在Ubuntu18.04下搭建SadTalker让图片开口说话
最近学习一些数字人的环境搭建,参考了两个博主的内容(具体参见文末),完成了在Ubuntu18.04下的SadTalker的搭建,选择SadTalker的主要原因是它对硬件的要求不高。下面是对过程的一些梳理,自己也重新学习下。初次尝试由于版本等问题花了一些时间,选择虚拟机搭建的优势是搭建错了可以删除重来,在实体机下搭建可能会引入一些环境问题。
1.环境准备
使用VMware WorkStation 16Pro和Ubuntu18.04桌面板,这里默认已经搭建完毕,这里我选择的虚拟机的配置如下(处理器4,内存8G);
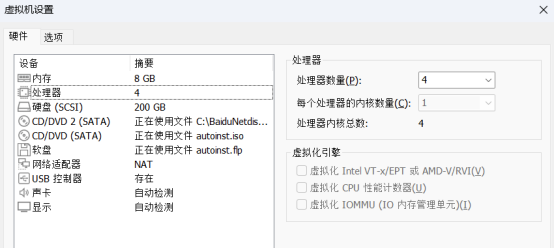
(测试过,选择处理器2,内存4G也能使用,但生成视频时时间更长,面部增强版无法完成)
2.conda管理工具
下载conda:
https://repo.anaconda.com/archive/Anaconda3-2023.03-1-Linux-x86_64.sh
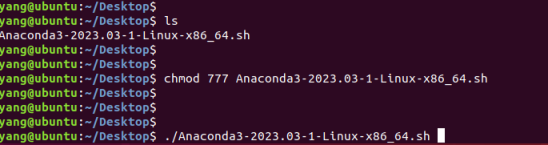
将下载的可执行文件放到ubuntu中,此处放在桌面,赋予权限后,直接运行,如下图:
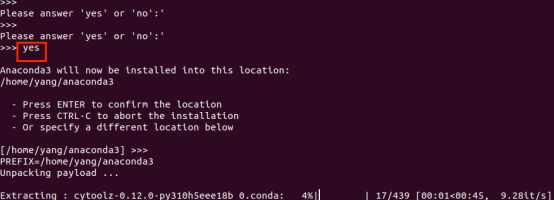
搭建过程回车和选择yes即可
搭建完后,执行初始化,配置环境变量
cd ~/anaconda3/bin
./conda init bash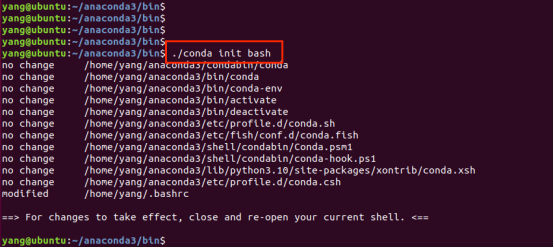
执行后,会在当前用户的bash配置~/.bashrc下如下内容,本质是配置环境变量:
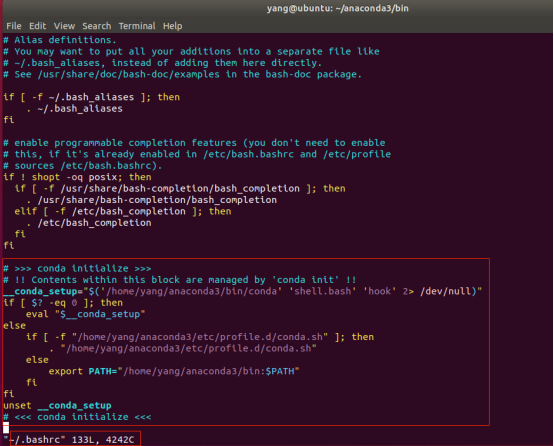
运行语句,让环境变量生效:
source ~/.bashrc
3.SadTalker安装配置
(1)下载源码:
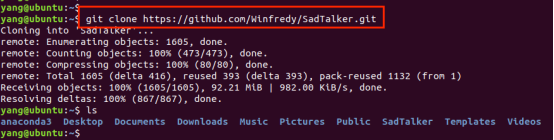
(2)为Sadtalker创建独立的环境,安装对应的工具,需要安装哪些,可以参考SadTalker源码说明
官网参考地址:
GitHub - OpenTalker/SadTalker: [CVPR 2023] SadTalker:Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation
关键内容如下:
git clone https://github.com/OpenTalker/SadTalker.gitcd SadTalkerconda create -n sadtalker python=3.8conda activate sadtalkerpip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113conda install ffmpegpip install -r requirements.txt### Coqui TTS is optional for gradio demo. ### pip install TTS运行的过程如下:
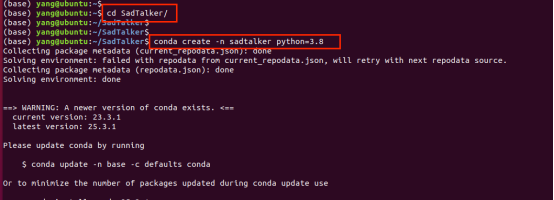
看到如下输出:
激活:
安装ffmpeg:
安装依赖:
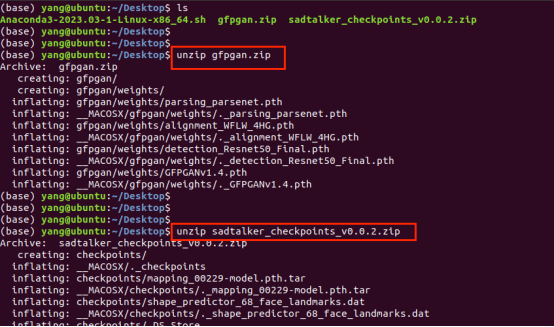
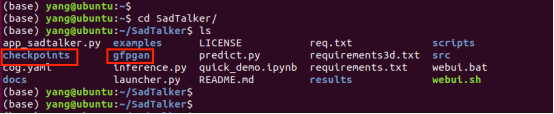
下载 gfpgan.zip 和 sadtalker_checkpoints_v0.0.2.zip,将它们解压后,对应的gfpgan和checkpoints放在~/SadTalker目录下,如下图所示:
下载参考文末其他博客
4.测试
在SadTalker源码下,默认有音频文件和图片,执行如下所示:
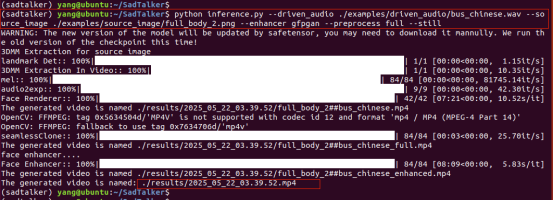
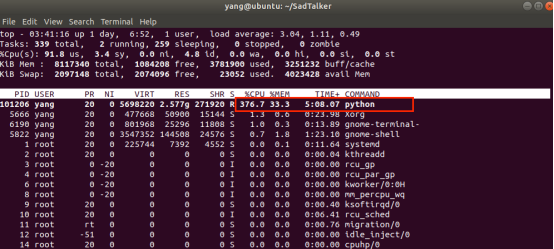
运行过程对CPU和内存监控如下:
完成后,对应视频文件如下:

视频播放如下:
5.参考
让照片人物开口说话,SadTalker 安装及使用(避坑指南)-CSDN博客
数字人生成指南--linux centos SadTalker使用指南,超级详细_sadtalker linux-CSDN博客