浅聊一下搭建企业私有知识库的可行方案
背景
今天突然发现,我们团队负责的一个科创比赛类的项目里,有一个对外宣传的官方网站,这里面有许多涉及到比赛规则,比赛内容,等赛制,规则类的条款文件。说实话,内容很多,很繁杂,对初次准备报名参加的考生来说,很可能会容易出现“找不着北”的心智负担,只能求助于有经验的一些机构,学校等等,搞不好还涉及到一些费用。而参加比赛本身却是不收费的,只是由于信息不对称,却导致出现部分家长花钱报名的情况。。。那有没有办法解决,或者说缓解这种现象呢?
说起来,AI发展到今天,相对成熟的一条落地路线就是RAG(检索增强),实际上我们可以利用相关的技术,搭建一个私有知识库,将所有的赛制,规则等等上传到我们私有的知识库里,让大模型来分析,整理,最后给用户一个清晰,可靠的结果。
实现方案
一体化(几乎)的解决方案–MaxKB
在RAG层面,我个人曾在以前的博客里,介绍过MaxKB,我自己也实际体验过他们的产品。个人认为,大多数中,小企业的系统,想要快速搭建私有知识库,集成RAG,MaxKB可以说是非常好的一个实现方案。产品文档丰富,成功案例多,(几乎)无代码,不需要很多专业知识,就可以快速搭建一套高可用的RAG解决方案。
本地部署
这里我主要聊一下本地部署MaxKb的RAG产品,开箱即用,非常方便。
