna:中文对话优化
-
BELLE:中文对话增强版
-
Koala:UC Berkeley的对话变体
-
领域专用分支
-
语言区域适应
-
Chinese-LLaMA:中文基础模型
-
Ziya:深度中文优化
-
Yulan-Chat:中文对话专家
-
-
专业领域
-
法律分支:Lawyer LLaMA、LAWGPT
-
医疗分支:ChatMed、BenTsao、TaoLi
-
金融分支:聚宝盆(Cornucopia)
-
学术分支:QiZhenGPT
-
-
多模态能力
-
视觉分支:LLaVA、Chinese-LLaVA、VisionLLM
-
语音分支:LLaSM
-
综合多模态:PandaGPT
-
特殊能力分支
-
Goat:数学推理专项优化
-
BiLLa:双语理解增强
-
Chatbridge:跨语言对话专家
这一分类体系反映了LLaMA家族如何从单一基础模型出发,通过不同微调策略“适应辐射”到各种生态位(应用场景),其分化速度和多样性堪比生物学驼类跨越各大洲的适应过程。
接下来将首先解析LLaMA的基础架构特性,然后系统梳理两大微调范式——全参数微调与参数高效微调(PEFT),并深入探讨不同领域下的微调技术选择与优化策略,最后展望LLaMA生态的未来发展方向。
LLaMA基础架构解析:强大性能的基因密码
LLaMA系列之所以能成为开源大模型的标杆,其基础架构设计功不可没。与GPT-3等闭源大模型相比,LLaMA在模型结构上集成了多项前沿改进,使其在更小参数量下实现了可比甚至更优的性能。
预训练数据规模是LLaMA强大能力的首要保障。以LLaMA-65B为例,其在1.4万亿token的公开数据集上训练,涵盖了CommonCrawl、Wikipedia、Gutenberg等多个高质量来源。这种数据规模虽不及GPT-3的庞大,但通过精心筛选和混合,确保了训练数据的多样性和质量。值得注意的是,后续的LLaMA 2 Long更是将训练token扩展至4000亿,远超原始LLaMA 2的700亿,为长上下文理解能力奠定了数据基础。
在模型架构层面,LLaMA采用了三项关键创新:
-
Pre-normalization:在Transformer模块的残差连接前进行层归一化,显著提升了训练稳定性,这一技术最早见于GPT-3;
-
SwiGLU激活函数:替代传统的ReLU,通过门控机制实现更复杂的非线性表达,该技术由PaLM模型率先采用;
-
旋转位置编码(RoPE):完全取代绝对位置嵌入,通过旋转矩阵实现位置信息的外推,这一设计后来成为扩展上下文长度的关键。
RoPE尤其值得关注,它不仅是LLaMA处理位置信息的核心机制,也成为后续扩展上下文窗口的技术基础。RoPE通过将token嵌入映射到3D空间并赋予旋转特性,使模型能够更高效地捕捉相对位置关系。Meta团队发现,简单地调整RoPE的超参数“基频”从10000增加到500000,就能显著减少对远端token的衰减效应,使LLaMA 2 Long支持高达32k的上下文窗口,性能甚至超越ChatGPT和Claude 2。
| 模型版本 | 参数量 | 训练token数 | 上下文窗口 | 关键技术 |
|---|---|---|---|---|
| LLaMA-7B | 70亿 | 1T | 2k | RoPE, SwiGLU |
| LLaMA-13B | 130亿 | 1T | 2k | Pre-normalization |
| LLaMA-65B | 650亿 | 1.4T | 2k | 混合精度训练 |
| LLaMA 2 Long | 70亿 | 4000亿 | 32k | RoPE ABF |
LLaMA的另一个显著优势是其计算效率。相比同期的OPT和BLOOM等开源大模型,LLaMA在更小参数量下实现了更优性能,使学术界和中小企业也能参与大模型研究和应用。例如,LLaMA-7B模型大小约27G(FP16),可在单张16G V100 GPU上进行推理甚至微调,这种“小的大模型”理念极大地降低了技术门槛(扩展阅读:5 个经典的大模型微调技术-CSDN博客、全模型微调 vs LoRA 微调 vs RAG-CSDN博客)。
