DROPP算法详解:专为时间序列和空间数据优化的PCA降维方案
DROPP (Dimensionality Reduction for Ordered Points via PCA) 是一种专门针对有序数据的降维方法。本文将详细介绍该算法的理论基础、实现步骤以及在降维任务中的具体应用。
在现代数据分析中,高维数据集普遍存在特征数量庞大的问题。这种高维特性不仅增加了计算复杂度,还可能导致算法性能下降和模型过拟合。降维技术作为数据预处理的重要手段,旨在减少输入变量的数量,同时最大程度地保留数据中的关键信息。该技术在简化模型复杂度、提高计算效率以及改善数据可视化方面发挥着重要作用,特别是在处理高维数据时表现出显著优势。
DROPP算法原理
DROPP (Dimensionality Reduction for Ordered Points via PCA) 算法通过在有序数据点间引入结构化协方差分析,并结合高斯核函数调整,将数据的顺序特性有效融入降维过程。该方法的核心思想是利用有序数据中相邻元素间的相似性特征,通过关注局部邻域信息来降低随机噪声对降维结果的影响。
DROPP算法特别适用于时间序列数据、空间序列数据或其他具有自然顺序特性的数据集。通过保持数据的内在顺序结构,该算法能够更准确地捕获数据的潜在模式。
算法实现步骤
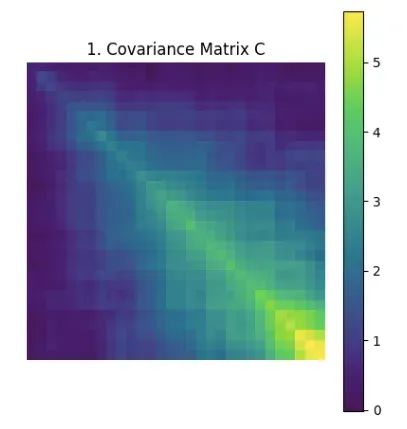
步骤一:协方差矩阵计算
协方差矩阵作为描述多变量数据特征间相互关系的重要工具,其每个元素反映了对应特征对之间的线性相关性强度和方向。在有序数据分析中,空间或时间上相邻的特征通常表现出较强的协方差关系,这一特性为DROPP算法的设计提供了理论基础。
对于包含n个样本和d个特征的数据集X,算法首先对每行数据进行标准化处理,随后计算协方差矩阵C:
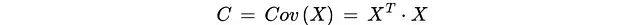
该矩阵量化了所有特征对之间的关联强度,为后续分析提供基础数据。
defnormalize_rows(X): norm=np.linalg.norm(X, axis=1, keepdims=True) returnX/ (norm+1e-10) defcompute_covariance(X): X_norm=normalize_rows(X) returnnp.dot(X_norm.T, X_norm)
步骤二:距离相关性分析
该步骤将协方差矩阵解释为特征维度间距离的函数。通过计算不同偏移量k(索引i和j之间的差值)对应的平均协方差值,算法构建了相关性随距离变化的函数关系:
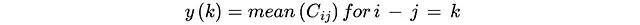
函数y(k)描述了特征间相关性如何随着距离增加而衰减,这一关系反映了有序数据的基本特性。
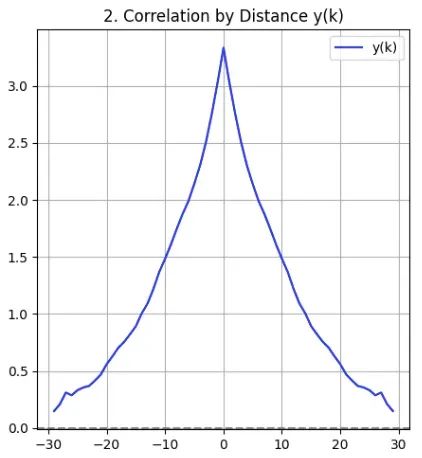
defcompute_yk(C): d=C.shape[0] yk=np.zeros(2*d-1) counts=np.zeros(2*d-1) foriinrange(d): forjinrange(d): k=i-j yk[k+d-1] +=C[i, j] counts[k+d-1] +=1 returnyk/counts
步骤三:潜在分布特征提取