官网提供了,离线,在线,阿里云,腾讯云,1panel,命令行这几种安装方式,我这里条件有限,就演示下在本地使用docker在线部署的方式。
首先根据文档确认下自己的机器是否满足安装条件,确认完成后,就可以拉取镜像安装了。
docker run -d --name=maxkb --restart=always -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data -v ~/.python-packages:/opt/maxkb/app/sandbox/python-packages registry.fit2cloud.com/maxkb/maxkb
安装好后的效果如下
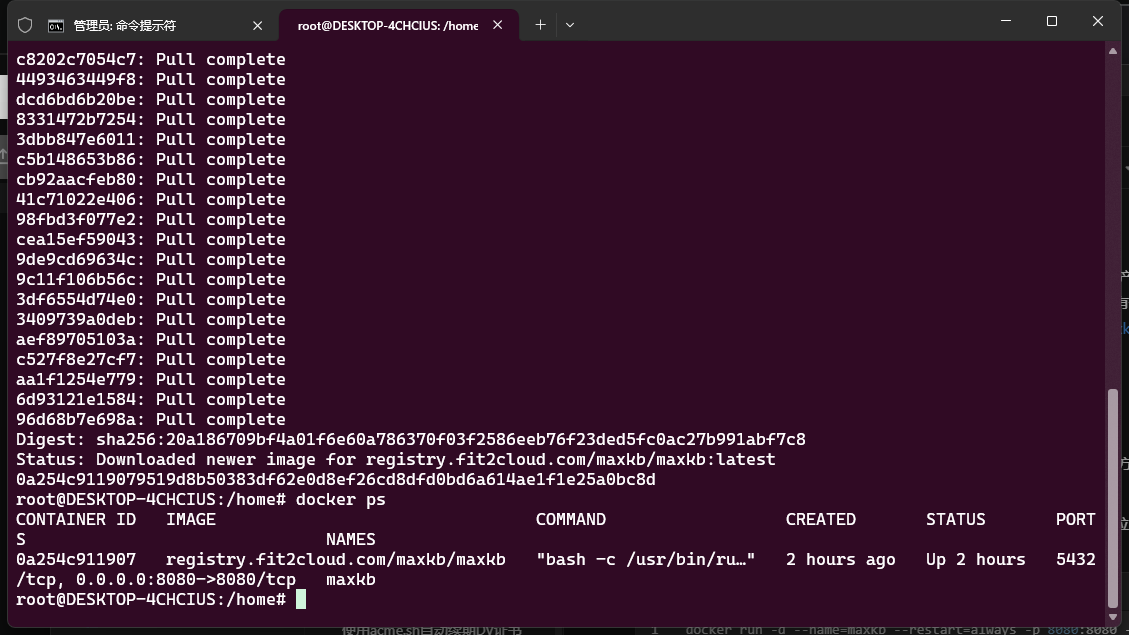
容器启动后,监听8080端口,可以直接在浏览器访问,之后使用默认的账号密码,就可以登录进来了。
实际上官方的文档也十分清楚,还是推荐看文档。
创建应用
后续的流程,实际上和AnythingLLM的逻辑差不多,也是先创建应用,然后绑定AI模型,MaxKb作为国产软件,对国产模型的支持度好很多。
而且,也支持本地模型。
这里,我绑定一个kimi的模型,其他道理一样,都是需要自己有一个APIkey。
其他参数可以先不管,去配置下知识库
配置知识库
配置知识库目的就是做检索增强(RAG),软件界面提供的操作流程也非常清晰方便,傻瓜式的按引导操作即可。