随着LLaMA 2的发布,模型家族进一步丰富,新增了MPT(支持84k上下文)和RedPajama(可在消费级显卡运行)等变体,形成了覆盖从移动端到数据中心的全谱系解决方案。这些技术进步为后续的微调工作提供了坚实基础,使LLaMA能够"进化"出适应各种环境和任务的“亚种”。
全参数微调:释放模型潜力的全面进化
全参数微调(Full Fine-Tuning)是适配预训练模型到下游任务最直接的方法,它允许调整模型的所有参数以最大化任务性能。对于LLaMA家族而言,全参数微调如同让驼类生物经历全面进化,重塑其“生理结构”以适应特定环境。
全参数微调的技术实现
传统全参数微调面临的主要挑战是显存需求爆炸。以LLaMA-7B为例,使用AdamW优化器进行全参数微调需要超过102GB显存,远超单张GPU的容量。这种资源需求将大模型微调长期限制在拥有高端计算集群的机构手中。
针对这一挑战,研究者们开发了多项内存优化技术:
-
混合精度训练:将部分计算转为FP16,减少显存占用同时保持关键部分为FP32精度。LLaMA-7B通过此技术将显存需求从27G(FP32)降至约14G(FP16);
-
梯度累积:当单卡batch size受限时(如只能设为1),通过多次前向后向计算再统一更新参数,模拟更大batch size的效果;
-
模型并行:将模型拆分到多个GPU上,如将不同层分配到不同设备(tensor并行)或分割注意力头(head并行)。
2023年6月,复旦大学邱锡鹏团队提出的LOMO优化器(Low-Memory Optimization)将全参数微调的门槛降至新低。LOMO通过将梯度计算与参数更新融合为单步操作,避免存储全部梯度张量,同时采用SGD替代AdamW消除优化器状态存储。这些创新使LLaMA-65B的全参数微调仅需8块RTX 3090(24GB显存)即可完成,显存使用降至传统方法的10.8%。
不同优化器下的显存使用对比(LLaMA-7B)如下表:
| 优化器类型 | 显存占用(GB) | 主要内存消耗项 | 适用场景 |
|---|---|---|---|
| AdamW | 102.20 | 优化器状态(73.7%) | 大型计算集群 |
| SGD | 51.99 | 梯度张量 | 中等规模GPU服务器 |
| LOMO | 14.58 | 参数+激活值 | 消费级GPU |
LOMO不仅节省内存,还保持了与全参数微调相当的性能。在SuperGLUE基准测试中,LOMO微调的LLaMA-13B在BoolQ和MultiRC等任务上显著优于零样本学习,且普遍超越流行的LoRA方法。值得注意的是,LOMO可与LoRA结合使用,二者分别优化不同部分参数,形成互补优势。
全参数微调的领域应用
全参数微调在需要深度适应的领域表现出独特价值。根据任务特性,我们可以将LLaMA的全参数微调应用分为几大类:
数学与逻辑推理领域对模型参数的整体协调性要求极高。研究表明,在GSM8K小学数学数据集上,全参数微调的LLaMA-13B比LoRA方法准确率高出5-7%。这种优势在70B大模型上更为明显,因为更大参数量提供了更丰富的内部表示空间。数学推理需要模型精确协调多层抽象概念,全参数微调可能更利于这种全局优化。
复杂结构化输出任务同样受益于全参数微调。例如将自然语言转换为SQL查询的任务中,全参数微调的LLaMA-7B比13B的LoRA模型表现更优,尽管后者参数量近乎翻倍。这种需要精确语法生成和结构化思维的任务,可能更需要模型所有参数的协调调整。
长上下文建模是LLaMA全参数微调的另一重要应用。Meta通过全参数微调将LLaMA 2的上下文窗口从2k扩展到32k,仅需不到1000步微调,成本“忽略不计”。这种微调结合了位置编码调整(如RoPE ABF)和长序列连续预训练,使LLaMA 2 Long在长文档摘要等任务上媲美GPT-4。