算法通过确定带宽参数k₀来识别有意义的局部结构与长距离噪声之间的边界。k₀定义为y(k)首次变为非正值的位置,该参数有效区分了真实的局部相关性和随机波动。
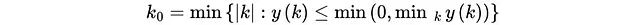
基于k₀,算法构建截断函数,仅保留距离k₀范围内的相关性信息,超出范围的值被置零:
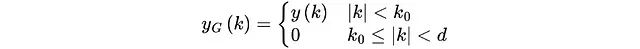
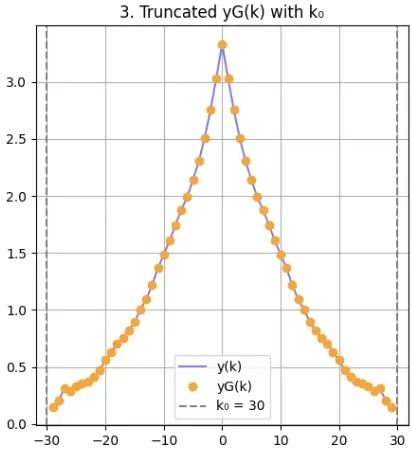
defcompute_k0(y): d= (len(y) +1) //2 center=d-1 min_val=min(0, np.min(y)) forkinrange(1, d): ify[center+k] <=min_valory[center-k] <=min_val: returnk returnd
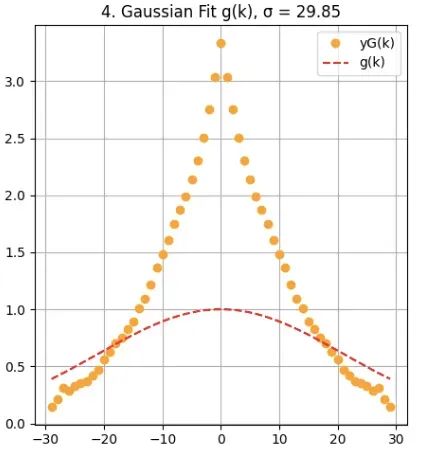
步骤四:高斯函数拟合
算法采用高斯函数对有序协方差结构的有效部分进行建模。该高斯函数能够平滑地描述相关性在有序数据中随距离的自然衰减规律:
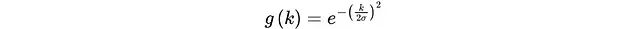
通过最小化高斯函数g(k)与截断协方差函数yG(k)之间的均方根误差(RMSE),算法确定最优的标准差参数σ:
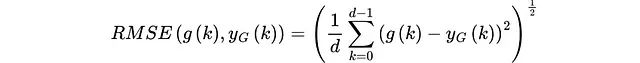
该高斯函数有效捕获了相关性的距离依赖模式,同时平滑了数据中的噪声和不规则波动。
deftruncate_yk(y, k0): d= (len(y) +1) //2 center=d-1 yG=np.zeros_like(y) forkinrange(-k0+1, k0): yG[center+k] =y[center+k] returnyG
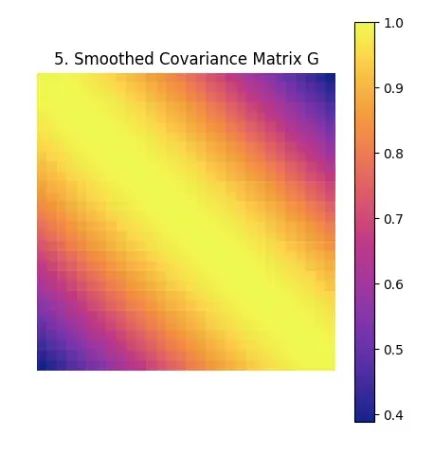
步骤五:平滑协方差矩阵构建
利用拟合得到的高斯函数g(k),算法构建平滑协方差矩阵G:
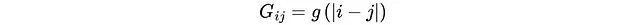
该矩阵有效捕获了数据的潜在生成过程,同时滤除了噪声和不相关的相关性信息。
deffit_gaussian(yG): d= (len(yG) +1) //2 center=d-1 k_vals=np.arange(-d+1, d) defrmse(sigma): gk=np.exp(-(k_vals/sigma) **2) returnnp.sqrt(np.mean((gk-yG) **2)) res=minimize_scalar(rmse, bounds=(1e-2, d), method='bounded') sigma_opt=res.x returnnp.exp(-(k_vals/sigma_opt) **2), sigma_opt
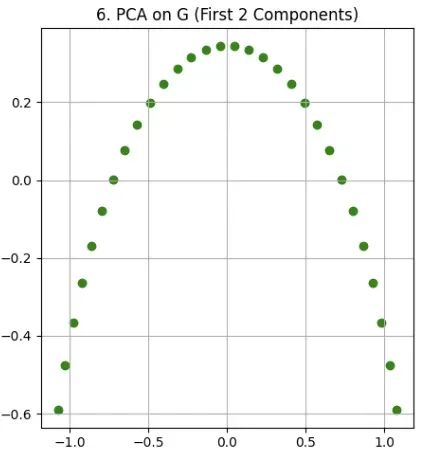
步骤六:主成分分析应用
对构建的平滑协方差矩阵G执行主成分分析(PCA)。PCA作为经典的线性降维技术,能够有效识别数据中的主要变异方向。该方法通过寻找能够解释最大方差的新坐标轴,在保留关键信息的同时实现维度约简。主成分分析的核心作用包括:识别数据中解释最大方差的方向轴,在保持重要信息的前提下减少特征维数,以及将数据转换至各主成分间相互正交的新坐标系统。