- 创建
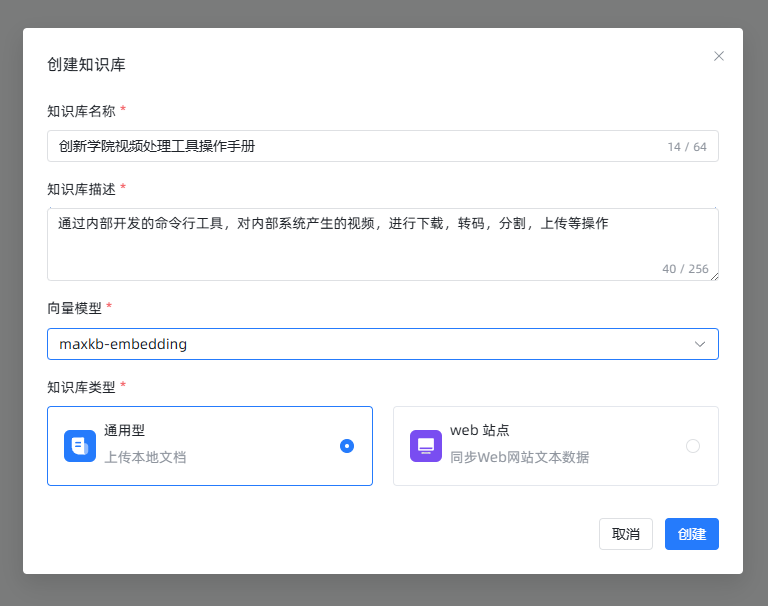
- 上传本地文档
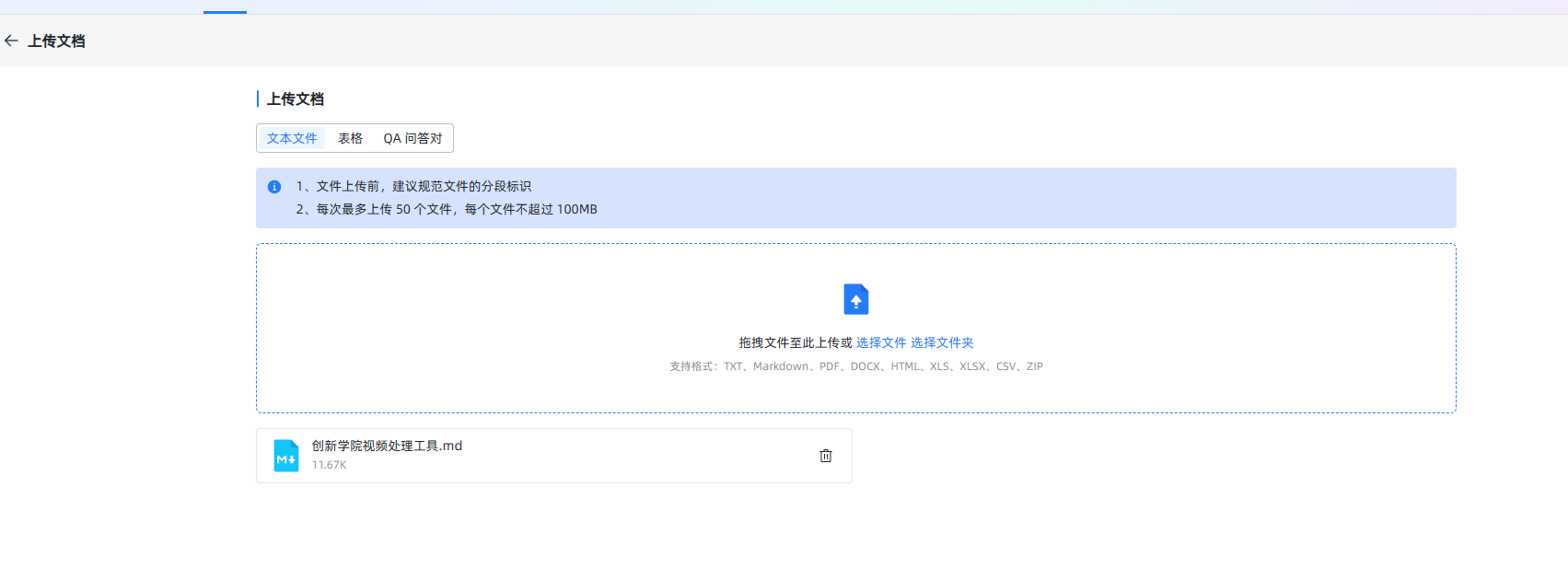
- 分段
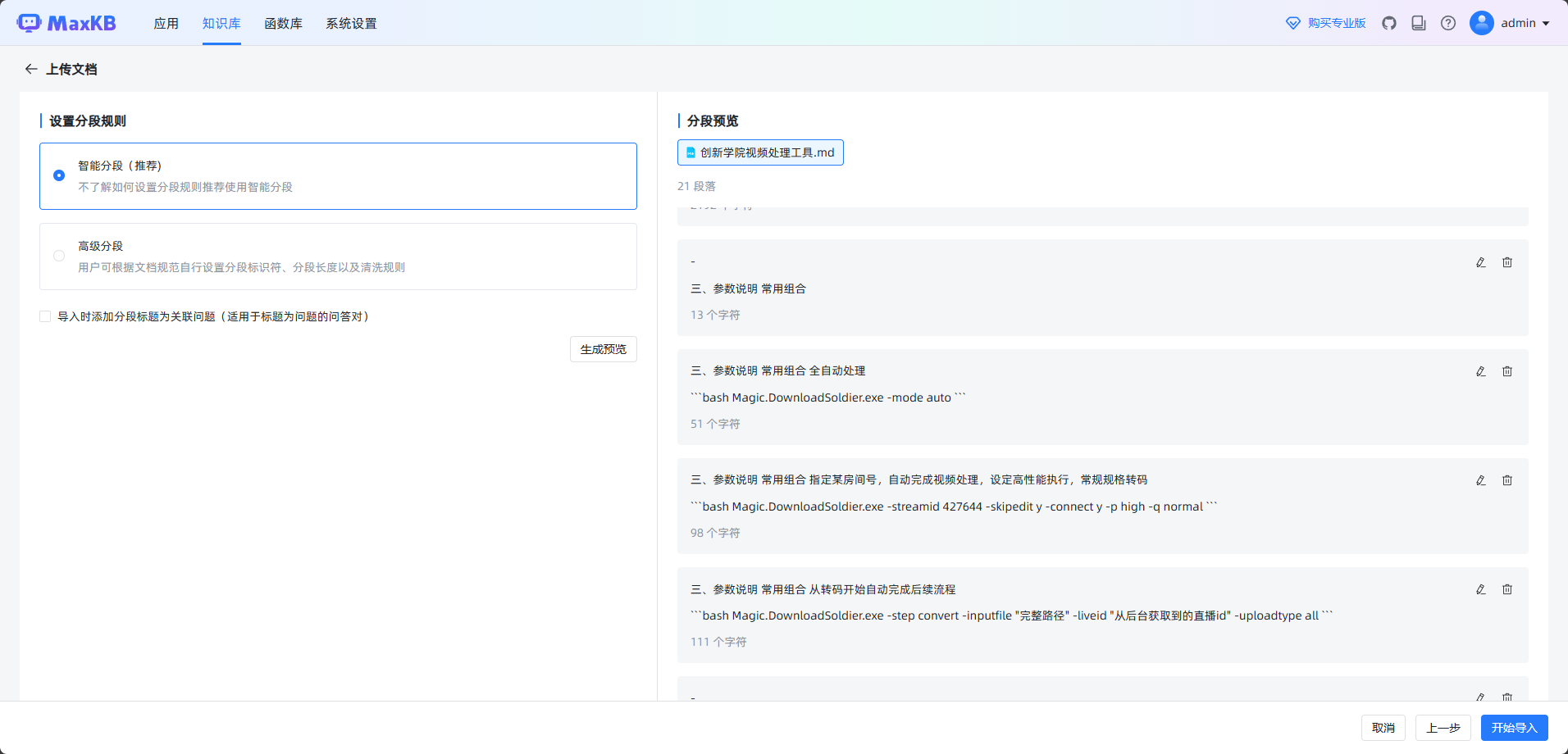
- 训练
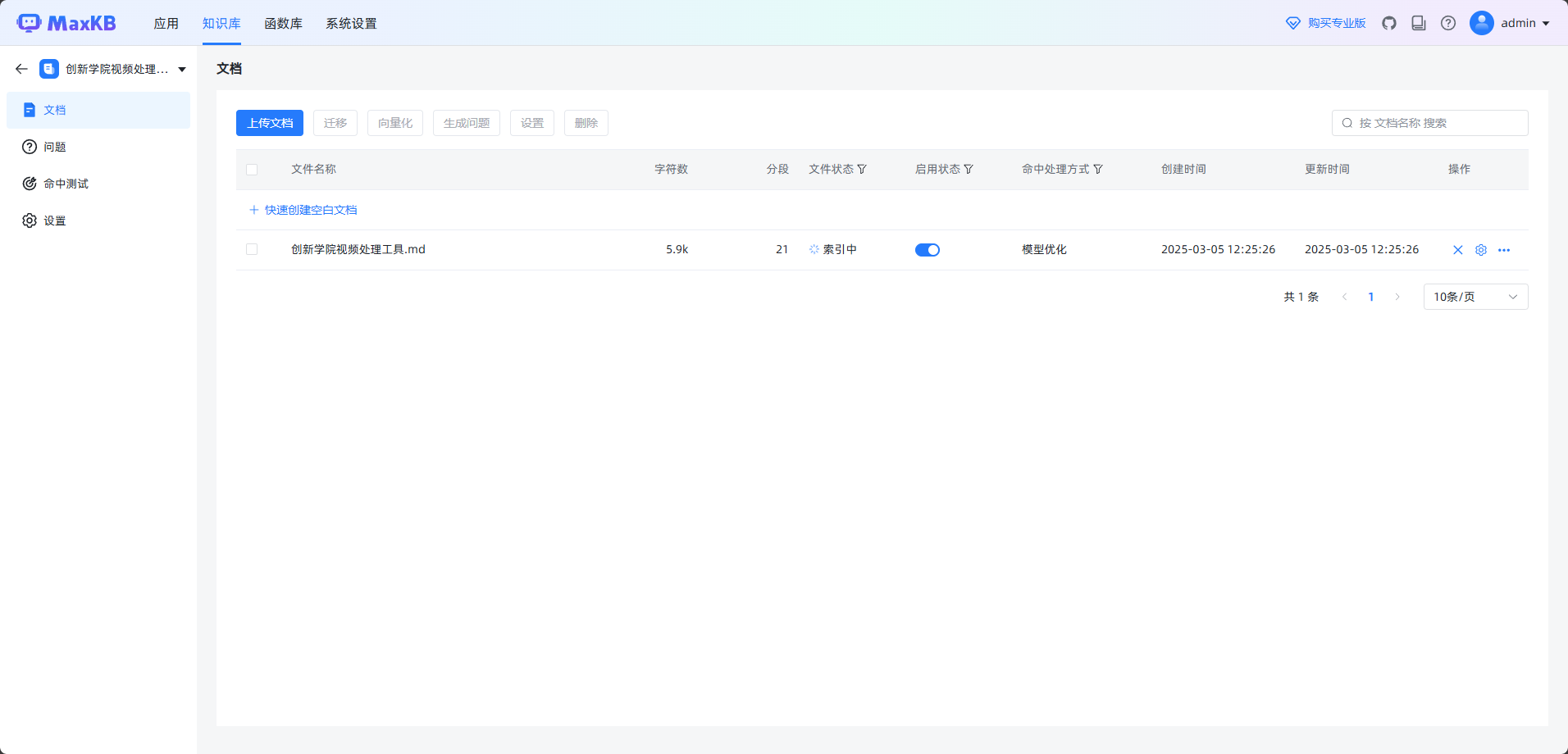
- 训练完成

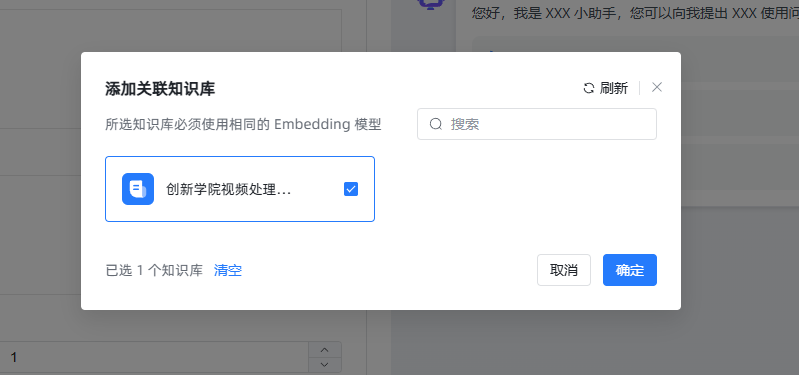
关联知识库
回到刚才创建的应用上,如果刚才没有关联知识库的话,现在可以关联一下
测试
绑定完以后,可以在旁边的调试窗口,测试一下效果
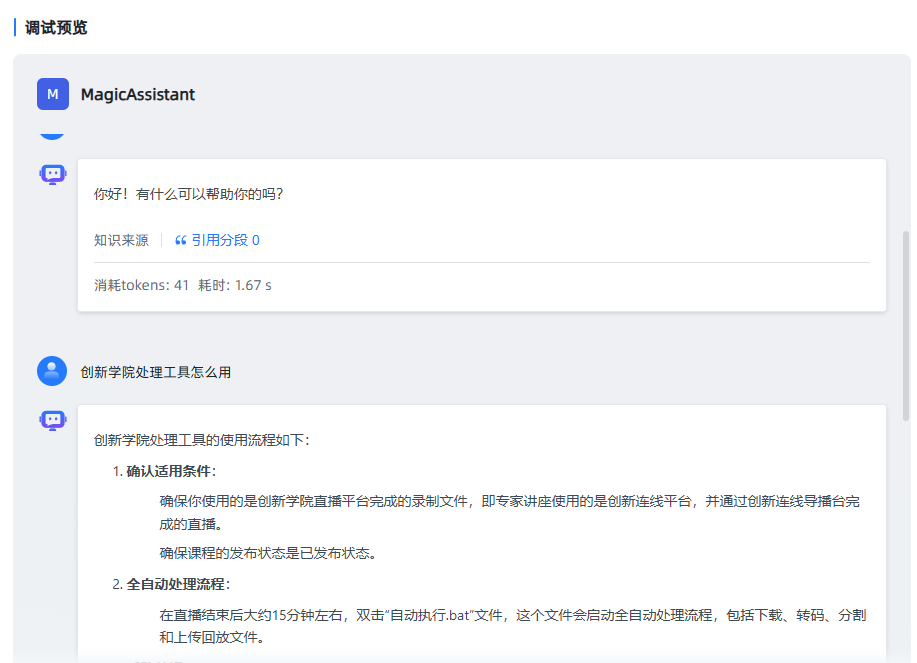
可以看到,它的回答正式根据知识库里的内容输出的。
保存发布
测试没问题以后,就可以发布应用了,注意,这个应用是我们自己训练的应用哟,虽然它的底座还是公有模型,但已经可以使用我们本地的私有数据了,而且,没有隐私安全问题。
发布之后,可以到概览界面,使用MaxKb为我们创建的url,这个就可以放到私有业务的系统里使用了。
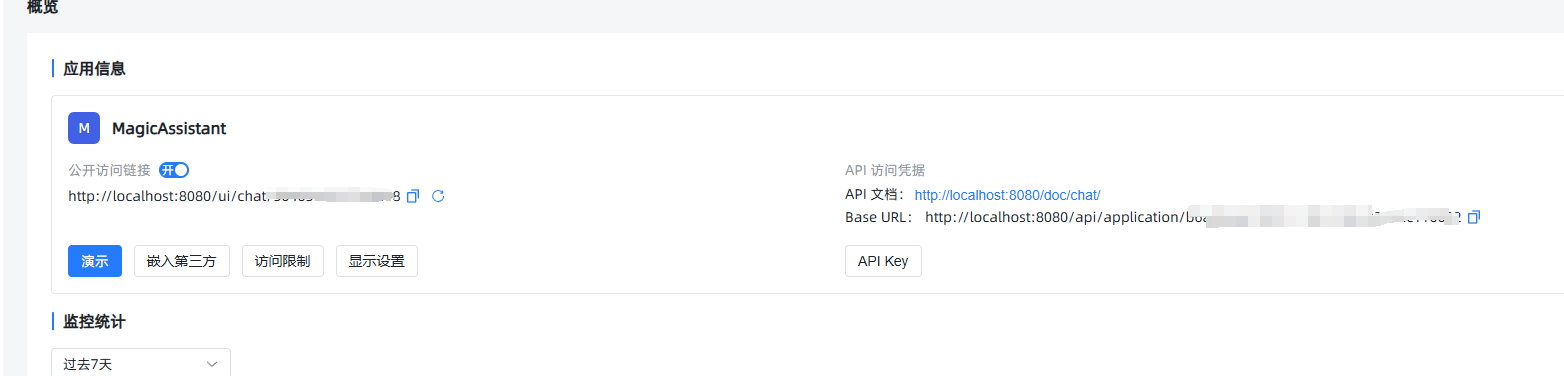
嵌入第三方
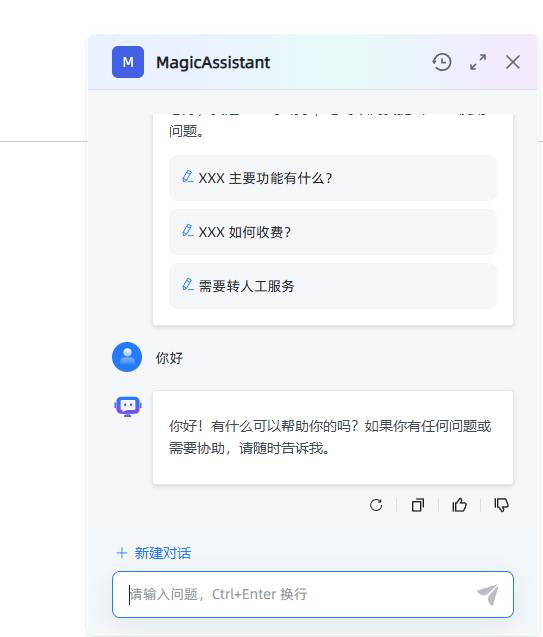