专业领域深度适应如法律、医疗等需要高度专业知识的领域,全参数微调展现出独特优势。腾讯云开发者社区的分析指出,当处理“代表性不足的领域”(如特定语言或小众专业)时,全参数微调能更充分地调整模型内部表示,准确率提升可达50%以上(如金融情感分析从34%提升至85%)。
全参数微调虽然强大,但也面临灾难性遗忘的挑战——模型在适应新任务时可能丢失原有知识。针对这一问题,研究者开发了渐进式微调、弹性权重巩固等技术,在LLaMA家族的应用中取得了初步成效。随着资源需求的降低,全参数微调正从科技巨头的专属技术转变为更广泛可用的工具,推动LLaMA在各领域的深度定制化应用。
参数高效微调(PEFT):轻量适配的定向进化
与全参数微调的“全面进化”不同,参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)如同生物界的“定向进化”,仅调整关键部位即可快速适应新环境。这类技术通过冻结预训练模型的大部分参数,仅微调少量新增或选定的参数,实现了在有限资源下对LLaMA家族的高效适配。
PEFT主流方法及技术原理
PEFT技术自2023年以来呈现爆发式增长,一篇涵盖246篇文献的最新综述将其系统分为四大类:加性微调、选择性微调、重参数化微调和混合微调。在LLaMA家族的应用中,以下几类方法尤为突出:
LoRA及其变种是LLaMA微调中最流行的技术。LoRA(Low-Rank Adaptation)基于一个关键洞察:微调引起的权重变化往往具有低秩特性。具体实现时,LoRA在原始权重矩阵旁添加两个低秩矩阵A和B(秩r通常为8),训练时仅更新这两个小矩阵。例如,对于LLaMA-7B的QKV注意力矩阵(形状为),LoRA仅添加形状为
和
的两个矩阵,将可训练参数从
降至
。微调完成后,LoRA权重可合并回原模型,不引入额外推理开销。
LoRA在LLaMA微调中展现出惊人效率。Alpaca-LoRA项目仅用单张RTX 4090,几小时即可完成LLaMA-7B的微调,效果媲美斯坦福全参数微调的Alpaca。这种效率使LoRA成为个人开发者和研究者的首选方案。
Adapter是另一类广泛应用的PEFT方法。Adapter在Transformer模块中插入小型瓶颈结构,通常包含下投影(如)、非线性层和上投影(
)。与LoRA不同,Adapter会改变模型架构,引入额外推理延迟(扩展阅读:初探 Transformer-CSDN博客)。针对这一问题,开发者提出了Parallel Adapter(并行插入)和CoDA(条件适配)等变体,后者仅对重要token激活Adapter分支以节省计算。
Prompt Tuning通过优化输入嵌入实现适配。Prefix-tuning在每个Transformer层的键、值、查询矩阵前添加可学习向量,而Prompt Tuning仅在输入层插入可学习token(扩展阅读:初探注意力机制-CSDN博客、来聊聊Q、K、V的计算-CSDN博客)。这类方法极端高效,但通常需要较大规模预训练模型才能发挥效果。在LLaMA家族中,Prompt Tuning更多用于辅助其他微调方法。
LLaMA微调中主要PEFT方法对比如下表:
| 方法类型 | 代表技术 | 可训练参数比例 | 是否改变架构 | 典型应用场景 |
|---|---|---|---|---|
| 低秩适应 | LoRA, DoRA | 0.1%-1% | 否 | 通用任务适配 |
| 适配器 | Adapter, Parallel Adapter | 1%-5% | 是 | 多任务学习 |
| 提示调优 | Prefix-tuning, Prompt Tuning | <0.1% | 是 | 轻量级适配 |
| 稀疏微调 | BitFit, Diff Pruning | 0.1%-10% | 否 | 领域自适应 |
