Deeper and Wider Siamese Networks for Real-Time Visual Tracking
现象:
the backbone networks used in Siamese trackers are relatively shallow, such as AlexNet , which does not fully take advantage of the capability of modern deep neural networks.
direct replacement of backbones with existing powerful architectures, such as ResNet and Inception, does not bring improvements.
如果要处理一些比较复杂的视觉问题时,使用孪生网络之前的backbone效果就不太好了(因为网络比较浅,不能充分提取图像的特征。)但是使用一些比较深/宽的网络替换掉之前的backbone后发现其效果反而更差了,所以本文就探索了是什么原因导致的这个现象,并提出了几种不同的backbone。
原因/问题:
-
receptive field size
large increases in the receptive field of neurons lead to reduced feature discriminability and localization precision;
感受野的增大导致特征差异以及局部精细度感知的降低。 -
feature padding
the network padding for convolutions induces a positional bias in learning.when an object moves near the search range boundary, it is difficult to make an accurate prediction.
卷积过程中使用的填充会导致位置的偏移,从而导致位于search range边缘的物体检测不准确 -
network stride
The network stride affects the degree of localization precision, especially for small-sized objects.
步长会影响局部精度,特别是对于小的物体
本文的创新点/解决:
- 设计了
CIR来减少padding的不利影响 - 控制了步长和感受野大小,并且把
CIR加了进来,在孪生网络的基础上设计了两种网络架构。
CIR单元:
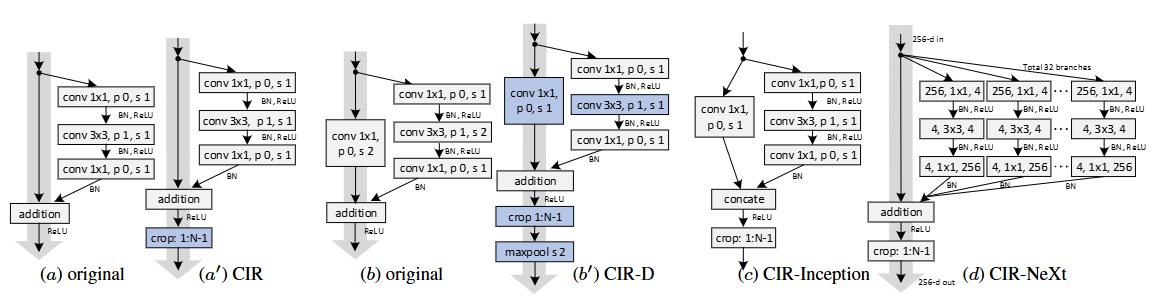
(a')CIR:The cropping operation removes features whose calculation is affected by the zero-padding signals. Since the padding size is one in the bottleneck layer, only the outermost features on the border of the feature maps are cropped out. This simple operation neatly removes padding-affected features in residual unit.
相加后得到的特征图的最外面一圈才会受到填充的影响,那就把最后一圈去掉(b')CIR-D:If we were only to insert cropping after the addition operation, as done in the proposed CIR unit, without changing the position of downsampling, the features after cropping would not receive any signal from the outermost pixels in the input image.
对于像(b)有下采样的卷积,就拿b举例,因为步长是2填充是1,原始图最外面那一圈的信息只包含在特征图最外面一圈中,如果直接像(a')一样把特征图最后一圈裁掉,那么原图最后一圈的信息将会永远丢失。所以作者改变了下采样的顺序(妙啊)
补充:
- 视觉跟踪任务的定义:Visual tracking is one of the fundamental problems in computer vision. It aims to estimate the position of an arbitrary target in a video sequence, given only its location in the initial frame.
- 孪生网络:
- 定义:Siamese architecture takes an image pair as input, comprising an exemplar image z and a candidate search image x. The image z represents the object of interest (e.g., an image patch centered on the target object in the first video frame)
两个input,两个网络,同一类的距离近些,不同类的距离远些。 siamese networkVSpseudo-siamese network- 左右两边共享权值,是相同的网络:
siamese network - 如果左右两边不共享权值,时不相同的网络:
pseudo-siamese network
- 左右两边共享权值,是相同的网络:
- 定义:Siamese architecture takes an image pair as input, comprising an exemplar image z and a candidate search image x. The image z represents the object of interest (e.g., an image patch centered on the target object in the first video frame)
CNN VS FCN- CNN: 在传统的
CNN网络中,在最后的卷积层之后会连接上若干个全连接层,将卷积层产生的特征图feature map映射成为一个固定长度的特征向量。一般的CNN结构适用于图像级别的分类和回归任务,因为它们最后都期望得到输入图像的分类的概率。(例如:手写字识别) - FCN:
FCN是对图像进行像素级的分类(也就是每个像素点都进行分类),从而解决了语义级别的图像分割问题。(例如:确定一张图片上猫的位置)
- CNN: 在传统的