它这里还提供了一个非常好的功能,叫做“嵌入第三方”,当我们把模型配置好以后,可以点击这个“嵌入第三方”按钮,复制他为我们生成的代码到我们已有的其他系统里,就可以很方便的使用这个私有模型了。
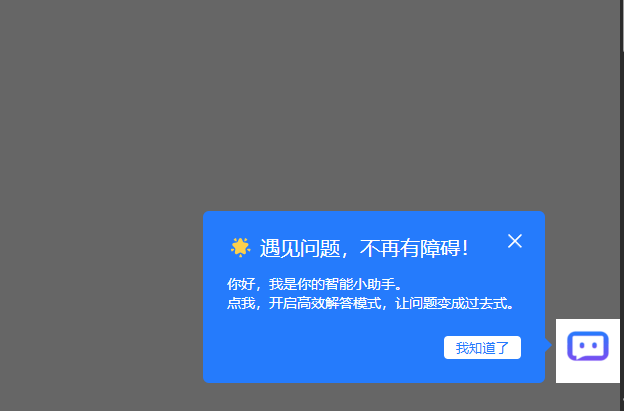
我随便找了个页面,放上他为我们生成的代码,效果如下,丝滑流畅~
总结
上面这一顿操作完成以后,基本就完成了一个简单的节点部署,后续如果对并发能力有更高的要求,就按照容器扩容的思路,增加节点数量就可以了,我们传统的运维人员就可以解决。
注意,这里案例部署的内容我有偷懒,基本还是借鉴的我之前【博客】已经写过的内容,但好在流程完整,这里就偷个懒吧~
半自动的解决方案–AnythingLLM
其实,AnytingLLM的方案,和MaxKB的思路大差不差,不同点是,AnythingLLM提供了一套对开发者有好的API接口,这个,不论是你用客户端的方式,还是用Docker镜像的方式,都可以使用,本地开发,我们就用客户端就可以。
那这种方案,就适合那种有一定研发能力的团队,想要按照自己的思路,开发RAG的交互逻辑,毕竟MaxKB封装的太好了,虽然也提供了自定义的能力,但比起直接集成API来说,还是差一些。
本地安装