QLoRA是LoRA与量化技术的结合,进一步降低了资源需求。QLoRA使用4-bit NormalFloat量化预训练权重,同时采用分页优化器处理内存峰值。实验显示,QLaMA-7B的QLoRA微调仅需约10GB显存,使消费级显卡也能参与大模型定制。
PEFT技术的选择需要权衡多个因素。Anyscale的研究团队通过三个典型案例分析了LoRA在LLaMA微调中的表现:在ViGGO(非结构化文本转功能表征)任务上,LoRA微调的13B模型达到95%准确率,仅比全参数微调低2%;而在GSM8K数学推理上,同一模型落后全参数微调7%,表明任务类型显著影响PEFT效果。
PEFT的领域适配策略
不同应用领域对PEFT技术的选择和要求各不相同。根据腾讯云开发者社区的总结,PEFT特别适合以下场景:
语气与风格适配是PEFT的优势领域。当需要LLaMA模仿特定写作风格或专业术语时(如法律文书、医疗报告),通过少量风格化数据微调LoRA或Adapter即可显著改善输出质量,且不会破坏原有语言理解能力。例如,使用几百个医患对话微调的LLaMA-Med在生成医疗建议时,专业性和亲和力同步提升。
边缘案例处理中PEFT展现精准修正能力。当LLaMA在特定场景(如罕见编程语言、小众方言)表现不佳时,针对性微调可以低成本解决这些问题。RedPajama项目通过在5TB多语言数据上训练,使30B参数模型能在RTX2070这类消费级显卡上流畅运行小众语言任务。
多任务服务场景凸显PEFT的管理优势。云服务商可以维护一个基础LLaMA模型和多个PEFT模块(如LoRA权重),根据请求动态加载相应模块。这种“集中式PEFT查询服务”大幅降低了多任务部署成本,使单个LLaMA实例能同时服务法律咨询、医疗问答等不同领域需求。
资源受限环境是PEFT的传统优势领域。如前所述,QLoRA等技术使LLaMA微调可在笔记本电脑完成,而像RedPajama-3B这样的精简模型甚至能在手机端进行轻量微调。这种可及性推动了LLaMA在全球范围内的普及,特别是在发展中国家和中小企业中。
值得注意的是,PEFT技术正与全参数微调走向融合。如复旦大学LOMO优化器既能用于全参数微调,也可结合LoRA实现“部分全参+部分PEFT”的混合策略。这种灵活度为LLaMA家族的领域适配提供了更丰富的技术选项,使开发者能根据任务需求和资源条件选择最佳微调路径。
领域专用微调:LLaMA家族的生态分化
正如达尔文在加拉帕戈斯群岛观察到的雀类分化现象,LLaMA家族在不同应用领域的微调过程中也展现出惊人的适应性辐射。从医疗健康到金融法律,从多模态交互到边缘设备,专用化LLaMA变体如“华驼”(中文医学专用)、MPT-7B-StoryWriter(长文本创作)等不断涌现,形成了丰富的大模型生态系统。
按领域划分的微调策略选择
不同领域对模型能力的需求各异,需要针对性的微调策略。基于搜索结果和实际案例,我们可以总结出LLaMA家族在各主要领域的微调方法论:
医疗健康领域面临数据敏感和专业性强的双重挑战。腾讯云的文章指出,患者病历等敏感数据通常不在公共领域,需专用微调实现合规利用。中文医疗社区开发的“华驼”基于LLaMA微调,采用两阶段策略:先在中英文医学文献上做全参数预训练扩展医学知识,再通过LoRA在医患对话数据上微调问诊能力。这种组合既保证了专业深度,又控制了训练成本。
金融与法律领域需要精确的术语处理和逻辑推理。Anyscale的实验表明,在金融合同分析任务中,LoRA微调的LLaMA-13B比全参数微调的7B版本表现更优,体现了参数规模与微调效率的平衡。法律领域则更常采用Adapter结合领域预训练的策略,如Legal-LLaMA先在法律条文上继续预训练,再通过Parallel Adapter微调具体任务。
教育领域的LLaMA微调强调安全性和教学有效性。教育专用模型通常采用多技术组合:通过全参数微调确保基础教学能力,结合RLHF(基于人类反馈的强化学习)优化对话安全性,最后采用Prompt Tuning实现学科自适应。例如Edu-LLaMA在数学解题任务中,先通过全参数微调掌握通用解题逻辑,再使用RLHF过滤不当输出,最终通过学科特定prompt实现数学符号的精准处理。