最终得到的主成分提供了数据的低维表示,有效反映了其潜在的结构特征。
defconstruct_G(gk): d= (len(gk) +1) //2 G=np.zeros((d, d)) foriinrange(d): forjinrange(d): G[i, j] =gk[abs(i-j) +d-1] returnG
模拟数据应用示例
以下代码展示了DROPP算法在模拟数据上的完整应用过程:
importnumpyasnp
importmatplotlib.pyplotasplt
fromsklearn.decompositionimportPCA
fromscipy.optimizeimportminimize_scalar # ---------------------- 模拟数据生成 ---------------------- np.random.seed(0)
n, d=100, 30 # n: 样本数, d: 有序特征数
X=np.cumsum(np.random.randn(n, d), axis=1) # 累积和 = 平滑趋势 # ---------------------- 应用 DROPP ---------------------- # 步骤 1:协方差
C=compute_covariance(X) # 步骤 2:y(k)
y=compute_yk(C)
k_vals=np.arange(-d+1, d) # 步骤 3:k0 和截断的 yG(k)
k0=compute_k0(y)
yG=truncate_yk(y, k0) # 步骤 4:拟合高斯函数
gk, sigma=fit_gaussian(yG) # 步骤 5:G 矩阵
G=construct_G(gk) # 步骤 6:对 G 应用 PCA
pca=PCA(n_components=2) components=pca.fit_transform(G)
总结
现实世界中的许多数据集源于单一的潜在生成过程。以分子动力学为例,蛋白质的运动遵循基于原子结构的物理定律;类似地,气象数据中的温度变化模式在年度周期中呈现可预测的规律性。这些数据集具有有序特性,序列中相邻数据点的相似性通常高于远距离数据点。
数据分析的根本目标在于理解数据背后的一般性生成过程,而非仅仅拟合特定实例。为实现这一目标,特别是在进行跨数据集比较分析时,需要一种能够有效处理数据有序性并滤除噪声干扰的方法。
DROPP算法正是基于这一需求而设计的专门方法。该算法基于有序数据中相似性程度取决于序列距离的核心假设,采用高斯函数对这种相似性关系进行建模,通过去除噪声干扰并寻找简化的主成分表示来捕获系统的核心行为模式。
该方法由A. Beer, O. Palotás, A. Maldonado, A. Draganov和I. Assent在论文"DROPP: Structure-Aware PCA for Ordered Data: A General Method and its Applications in Climate Research and Molecular Dynamics"中提出,DOI: 10.1109/ICDE60146.2024.00093。
https://avoid.overfit.cn/post/6ab3c6ea0cad49f0ac1170bc73363b6e
作者:Alisa Salnikova