论文阅读:Self-Collaboration Code Generation via ChatGPT
摘要
尽管大型语言模型(LLMs)在代码生成能力方面表现出色,但在处理复杂任务时仍存在挑战。在现实软件开发中,人类通常通过团队协作来应对复杂任务,这种策略能有效控制开发复杂度并提升软件质量。受此启发,本文提出一种基于 LLMs(以 ChatGPT 为例)的自协作代码生成框架。具体而言,通过角色指令:(1)多个 LLM 代理扮演不同的 “专家” 角色,每个角色负责复杂任务中的特定子任务;(2)指定协作和交互方式,使不同角色形成虚拟团队以协同完成工作,最终实现无需人工干预的代码生成任务。为有效组织和管理该虚拟团队,本文将软件开发方法论融入框架,构建了由三个 LLM 角色(分析师、编码员、测试员)组成的基础团队,分别负责软件开发的分析、编码和测试阶段。在多个代码生成基准测试中,实验结果表明,自协作代码生成的 Pass@1 分数相比基准 LLM 代理提升了 29.9%-47.1%。此外,本文还展示了自协作框架能够使 LLMs 高效处理单个 LLM 代理难以解决的复杂代码库级任务。
论文总结
1. 研究背景与目标
- 现有 LLMs 在复杂代码生成任务中表现受限,而人类通过团队协作分解任务、提升质量。
- 提出自协作框架,利用 LLMs 模拟团队分工(分析师、编码员、测试员),结合软件开发方法论(如瀑布模型)实现高效代码生成。
2. 核心方法
- 分工模块(DOL):通过角色指令为 LLM 分配特定角色(如分析师负责需求分解,编码员生成代码,测试员反馈优化),使其以 “专家” 视角处理子任务。
- 协作模块:引入黑板机制作为信息共享中枢,各角色通过自然语言交互,基于前序阶段结果迭代优化输出。例如,分析师生成设计文档→编码员基于文档编码→测试员反馈缺陷→编码员修复,形成闭环。
- 实例化流程:采用简化瀑布模型,定义三阶段流水线(分析→编码→测试),角色间最大交互次数(MI)限制为 4 次,通过 JSON 格式输出确保结构化。
3. 实验与结果
- 基准测试:在 HumanEval、MBPP、APPS、CoderEval 等基准上,自协作框架相比单 LLM 代理(如 ChatGPT)提升显著。例如,在 HumanEval 上 Pass@1 提升 29.9%,在 CoderEval 的复杂依赖任务中提升 47.1%。
- 角色有效性:消融实验表明,三角色协同(分析师 + 编码员 + 测试员)效果最优,单独移除任一角色均导致性能下降。角色指令比无角色提示(如零样本提示)更有效,证明 “角色扮演” 能约束 LLM 生成空间,提升专业性。
- 模型扩展性:在 GPT-4、CodeLlama 等模型上验证了框架的普适性,发现模型参数规模(如≥7B)和领域知识(如 CodeLlama 相比 Llama2)对协作效果有显著影响。
4. 应用与案例
- 函数级任务:以 HumanEval 为例,分析师分解需求为子任务(如检查素数、生成斐波那契数列),编码员按计划生成代码,测试员发现边界条件错误并推动修复,最终通过所有测试用例。