多模态与边缘计算的特殊适配
在多模态交互领域,LLaMA的微调呈现“轻量化主干+重模块扩展”特点。阿里云的研究显示,将视觉编码器与LLaMA-7B结合时,冻结主干网络仅微调跨模态注意力层,既能保持语言能力又可降低70%训练成本。而边缘设备部署则发展出“双阶段量化”策略:先进行QAT(量化感知训练)微调,再实施动态8bit量化,使LLaMA-3B能在树莓派上实现2秒/词的推理速度。
1. 多模态适配的优化方向
当前,多模态LLaMA的微调主要聚焦于模态对齐效率和计算开销平衡:
-
跨模态注意力优化:采用稀疏注意力机制(如LongLoRA的滑动窗口策略)减少视觉-语言交互的计算复杂度,提升长序列处理能力。
-
渐进式模态融合:华为的Fuse-LLaMA采用分阶段训练策略,先对齐视觉-文本特征空间,再微调下游任务,相比端到端训练节省40%显存占用。
-
轻量化视觉编码器:如使用SigLIP(Sigmoid Loss for Image-Text Pretraining)替代CLIP,在保持性能的同时减少50%参数量,更适合边缘部署。
2. 边缘计算的挑战与创新
边缘设备上的LLaMA微调面临算力受限和延迟敏感两大核心问题,催生多种适配方案:
-
动态量化+知识蒸馏(DQKD):在量化微调阶段引入教师模型(如FP16精度的LLaMA-7B)进行输出对齐,缓解低精度带来的性能损失。
-
混合精度适配:关键模块(如自注意力层)保持FP16,其余部分采用8bit量化,在树莓派上实现精度与速度的最佳平衡(<3%准确率损失,推理速度提升5倍)。
-
硬件感知微调:针对特定芯片(如英伟达Jetson、高通AI引擎)优化算子,利用TensorRT-LLM等工具链实现端到端加速。
3. 未来趋势:端-边-云协同微调
随着边缘AI的普及,分层微调架构成为研究热点:
-
云端预训练+边缘个性化:在云端完成通用能力微调,边缘设备仅需轻量级适配(如LoRA或Adapter),实现用户数据本地化处理。
-
联邦边缘学习(FEL):多个边缘节点协作微调全局模型,通过差分隐私保护数据安全,Meta的实验显示可使医疗问诊模型的准确率提升15%。
-
自适应计算卸载:根据设备负载动态分配计算任务(如文本生成在本地,多模态分析在云端),华为的Edge-LLaMA框架已实现毫秒级任务调度。
典型案例分析
Vicuna-13B:高效对话专家的技术解析
作为LLaMA家族中最成功的变体之一,Vicuna-13B的技术实现值得深入分析。其核心创新包括:
-
高质量对话数据:从ShareGPT收集约70K用户与ChatGPT的真实对话,涵盖多样化主题和交互模式。
-
内存优化:将最大上下文长度从Alpaca的512扩展到2048,采用梯度检查点和Flash Attention技术解决内存压力。
-
多轮对话支持:调整训练损失函数以考虑对话历史,仅在聊天机器人输出上计算微调损失。
-
成本控制:使用SkyPilot托管的Spot实例,通过自动恢复和区域切换将13B模型的训练成本从约1000美元降至300美元。
评估方面,研究团队创新性地采用GPT-4作为评判者,设计了8类80个问题进行全面测试。结果显示Vicuna在90%的情况下优于其他开源模型,总分达到ChatGPT的92%。这种评估方法后来被众多LLaMA变体效仿,成为开源模型性能对比的新标准。
Vicuna的成功印证了一个重要观点:数据质量比模型规模更重要。通过精心筛选的真实对话数据,13B参数的Vicuna能够达到175B参数GPT-3的九成效果,这一性价比优势使其成为开源社区的重要里程碑。
Chinese-LLaMA:中文适应的技术路径
针对LLaMA原生中文能力薄弱的问题,Chinese-LLaMA采取了多管齐下的优化策略:
-
词表扩展:在原有英语为主的词表基础上,新增数千个常用中文字符和词汇,解决中文token化效率低下的问题。