这里,我还是使用desktop的安装方式,这种方式更适合开发环境,上手更快,实际如果要用到生产环境的话,最好是参照官网用docker的方式部署,这里就不再赘述,给出地址:https://docs.anythingllm.com/installation-docker/local-docker
配置模型
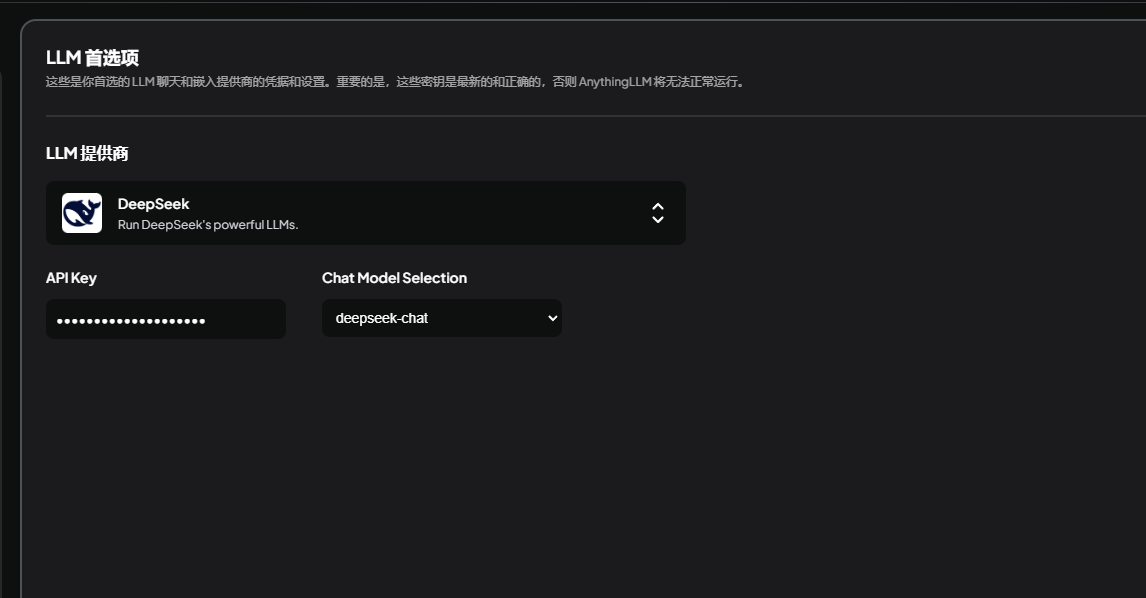
按照引导,进入软件界面后,可以配置模型,可选的模型厂家包括,OpenAI,xAI,Azure,Deepseek等,这里我们选deepseek就好,如果你有其他厂家的key,选其他的也没问题。
选好之后,复制自己的APIKey到软件即可
创建工作区
工作区的概念每个人理解都不一样,我理解就是方便整理的,你可以把你的工作方向划分一下,创建不同的工作区,这样更加清晰。
非开发人员不了解的话,随便起个名字就好。
投喂训练
到此,基本的配置工作就完成了,我们可以上传本地的一些文档,图片等等,然后训练。
比如我这里问他一个比赛项目的赛制问题。我在投喂之前,它的回答是这样的。

这里我把一些赛制的规则文档投喂给他,启动训练。
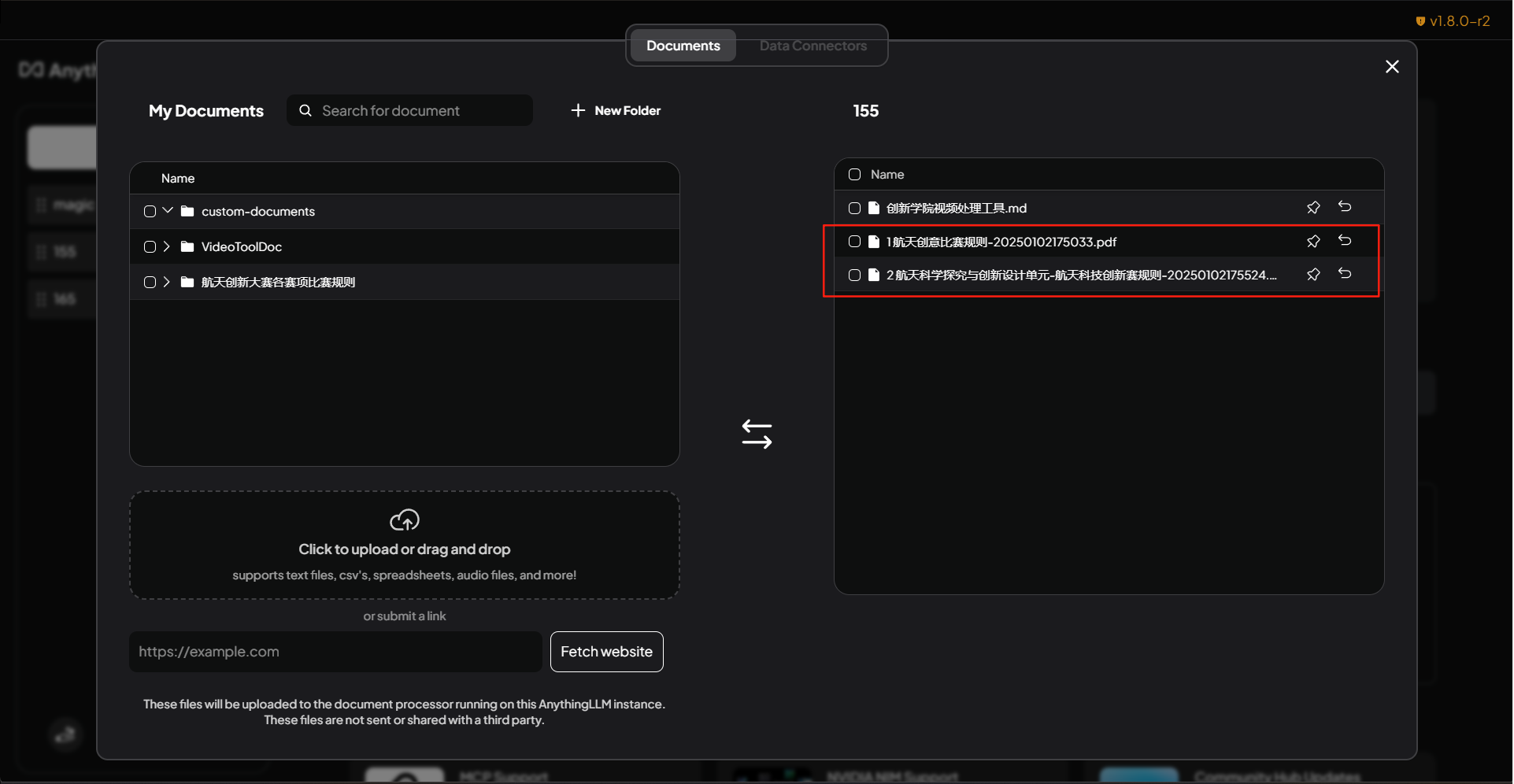
训练结束后再次问同样的问题,他给我的回答就是基于该文档的内容了,然后他就可以帮我去解析赛制规则了。

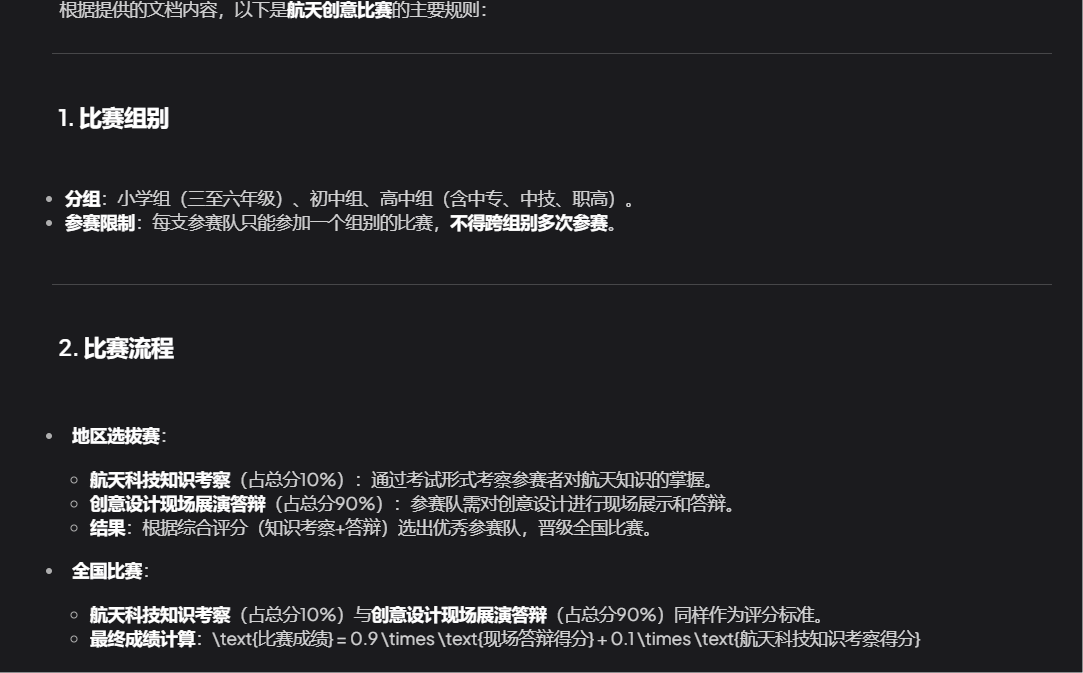