- 复杂任务:在游戏开发(如障碍躲避游戏)和网站开发(天气预报网站)中,自协作框架生成包含多文件(HTML/CSS/JS)的完整项目,功能覆盖率和代码质量显著优于单模型直接生成。
5. 结论与展望
- 贡献:首次将软件开发方法论引入 LLM 协作,证明自协作能有效提升复杂代码生成的准确性和鲁棒性,为多智能体协作提供新范式。
- 局限与未来:现有基准与真实开发场景存在差距,未来可引入人类专家轻量级干预,扩展至更多开发角色(如架构师、运维),并探索跨领域(如硬件设计、科学计算)的协作应用。
设计方法内容原理
1. 自协作框架整体架构
框架分为分工模块(DOL)和协作模块,通过角色指令驱动 LLM 代理协同工作:
- 输入:用户需求 x(自然语言描述)。
- 输出:目标代码 y。
- 核心逻辑:
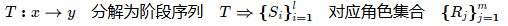 其中,每个阶段
其中,每个阶段由特定角色
处理,通过黑板机制共享中间结果
,迭代更新输出
,直至满足终止条件(如测试通过或达到最大交互次数)。
2. 分工模块(DOL):角色指令与任务分解
- 角色指令设计:
- 分析师(Analyst):负责需求抽象与分解,输出高层设计计划(如模块划分、接口定义)。 示例指令:“将需求分解为可实现的子任务,制定指导编码的高层计划,避免涉及具体实现细节。”
- 编码员(Coder):根据设计计划生成代码,或根据测试反馈修复优化。 示例指令:“按照分析师提供的计划编写 Python 代码,确保效率、可读性和最佳实践;若收到测试报告,基于反馈修改代码且不引入新错误。”
- 测试员(Tester):模拟测试过程,生成测试报告(如功能缺陷、边界条件问题)。 示例指令:“测试代码功能是否符合需求,记录问题并生成简洁报告,若代码通过测试,输出‘Code Test Passed’。”
- 任务分解原则:基于软件开发方法论(如瀑布模型)将复杂任务线性划分为分析→编码→测试阶段,每个阶段由单一角色主导,确保职责分离。
3. 协作模块:黑板机制与交互流程
- 黑板机制(Blackboard):
- 存储多模态信息:需求文档、设计计划、代码草稿、测试报告等。
- 交互流程:
- 分析师解析需求 x,生成设计计划
并存入黑板。
- 编码员读取
并返回黑板。
- 测试员读取
(含 Bug 反馈)。
- 编码员根据
,重复直至
- 分析师解析需求 x,生成设计计划
- 交互形式:通过自然语言指令实现角色间通信,例如测试员反馈:“代码在处理空列表时返回错误结果,需添加边界条件检查。”
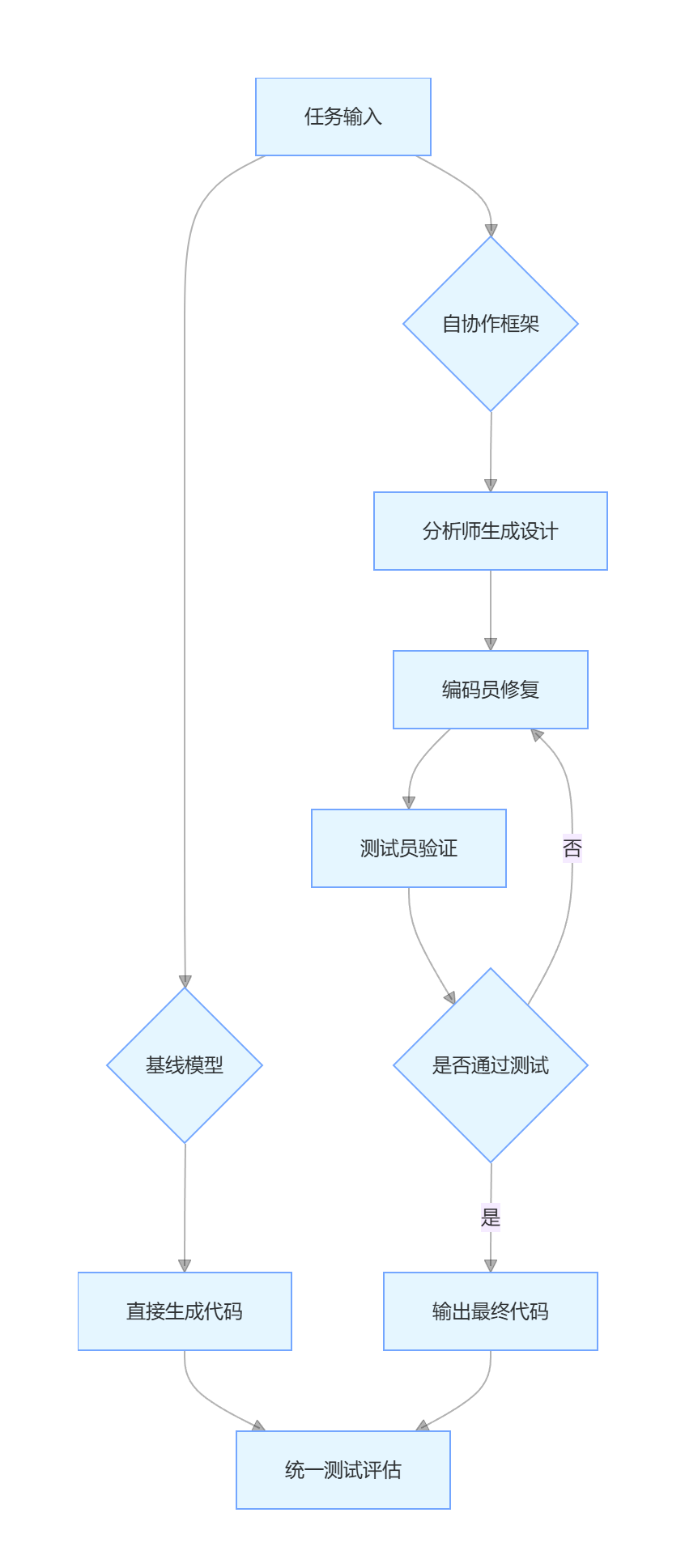
4. 实例化:基于瀑布模型的三角色团队
- 阶段与角色映射:
开发阶段 负责角色 核心任务 分析阶段 分析师 分解需求为子任务,生成模块设计与接口定义(如 UML 图、API 规格)。 编码阶段 编码员 根据设计文档编写代码,支持多语言(如 Python/Java),输出可执行脚本。 测试阶段 测试员 生成测试用例,验证功能正确性、鲁棒性,反馈缺陷(如语法错误、逻辑漏洞)。 - 关键技术:
- 角色初始化:通过一次性角色指令定义职责,避免多轮交互中的上下文漂移。
- 结构化输出:要求 LLM 以 JSON 格式生成中间结果,减少信息歧义,便于黑板解析和跨角色传递。
5. 理论基础与创新点
- 模拟人类团队协作:通过分工降低任务复杂度,利用多角色校验提升代码质量(如分析师避免需求误解,测试员发现编码逻辑错误)。
- 轻量化实现:无需模型微调或额外训练,仅通过提示工程复用 LLM 的通用能力,适用于多种 LLM(如 ChatGPT、GPT-4、CodeLlama)。
- 可扩展性:支持动态调整角色数量和类型(如添加 “编译器” 角色或前端 / 后端分工),适配不同开发流程(如敏捷开发、DevOps)。
数据集来源
论文实验采用了 6 个公开的代码生成基准数据集,覆盖函数级到项目级任务,部分数据集还提供了扩展版本以增强测试难度。具体来源如下:
| 数据集 | 来源 / 作者 | 任务类型 | 规模与特点 |
|---|---|---|---|
| MBPP | Austin et al., 2021 | Python 函数级编程任务 | 427 个手动验证任务,含自然语言描述、代码解和 3 个自动化测试用例,覆盖编程基础和标准库功能。 |
| HumanEval | Chen et al., 2021 | Python 函数级编程任务 | 164 个手写任务,包含函数签名、自然语言描述、用例、函数体及平均 7.7 个单元测试,由 OpenAI 提出。 |
| MBPP-ET | Dong et al., 2023 (扩展版) | Python 函数级任务(增强测试) | MBPP 扩展版,每个任务新增 100 + 测试用例,侧重边缘情况,提升评估可靠性。 |
| HumanEval-ET | Dong et al., 2023 (扩展版) | Python 函数级任务(增强测试) | HumanEval 扩展版,同上。 |
| APPS | Hendrycks et al., 2021 | 算法与编程问题(竞赛级难度) | 收集自 Codeforces、Kattis 等平台,包含 1000 + 复杂任务(平均 293.2 词描述),平均 21.2 个测试用例。 |
| CoderEval | Yu et al., 2024 | 含依赖关系的代码生成任务(模拟真实开发) | 包含 Standalone(独立代码)、Plib-depend(库依赖)、Class-depend(类依赖)、File-depend(文件依赖)、Project-depend(项目依赖)5 类,评估代码在复杂依赖场景下的生成能力。 |
试验对照组设计
-
基线模型
- 零样本 (Zero-Shot):直接使用原始 LLM(如 ChatGPT、GPT-4),无任何额外提示,仅输入任务描述:
AlphaCode (1.1B) 是一种基于 transformer 的代码生成模型,在 2021 年 7 月 14 日之前对选定的公码进行了训练,可以解决一些基本的代码生成问题。