-
持续预训练:在110G纯中文文本上进行增量预训练,使模型掌握中文语言模式和基础知识。
-
指令微调:使用中英文混合的指令数据(格式兼容llama-2-chat)进行监督微调,优化模型的任务跟随能力。
-
社区协作:项目开源两周即在Hugging Face获得过万下载,GitHub收获1200 Stars,通过社区反馈快速迭代。
这种“预训练-微调”两阶段方法如同驼类适应新环境的过程:先建立基本的生存能力(中文理解),再发展特定技能(任务执行)。后续的Chinese-Vicuna、Ziya等模型在此基础上进一步优化,形成了完整的中文LLaMA生态。
聚宝盆(Cornucopia):金融领域专家的打造
金融领域对专业性和准确性要求极高,聚宝盆模型通过以下方式实现了专业能力突破:
-
数据构建:整合公开金融问答数据和爬取的专业内容,覆盖保险、理财、股票、基金等多个子领域,构建12M指令数据集。
-
指令设计:专业问题如“办理商业汇票应遵守哪些原则和规定?”配以详细准确的回答,确保模型掌握精确的金融知识。
-
LoRA微调:采用参数高效微调方法在LLaMA-7B上进行适配,单张A100显卡(80GB)即可完成训练,batch_size=64时显存占用约40G。
-
评估对比:与文心一言、讯飞星火等通用模型比较,在金融专业问题上表现更优。如回答“老年人理财好还是存定期好?”时,能根据风险承受能力给出差异化建议,而非通用模糊回答。
聚宝盆的成功表明,即使是7B参数的“小型”LLaMA,通过高质量的领域特定微调,也能在专业任务上媲美甚至超越更大规模的通用模型。这类似于特定环境下,经过专门驯化的驼类(如产绒羊驼)比野生大型驼类更具经济价值。
未来展望:LLaMA家族的进化方向
基于当前发展趋势,LLaMA家族可能朝以下方向继续“进化”:
-
更长上下文:LLaMA 2 Long已展示32k上下文能力,未来可能进一步扩展。RoPE ABF等位置编码改进是关键。
-
多模态深度融合:现有LLaVA、LLaSM等模型尚处早期,真正的跨模态理解和生成仍有提升空间。
-
专业化与微型化:如医学领域的BenTsao、金融领域的聚宝盆所示,特定领域的小型专家模型是重要方向。
-
训练方法创新:全参数微调与PEFT的混合策略,如LOMO优化器结合LoRA,可能成为新标准。
-
评估体系完善:超越传统基准,建立更全面的领域专用评估标准,如金融、医疗等专业领域的细粒度测试集。
-
伦理安全增强:现有开源模型在安全性、偏见控制方面仍有不足,需要建立更完善的防护机制。
正如驼类动物从史前时代至今不断适应变化的环境,LLaMA家族也将在技术变革中持续进化。这场从碳基到硅基的跨域类比,不仅提供了生动的命名框架,更启示我们:多样性、适应性和专业化是技术生态繁荣的关键。
结语:从生物进化到技术进化
纵观LLaMA家族的发展历程,我们看到了与生物学进化惊人的相似性:
-
基础物种形成:LLaMA如同驼类祖先,提供了基本的“基因型”(模型架构)
-
适应性辐射:各类微调变体快速占领不同“生态位”(应用场景)
-
特化与优化:领域专用模型发展出独特的“生存技能”(专业能力)
-
生态位分化:通用与专用、文本与多模态模型形成互补共存
这种跨域类比不仅有趣,更具深刻的启示意义。生物学驼类历经数千万年自然选择形成的多样性,在硅基LLaMA家族中仅用短短一年多就实现了技术层面的“快速进化”。这既展示了人工智能技术的惊人发展速度,也提醒我们:健康的技术生态需要像自然生态一样保持多样性。
从碳基羊驼到硅基LLaMA,从安第斯山脉到数字世界,这场跨越物质形态的“进化之旅”仍在继续。或许未来某天,当LLaMA家族的某个后代真正达到通用人工智能的高度时(扩展阅读:关于大模型的认知升级-CSDN博客、多智能体在具身智能上的研究-CSDN博客),我们会想起这个以驼类命名的起点——正如现代骆驼仍保留着远古祖先的基本形态,却已适应了完全不同的现代环境。