当然,光在客户端问还不够,接下来,要把它的能力集成到业务系统里去
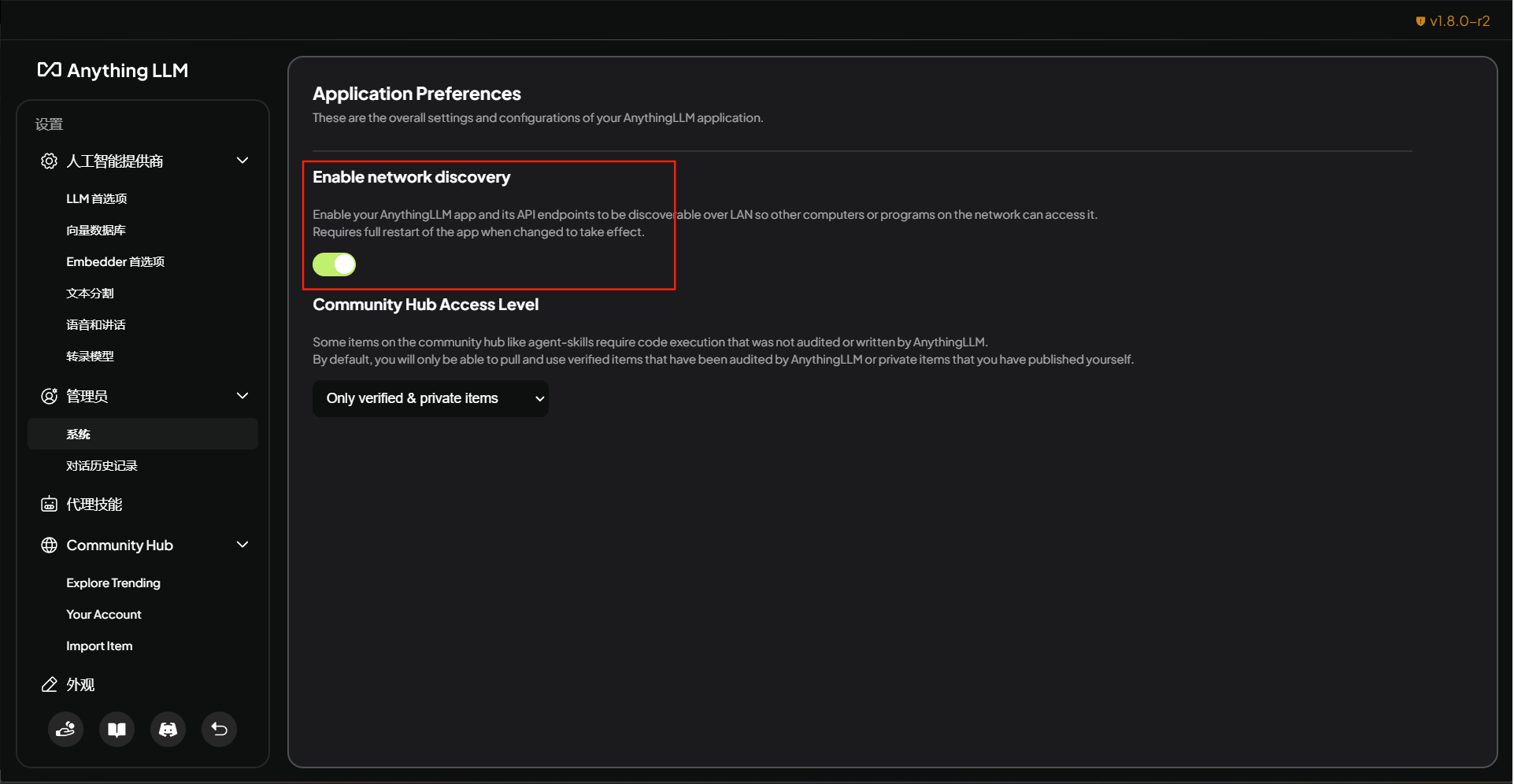
开启host
进入到AnythingLLM的设置界面,打开“管理员”/“系统”选项卡,将“Enable network discovery”开关打开即可。
然后,就可以进入到“工具”/“API 密钥”选项卡,生成API密钥了。
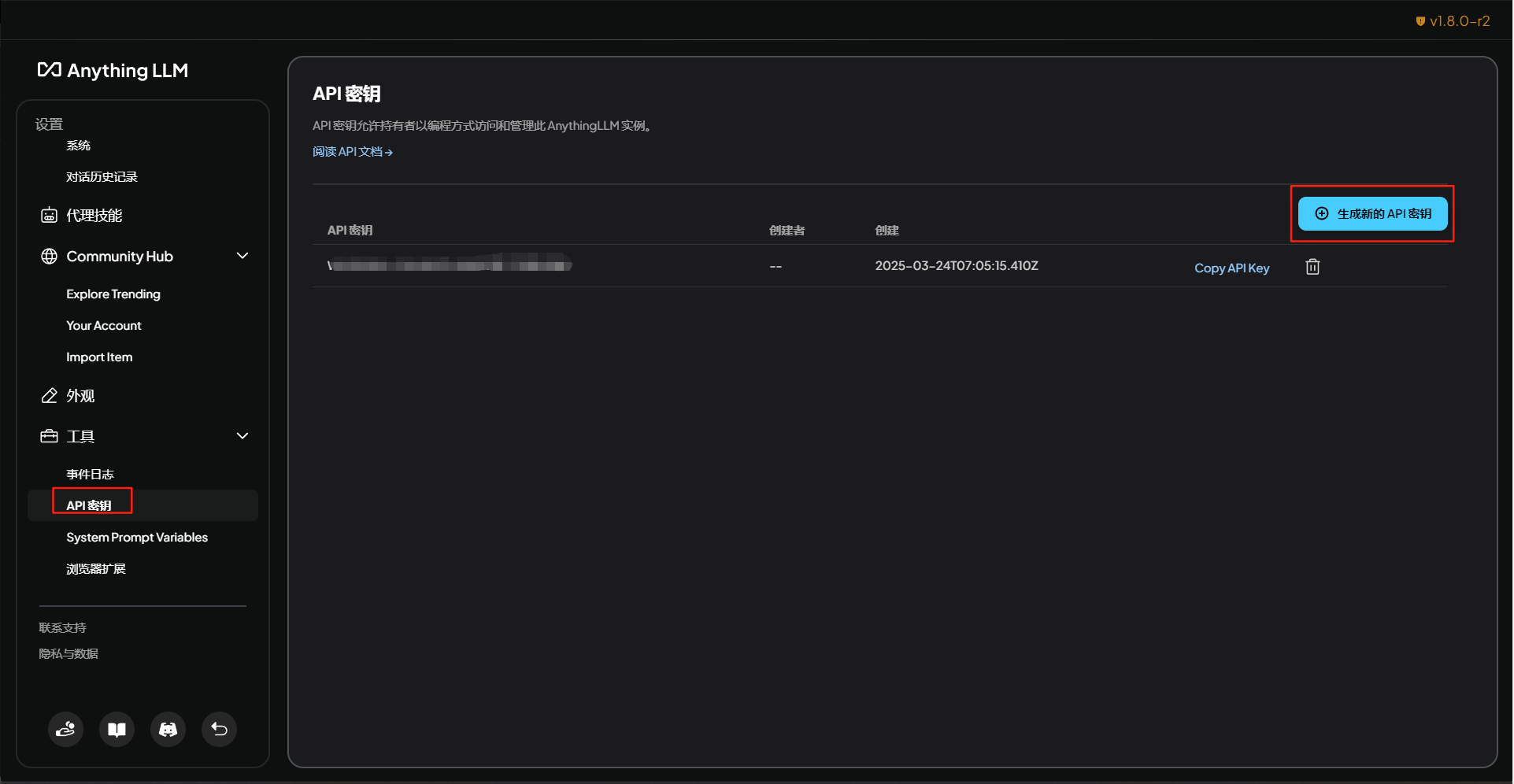
注意,上面的swagger文档,不能浏览器看到的哟,就算打开了网络发现,也不能, 只能在客户端看到,方便我们做对接开发。另外,生产环境使用的时候,要确保做好了安全措施,具体可以参考官网提供的最佳实践,这不是本篇讨论的重点,不再赘述。
写几行代码
准备工作,做好后,我们随便写几行Http请求代码(如下)
var client = new HttpClient();
var request = new HttpRequestMessage(HttpMethod.Post, "http://localhost:3001/api/v1/openai/chat/completions");
request.Headers.Add("stream", "true");
request.Headers.Add("Authorization", "••••••");