Incoder (6.7B) 是一个统一的生成模型,它允许通过因果掩码语言建模训练目标从左到右生成代码和代码填充/编辑。
CodeGeeX (13B) 是一个具有 130 亿个参数的大规模多语言代码生成模型,在 20 多种编程语言的大型代码语料库上进行了预训练。
StarCoder (15.5B) 是一个代码 LLM,使用来自 GitHub 的许可数据(包括来自 80 的数据)进行训练+编程语言、Git 提交、GitHub 问题和 Jupyter 笔记本。
CodeGen (16.1B)是一个受过 NL 和编程数据训练的 LLM,用于基于对话的程序合成。在本文中,我们采用 CodeGen-Multi 版本。
PaLM Coder (540B)在代码上从 PaLM 540B 进行了微调,其中 PaLM 使用名为 Pathways 的机器学习系统,该系统可以在数千个加速器芯片上实现 LLM 的高效训练。
CodeX (175B) ,也称为 code-davinci-002,是从 davinci 175B 对带有代码完成任务的多语言代码数据进行微调的。CodeX 也是为 Copilot(一个著名的商业应用程序)提供支持的主干模型。
CodeX (175B) + CodeT 是 GPT-4 之前最先进的 (SOTA) 方法。CodeT 使用 LLM 为代码示例自动生成测试用例。它使用这些测试用例执行代码样本,并执行双重执行协议,同时考虑测试用例的输出一致性和代码样本之间的输出一致性。
CodeLlama (34B)是一个用于代码生成任务的开放基础模型,源自基于 Llama 2 [55] 的持续训练和微调。
ChatGPT 是 InstructGPT的兄弟模型,它被训练为遵循提示中的指令并提供详细的响应。我们通过 OpenAI 的 API 访问 ChatGPT。由于 ChatGPT 会定期接收更新,因此我们采用固定版本“gpt-3.5-turbo-0301”作为我们的基础模型,它不会接收更新,以最大限度地降低模型意外更改影响结果的风险。
GPT-4 是一种大规模的多模态模型,可以接受图像和文本输入并生成文本输出。GPT-4 在各种基准测试中表现出人类水平的性能。
- 单角色 (Single-Role):使用单一 LLM 代理,添加通用指令(如 "生成满足需求的代码")
- 多轮对话 (Multi-Turn):允许 LLM 通过多轮交互优化输出,但无明确角色分工
- 零样本 (Zero-Shot):直接使用原始 LLM(如 ChatGPT、GPT-4),无任何额外提示,仅输入任务描述:
-
实验组
- 自协作框架 (Self-Collaboration):基于分工模块和协作模块,配置分析师 + 编码员 + 测试员三角色
- 消融实验:依次移除分析师、编码员、测试员角色,验证各角色贡献
3. 实验评价指标
1. Pass@1:生成的代码通过所有测试用例的比例
2. Pass@k:尝试 k 次生成中至少有一次通过的比例