var content = new StringContent("{\r\n \"messages\": [\r\n {\r\n \"content\": \"You are a helpful assistant.注意以下回复内容尽量控制在500字以内,如非必要,不要超过1000字,也不要回答任何涉及政治敏感,隐私安全方面的问题\",\r\n \"role\": \"system\"\r\n },\r\n {\r\n \"content\": \"你好\",\r\n \"role\": \"user\"\r\n }\r\n ],\r\n \"model\": \"localmodel\",\r\n \"frequency_penalty\": 0,\r\n \"max_tokens\": 2048,\r\n \"presence_penalty\": 0,\r\n \"stream\": true,\r\n \"temperature\": 1.0,\r\n \"top_p\": 1.0,\r\n \"tool_choice\": \"none\",\r\n \"logprobs\": false\r\n}", null, "application/json");
request.Content = content;
var response = await client.SendAsync(request);
response.EnsureSuccessStatusCode();
Console.WriteLine(await response.Content.ReadAsStringAsync());前台封装的代码,就不展示了,按喜好各自开发即可,我的还是长这样👇
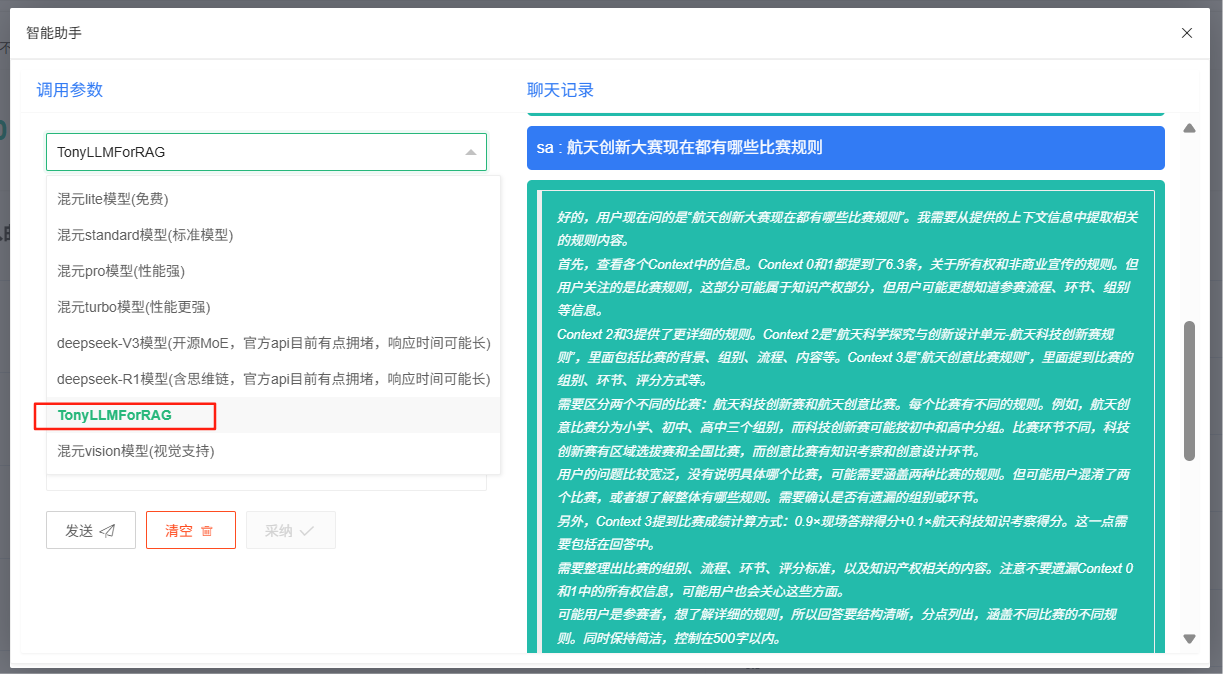
这里选中的就是我自定义的模型,实际指向的已经是AnythingLLM的节点了,可以看下控制台的截图和AnythingLLM客户端的聊天记录
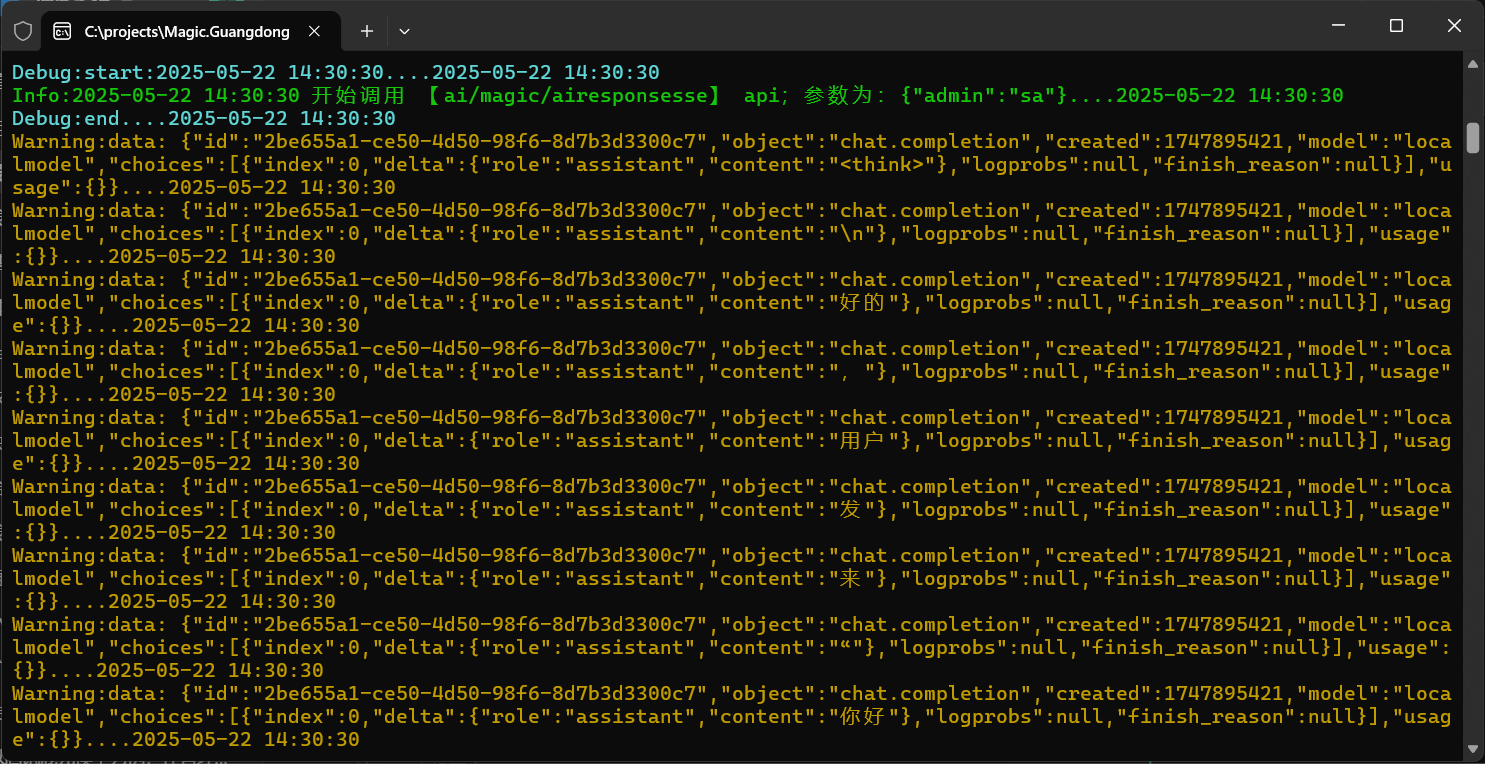
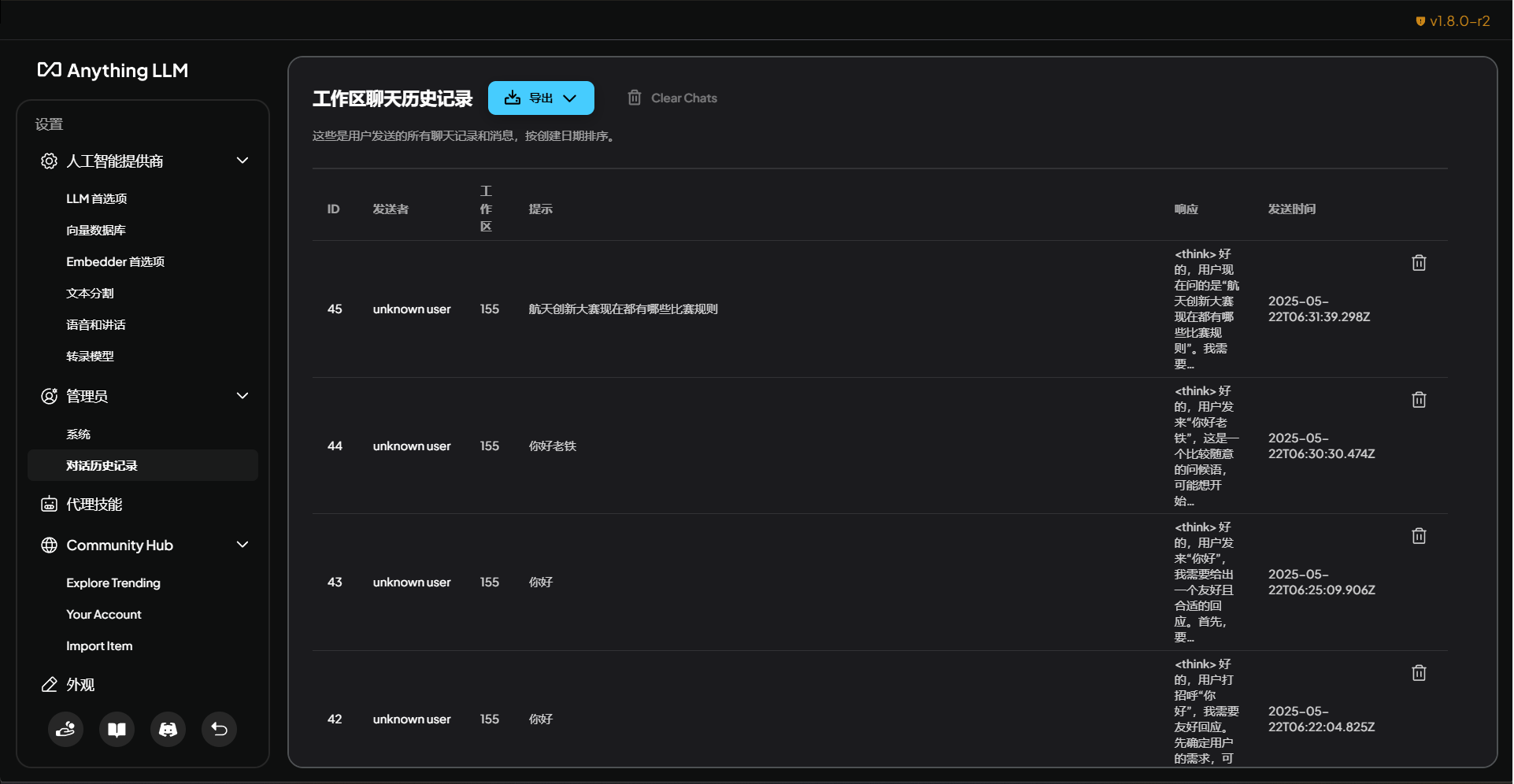
总结
至此,不论是通过“简单省事”的MaxKB,还是靠自己动手DIY的AnythingLLM的方式,亦或是其他实现RAG的各种花式操作。总结起来就是在本地业务集成RAG模块已经没有技术门槛,而且成本可控,也确实能增强我们原有的系统服务能力。
当然,如果让我推荐的话,对于大部分团队的业务来说,我觉得可能MaxKB还是最好的选择,它们提供的软件屏蔽了大部分AI层面的业务负责,尽可能的给用户提供,简单便利的操作即可,其自定义能力也足够应付大部分场景了,而且,是国产软件,信息安全,信创过关,比自己集成要稳定安全的多。